Juli 2020
Dessa funktioner och förbättringar av Azure Databricks-plattformen släpptes i juli 2020.
Kommentar
Versioner mellanlagras. Ditt Azure Databricks-konto kanske inte uppdateras förrän upp till en vecka efter det första lanseringsdatumet.
Webbterminal (allmänt tillgänglig förhandsversion)
29 juli-4 augusti 2020: Version 3.25
Webbterminalen är ett praktiskt och mycket interaktivt sätt för användare med can attach to-behörighet i ett kluster att köra gränssnittskommandon, inklusive redigeringsprogram som Vim eller Emacs. Exempel på användning av webbterminalen är övervakning av resursanvändning och installation av Linux-paket.
Mer information finns i Köra gränssnittskommandon i Azure Databricks-webbterminalen.
Nytt, säkrare ramverk för globalt init-skript (allmänt tillgänglig förhandsversion)
29 juli - 4 augusti 2020: Version 3.25
Det nya globala init-skriptramverket ger betydande förbättringar jämfört med äldre globala init-skript:
- Init-skript är säkrare, vilket kräver administratörsbehörighet för att skapa, visa och ta bort.
- Skriptrelaterade startfel loggas.
- Du kan ange körningsordningen för flera init-skript.
- Init-skript kan referera till klusterrelaterade miljövariabler.
- Init-skript kan skapas och hanteras med hjälp av sidan för administratörsinställningar eller det nya REST-API:et för globala Init-skript.
Databricks rekommenderar att du migrerar befintliga äldre globala init-skript till det nya ramverket för att dra nytta av dessa förbättringar.
Mer information finns i Använda globala init-skript.
IP-åtkomstlistor är nu allmänt tillgängliga
29 juli - 4 augusti 2020: Version 3.25
API:et för IP-åtkomstlista är nu allmänt tillgängligt.
Ga-versionen innehåller en ändring, vilket är att byta namn på list_type värdena:
WHITELISTtillALLOWBLACKLISTtillBLOCK
Använd API:et för IP-åtkomstlista för att konfigurera dina Azure Databricks-arbetsytor så att användarna endast ansluter till tjänsten via befintliga företagsnätverk med en säker perimeter. Azure Databricks-administratörer kan använda API:et för IP-åtkomstlista för att definiera en uppsättning godkända IP-adresser, inklusive listan över tillåtna och blockerade. All inkommande åtkomst till webbappen och REST-API:er kräver att användaren ansluter från en auktoriserad IP-adress, vilket garanterar att arbetsytor inte kan nås från ett offentligt nätverk som ett kafé eller en flygplats om inte användarna använder VPN.
Den här funktionen kräver Premium-planen.
Mer information finns i Konfigurera IP-åtkomstlistor för arbetsytor.
Ny dialogruta för filuppladdning
29 juli - 4 augusti 2020: Version 3.25
Nu kan du ladda upp små tabelldatafiler (till exempel CSV:er) och komma åt dem från en notebook-fil genom att välja Lägg till data från notebook-menyn Arkiv . Genererad kod visar hur du läser in data i Pandas eller DataFrames. Administratörer kan inaktivera den här funktionen på fliken Avancerat i administrationskonsolen.
Mer information finns i Bläddra bland filer i DBFS.
Förbättrad filtrering och sortering för SCIM API
29 juli - 4 aug 2020: Version 3.25
SCIM-API:et innehåller nu dessa förbättringar för filtrering och sortering:
- Administratörsanvändare kan filtrera användare på attributet
active. - Alla användare kan sortera resultat med hjälp av
sortByfrågeparametrarna ochsortOrder. Standardvärdet är att sortera efter ID.
Azure Government-regioner har lagts till
den 25 juli 2020
Azure Databricks blev nyligen tillgängligt i regionerna US Gov Arizona och US Gov Virginia för amerikanska myndigheter och deras partner.
