Konfigurera AutoML-träning med Python
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här guiden får du lära dig hur du konfigurerar en automatiserad maskininlärning, AutoML, träningskörning med Azure Machine Learning Python SDK med azure machine learning automatiserad ML. Automatiserad ML väljer en algoritm och hyperparametrar åt dig och genererar en modell som är redo för distribution. Den här guiden innehåller information om de olika alternativ som du kan använda för att konfigurera automatiserade ML-experiment.
Ett exempel från slutpunkt till slutpunkt finns i Självstudie: AutoML – träna regressionsmodell.
Om du föredrar en upplevelse utan kod kan du även konfigurera autoML-träning utan kod i Azure Machine Learning-studio.
Förutsättningar
För den här artikeln behöver du
En Azure Machine Learning-arbetsyta. Information om hur du skapar arbetsytan finns i Skapa arbetsyteresurser.
Azure Machine Learning Python SDK installerat. Om du vill installera SDK:et kan du antingen
Skapa en beräkningsinstans som automatiskt installerar SDK och är förkonfigurerad för ML-arbetsflöden. Mer information finns i Skapa och hantera en Azure Machine Learning-beräkningsinstans .
automlInstallera paketet själv, vilket inkluderar standardinstallationen av SDK: et.
Viktigt!
Python-kommandona i den här artikeln kräver den senaste
azureml-train-automlpaketversionen.- Installera det senaste
azureml-train-automlpaketet i din lokala miljö. - Mer information om det senaste
azureml-train-automlpaketet finns i viktig information.
Varning
Python 3.8 är inte kompatibelt med
automl.
Välj experimenttyp
Innan du påbörjar experimentet bör du fastställa vilken typ av maskininlärningsproblem du löser. Automatiserad maskininlärning stöder uppgiftstyperna classification, regressionoch forecasting. Läs mer om aktivitetstyper.
Kommentar
Stöd för nlp-uppgifter (natural language processing): bildklassificering (multi-class och multi-label) och namngiven entitetsigenkänning är tillgängligt i offentlig förhandsversion. Läs mer om NLP-uppgifter i automatiserad ML.
De här förhandsgranskningsfunktionerna tillhandahålls utan ett serviceavtal. Vissa funktioner kanske inte stöds eller har begränsade funktioner. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Följande kod använder parametern taskAutoMLConfig i konstruktorn för att ange experimenttypen som classification.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Datakällor och format
Automatiserad maskininlärning har stöd för både lokala data och data i molnlagring som Azure Blob Storage. Data kan läsas in i en Pandas DataFrame eller en Azure Machine Learning TabularDataset. Läs mer om datamängder.
Krav för träningsdata i maskininlärning:
- Data måste vara i tabellform.
- Värdet som ska förutsägas, målkolumnen, måste finnas i data.
Viktigt!
Automatiserade ML-experiment stöder inte träning med datauppsättningar som använder identitetsbaserad dataåtkomst.
För fjärrexperiment måste träningsdata vara tillgängliga från fjärrberäkningen. Automatiserad ML accepterar endast Azure Machine Learning TabularDatasets när du arbetar med en fjärrberäkning.
Azure Machine Learning-datamängder exponerar funktioner för att:
- Överför enkelt data från statiska filer eller URL-källor till din arbetsyta.
- Göra data tillgängliga för träningsskript när de körs på beräkningsresurser i molnet. Se Träna med datauppsättningar för ett exempel på hur du använder
Datasetklassen för att montera data till ditt fjärrberäkningsmål.
Följande kod skapar en TabularDataset från en webb-URL. Se Skapa en TabularDataset för kodexempel på hur du skapar datauppsättningar från andra källor som lokala filer och datalager.
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
För lokala beräkningsexperiment rekommenderar vi Pandas-dataramar för snabbare bearbetningstider.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Tränings-, validerings- och testdata
Du kan ange separata träningsdata och valideringsdatauppsättningar direkt i AutoMLConfig konstruktorn. Läs mer om hur du konfigurerar tränings-, validerings-, korsvaliderings- och testdata för dina AutoML-experiment.
