Utvärdera modellkomponent
I den här artikeln beskrivs en komponent i Azure Machine Learning-designern.
Använd den här komponenten för att mäta noggrannheten för en tränad modell. Du anger en datamängd som innehåller poäng som genererats från en modell och komponenten Utvärdera modell beräknar en uppsättning utvärderingsmått av branschstandard.
De mått som returneras av Utvärdera modell beror på vilken typ av modell du utvärderar:
- Klassificeringsmodeller
- Regressionsmodeller
- Klustringsmodeller
Dricks
Om du är nybörjare på modellutvärdering rekommenderar vi videoserien av Dr Stephen Elston som en del av maskininlärningskursen från EdX.
Så här använder du Utvärdera modell
AnslutPoängsatta datauppsättningsutdata från resultatmodell- eller resultatdatauppsättningens utdata från Tilldela data till kluster till den vänstra indataporten för Utvärdera modell.
Kommentar
Om du använder komponenter som "Välj kolumner i datauppsättning" för att välja en del av indatauppsättningen kontrollerar du att kolumnen Faktisk etikett (används i träning), kolumnen "Poängsatta sannolikheter" och kolumnen "Poängsatta etiketter" finns för att beräkna mått som AUC, noggrannhet för binär klassificering/avvikelseidentifiering. Kolumnen "Poängsatta etiketter" finns för att beräkna mått för klassificering/regression i flera klasser. Kolumnen Tilldelningar, kolumnerna "DistancesToClusterCenter no.X" (X är centroidindex, från 0, ..., Antal centroider-1) finns för att beräkna mått för klustring.
Viktigt!
- För att utvärdera resultaten bör utdatauppsättningen innehålla specifika poängkolumnnamn som uppfyller komponentkraven för Utvärdera modell.
- Kolumnen
Labelsbetraktas som faktiska etiketter. - För regressionsaktivitet måste datauppsättningen som ska utvärderas ha en kolumn med namnet
Regression Scored Labels, som representerar poängsatta etiketter. - För binär klassificeringsaktivitet måste datauppsättningen som ska utvärderas ha två kolumner med namnet
Binary Class Scored Labels,Binary Class Scored Probabilities, som representerar poängsatta etiketter respektive sannolikheter. - För uppgift med flera klassificeringar måste datauppsättningen som ska utvärderas ha en kolumn med namnet
Multi Class Scored Labels, som representerar poängsatta etiketter. Om utdata från den överordnade komponenten inte har dessa kolumner måste du ändra enligt kraven ovan.
[Valfritt] AnslutPoängsatta datamängdsutdata från resultatdatauppsättningens utdata för poängmodellen eller resultatuppsättningen för tilldelning av data till kluster för den andra modellen till rätt indataport för Utvärdera modell. Du kan enkelt jämföra resultat från två olika modeller på samma data. De två indataalgoritmerna ska vara av samma algoritmtyp. Eller så kan du jämföra poäng från två olika körningar över samma data med olika parametrar.
Kommentar
Algoritmtypen refererar till "Klassificering med två klasser", "Klassificering av flera klasser", "Regression", "Klustring" under "Maskininlärningsalgoritmer".
Skicka pipelinen för att generera utvärderingspoängen.
Resultat
När du har kört Utvärdera modell väljer du komponenten för att öppna navigeringspanelen Utvärdera modell till höger. Välj sedan fliken Utdata + loggar och på den fliken har avsnittet Datautdata flera ikoner. Ikonen Visualisera har en stapeldiagramikon och är ett första sätt att se resultatet.