Databricks Runtime 7.1 GA
den 21 juli 2020
Databricks Runtime 7.1 innehåller många ytterligare funktioner och förbättringar jämfört med Databricks Runtime 7.0, inklusive:
- Google BigQuery-anslutningsprogram
%pipkommandon för att hantera Python-bibliotek som installerats i en notebook-session- Koalas installerat
- Många Förbättringar av Delta Lake, inklusive:
- Ange användardefinierade incheckningsmetadata
- Hämta versionen av den senaste incheckningen som skrivits av den aktuella
SparkSession - Konvertera Parquet-tabeller som skapats av Structured Streaming med hjälp av transaktionsloggen
_spark_metadata MERGE INTOPrestandaförbättringar
Mer information finns i fullständiga viktig information om Databricks Runtime 7.1 (stöds inte).
Databricks Runtime 7.1 ML GA
den 21 juli 2020
Databricks Runtime 7.1 för Machine Learning bygger på Databricks Runtime 7.1 och innehåller följande nya funktioner och biblioteksändringar:
- pip- och conda magic-kommandon aktiverade som standard
- spark-tensorflow-distributor: 0.1.0
- kudde 7.0.0 -> 7.1.0
- pytorch 1.5.0 -> 1.5.1
- torchvision 0.6.0 -> 0.6.1
- horovod 0.19.1 -> 0.19.5