Om du inte uttryckligen anger en validation_data parameter eller n_cross_validation parameter använder automatiserad ML standardtekniker för att avgöra hur verifieringen utförs. Den här bestämningen beror på antalet rader i datauppsättningen som tilldelats parametern training_data .
| Träningsdatastorlek | Valideringsteknik |
|---|---|
| Större än 20 000 rader | Delning av tränings-/valideringsdata tillämpas. Standardvärdet är att ta 10 % av den inledande träningsdatauppsättningen som verifieringsuppsättning. Verifieringsuppsättningen används i sin tur för måttberäkning. |
| Mindre än 20 000 rader | Metoden för korsvalidering tillämpas. Standardantalet vikningar beror på antalet rader. Om datamängden är mindre än 1 000 rader används 10 vikter. Om raderna är mellan 1 000 och 20 000 används tre veck. |
Dricks
Du kan ladda upp testdata (förhandsversion) för att utvärdera modeller som automatiserad ML genererade åt dig. Dessa funktioner är experimentella förhandsversionsfunktioner och kan ändras när som helst. Lär dig att:
- Skicka in testdata till autoMLConfig-objektet.
- Testa modellerna automatiserad ML som genererats för experimentet.
Om du föredrar en upplevelse utan kod kan du läsa steg 12 i Konfigurera AutoML med studiogränssnittet
Stora data
Automatiserad ML stöder ett begränsat antal algoritmer för träning av stora data som kan skapa modeller för stordata på små virtuella datorer. Automatiserad ML-heuristik beror på egenskaper som datastorlek, minnesstorlek för virtuella datorer, tidsgräns för experiment och funktionaliseringsinställningar för att avgöra om dessa stora dataalgoritmer ska tillämpas. Läs mer om vilka modeller som stöds i automatiserad ML.
För regression, Online Gradient Descent Regressor och Fast Linear Regressor
För klassificering, Averaged Perceptron Classifier och Linjär SVM-klassificerare, där den linjära SVM-klassificeraren har både stora data och små dataversioner.
Om du vill åsidosätta dessa heuristiker använder du följande inställningar:
| Uppgift | Inställning | OBS! |
|---|---|---|
| Blockera algoritmer för dataströmning | blocked_models i objektet AutoMLConfig och visa en lista över de modeller som du inte vill använda. |
Resulterar i antingen körningsfel eller lång körningstid |
| Använda algoritmer för dataströmning | allowed_models i objektet AutoMLConfig och visa en lista över de modeller som du vill använda. |
|
| Använda algoritmer för dataströmning (studio UI-experiment) |
Blockera alla modeller utom de stordataalgoritmer som du vill använda. |
Beräkning för att köra experiment
Bestäm sedan var modellen ska tränas. Ett automatiserat ML-träningsexperiment kan köras på följande beräkningsalternativ.
Välj en lokal beräkning: Om ditt scenario handlar om inledande utforskningar eller demonstrationer med små data och korta tåg (dvs. sekunder eller ett par minuter per underordnad körning) kan det vara ett bättre val att träna på den lokala datorn. Det finns ingen installationstid, infrastrukturresurserna (datorn eller den virtuella datorn) är direkt tillgängliga. Det finns ett exempel med lokala beräkningar i den här notebook-filen.
Välj ett ml-fjärrberäkningskluster: Om du tränar med större datauppsättningar som i produktionsträning och skapar modeller som behöver längre tåg, ger fjärrberäkning mycket bättre prestanda från slutpunkt till slutpunkt eftersom
AutoMLdet parallelliserar tåg över klustrets noder. Vid en fjärrberäkning lägger starttiden för den interna infrastrukturen till cirka 1,5 minuter per underordnad körning, plus ytterligare minuter för klusterinfrastrukturen om de virtuella datorerna ännu inte är igång.Azure Machine Learning Managed Compute är en hanterad tjänst som gör det möjligt att träna maskininlärningsmodeller i kluster med virtuella Azure-datorer. Beräkningsinstansen stöds också som beräkningsmål.Ett Azure Databricks-kluster i din Azure-prenumeration. Mer information finns i Konfigurera ett Azure Databricks-kluster för automatiserad ML. Det finns exempel på notebook-filer med Azure Databricks på den här GitHub-lagringsplatsen.
