Hantera Python-miljön i Azure HDInsight på ett säkert sätt med skriptåtgärd
HDInsight har två inbyggda Python-installationer i Spark-klustret, Anaconda Python 2.7 och Python 3.5. Kunder kan behöva anpassa Python-miljön som att installera externa Python-paket. Här visar vi bästa praxis för att på ett säkert sätt hantera Python-miljöer för Apache Spark-kluster i HDInsight.
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight. Om du inte redan har ett Spark-kluster i HDInsight kan du köra skriptåtgärder när klustret skapas. Gå till dokumentationen om hur du använder anpassade skriptåtgärder.
Stöd för programvara med öppen källkod som används i HDInsight-kluster
Microsoft Azure HDInsight-tjänsten använder en miljö med tekniker med öppen källkod som bildas runt Apache Hadoop. Microsoft Azure tillhandahåller en allmän supportnivå för tekniker med öppen källkod. Mer information finns på webbplatsen för Vanliga frågor och svar om Azure-support. HDInsight-tjänsten ger ytterligare stöd för inbyggda komponenter.
Det finns två typer av komponenter med öppen källkod som är tillgängliga i HDInsight-tjänsten:
| Komponent | beskrivning |
|---|---|
| Inbyggd | Dessa komponenter är förinstallerade i HDInsight-kluster och tillhandahåller kärnfunktioner i klustret. Till exempel tillhör Apache Hadoop YARN Resource Manager, Apache Hive-frågespråket (HiveQL) och Mahout-biblioteket den här kategorin. En fullständig lista över klusterkomponenter finns i Nyheter i Apache Hadoop-klusterversionerna som tillhandahålls av HDInsight. |
| Anpassat | Som användare av klustret kan du installera eller använda valfri komponent i communityn eller skapad av dig i din arbetsbelastning. |
Viktigt!
Komponenter som medföljer HDInsight-klustret stöds fullt ut. Microsoft Support hjälper till att isolera och lösa problem som rör dessa komponenter.
Anpassade komponenter får kommersiellt rimligt stöd för att hjälpa dig att ytterligare felsöka problemet. Microsofts support kanske kan lösa problemet eller så kan de be dig att engagera tillgängliga kanaler för öppen källkod tekniker där djup expertis för den tekniken finns. Det finns till exempel många community-webbplatser som kan användas, till exempel: Microsoft Q&A-frågesida för HDInsight, https://stackoverflow.com. Apache-projekt har också projektwebbplatser på https://apache.org.
Förstå standardinstallationen av Python
HDInsight Spark-kluster har Anaconda installerat. Det finns två Python-installationer i klustret, Anaconda Python 2.7 och Python 3.5. I följande tabell visas standardinställningarna för Python för Spark, Livy och Jupyter.
| Inställning | Python 2.7 | Python 3.5 |
|---|---|---|
| Sökväg | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Spark-version | Standardinställningen är 2,7 | Kan ändra konfiguration till 3.5 |
| Livy-version | Standardinställningen är 2,7 | Kan ändra konfiguration till 3.5 |
| Jupyter | PySpark-kernel | PySpark3-kernel |
För Spark 3.1.2-versionen tas Apache PySpark-kerneln bort och en ny Python 3.8-miljö installeras under /usr/bin/miniforge/envs/py38/bin, som används av PySpark3-kerneln. Miljövariablerna PYSPARK_PYTHON och PYSPARK3_PYTHON uppdateras med följande:
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
Installera externa Python-paket på ett säkert sätt
HDInsight-klustret är beroende av den inbyggda Python-miljön, både Python 2.7 och Python 3.5. Direkt installation av anpassade paket i de inbyggda standardmiljöerna kan orsaka oväntade ändringar i biblioteksversionen. Och dela upp klustret ytterligare. Följ stegen för att installera anpassade externa Python-paket för dina Spark-program på ett säkert sätt.