- mlflow 1.8.0 -> 1.9.1
Mer information finns i fullständiga viktig information om Databricks Runtime 7.1 för ML (stöds inte).
Databricks Runtime 7.1 Genomics GA
den 21 juli 2020
Databricks Runtime 7.1 för Genomics bygger på Databricks Runtime 7.1 och innehåller följande nya funktioner:
- LOCO-omvandling
- GloWGR-utdataomformningsfunktion
- RNASeq matar ut omålade justeringar
Databricks Connect 7.1 (allmänt tillgänglig förhandsversion)
den 17 juli 2020
Databricks Anslut 7.1 finns nu i offentlig förhandsversion.
Uppdateringar av API för IP-åtkomstlista
15-21 juli 2020: Version 3.24
Följande API-egenskaper för IP-åtkomstlista har ändrats:
updator_user_idtillupdated_bycreator_user_idtillcreated_by
Python-notebooks har nu stöd för flera utdata per cell
15-21 juli 2020: Version 3.24
Python-notebook-filer stöder nu flera utdata per cell. Det innebär att du kan ha valfritt antal visnings-, displayHTML- eller utskriftsuttryck i en cell. Dra nytta av möjligheten att visa rådata och diagrammet i samma cell, eller alla utdata som lyckades innan du stötte på ett fel.