Tänk på dessa faktorer när du väljer beräkningsmål:
| Fördelar (fördelar) | Nackdelar (handikapp) | |
|---|---|---|
| Lokalt beräkningsmål | ||
| Fjärr-ML-beräkningskluster |
Konfigurera dina experimentinställningar
Det finns flera alternativ som du kan använda för att konfigurera ditt automatiserade ML-experiment. Dessa parametrar anges genom instansiering av ett AutoMLConfig objekt. En fullständig lista över parametrar finns i klassen AutoMLConfig.
Följande exempel är för en klassificeringsuppgift. Experimentet använder AUC viktat som primärt mått och har en tidsgräns för experimentet inställd på 30 minuter och 2 korsvalideringsveckningar.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
Du kan också konfigurera prognosuppgifter, vilket kräver extra konfiguration. Mer information finns i artikeln Konfigurera AutoML för tidsserieprognoser .
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Modeller som stöds
Automatiserad maskininlärning provar olika modeller och algoritmer under automatiserings- och justeringsprocessen. Som användare behöver du inte ange algoritmen.
De tre olika task parametervärdena avgör vilken lista med algoritmer eller modeller som ska tillämpas. Använd parametrarna allowed_models eller blocked_models för att ytterligare ändra iterationer med tillgängliga modeller som ska inkluderas eller exkluderas.
I följande tabell sammanfattas de modeller som stöds efter aktivitetstyp.
Kommentar
Om du planerar att exportera dina automatiserade ML-skapade modeller till en ONNX-modell kan endast de algoritmer som anges med en * (asterisk) konverteras till ONNX-formatet. Läs mer om att konvertera modeller till ONNX.
Observera också att ONNX endast stöder klassificerings- och regressionsaktiviteter just nu.
Primärt mått
Parametern primary_metric avgör vilket mått som ska användas under modellträningen för optimering. De tillgängliga mått som du kan välja bestäms av den aktivitetstyp du väljer.
Att välja ett primärt mått för automatiserad ML för att optimera beror på många faktorer. Vi rekommenderar att du främst överväger att välja ett mått som bäst motsvarar dina affärsbehov. Tänk sedan på om måttet är lämpligt för din datamängdsprofil (datastorlek, intervall, klassdistribution osv.). I följande avsnitt sammanfattas de rekommenderade primära måtten baserat på aktivitetstyp och affärsscenario.
Lär dig mer om de specifika definitionerna av dessa mått i Förstå automatiserade maskininlärningsresultat.
Mått för klassificeringsscenarier
Tröskelvärdesberoende mått, till exempel accuracy, recall_score_weighted, norm_macro_recalloch precision_score_weighted kanske inte optimeras lika bra för datauppsättningar som är små, har mycket stor klassförskjutning (obalans i klassen) eller när det förväntade måttvärdet är mycket nära 0,0 eller 1,0. I dessa fall AUC_weighted kan vara ett bättre val för det primära måttet. När automatiserad ML har slutförts kan du välja den vinnande modellen baserat på måttet som passar bäst för dina affärsbehov.
| Mått | Exempel på användningsfall |
|---|---|
accuracy |
Bildklassificering, Attitydanalys, Churn-förutsägelse |
AUC_weighted |
Bedrägeriidentifiering, bildklassificering, avvikelseidentifiering/skräppostidentifiering |
average_precision_score_weighted |
Attitydanalys |
norm_macro_recall |
Förutsägelse av omsättning |
precision_score_weighted |
Mått för regressionsscenarier
r2_score, normalized_mean_absolute_error och normalized_root_mean_squared_error försöker alla minimera förutsägelsefel. r2_score och normalized_root_mean_squared_error minimerar både genomsnittliga kvadratfel samtidigt normalized_mean_absolute_error som det genomsnittliga absoluta värdet för fel minimeras. Absolut värde behandlar fel i alla storleksklasser och kvadratfel får en mycket större straffavgift för fel med större absoluta värden. Beroende på om större fel ska straffas mer eller inte kan man välja att optimera kvadratfel eller absolut fel.
Den största skillnaden mellan r2_score och normalized_root_mean_squared_error är hur de normaliseras och deras betydelser. normalized_root_mean_squared_error är rotvärdet kvadratfel som normaliseras efter intervall och kan tolkas som den genomsnittliga felstorleken för förutsägelse. r2_score är ett genomsnittligt kvadratfel som normaliserats av en uppskattning av variansen för data. Det är den andel av variationen som kan fångas in av modellen.