När du har klickat på Visualisera-ikonen för binär klassificering kan du visualisera den binära förvirringsmatrisen. För flera klassificeringar kan du hitta felmatrisritningsfilen under fliken Utdata + loggar på följande sätt:
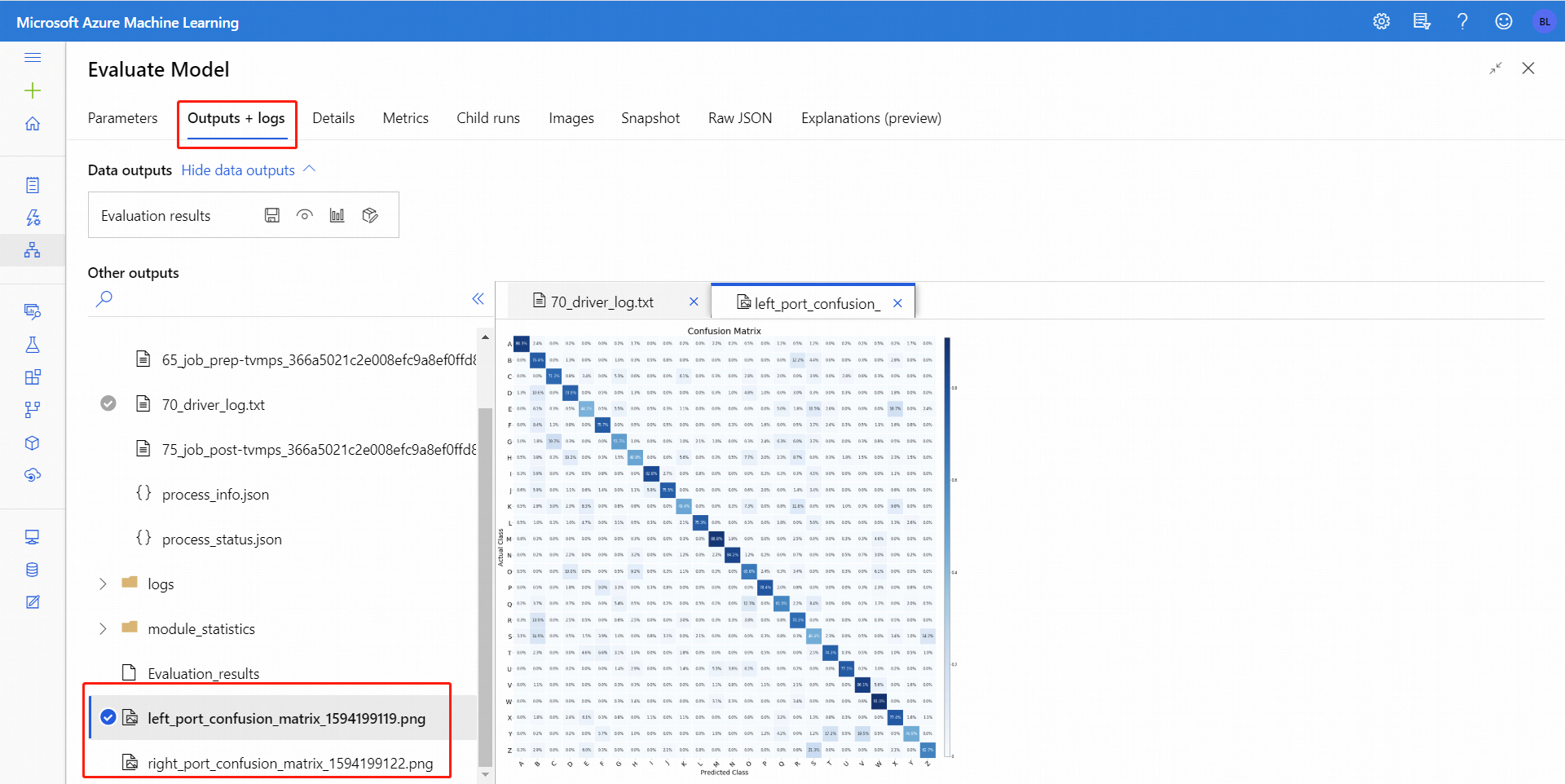
Om du ansluter datauppsättningar till båda indata i Utvärdera modell innehåller resultaten mått för båda datauppsättningarna eller båda modellerna. Modellen eller data som är kopplade till den vänstra porten visas först i rapporten, följt av måtten för datamängden eller modellen som är kopplad till den högra porten.