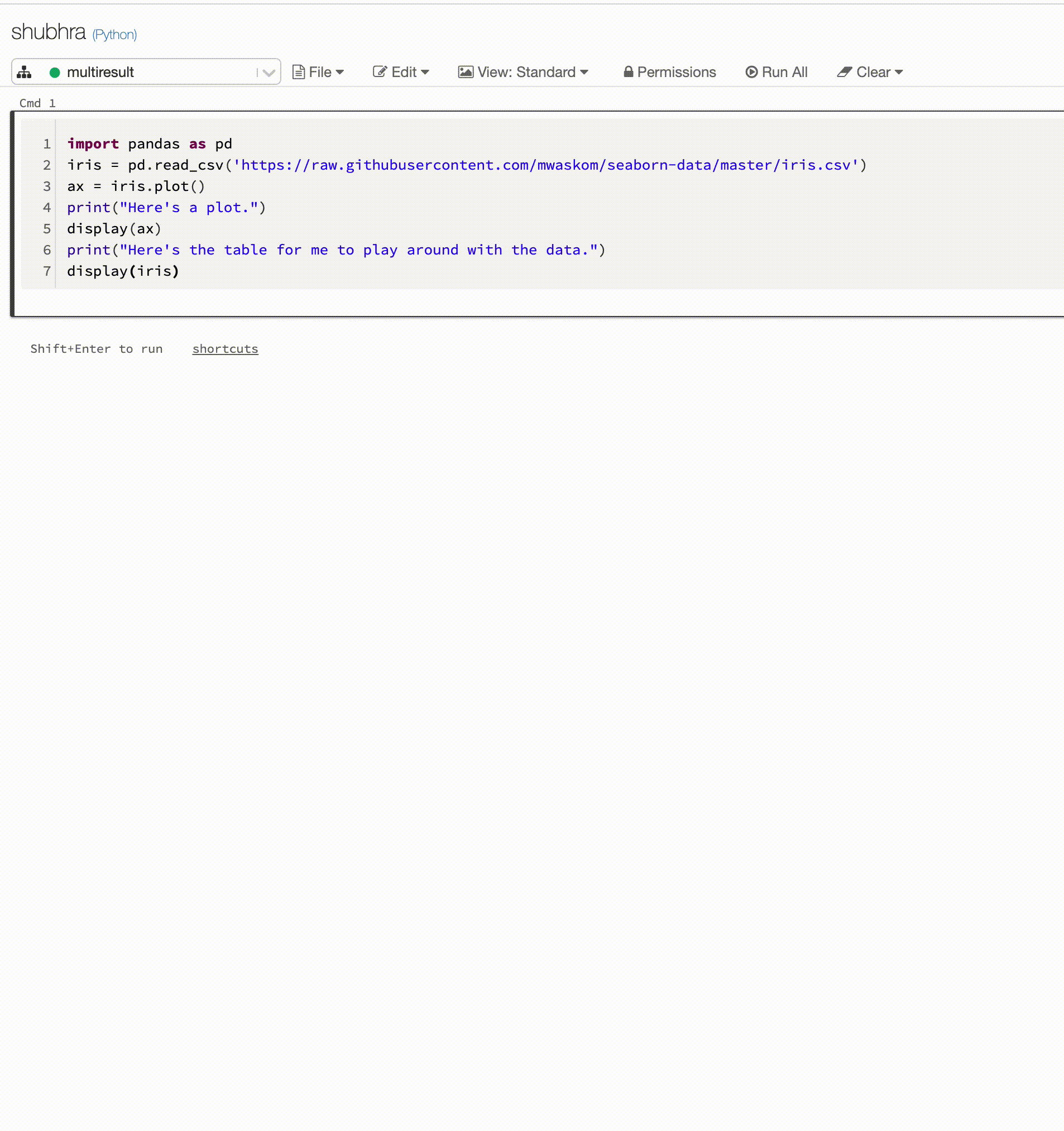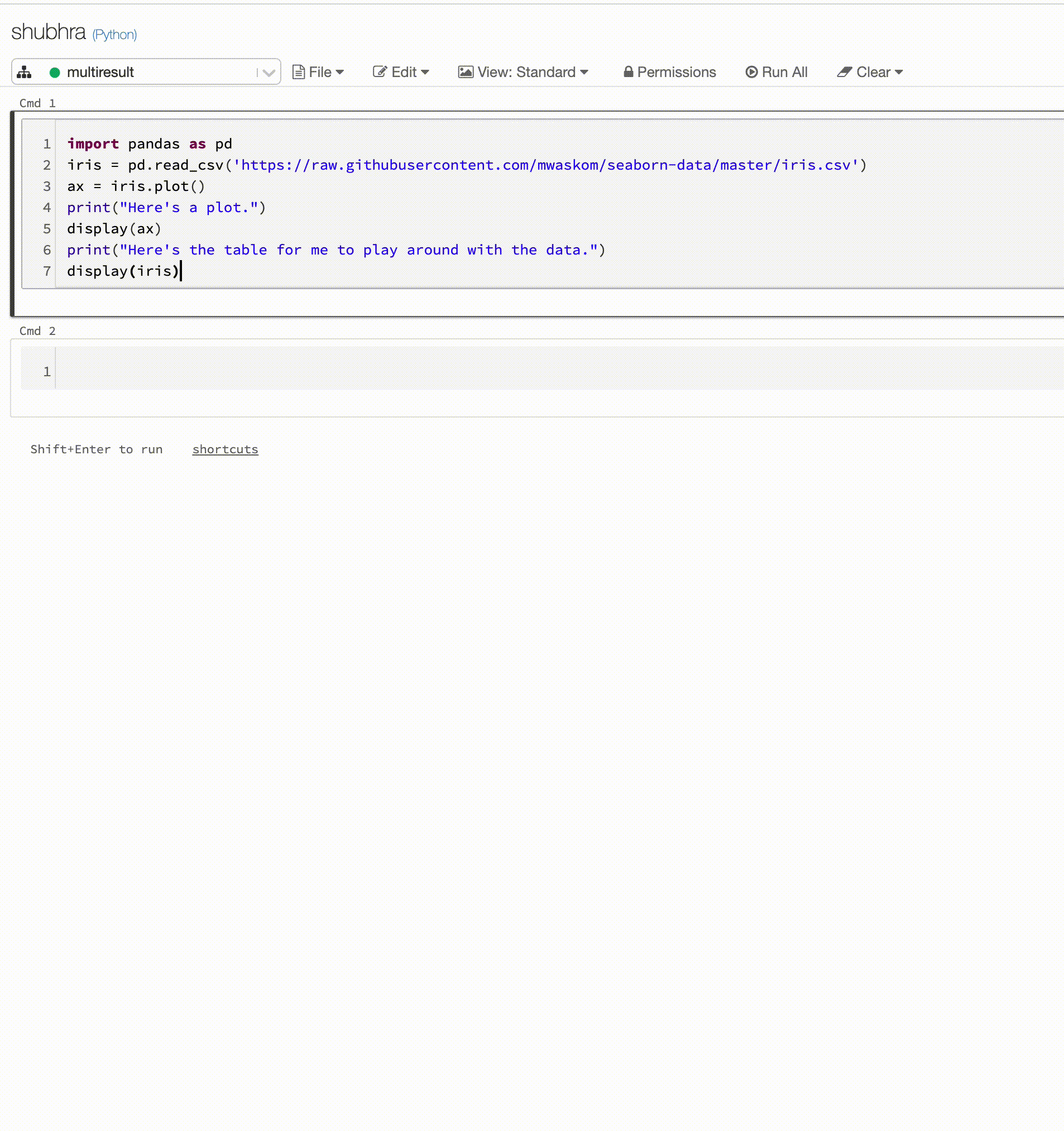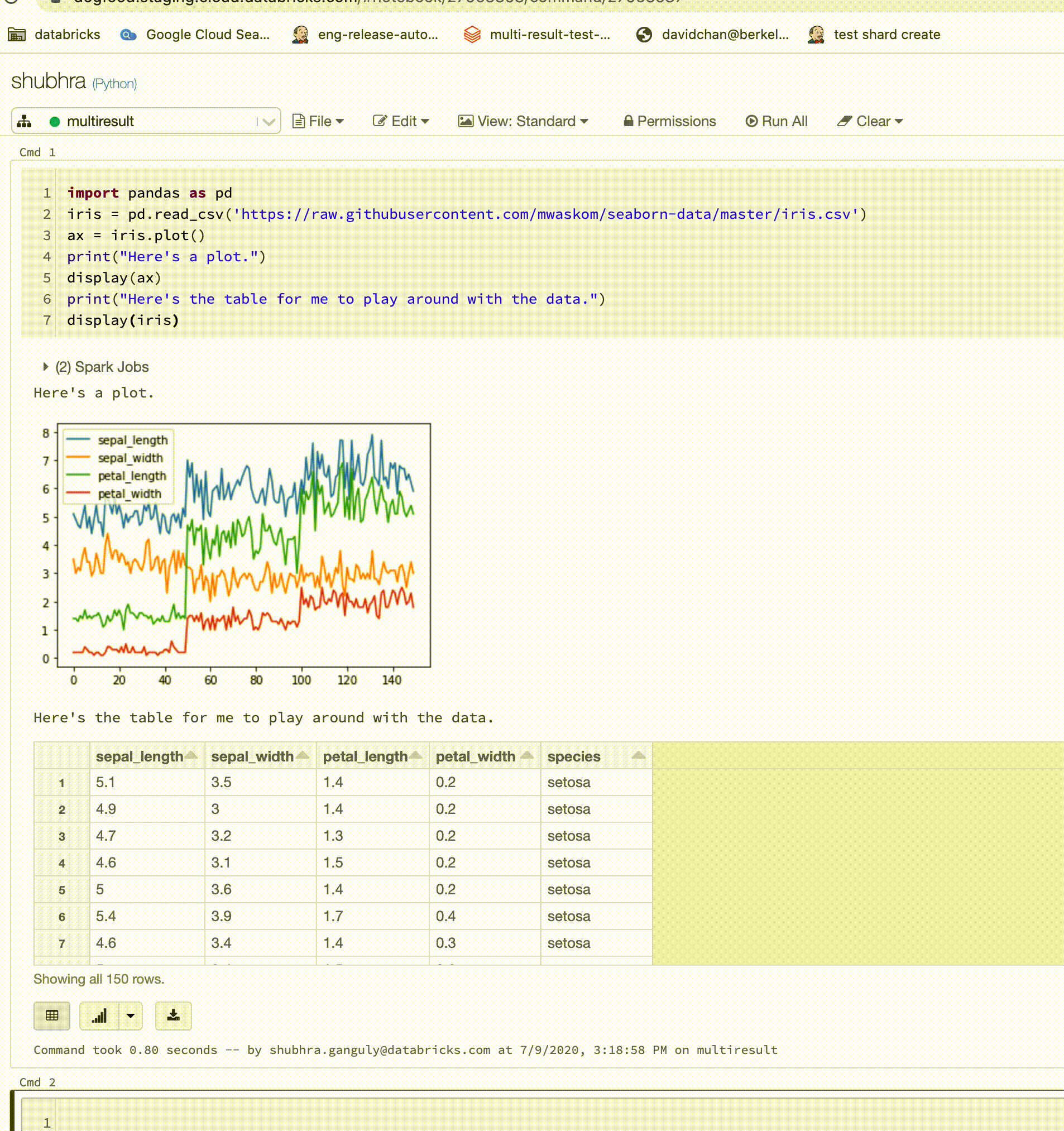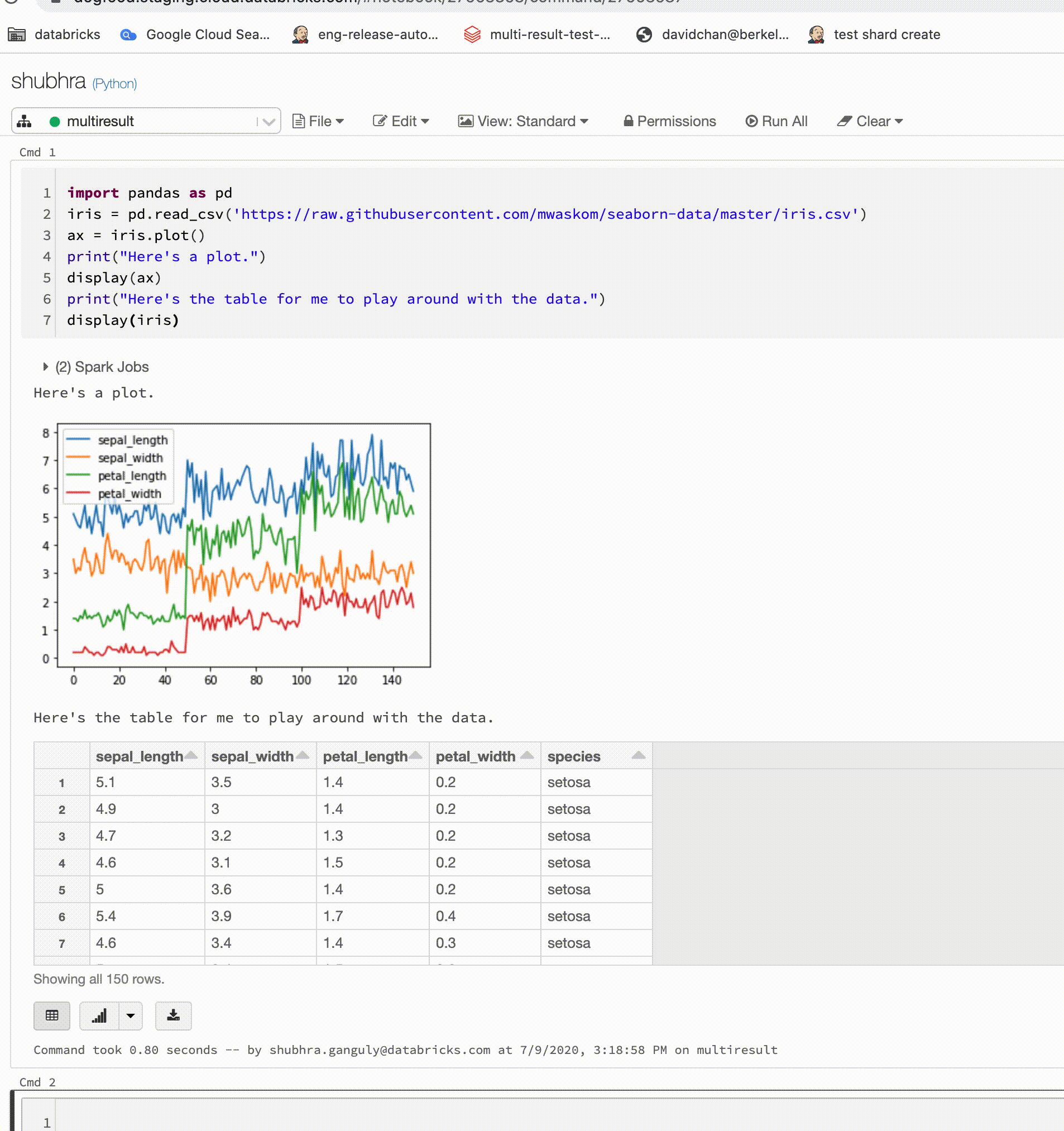
Den här funktionen kräver Databricks Runtime 7.1 eller senare och är inaktiverad som standard i Databricks Runtime 7.1. Aktivera det genom att ange spark.databricks.workspace.multipleResults.enabled true.
Visa notebook-kod och resultatceller sida vid sida
15-21 juli 2020: Version 3.24
Med det nya visningsalternativet sida vid sida kan du visa kod och resultat bredvid varandra. Det här visningsalternativet ansluter till alternativet "Standard" (tidigare "Kod") och alternativet Endast resultat.
