Skapa ett SQL-lager
Arbetsyteadministratörer och tillräckligt privilegierade användare kan konfigurera och hantera SQL-lager. Den här artikeln beskriver hur du skapar, redigerar och övervakar befintliga SQL-lager.
Du kan också skapa SQL-lager med hjälp av SQL Warehouse-API:et eller Terraform.
Databricks rekommenderar att du använder serverlösa SQL-lager när det är tillgängligt.
Kommentar
De flesta användare kan inte skapa SQL-lager, men kan starta om alla SQL-lager som de kan ansluta till. Se Vad är ett SQL-lager?.
Krav
SQL-lager har följande krav:
Om du vill skapa ett SQL-lager måste du vara arbetsyteadministratör eller användare med obegränsad behörighet att skapa kluster.
Innan du kan skapa ett serverlöst SQL-lager i en region som stöder funktionen kan det finnas nödvändiga steg. Se Aktivera serverlösa SQL-lager.
För klassiska eller pro SQL-lager måste ditt Azure-konto ha tillräcklig vCPU-kvot. Standardkvoten för vCPU är vanligtvis tillräcklig för att skapa ett serverlöst SQL-lager, men kanske inte räcker för att skala SQL-lagret eller för att skapa ytterligare lager. Se Nödvändig Azure vCPU-kvot för klassiska och pro SQL-lager. Du kan begära ytterligare vCPU-kvot. Ditt Azure-konto kan ha begränsningar för hur mycket vCPU-kvot du kan begära. Kontakta ditt Azure-kontoteam om du vill ha mer information.
Skapa ett SQL-lager
Så här skapar du ett SQL-lager med hjälp av webbgränssnittet:
- Klicka på SQL Warehouses i sidofältet.
- Klicka på Skapa SQL Warehouse.
- Ange ett namn för lagret.
- (Valfritt) Konfigurera lagerinställningar. Se Konfigurera INSTÄLLNINGAR för SQL-lager.
- (Valfritt) Konfigurera avancerade alternativ. Se Avancerade alternativ.
- Klicka på Skapa.
- (Valfritt) Konfigurera åtkomst till SQL-informationslagret. Se Hantera ett SQL-lager.
Det skapade lagret startar automatiskt.
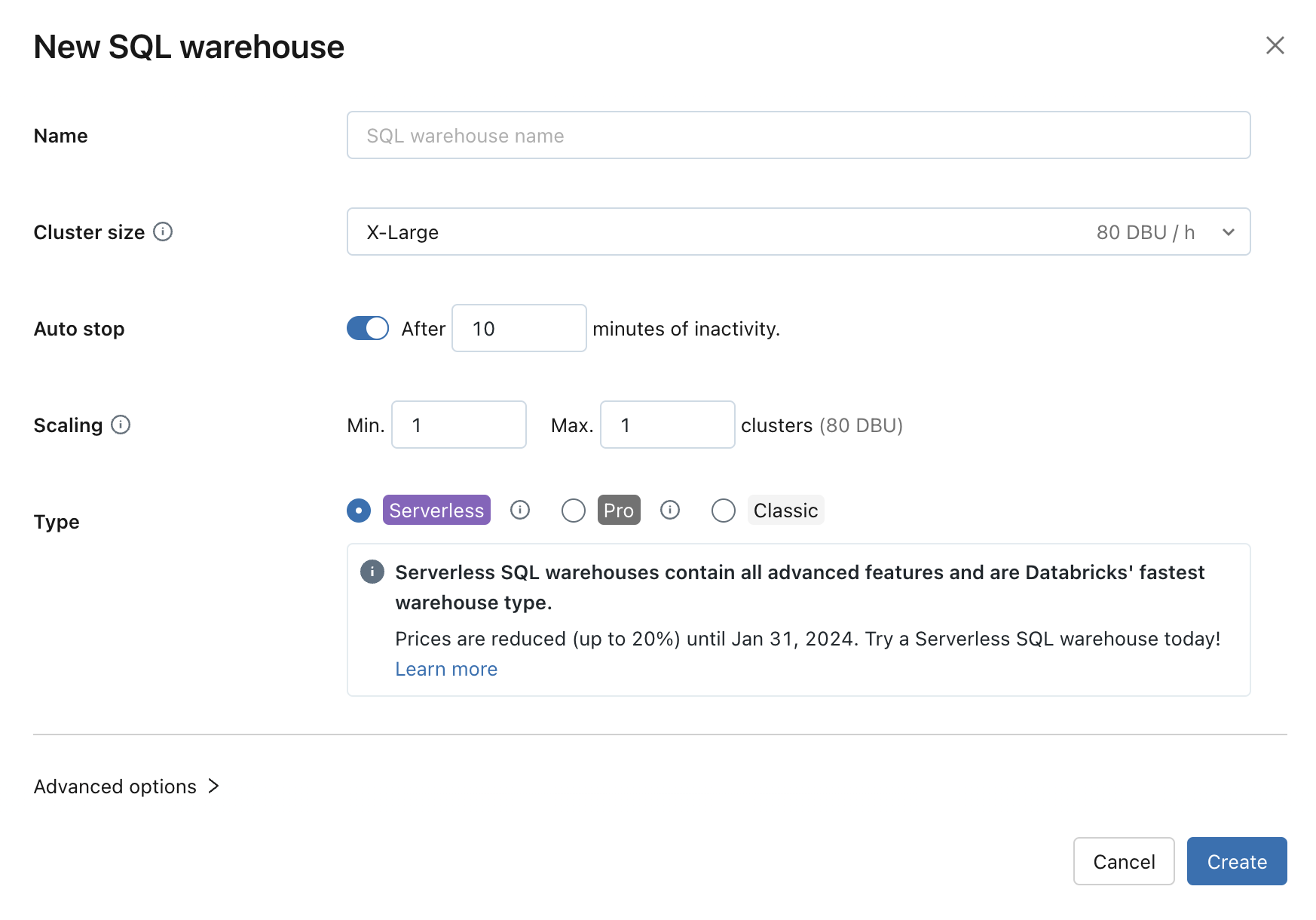
Konfigurera SQL Warehouse-inställningar
Du kan ändra följande inställningar när du skapar eller redigerar ett SQL-lager:
Klusterstorlek representerar storleken på drivrutinsnoden och antalet arbetsnoder som är associerade med klustret. Standardvärdet är X-Large. Öka storleken om du vill minska frågefördröjningen.
