Felsöka Apache Spark med Azure HDInsight
Lär dig mer om de viktigaste problemen och deras lösningar när du arbetar med Apache Spark-nyttolaster i Apache Ambari.
Hur gör jag för att konfigurera ett Apache Spark-program med Apache Ambari i kluster?
Spark-konfigurationsvärden kan justeras för att undvika ett Apache Spark-programfel OutofMemoryError . Följande steg visar standardvärden för Spark-konfiguration i Azure HDInsight:
Logga in på Ambari på
https://CLUSTERNAME.azurehdidnsight.netmed dina autentiseringsuppgifter för klustret. Den första skärmen visar en översiktsinstrumentpanel. Det finns små kosmetiska skillnader mellan HDInsight 4.0.Gå till Spark2-konfigurationer>.
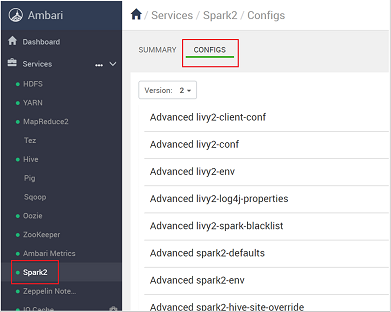
I listan med konfigurationer väljer du och expanderar Custom-spark2-defaults.
Leta efter den värdeinställning som du behöver justera, till exempel spark.executor.memory. I det här fallet är värdet på 9728 m för högt.
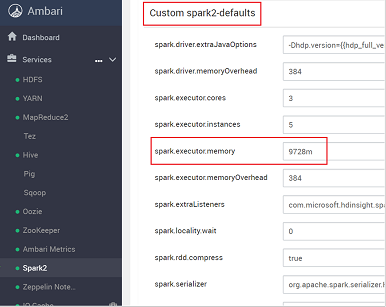
Ange värdet till den rekommenderade inställningen. Värdet 2048m rekommenderas för den här inställningen.
Spara värdet och spara sedan konfigurationen. Välj Spara.
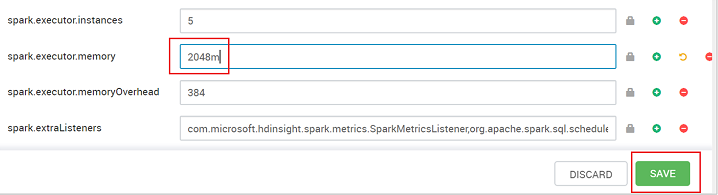
Skriv en anteckning om konfigurationsändringarna och välj sedan Spara.
Du får ett meddelande om några konfigurationer behöver åtgärdas. Anteckna objekten och välj sedan Fortsätt ändå.

När en konfiguration sparas uppmanas du att starta om tjänsten. Välj Starta om.
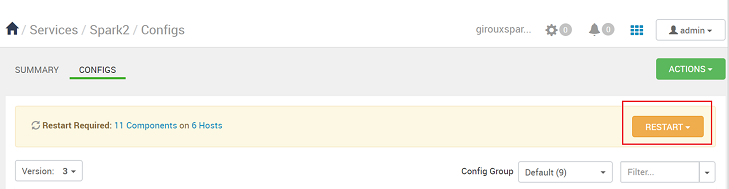
Bekräfta omstarten.
Du kan granska de processer som körs.
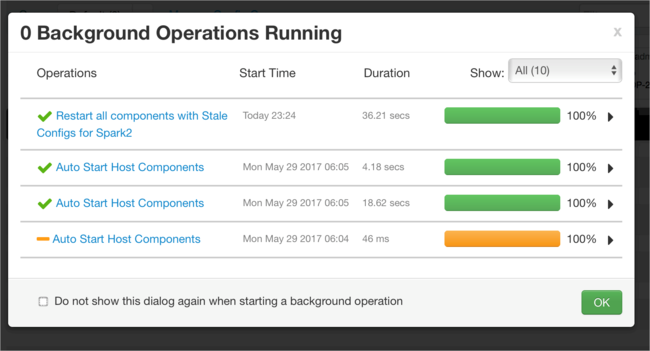
Du kan lägga till konfigurationer. I listan med konfigurationer väljer du Custom-spark2-defaults och sedan Lägg till egenskap.