Kommentar
r2_score och normalized_root_mean_squared_error fungerar också på samma sätt som primära mått. Om en fast valideringsuppsättning tillämpas optimerar dessa två mått samma mål, medelvärdet av kvadratfel och optimeras av samma modell. När endast en träningsuppsättning är tillgänglig och korsvalidering tillämpas skulle de vara något annorlunda eftersom normaliseraren för normalized_root_mean_squared_error är fast som träningsuppsättningens intervall, men normaliseraren för r2_score skulle variera för varje vik eftersom det är variansen för varje vik.
Om rangordningen, i stället för det exakta värdet är av intresse, spearman_correlation kan vara ett bättre val eftersom den mäter rangrelationen mellan verkliga värden och förutsägelser.
Men för närvarande adresserar inga primära mått för regression relativ skillnad. r2_scoreAlla , normalized_mean_absolute_erroroch normalized_root_mean_squared_error behandlar ett förutsägelsefel på 20 000 USD samma för en arbetare med en lön på 30 000 USD som en arbetare som tjänar 20 miljoner usd, om dessa två datapunkter tillhör samma datauppsättning för regression eller samma tidsserie som anges av tidsserieidentifieraren. I verkligheten är det mycket nära att förutsäga endast $ 20k av från en $ 20M lön (en liten relativ skillnad på 0,1% ), medan $ 20k från $ 30k inte är nära (en stor relativ skillnad på 67%). För att åtgärda problemet med relativ skillnad kan man träna en modell med tillgängliga primära mått och sedan välja modellen med bäst mean_absolute_percentage_error eller root_mean_squared_log_error.
| Mått | Exempel på användningsfall |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Prisförutsägelse (hus/produkt/tips), Förutsägelse av granskningspoäng |
r2_score |
Flygbolagsfördröjning, löneuppskattning, felmatchningstid |
normalized_mean_absolute_error |
Mått för scenarier för tidsserieprognoser
Rekommendationerna liknar dem som anges för regressionsscenarier.
| Mått | Exempel på användningsfall |
|---|---|
normalized_root_mean_squared_error |
Prisförutsägelse (prognostisering), lageroptimering, efterfrågeprognoser |
r2_score |
Prisförutsägelse (prognostisering), lageroptimering, efterfrågeprognoser |
normalized_mean_absolute_error |
Funktionalisering av data
I varje automatiserat ML-experiment skalas och normaliseras dina data automatiskt för att hjälpa vissa algoritmer som är känsliga för funktioner som finns i olika skalor. Den här skalningen och normaliseringen kallas för funktionalisering. Mer information och kodexempel finns i Funktionalisering i AutoML .
Kommentar
Automatiserade maskininlärningssteg (funktionsnormalisering, hantering av saknade data, konvertering av text till numeriska osv.) blir en del av den underliggande modellen. När du använder modellen för förutsägelser tillämpas samma funktionaliseringssteg som tillämpas under träningen på dina indata automatiskt.
När du konfigurerar experimenten i objektet AutoMLConfig kan du aktivera/inaktivera inställningen featurization. I följande tabell visas de godkända inställningarna för funktionalisering i AutoMLConfig-objektet.
| Funktionaliseringskonfiguration | Description |
|---|---|
"featurization": 'auto' |
Anger att som en del av förbearbetningen utförs dataskyddsmekanismer och funktionaliseringssteg automatiskt. Standardinställning. |
"featurization": 'off' |
Anger att funktionaliseringssteget inte ska utföras automatiskt. |
"featurization": 'FeaturizationConfig' |
Anger att det anpassade funktionaliseringssteget ska användas. Lär dig hur du anpassar funktionalisering. |
Konfiguration av ensemble
Ensemblemodeller är aktiverade som standard och visas som de sista kör iterationerna i en AutoML-körning. För närvarande stöds VotingEnsemble och StackEnsemble .
Röstning implementerar mjuk röstning, som använder viktade medelvärden. Stackningsimplementeringen använder en implementering på två lager, där det första lagret har samma modeller som röstningsensemblen, och den andra lagermodellen används för att hitta den optimala kombinationen av modellerna från det första lagret.
