Visa träningskod för en automatiserad ML-modell
I den här artikeln får du lära dig hur du visar den genererade träningskoden från valfri automatiserad maskininlärningstränad modell.
Med kodgenerering för automatiserade ML-tränade modeller kan du se följande information som automatiserad ML använder för att träna och skapa modellen för en specifik körning.
- Förbearbetning av data
- Algoritmval
- Funktionalisering
- Hyperparametrar
Du kan välja valfri automatiserad ML-tränad modell, rekommenderad eller underordnad körning och visa den genererade Python-träningskoden som skapade den specifika modellen.
Med den genererade modellens träningskod kan du,
- Lär dig vilka funktionaliseringsprocesser och hyperparametrar som modellalgoritmen använder.
- Spåra/version/granska tränade modeller. Lagra versionskod för att spåra vilken specifik träningskod som används med den modell som ska distribueras till produktion.
- Anpassa träningskoden genom att ändra hyperparametrar eller tillämpa dina kunskaper/erfarenheter för ML och algoritmer och träna om en ny modell med din anpassade kod.
Följande diagram visar att du kan generera koden för automatiserade ML-experiment med alla aktivitetstyper. Välj först en modell. Den valda modellen markeras och sedan kopierar Azure Machine Learning kodfilerna som används för att skapa modellen och visar dem i den delade mappen notebook-filer. Härifrån kan du visa och anpassa koden efter behov.
Förutsättningar
En Azure Machine Learning-arbetsyta. Information om hur du skapar arbetsytan finns i Skapa arbetsyteresurser.
Den här artikeln förutsätter viss kunskap om hur du konfigurerar ett automatiserat maskininlärningsexperiment. Följ självstudien eller instruktioner för att se de huvudsakliga designmönstren för automatiserade maskininlärningsexperiment.
Automatiserad ML-kodgenerering är endast tillgänglig för experiment som körs på azure machine learning-fjärrberäkningsmål. Kodgenerering stöds inte för lokala körningar.
Alla automatiserade ML-körningar som utlöses via Azure Machine Learning-studio, SDKv2 eller CLIv2 har kodgenerering aktiverat.
Hämta genererad kod och modellartefakter
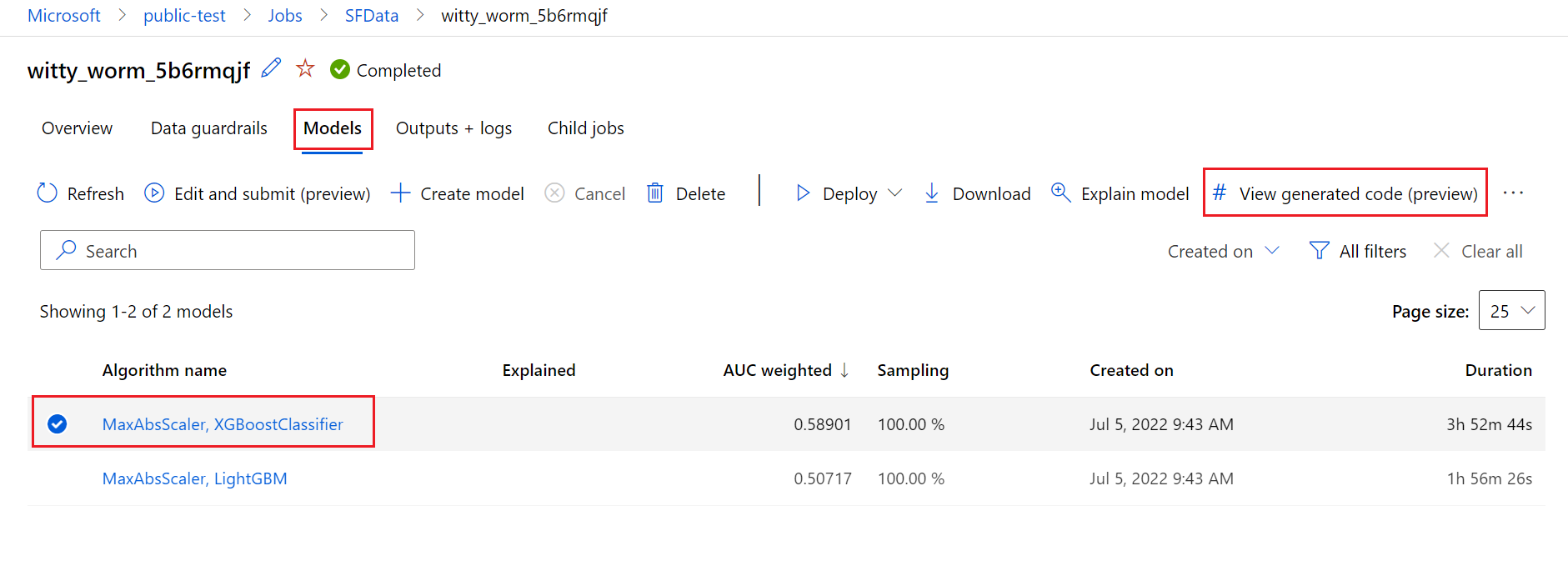
Som standard genererar varje automatiserad ML-tränad modell sin träningskod när träningen har slutförts. Automatiserad ML sparar den här koden i experimentet outputs/generated_code för den specifika modellen. Du kan visa dem i Azure Machine Learning-studio användargränssnittet på fliken Utdata + loggar i den valda modellen.