Följande bild representerar till exempel en jämförelse av resultat från två klustringsmodeller som byggdes på samma data, men med olika parametrar.
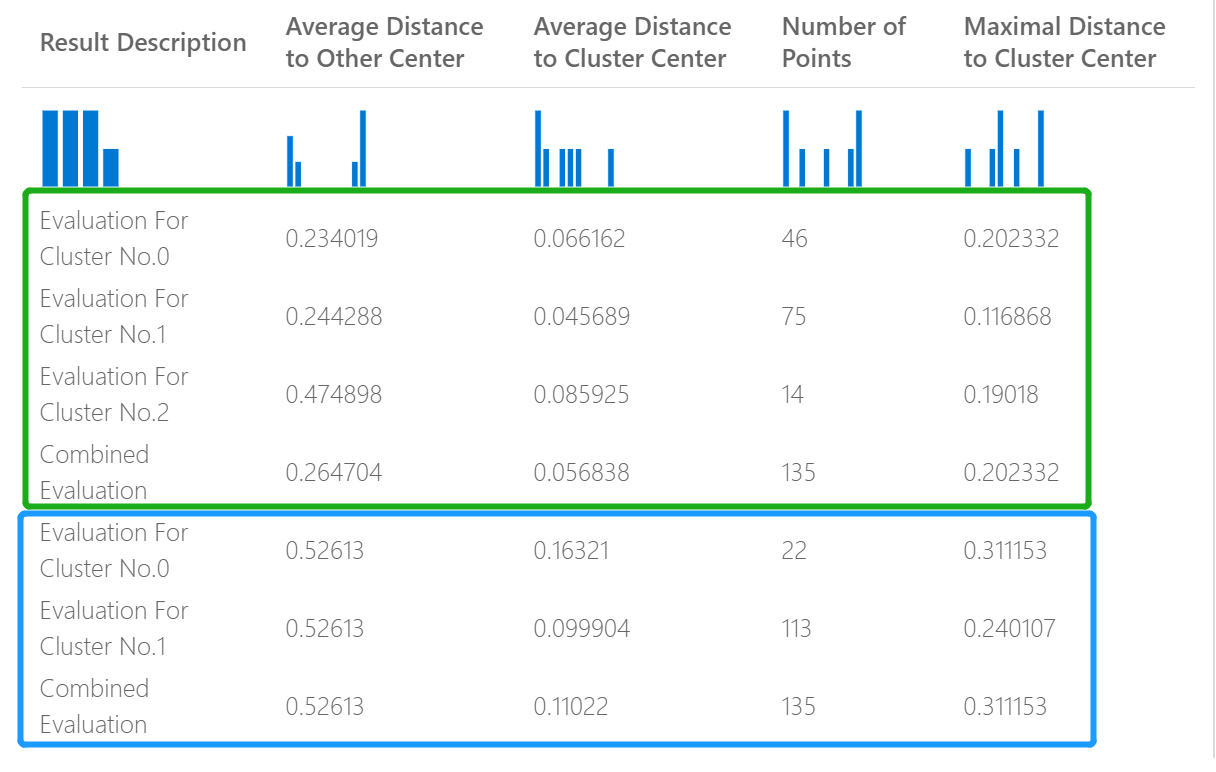
Eftersom det här är en klustringsmodell skiljer sig utvärderingsresultaten från om du jämför poäng från två regressionsmodeller eller jämför två klassificeringsmodeller. Den övergripande presentationen är dock densamma.
Mått
I det här avsnittet beskrivs de mått som returneras för de specifika typer av modeller som stöds för användning med Utvärdera modell:
Mått för klassificeringsmodeller
Följande mått rapporteras vid utvärdering av binära klassificeringsmodeller.
Noggrannhet mäter hur bra en klassificeringsmodell är som andelen sanna resultat till totalt antal fall.
Precision är andelen sanna resultat för alla positiva resultat. Precision = TP/(TP+FP)
Recall är bråkdelen av den totala mängden relevanta instanser som faktiskt hämtades. Recall = TP/(TP+FN)
F1-poängen beräknas som det viktade medelvärdet av precision och återkallas mellan 0 och 1, där det idealiska F1-poängvärdet är 1.