Automatisk stopp avgör om lagret stoppas om det är inaktivt under det angivna antalet minuter. Inaktiva SQL-lager fortsätter att ackumulera DBU- och molninstansavgifter tills de stoppas.
- Pro och klassiska SQL-lager: Standardvärdet är 45 minuter, vilket rekommenderas för vanlig användning. Minst 10 minuter.
- Serverlösa SQL-lager: Standardvärdet är 10 minuter, vilket rekommenderas för vanlig användning. Minst 5 minuter när du använder användargränssnittet. Observera att du kan skapa ett serverlöst SQL-lager med hjälp av SQL Warehouses-API:et, i vilket fall du kan ange värdet För automatisk stopp så lågt som 1 minut.
Skalning anger det lägsta och högsta antalet kluster som ska användas för en fråga. Standardvärdet är ett minimum och högst ett kluster. Du kan öka maximalt antal kluster om du vill hantera fler samtidiga användare för en viss fråga. Azure Databricks rekommenderar ett kluster för varje 10 samtidiga frågor.
För att upprätthålla optimala prestanda återvinner Databricks regelbundet kluster. Under en återanvändningsperiod kan du tillfälligt se ett klusterantal som överskrider det maximala antalet när Databricks övergår nya arbetsbelastningar till det nya klustret och väntar på att återvinna det gamla klustret tills alla öppna arbetsbelastningar har slutförts.
Typ avgör typ av lager. Om serverlös är aktiverat på ditt konto är serverlös standardinställningen. Se SQL-lagertyper för listan.
Avancerade alternativ
Konfigurera följande avancerade alternativ genom att expandera området Avancerade alternativ när du skapar ett nytt SQL-lager eller redigerar ett befintligt SQL-lager. Du kan också konfigurera dessa alternativ med hjälp av SQL Warehouse-API:et.
Taggar: Med taggar kan du övervaka kostnaden för molnresurser som används av användare och grupper i din organisation. Du anger taggar som nyckel/värde-par.
Unity Catalog: Om Unity Catalog är aktiverat för arbetsytan är det standard för alla nya lager på arbetsytan. Om Unity Catalog inte är aktiverat för din arbetsyta ser du inte det här alternativet. Se Vad är Unity Catalog?.
Kanal: Använd förhandsgranskningskanalen för att testa nya funktioner, inklusive dina frågor och instrumentpaneler, innan den blir Databricks SQL-standard.
Viktig information innehåller en lista över vad som finns i den senaste förhandsversionen.
Viktigt!
Databricks rekommenderar att du inte använder en förhandsversion för produktionsarbetsbelastningar. Eftersom endast arbetsyteadministratörer kan visa ett lagers egenskaper, inklusive dess kanal, bör du överväga att ange att ett Databricks SQL-lager använder en förhandsversion i informationslagrets namn för att hindra användare från att använda det för produktionsarbetsbelastningar.
Hantera ett SQL-lager
Administratörer och användningar av arbetsytor med CAN MANAGE-behörigheter i ett SQL-lager kan utföra följande uppgifter i ett befintligt SQL-lager:
- Om du vill stoppa ett lager som körs klickar du på stoppikonen bredvid lagret.
- Om du vill starta ett stoppat lager klickar du på startikonen bredvid lagret.
- Om du vill redigera ett lager klickar du på menyn för kebab
 och klickar sedan på Redigera.
och klickar sedan på Redigera. - Om du vill lägga till och redigera behörigheter klickar du på menyn för kebab och klickar sedan på Behörigheter. Mer information om behörighetsnivåer finns i ACL:er för SQL-lager.
- Om du vill uppgradera ett SQL-lager till serverlöst klickar du på menyn för kebab och klickar sedan på Uppgradera till Serverlös.
- Om du vill ta bort ett lager klickar du på menyn för kebab och klickar sedan på Ta bort.
Kommentar
Kontakta din Databricks-representant för att återställa ett borttaget lager inom 14 dagar.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för