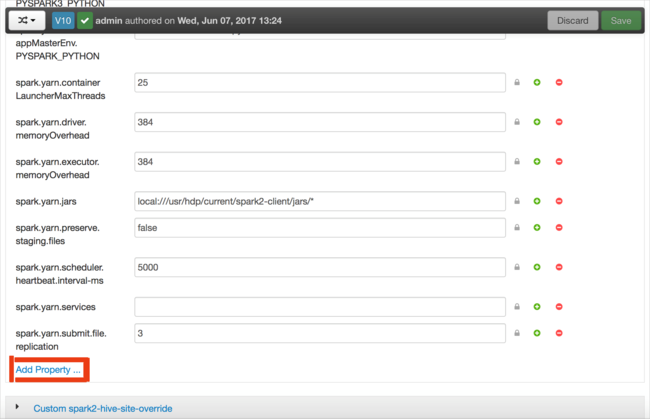
Definiera en ny egenskap. Du kan definiera en enskild egenskap med hjälp av en dialogruta för specifika inställningar, till exempel datatypen. Eller så kan du definiera flera egenskaper med hjälp av en definition per rad.
I det här exemplet definieras egenskapen spark.driver.memory med värdet 4g.
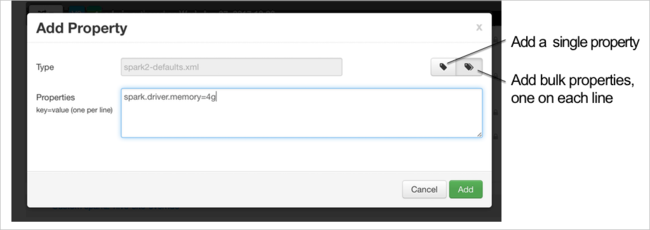
Spara konfigurationen och starta sedan om tjänsten enligt beskrivningen i steg 6 och 7.
De här ändringarna är klusteromfattande men kan åsidosättas när du skickar Spark-jobbet.
Hur gör jag för att konfigurera ett Apache Spark-program med hjälp av en Jupyter Notebook i kluster?
I den första cellen i Jupyter Notebook anger du Spark-konfigurationerna i giltigt JSON-format efter %%configure-direktivet . Ändra de faktiska värdena efter behov:

Hur gör jag för att konfigurera ett Apache Spark-program med Apache Livy i kluster?
Skicka Spark-programmet till Livy med hjälp av en REST-klient som cURL. Använd ett kommando som liknar följande. Ändra de faktiska värdena efter behov:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Hur gör jag för att konfigurera ett Apache Spark-program med spark-submit i kluster?
Starta spark-shell med ett kommando som liknar följande. Ändra det faktiska värdet för konfigurationerna efter behov:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Extra läsning
Apache Spark-jobböverföring i HDInsight-kluster
Nästa steg
Om du inte ser problemet eller inte kan lösa problemet går du till någon av följande kanaler för mer support:
Översikt över Spark-minneshantering.
Få svar från Azure-experter via Azure Community Support.
Anslut med @AzureSupport – det officiella Microsoft Azure-kontot för att förbättra kundupplevelsen. Anslut azure-communityn till rätt resurser: svar, support och experter.
Om du behöver mer hjälp kan du skicka en supportbegäran från Azure-portalen. Välj Support i menyraden eller öppna hubben Hjälp + support . Mer detaljerad information finns i Skapa en Azure-supportbegäran. Tillgång till support för prenumerationshantering och fakturering ingår i din Microsoft Azure-prenumeration och teknisk support ges via ett supportavtal för Azure.