script.py Det här är modellens träningskod som du förmodligen vill analysera med funktionaliseringsstegen, specifika algoritmer som används och hyperparametrar.
script_run_notebook.ipynb Notebook med pannplåtskod för att köra modellens träningskod (script.py) i Azure Machine Learning-beräkning via Azure Machine Learning SDKv2.
När den automatiserade ML-träningskörningen script.py har slutförts finns det du som kan komma åt filerna och script_run_notebook.ipynb via Azure Machine Learning-studio användargränssnittet.
Det gör du genom att gå till fliken Modeller på sidan för den automatiserade överordnade ML-experimentkörningen. När du har valt någon av de tränade modellerna kan du välja knappen Visa genererad kod . Den här knappen omdirigerar dig till notebook-portaltillägget , där du kan visa, redigera och köra den genererade koden för just den valda modellen.
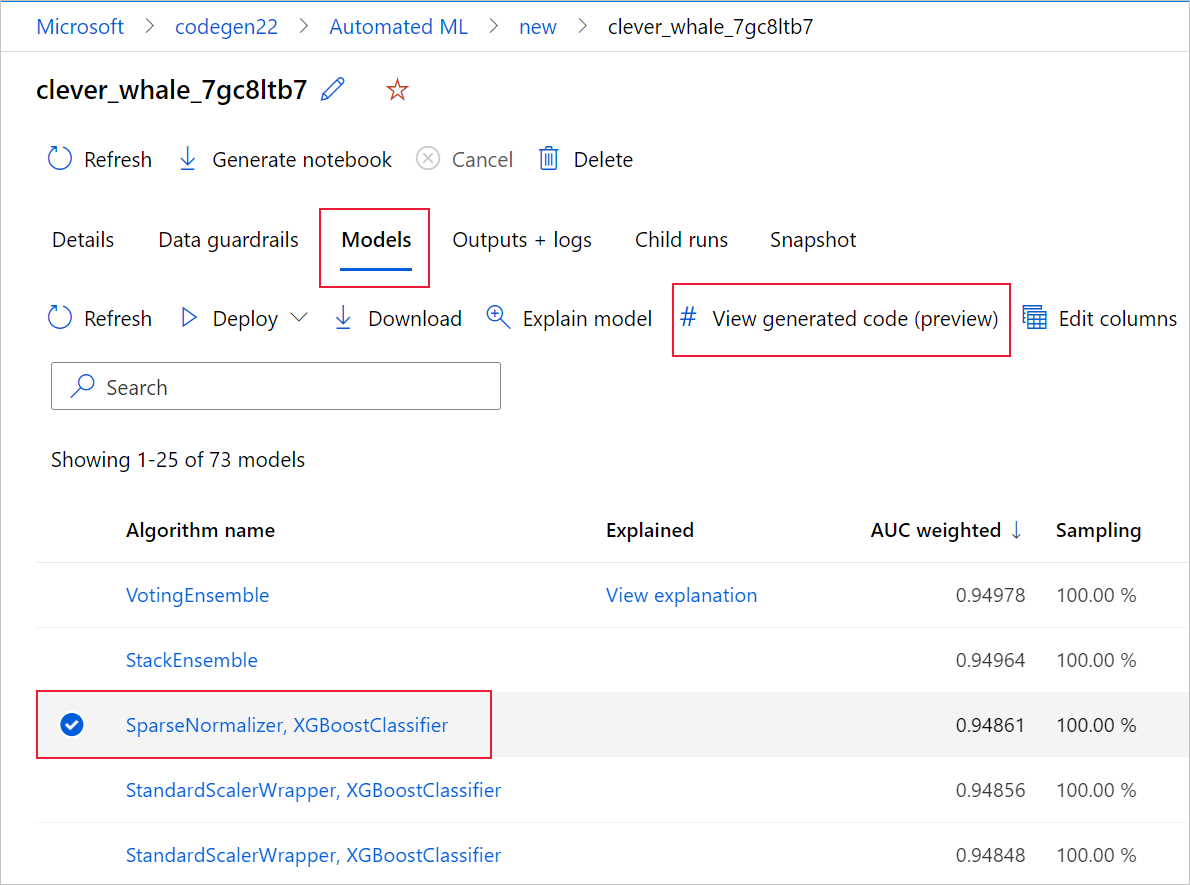
Du kan också komma åt modellens genererade kod överst på den underordnade körningens sida när du navigerar till den underordnade körningens sida i en viss modell.