Om du använder ONNX-modeller eller har aktiverat modellförklarbarhet inaktiveras stapling och endast röstning används.
Ensembleträning kan inaktiveras med hjälp av de enable_voting_ensemble booleska parametrarna.enable_stack_ensemble
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Om du vill ändra standardbeteendet för ensemblen finns det flera standardargument som kan anges som kwargs i ett AutoMLConfig objekt.
Viktigt!
Följande parametrar är inte explicita parametrar för klassen AutoMLConfig.
ensemble_download_models_timeout_sec: Under VotingEnsemble - och StackEnsemble-modellgenereringen laddas flera anpassade modeller från de tidigare underordnade körningarna ned. Om det här felet uppstår:AutoMLEnsembleException: Could not find any models for running ensemblingkan du behöva ge mer tid för att modellerna ska laddas ned. Standardvärdet är 300 sekunder för att ladda ned dessa modeller parallellt och det finns ingen maximal tidsgräns. Konfigurera den här parametern med ett högre värde än 300 sekunder om det behövs mer tid.Kommentar
Om tidsgränsen nås och det finns modeller nedladdade fortsätter monteringen med så många modeller som den har laddat ned. Det krävs inte att alla modeller måste laddas ned för att slutföras inom den tidsgränsen. Följande parametrar gäller endast för StackEnsemble-modeller :
stack_meta_learner_type: meta-learner är en modell som tränats på utdata från de enskilda heterogena modellerna. Standardmetalärare ärLogisticRegressionför klassificeringsuppgifter (ellerLogisticRegressionCVom korsvalidering är aktiverat) ochElasticNetför regression/prognostiseringsuppgifter (ellerElasticNetCVom korsvalidering är aktiverat). Den här parametern kan vara en av följande strängar:LogisticRegression,LogisticRegressionCV,LightGBMClassifier,ElasticNet,ElasticNetCV, ,LightGBMRegressorellerLinearRegression.stack_meta_learner_train_percentage: anger den andel av träningsuppsättningen (när du väljer tränings- och valideringstyp för träning) som ska reserveras för träning av meta-learner. Standardvärdet är0.2.stack_meta_learner_kwargs: valfria parametrar som ska skickas till metainlärarens initierare. Dessa parametrar och parametertyper speglar parametrarna och parametertyperna från motsvarande modellkonstruktor och vidarebefordras till modellkonstruktorn.
Följande kod visar ett exempel på hur du anger anpassat ensemblebeteende i ett AutoMLConfig objekt.
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Avsluta villkor
Det finns några alternativ som du kan definiera i autoMLConfig för att avsluta experimentet.
| Kriterie | beskrivning |
|---|---|
| Inga villkor | Om du inte definierar några slutparametrar fortsätter experimentet tills inga ytterligare framsteg görs för ditt primära mått. |
| Efter en längre tid | Använd experiment_timeout_minutes i inställningarna för att definiera hur länge i minuter experimentet ska fortsätta att köras. För att undvika timeout-fel för experiment finns det minst 15 minuter eller 60 minuter om din rad efter kolumnstorlek överskrider 10 miljoner. |
| En poäng har uppnåtts | Användningen experiment_exit_score slutför experimentet när en angiven primär måttpoäng har nåtts. |
Köra experiment
Varning
Om du kör ett experiment med samma konfigurationsinställningar och primärt mått flera gånger ser du förmodligen variation i varje experiments slutliga måttpoäng och genererade modeller. De algoritmer som automatiserad ML använder har inbyggd slumpmässighet som kan orsaka liten variation i modellernas utdata från experimentet och den rekommenderade modellens slutliga måttpoäng, till exempel noggrannhet. Du kommer förmodligen också att se resultat med samma modellnamn, men olika hyperparametrar används.
För automatiserad ML skapar du ett Experiment objekt, som är ett namngivet objekt i ett Workspace som används för att köra experiment.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Skicka experimentet för att köra och generera en modell. AutoMLConfig Skicka till submit metoden för att generera modellen.
run = experiment.submit(automl_config, show_output=True)
Kommentar
Beroenden installeras först på en ny dator. Det kan ta upp till 10 minuter innan utdata visas.