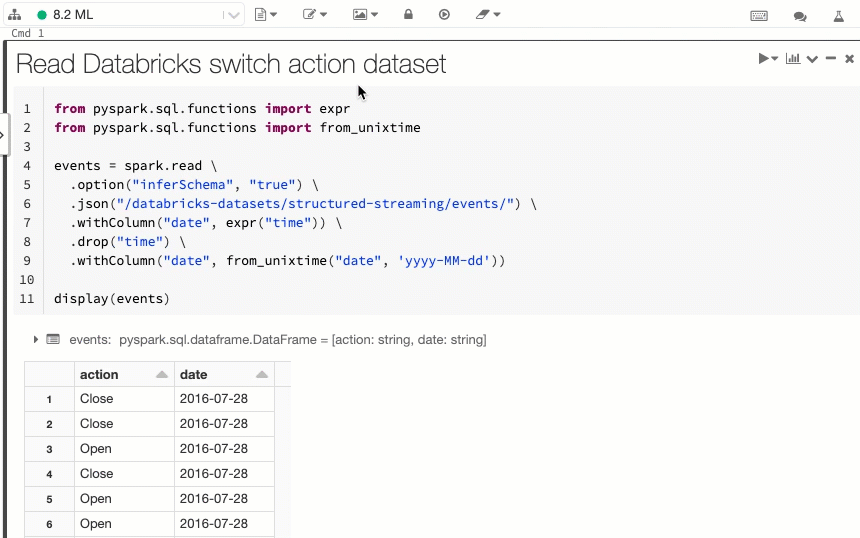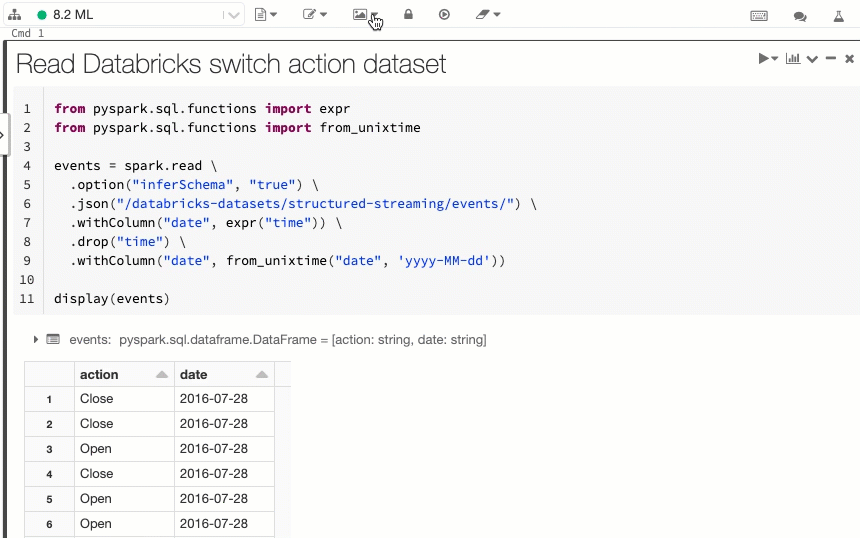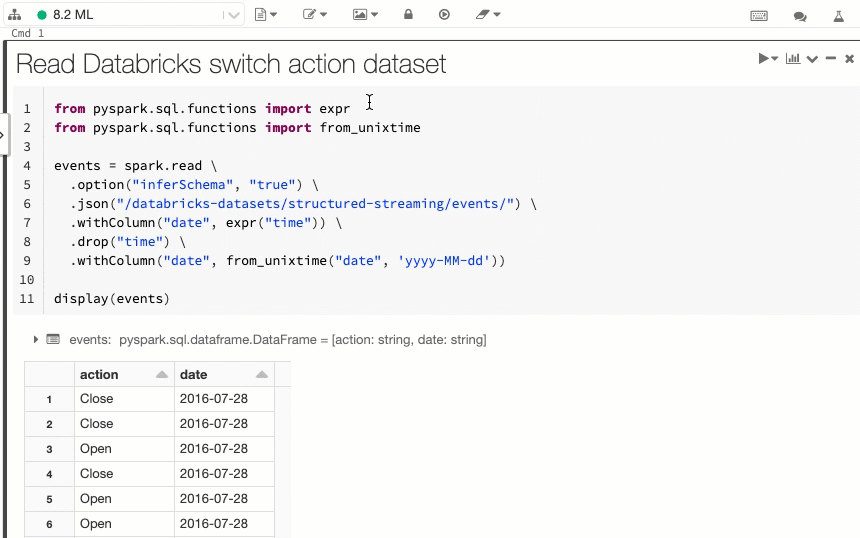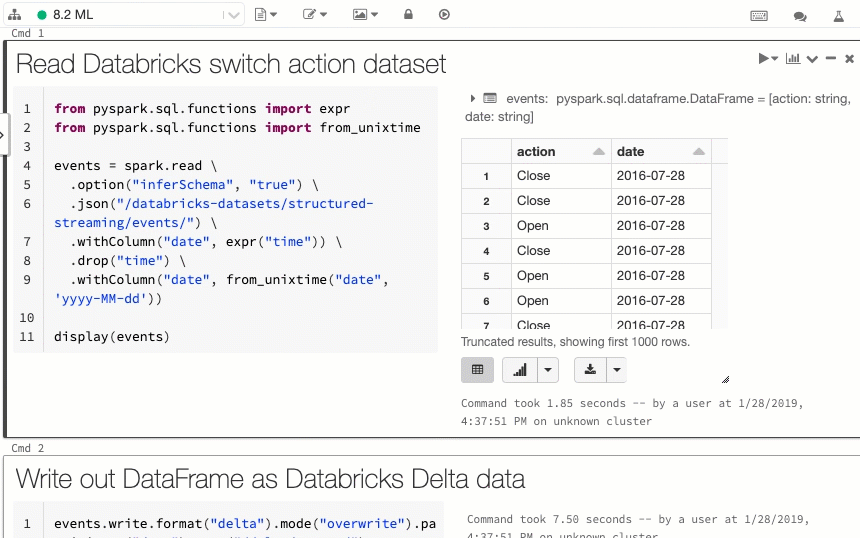
Pausa jobbscheman
15-21 juli 2020: Version 3.24
Jobbscheman har nu paus- och pausknappar som gör det enkelt att pausa och återuppta jobb. Nu kan du göra ändringar i ett jobbschema utan att ytterligare jobbkörningar startar medan du gör ändringarna. Aktuella körningar eller körningar som utlöses av Kör nu påverkas inte. Mer information finns i Pausa och återuppta ett jobbschema.