Om du använder Python SDKv2 kan du också ladda ned "script.py" och "script_run_notebook.ipynb" genom att hämta den bästa körningen via MLFlow och ladda ned de resulterande artefakterna.
Begränsningar
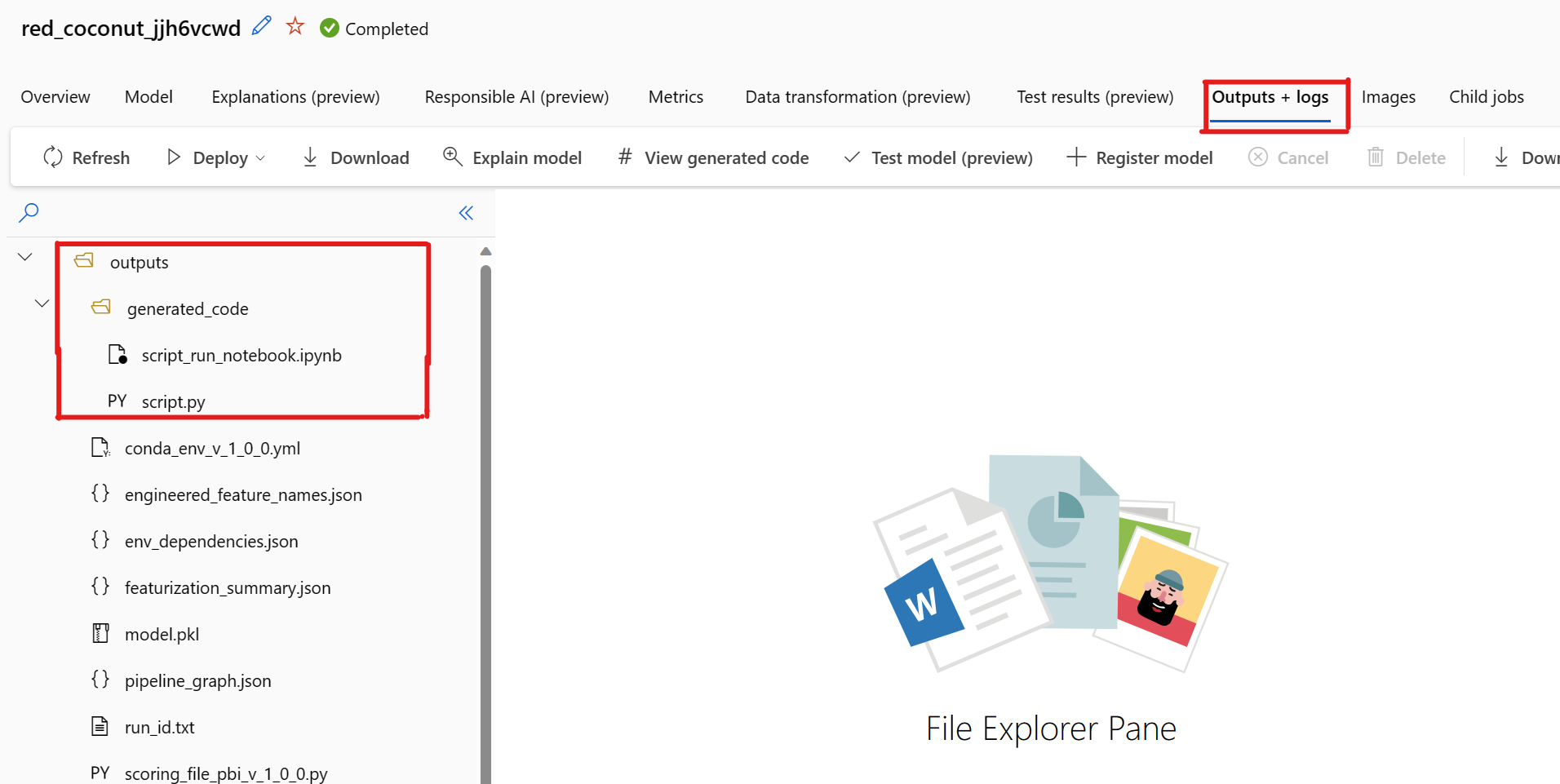
Det finns ett känt problem när du väljer Visa genererad kod. Den här åtgärden kan inte omdirigeras till Notebooks-portalen när lagringen finns bakom ett virtuellt nätverk. Som en lösning kan användaren manuellt ladda ned filerna script.py och script_run_notebook.ipynb genom att navigera till fliken Utdata + loggar under mappen utdata>generated_code . Dessa filer kan laddas upp manuellt till mappen notebook-filer för att köra eller redigera dem. Följ den här länken om du vill veta mer om virtuella nätverk i Azure Machine Learning.