AUC mäter området under kurvan ritat med sanna positiva identifieringar på y-axeln och falska positiva identifieringar på x-axeln. Det här måttet är användbart eftersom det innehåller ett enda tal som gör att du kan jämföra modeller av olika typer. AUC är classification-threshold-invariant. Den mäter kvaliteten på modellens förutsägelser oavsett vilket klassificeringströskelvärde som väljs.
Mått för regressionsmodeller
Måtten som returneras för regressionsmodeller är utformade för att uppskatta mängden fel. En modell anses passa datakällan om skillnaden mellan observerade och förutsagda värden är liten. Men om du tittar på mönstret för residualerna (skillnaden mellan en förutsagd punkt och dess motsvarande faktiska värde) kan du berätta mycket om potentiell bias i modellen.
Följande mått rapporteras för utvärdering av linjära regressionsmodeller. Andra regressionsmodeller som Fast Forest Quantile Regression kan ha olika mått.
Genomsnittligt absolut fel (MAE) mäter hur nära förutsägelserna är de faktiska utfallen. Därför är en lägre poäng bättre.
RMSE (Root Mean Squared Error) skapar ett enda värde som sammanfattar felet i modellen. Genom att placera skillnaden i kvart bortser måttet från skillnaden mellan överförutsägelse och underförutsägelse.
Relativt absolut fel (RAE) är den relativa absoluta skillnaden mellan förväntade och faktiska värden, relativ eftersom den genomsnittliga skillnaden divideras med det aritmetiska medelvärdet.
Det relativa kvadratfelet (RSE) normaliserar på samma sätt det totala kvadratfelet för de förutsagda värdena genom att dividera med det totala kvadratfelet för de faktiska värdena.
Bestämningskoefficient, som ofta kallas R2, representerar modellens förutsägelsekraft som ett värde mellan 0 och 1. Noll innebär att modellen är slumpmässig (förklarar ingenting); 1 innebär att det finns en perfekt passform. Försiktighet bör dock användas vid tolkning av R2-värden , eftersom låga värden kan vara helt normala och höga värden kan misstänkas.
Mått för klustringsmodeller
Eftersom klustringsmodeller skiljer sig avsevärt från klassificerings- och regressionsmodeller i många avseenden returnerar Evaluate Model även en annan uppsättning statistik för klustringsmodeller.
Statistiken som returneras för en klustringsmodell beskriver hur många datapunkter som har tilldelats varje kluster, mängden separation mellan kluster och hur tätt datapunkterna samlas i varje kluster.
Statistiken för klustringsmodellen är genomsnittlig för hela datamängden, med ytterligare rader som innehåller statistiken per kluster.
Följande mått rapporteras för utvärdering av klustringsmodeller.
Poängen i kolumnen Genomsnittligt avstånd till annat centrum representerar hur nära varje punkt i klustret i genomsnitt är till centroiderna för alla andra kluster.
Poängen i kolumnen Genomsnittligt avstånd till klustercenter representerar närheten för alla punkter i ett kluster till centroiden i klustret.
Kolumnen Antal punkter visar hur många datapunkter som har tilldelats till varje kluster, tillsammans med det totala totala antalet datapunkter i ett kluster.
Om antalet datapunkter som tilldelats kluster är mindre än det totala antalet tillgängliga datapunkter innebär det att datapunkterna inte kunde tilldelas till ett kluster.
Poängen i kolumnen Maximalt avstånd till Klustercenter representerar maximalt antal avstånd mellan varje punkt och centroiden för den punktens kluster.
Om det här talet är högt kan det innebära att klustret är utspridt. Du bör granska den här statistiken tillsammans med Genomsnittligt avstånd till Klustercenter för att fastställa klustrets spridning.
Den kombinerade utvärderingspoängen längst ned i varje resultatavsnitt visar de genomsnittliga poängen för de kluster som skapats i den specifika modellen.
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.