Jobb-API-slutpunkter verifierar körnings-ID
15-21 juli 2020: Version 3.24
jobs/runs/cancel API-slutpunkterna och jobs/runs/output verifierar nu att parametern run_id är giltig. För ogiltiga parametrar returnerar dessa API-slutpunkter nu HTTP-statuskod 400 i stället för kod 500.
Microsoft Entra ID-token för att auktorisera till Databricks REST API GA
15-21 juli 2020: Version 3.24
Det är nu allmänt tillgängligt att använda Microsoft Entra-ID-token för att autentisera till API:et för arbetsyta. Med Microsoft Entra ID-token kan du automatisera skapandet och installationen av nya arbetsytor. Tjänstens huvudnamn är programobjekt i Microsoft Entra-ID. Du kan också använda tjänstens huvudnamn på dina Azure Databricks-arbetsytor för att automatisera arbetsflöden. Mer information finns i Microsoft Entra ID-token (tidigare Azure Active Directory).
Formatera SQL i notebooks automatiskt
15-21 juli 2020: Version 3.24
Nu kan du formatera SQL Notebook-celler från ett kortkommando, snabbmenyn för kommandot och anteckningsbokens redigera-meny (välj Redigera > format för SQL-celler). SQL-formatering gör det enkelt att läsa och underhålla kod med liten ansträngning. Det fungerar både för SQL-notebook-filer och %sql celler.

Reproducerbar installationsordning för Maven- och CRAN-bibliotek
1-9 juli 2020: Version 3.23
Azure Databricks bearbetar nu Maven- och CRAN-bibliotek i den ordning de installerades i klustret.
Ta kontroll över användarnas personliga åtkomsttoken med API för tokenhantering (offentlig förhandsversion)
1-9 juli 2020: Version 3.23
Nu kan Azure Databricks-administratörer använda API:et för tokenhantering för att hantera användarnas personliga åtkomsttoken för Azure Databricks:
- Övervaka och återkalla användarnas personliga åtkomsttoken.
- Kontrollera livslängden för framtida token på din arbetsyta.
- Kontrollera vilka användare som kan skapa och använda token.
Se Övervaka och hantera personliga åtkomsttoken.
Återställ urklippta notebook-celler
1-9 juli 2020: Version 3.23
Nu kan du återställa notebook-celler som har klippts ut antingen med hjälp av kortkommandot (Z) eller genom att välja Redigera > Ångra klipp ut celler. Den här funktionen motsvarar den för att ångra borttagna celler.
Tilldela jobb KAN HANTERA behörighet till icke-administratörsanvändare
1-9 juli 2020: Version 3.23
Nu kan du tilldela icke-administratörsanvändare och grupper behörigheten CAN MANAGE för jobb. Med den här behörighetsnivån kan användare hantera alla inställningar för jobbet, inklusive att tilldela behörigheter, ändra ägare och ändra klusterkonfigurationen (till exempel lägga till bibliotek och ändra klusterspecifikationen). Se Kontrollera åtkomst till ett jobb.
Azure Databricks-användare som inte är administratörer kan visa och filtrera efter användarnamn med hjälp av SCIM-API:et
1-9 juli 2020: Version 3.23
Icke-administratörsanvändare kan nu visa användarnamn och filtrera användare efter användarnamn med hjälp av SLUTpunkten SCIM/Användare.
Länk för att visa klusterspecifikation när du visar jobbkörningsinformation
1-9 juli 2020: Version 3.23
Nu när du visar information om en jobbkörning kan du klicka på en länk till klusterkonfigurationssidan för att visa klusterspecifikationen. Tidigare skulle du behöva kopiera jobb-ID:t från URL:en och gå till klusterlistan för att söka efter det.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för