Om du ställer in show_output på resulterar det i att True utdata visas i konsolen.
Flera underordnade körningar i kluster
Automatiserade underordnade ML-experimentkörningar kan utföras på ett kluster som redan kör ett annat experiment. Tidpunkten beror dock på hur många noder klustret har och om dessa noder är tillgängliga för att köra ett annat experiment.
Varje nod i klustret fungerar som en enskild virtuell dator (VM) som kan utföra en enda träningskörning. för automatiserad ML innebär detta en underordnad körning. Om alla noder är upptagna placeras det nya experimentet i kö. Men om det finns kostnadsfria noder kommer det nya experimentet att köra automatiserade ML-underordnade körningar parallellt på tillgängliga noder/virtuella datorer.
För att hantera underordnade körningar och när de kan utföras rekommenderar vi att du skapar ett dedikerat kluster per experiment och matchar antalet max_concurrent_iterations experiment med antalet noder i klustret. På så sätt använder du alla noder i klustret samtidigt med det antal samtidiga underordnade körningar/iterationer som du vill använda.
Konfigurera max_concurrent_iterations i objektet AutoMLConfig . Om den inte har konfigurerats tillåts som standard endast en samtidig underordnad körning/iteration per experiment.
När det gäller beräkningsinstanser max_concurrent_iterations kan ställas in på samma sätt som antalet kärnor på den virtuella datorn för beräkningsinstansen.
Utforska modeller och mått
Automatiserad ML erbjuder alternativ för att övervaka och utvärdera dina träningsresultat.
Du kan visa dina träningsresultat i en widget eller infogad om du är i en notebook-fil. Mer information finns i Övervaka automatiserade maskininlärningskörningar .
Definitioner och exempel på prestandadiagram och mått som tillhandahålls för varje körning finns i Utvärdera automatiserade maskininlärningsexperimentresultat.
Information om hur du får en funktionaliseringssammanfattning och förstår vilka funktioner som har lagts till i en viss modell finns i Funktionaliseringstransparens.
Du kan visa hyperparametrar, skalnings- och normaliseringstekniker och algoritmer som tillämpas på en specifik automatiserad ML-körning med den anpassade kodlösningen. print_model()
Dricks
Automatiserad ML låter dig också visa den genererade modellträningskoden för auto ML-tränade modeller. Den här funktionen är i offentlig förhandsversion och kan ändras när som helst.
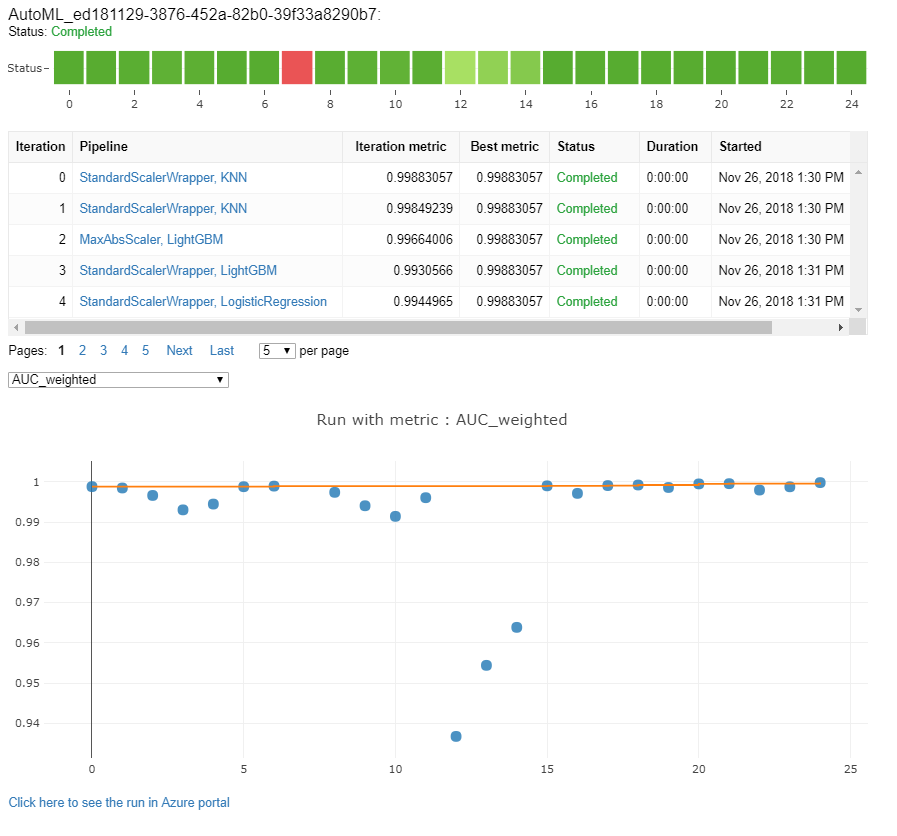
Övervaka automatiserade maskininlärningskörningar
För automatiserade ML-körningar ersätter <<experiment_name>> du med lämpligt experimentnamn för att komma åt diagrammen från en tidigare körning:
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
Testmodeller (förhandsversion)
Viktigt!