Skapa en virtuell Python-miljö med hjälp av conda. En virtuell miljö ger ett isolerat utrymme för dina projekt utan att bryta andra. När du skapar den virtuella Python-miljön kan du ange den Python-version som du vill använda. Du behöver fortfarande skapa en virtuell miljö även om du vill använda Python 2.7 och 3.5. Det här kravet är att se till att klustrets standardmiljö inte blir trasig. Kör skriptåtgärder i klustret för alla noder med följande skript för att skapa en virtuell Python-miljö.
--prefixanger en sökväg där en virtuell conda-miljö finns. Det finns flera konfigurationer som behöver ändras ytterligare baserat på sökvägen som anges här. I det här exemplet använder vi py35new eftersom klustret redan har en befintlig virtuell miljö med namnet py35.python=anger Python-versionen för den virtuella miljön. I det här exemplet använder vi version 3.5, samma version som klustret som är inbyggt i ett. Du kan också använda andra Python-versioner för att skapa den virtuella miljön.anacondaanger package_spec som anaconda för att installera Anaconda-paket i den virtuella miljön.
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yesInstallera externa Python-paket i den skapade virtuella miljön om det behövs. Kör skriptåtgärder i klustret för alla noder med följande skript för att installera externa Python-paket. Du måste ha sudo-behörighet här för att kunna skriva filer till mappen för den virtuella miljön.
Sök i paketindexet efter den fullständiga listan över paket som är tillgängliga. Du kan också hämta en lista över tillgängliga paket från andra källor. Du kan till exempel installera paket som görs tillgängliga via conda-forge.
Använd följande kommando om du vill installera ett bibliotek med den senaste versionen:
Använd conda-kanal:
seabornär det paketnamn som du vill installera.-n py35newange namnet på den virtuella miljön som bara skapas. Se till att ändra namnet på motsvarande sätt baserat på hur du skapar den virtuella miljön.
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yesEller använd PyPi-lagringsplats, ändra
seabornochpy35newpå motsvarande sätt:sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
Använd följande kommando om du vill installera ett bibliotek med en viss version:
Använd conda-kanal:
numpy=1.16.1är paketnamnet och versionen som du vill installera.-n py35newange namnet på den virtuella miljön som bara skapas. Se till att ändra namnet på motsvarande sätt baserat på hur du skapar den virtuella miljön.
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yesEller använd PyPi-lagringsplats, ändra
numpy==1.16.1ochpy35newpå motsvarande sätt:sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
Om du inte känner till namnet på den virtuella miljön kan du SSH till huvudnoden i klustret och köra
/usr/bin/anaconda/bin/conda info -eför att visa alla virtuella miljöer.Ändra Spark- och Livy-konfigurationer och peka på den skapade virtuella miljön.
Öppna Ambari-användargränssnittet, gå till Spark 2-sidan, fliken Konfigurationer.
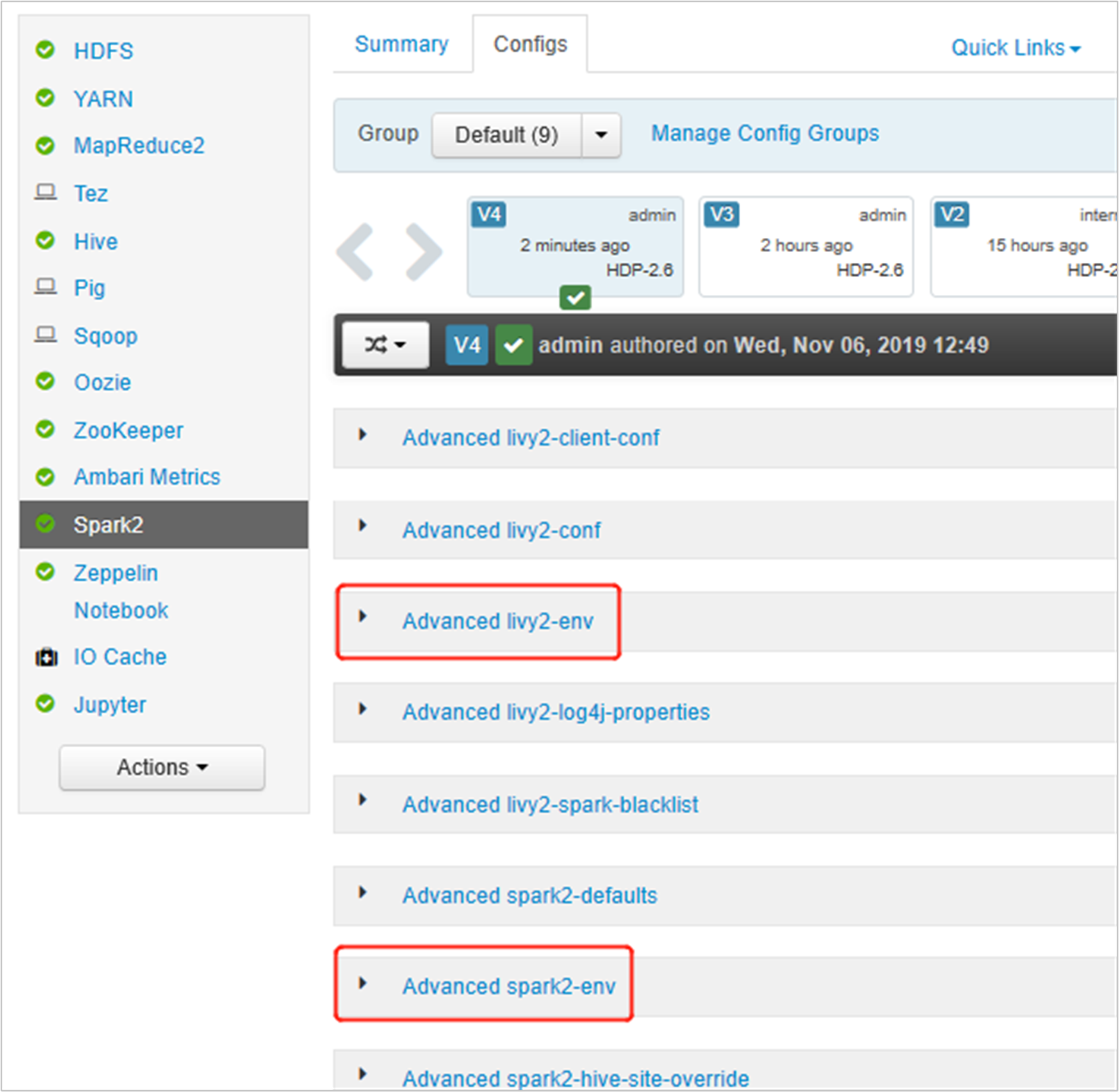
Expandera Advanced livy2-env och lägg till följande instruktioner längst ned. Om du har installerat den virtuella miljön med ett annat prefix ändrar du sökvägen på motsvarande sätt.
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python
Expandera Advanced spark2-env och ersätt den befintliga export-PYSPARK_PYTHON-instruktionen längst ned. Om du har installerat den virtuella miljön med ett annat prefix ändrar du sökvägen på motsvarande sätt.