script.py
Filen script.py innehåller den kärnlogik som behövs för att träna en modell med tidigare använda hyperparametrar. Modellens träningskod är avsedd att köras i kontexten för en Azure Machine Learning-skriptkörning, men med vissa ändringar kan modellens träningskod också köras fristående i din egen lokala miljö.
Skriptet kan delas upp i flera av följande delar: datainläsning, dataförberedelse, databedriftsättning, specifikation av förprocessorer/algoritmer och träning.
Läsa in data
Funktionen get_training_dataset() läser in den tidigare använda datamängden. Det förutsätter att skriptet körs i ett Azure Machine Learning-skript som körs under samma arbetsyta som det ursprungliga experimentet.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
När du kör som en del av en skriptkörning Run.get_context().experiment.workspace hämtar rätt arbetsyta. Men om det här skriptet körs i en annan arbetsyta eller körs lokalt måste du ändra skriptet för att uttryckligen ange rätt arbetsyta.
När arbetsytan har hämtats hämtas den ursprungliga datamängden med dess ID. En annan datauppsättning med exakt samma struktur kan också anges med ID eller namn med get_by_id() eller get_by_name(), respektive. Du hittar ID:t senare i skriptet, i ett liknande avsnitt som följande kod.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
Du kan också välja att ersätta hela den här funktionen med din egen datainläsningsmekanism. De enda begränsningarna är att returvärdet måste vara en Pandas-dataram och att data måste ha samma form som i det ursprungliga experimentet.
Kod för förberedelse av data
Funktionen prepare_data() rensar data, delar upp funktions- och exempelviktkolumnerna och förbereder data för användning i träning.
Den här funktionen kan variera beroende på typen av datamängd och experimentaktivitetstypen: klassificering, regression, tidsserieprognoser, bilder eller NLP-uppgifter.
I följande exempel visas att dataramen från datainläsningssteget i allmänhet skickas in. Etikettkolumnen och exempelvikterna, om de ursprungligen angavs, extraheras och rader som innehåller NaN tas bort från indata.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Om du vill göra fler dataförberedelser kan du göra det i det här steget genom att lägga till din anpassade kod för förberedelse av data.
Kod för datafunktionalisering
Funktionen generate_data_transformation_config() anger funktionaliseringssteget i den sista scikit-learn-pipelinen. Funktionaliseringarna från det ursprungliga experimentet återges här, tillsammans med deras parametrar.
Till exempel kan möjlig datatransformering som kan ske i den här funktionen baseras på imputers som och SimpleImputer()CatImputer(), eller transformatorer som StringCastTransformer() och LabelEncoderTransformer().
Följande är en transformerare av typen StringCastTransformer() som kan användas för att transformera en uppsättning kolumner. I det här fallet anges den uppsättning som anges av column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Om du har många kolumner som måste ha samma funktionalisering/transformering tillämpad (till exempel 50 kolumner i flera kolumngrupper) hanteras dessa kolumner genom gruppering baserat på typ.
Observera i följande exempel att varje grupp har en unik mappare tillämpad. Den här mapparen tillämpas sedan på var och en av kolumnerna i den gruppen.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Med den här metoden kan du ha en mer effektiv kod genom att inte ha en transformerares kodblock för varje kolumn, vilket kan vara särskilt besvärligt även när du har tiotals eller hundratals kolumner i datauppsättningen.
Med klassificerings- och regressionsaktiviteter används [FeatureUnion] för funktionaliserare.
För prognosmodeller för tidsserier samlas flera tidsseriemedvetna funktionaliserare in i en scikit-learn-pipeline och omsluts sedan i TimeSeriesTransformer.
Alla användare tillhandahöll funktionaliseringar för prognosmodeller för tidsserier innan de som tillhandahålls av automatiserad ML.
Specifikationskod för förprocessor
Funktionen generate_preprocessor_config(), om den finns, anger ett förbearbetningssteg som ska utföras efter funktionalisering i den sista scikit-learn-pipelinen.
Normalt består det här förbearbetningssteget endast av datastandardisering/normalisering som utförs med sklearn.preprocessing.
Automatiserad ML anger endast ett förbearbetningssteg för icke-utökningsbara klassificerings- och regressionsmodeller.
Här är ett exempel på en genererad kod för förprocessor:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Specifikationskod för algoritmer och hyperparametrar
Specifikationskoden för algoritmer och hyperparametrar är sannolikt det som många ML-proffs är mest intresserade av.
Funktionen generate_algorithm_config() anger den faktiska algoritmen och hyperparametrar för träning av modellen som den sista fasen i den sista scikit-learn-pipelinen.
I följande exempel används en XGBoostClassifier-algoritm med specifika hyperparametrar.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
Den genererade koden använder i de flesta fall öppen källkod programvarupaket (OSS) och klasser. Det finns instanser där mellanliggande omslutningsklasser används för att förenkla mer komplex kod. Till exempel kan XGBoost-klassificerare och andra vanliga bibliotek som LightGBM- eller Scikit-Learn-algoritmer användas.
Som ML Professional kan du anpassa algoritmens konfigurationskod genom att justera dess hyperparametrar efter behov baserat på dina kunskaper och erfarenheter för den algoritmen och ditt specifika ML-problem.
För ensemblemodeller generate_preprocessor_config_N() (om det behövs) och generate_algorithm_config_N() definieras för varje elev i ensemblemodellen, där N representerar placeringen av varje elev i ensemblemodellens lista. För stackensembler definieras metaläraren generate_algorithm_config_meta() .
Träningskod från slutpunkt till slutpunkt
Kodgenereringen genererar build_model_pipeline() och train_model() för att definiera scikit-learn-pipelinen och för att anropa fit() den.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
Scikit-learn-pipelinen innehåller funktionaliseringssteget, en förprocessor (om den används) och algoritmen eller modellen.
För prognosmodeller för tidsserier omsluts scikit-learn-pipelinen i en ForecastingPipelineWrapper, som har ytterligare logik som behövs för att hantera tidsseriedata korrekt beroende på den tillämpade algoritmen.
För alla aktivitetstyper använder PipelineWithYTransformer vi i fall där etikettkolumnen måste kodas.
När du har scikit-Learn-pipelinen är fit() allt som återstår att anropa metoden för att träna modellen:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
Returvärdet från train_model() är modellen som är monterad/tränad på indata.
Huvudkoden som kör alla tidigare funktioner är följande:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
När du har tränat modellen kan du använda den för att göra förutsägelser med metoden predict(). Om experimentet är för en tidsseriemodell använder du metoden forecast() för förutsägelser.
y_pred = model.predict(X)
Slutligen serialiseras och sparas modellen som en .pkl fil med namnet "model.pkl":
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
Notebook-filen script_run_notebook.ipynb fungerar som ett enkelt sätt att köra script.py på en Azure Machine Learning-beräkning.
Den här notebook-filen liknar de befintliga automatiserade ML-exempelanteckningsböckerna, men det finns ett par viktiga skillnader som beskrivs i följande avsnitt.
Environment
Vanligtvis anges träningsmiljön för en automatiserad ML-körning automatiskt av SDK:t. Men när du kör ett anpassat skript som den genererade koden, kör automatiserad ML inte längre processen, så miljön måste anges för att kommandojobbet ska lyckas.
Kodgenereringen återanvänder miljön som användes i det ursprungliga automatiserade ML-experimentet, om möjligt. Detta garanterar att träningsskriptkörningen inte misslyckas på grund av saknade beroenden och har en sidoförmån med att inte behöva återskapa En Docker-avbildning, vilket sparar tid och beräkningsresurser.
Om du gör ändringar script.py i som kräver ytterligare beroenden, eller om du vill använda din egen miljö, måste du uppdatera miljön i enlighet med detta script_run_notebook.ipynb .
Skicka experimentet
Eftersom den genererade koden inte längre drivs av automatiserad ML, i stället för att skapa och skicka ett AutoML-jobb, måste du skapa en Command Job och ange den genererade koden (script.py) till den.
Följande exempel innehåller de parametrar och vanliga beroenden som behövs för att köra ett kommandojobb, till exempel beräkning, miljö osv.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
Nästa steg
- Läs mer om hur och var du distribuerar en modell.
- Se hur du aktiverar tolkningsfunktioner specifikt i automatiserade ML-experiment.