Att testa dina modeller med en testdatauppsättning för att utvärdera automatiserade ML-genererade modeller är en förhandsversionsfunktion. Den här funktionen är en experimentell förhandsversionsfunktion och kan ändras när som helst.
Varning
Den här funktionen är inte tillgänglig för följande automatiserade ML-scenarier
Om du skickar parametrarna test_data eller test_size till AutoMLConfigutlöses automatiskt en fjärrtestkörning som använder de angivna testdata för att utvärdera den bästa modellen som automatiserad ML rekommenderar när experimentet har slutförts. Den här fjärrtestkörningen görs i slutet av experimentet när den bästa modellen har fastställts. Se hur du skickar testdata till din AutoMLConfig.
Hämta testjobbresultat
Du kan hämta förutsägelser och mått från fjärrtestjobbet från Azure Machine Learning-studio eller med följande kod.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
Modelltestjobbet genererar filen predictions.csv som lagras i standarddataarkivet som skapats med arbetsytan. Det här dataarkivet är synligt för alla användare med samma prenumeration. Testjobb rekommenderas inte för scenarier om någon av informationen som används för eller skapas av testjobbet måste förbli privat.
Testa befintlig automatiserad ML-modell
Om du vill testa andra befintliga automatiserade ML-modeller som skapats, bästa jobb eller underordnat jobb använder du ModelProxy() för att testa en modell när den huvudsakliga AutoML-körningen har slutförts. ModelProxy() returnerar redan förutsägelserna och måtten och kräver inte ytterligare bearbetning för att hämta utdata.
Kommentar
ModelProxy är en experimentell förhandsversionsklass och kan ändras när som helst.
Följande kod visar hur du testar en modell från en körning med hjälp av metoden ModelProxy.test(). I metoden test() har du möjlighet att ange om du bara vill se förutsägelserna för testkörningen med parametern include_predictions_only .
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Registrera och distribuera modeller
När du har testat en modell och bekräftat att du vill använda den i produktion kan du registrera den för senare användning och
Om du vill registrera en modell från en automatiserad ML-körning använder du register_model() metoden .
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Mer information om hur du skapar en distributionskonfiguration och distribuerar en registrerad modell till en webbtjänst finns i hur och var du distribuerar en modell.
Dricks
För registrerade modeller är distribution med ett klick tillgängligt via Azure Machine Learning-studio. Se hur du distribuerar registrerade modeller från studion.
Modelltolkning
Med modelltolkning kan du förstå varför dina modeller har gjort förutsägelser och de underliggande funktionsvärdevärdena. SDK innehåller olika paket för att aktivera funktioner för modelltolkning, både vid träning och slutsatsdragning, för lokala och distribuerade modeller.
Se hur du aktiverar tolkningsfunktioner specifikt i automatiserade ML-experiment.
Allmän information om hur modellförklaringar och funktionsvikt kan aktiveras i andra delar av SDK:t utanför automatiserad maskininlärning finns i begreppsartikeln om tolkning .
Kommentar
ForecastTCN-modellen stöds för närvarande inte av förklaringsklienten. Den här modellen returnerar inte en förklaringsinstrumentpanel om den returneras som den bästa modellen och inte stöder förklaringar på begäran.