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}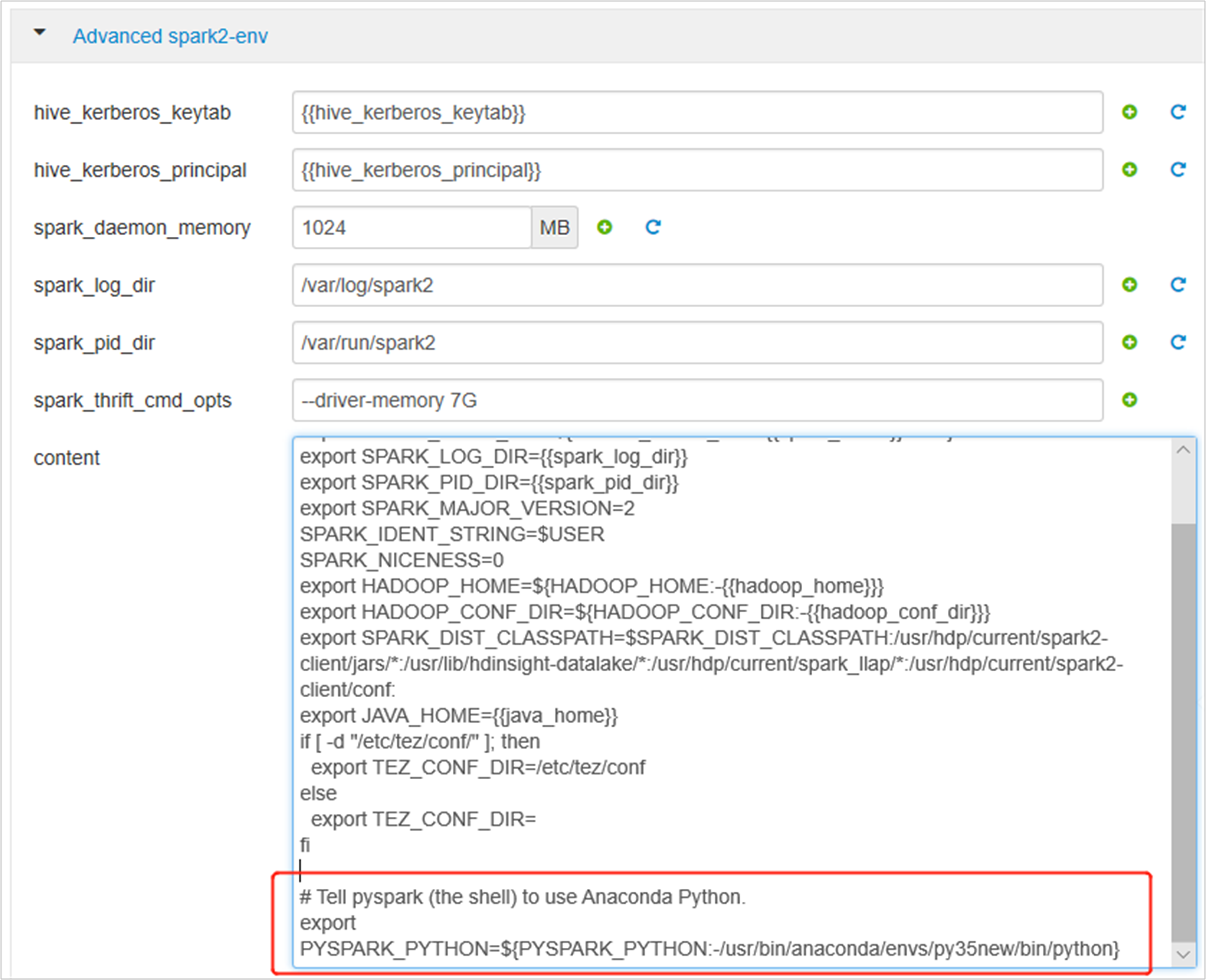
Spara ändringarna och starta om de tjänster som påverkas. Dessa ändringar behöver startas om av Spark 2-tjänsten. Ambari-användargränssnittet uppmanar till en obligatorisk omstartspåminnelse, klickar på Starta om för att starta om alla berörda tjänster.

Ange två egenskaper för Spark-sessionen för att säkerställa att jobbet pekar på den uppdaterade Spark-konfigurationen:
spark.yarn.appMasterEnv.PYSPARK_PYTHONochspark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON.Använd funktionen med hjälp av terminalen eller en notebook-fil
spark.conf.set.spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")Om du använder
livylägger du till följande egenskaper i begärandetexten:"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
Om du vill använda den nya skapade virtuella miljön på Jupyter. Ändra Jupyter-konfigurationer och starta om Jupyter. Kör skriptåtgärder på alla huvudnoder med följande instruktion för att peka Jupyter till den nya skapade virtuella miljön. Se till att ändra sökvägen till det prefix som du har angett för den virtuella miljön. När du har kört den här skriptåtgärden startar du om Jupyter-tjänsten via Ambari-användargränssnittet för att göra den här ändringen tillgänglig.
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.jsonDu kan dubbel bekräfta Python-miljön i Jupyter Notebook genom att köra koden: