Använda Microsoft Cognitive Toolkit-djupinlärningsmodell med Azure HDInsight Spark-kluster
I den här artikeln utför du följande steg.
Kör ett anpassat skript för att installera Microsoft Cognitive Toolkit på ett Azure HDInsight Spark-kluster.
Ladda upp en Jupyter Notebook till Apache Spark-klustret för att se hur du använder en tränad Microsoft Cognitive Toolkit-djupinlärningsmodell för filer i ett Azure Blob Storage-konto med hjälp av Spark Python API (PySpark)
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Se Skapa ett Apache Spark-kluster.
Kunskaper om Jupyter Notebooks med Spark på HDInsight. Mer information finns i Läsa in data och köra frågor med Apache Spark i HDInsight.
Hur flödar den här lösningen?
Den här lösningen är uppdelad mellan den här artikeln och en Jupyter Notebook som du laddar upp som en del av den här artikeln. I den här artikeln slutför du följande steg:
- Kör en skriptåtgärd i ett HDInsight Spark-kluster för att installera Microsoft Cognitive Toolkit- och Python-paket.
- Ladda upp Jupyter Notebook som kör lösningen till HDInsight Spark-klustret.
Följande återstående steg beskrivs i Jupyter Notebook.
- Läs in exempelbilder i en Spark Resilient Distributed Dataset eller RDD.
- Läs in moduler och definiera förinställningar.
- Ladda ned datauppsättningen lokalt i Spark-klustret.
- Konvertera datamängden till en RDD.
- Poängsätta bilderna med hjälp av en tränad Cognitive Toolkit-modell.
- Ladda ned den tränade Cognitive Toolkit-modellen till Spark-klustret.
- Definiera funktioner som ska användas av arbetsnoder.
- Poängsätta bilderna på arbetsnoder.
- Utvärdera modellens noggrannhet.
Installera Microsoft Cognitive Toolkit
Du kan installera Microsoft Cognitive Toolkit på ett Spark-kluster med hjälp av skriptåtgärd. Skriptåtgärden använder anpassade skript för att installera komponenter i klustret som inte är tillgängliga som standard. Du kan använda det anpassade skriptet från Azure-portalen med hjälp av HDInsight .NET SDK eller med hjälp av Azure PowerShell. Du kan också använda skriptet för att installera verktygslådan antingen som en del av klusterskapandet eller när klustret är igång.
I den här artikeln använder vi portalen för att installera verktygslådan när klustret har skapats. Andra sätt att köra det anpassade skriptet finns i Anpassa HDInsight-kluster med hjälp av skriptåtgärd.
Med hjälp av Azure-portalen
Anvisningar om hur du använder Azure-portalen för att köra skriptåtgärder finns i Anpassa HDInsight-kluster med hjälp av skriptåtgärd. Se till att du anger följande indata för att installera Microsoft Cognitive Toolkit. Använd följande värden för skriptåtgärden:
| Property | Värde |
|---|---|
| Typ av skript | -Anpassade |
| Name | Installera MCT |
| Bash-skript-URI | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| Nodtyper: | Head, Worker |
| Parametrar | Ingen |
Ladda upp Jupyter Notebook till Azure HDInsight Spark-kluster
Om du vill använda Microsoft Cognitive Toolkit med Azure HDInsight Spark-klustret måste du läsa in Jupyter Notebook-CNTK_model_scoring_on_Spark_walkthrough.ipynb till Azure HDInsight Spark-klustret. Den här notebook-filen är tillgänglig på GitHub på https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Ladda ned och packa upp https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Från en webbläsare går du till
https://CLUSTERNAME.azurehdinsight.net/jupyter, därCLUSTERNAMEär namnet på klustret.I Jupyter Notebook väljer du Ladda upp i det övre högra hörnet och navigerar sedan till nedladdningen och väljer filen
CNTK_model_scoring_on_Spark_walkthrough.ipynb.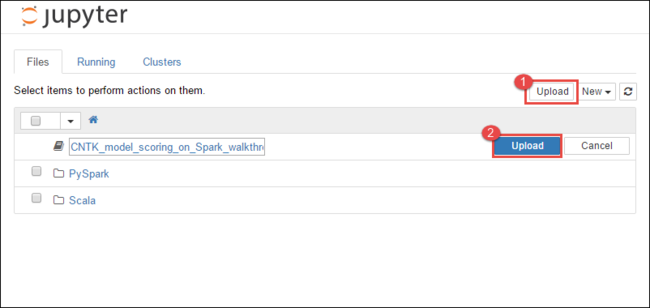
Välj Ladda upp igen.
När notebook-filen har laddats upp klickar du på namnet på anteckningsboken och följer sedan anvisningarna i själva notebook-filen om hur du läser in datauppsättningen och utför artikeln.
Se även
Scenarier
- Apache Spark med BI: Utföra interaktiv dataanalys med Spark i HDInsight med BI-verktyg
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att analysera byggnadstemperaturen med hjälp av HVAC-data
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att förutsäga resultat av livsmedelsinspektion
- Analys av webbplatsloggar med Apache Spark i HDInsight
- Application Insight-telemetridataanalys med Apache Spark i HDInsight
Skapa och köra program
- Skapa ett fristående program med hjälp av Scala
- Köra jobb via fjärranslutning på ett Apache Spark-kluster med hjälp av Apache Livy
Verktyg och tillägg
- Använda HDInsight Tools-plugin för IntelliJ IDEA till att skapa och skicka Spark Scala-appar
- Använda HDInsight Tools-plugin-programmet för IntelliJ IDEA för att fjärrsöka Apache Spark-program
- Använda Apache Zeppelin-notebook-filer med ett Apache Spark-kluster i HDInsight
- Kernels tillgängliga för Jupyter Notebook i Apache Spark-kluster för HDInsight
- Använda externa paket med Jupyter Notebooks
- Installera Jupyter på datorn och ansluta till ett HDInsight Spark-kluster