Köra Python-skript
Viktigt
Stödet för Machine Learning Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du byter till Azure Machine Learning innan dess.
Från och med den 1 december 2021 kan du inte längre skapa nya Machine Learning Studio-resurser (klassisk). Du kan fortsätta att använda befintliga Machine Learning Studio-resurser (klassisk) till och med den 31 augusti 2024.
- Se information om hur du flyttar maskininlärningsprojekt från ML Studio (klassisk) till Azure Machine Learning.
- Läs mer om Azure Machine Learning.
Dokumentationen om ML Studio (klassisk) håller på att dras tillbaka och kanske inte uppdateras i framtiden.
Kör ett Python skript från ett Machine Learning experiment
Kategori: Python språkmoduler
Anteckning
Gäller endast för: Machine Learning Studio (klassisk)
Liknande dra och släpp-moduler finns i Azure Machine Learning designer.
Modulöversikt
I den här artikeln beskrivs hur du använder modulen Execute Python Script i Machine Learning Studio (klassisk) för att köra Python kod. Mer information om arkitektur- och designprinciperna för Python i Studio (klassisk) finns i följande artikel.
Med Python kan du utföra uppgifter som för närvarande inte stöds av befintliga Studio-moduler (klassiska), till exempel:
- Visualisera data med hjälp av
matplotlib - Använda Python bibliotek för att räkna upp datauppsättningar och modeller på din arbetsyta
- Läsning, inläsning och manipulering av data från källor stöds inte av modulen Importera data
Machine Learning Studio (klassisk) använder Anaconda-distributionen av Python, som innehåller många vanliga verktyg för databehandling.
Så här använder du Kör Python-skript
Modulen Execute Python Script innehåller exempel på Python kod som du kan använda som utgångspunkt. Om du vill konfigurera modulen Execute Python Script (Kör Python skript) anger du en uppsättning indata och Python kod som ska köras i textrutan Python skript.
Lägg till modulen Execute Python Script (Kör Python skript) i experimentet.
Rulla längst ned i fönstret Egenskaper och för Python Version väljer du den version av Python bibliotek och körningsmiljö som ska användas i skriptet.
- Anaconda 2.0-distribution för Python 2.7.7
- Anaconda 4.0-distribution för Python 2.7.11
- Anaconda 4.0-distribution för Python 3.5 (standard)
Vi rekommenderar att du anger versionen innan du skriver ny kod. Om du ändrar versionen senare uppmanas du att bekräfta ändringen.
Viktigt
Om du använder flera instanser av modulen Execute Python Script i experimentet måste du välja en enda version av Python för alla moduler i experimentet.
Lägg till och anslut på Dataset1 för alla datauppsättningar från Studio (klassisk) som du vill använda för indata. Referera till den här datauppsättningen i ditt Python-skript som DataFrame1.
Det är valfritt att använda en datauppsättning om du vill generera data med hjälp av Python eller använda Python kod för att importera data direkt till modulen.
Den här modulen stöder tillägg av en andra Studio-datauppsättning (klassisk) på Dataset2. Referera till den andra datauppsättningen i ditt Python-skript som DataFrame2.
Datauppsättningar som lagras i Studio (klassisk) konverteras automatiskt till pandas data.frames när de läses in med den här modulen.
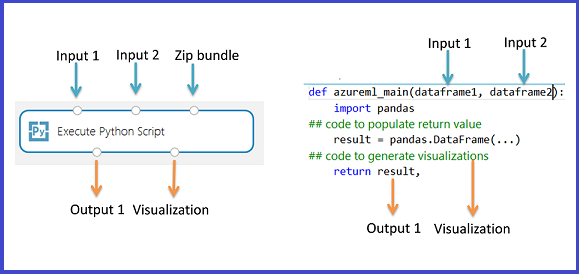
Om du vill inkludera nya Python paket eller kod lägger du till den zippade filen som innehåller dessa anpassade resurser i skriptpaketet. Indata till skriptpaketet måste vara en zippad fil som redan har laddats upp till din arbetsyta. Mer information om hur du förbereder och laddar upp dessa resurser finns i Packa upp komprimerade data.
Alla filer som finns i det uppladdade zippade arkivet kan användas under experimentkörningen. Om arkivet innehåller en katalogstruktur bevaras strukturen, men du måste förbereda en katalog med namnet src till sökvägen.
I textrutan Python skript skriver eller klistrar du in ett giltigt Python skript.
Textrutan Python skript är förifylld med några instruktioner i kommentarer och exempelkod för dataåtkomst och utdata. Du måste redigera eller ersätta den här koden. Se till att följa Python konventioner om indrag och hölje.
- Skriptet måste innehålla en funktion med namnet
azureml_mainsom startpunkt för den här modulen. - Startpunktsfunktionen kan innehålla upp till två indataargument:
Param<dataframe1>ochParam<dataframe2> - Zippade filer som är anslutna till den tredje indataporten packas upp och lagras i katalogen ,
.\Script Bundlesom också läggs till i Pythonsys.path.
Om zip-filen innehåller importerar
mymodule.pydu den därför med hjälp avimport mymodule.- En enskild datauppsättning kan returneras till Studio (klassisk), som måste vara en sekvens av typen
pandas.DataFrame. Du kan skapa andra utdata i din Python kod och skriva dem direkt till Azure Storage, eller skapa visualiseringar med hjälp av Python enheten.
- Skriptet måste innehålla en funktion med namnet
Kör experimentet eller välj modulen och klicka på Kör valt för att bara köra Python skriptet.
Alla data och all kod läses in i en virtuell dator och körs med den angivna Python miljön.
Resultat
Modulen returnerar följande utdata:
Resultatdatauppsättning. Resultatet av alla beräkningar som utförs av den inbäddade Python koden måste anges som en pandas data.frame, som automatiskt konverteras till Machine Learning datauppsättningsformat, så att du kan använda resultatet med andra moduler i experimentet. Modulen är begränsad till en enda datauppsättning som utdata. Mer information finns i Datatabell.
Python Enhet. Dessa utdata stöder både konsolutdata och visning av PNG-grafik med hjälp av Python tolken.
Så här kopplar du skriptresurser
Modulen Execute Python Script stöder godtyckliga Python skriptfiler som indata, förutsatt att de förbereds i förväg och laddas upp till din arbetsyta som en del av en .ZIP fil.
Upload en ZIP-fil som innehåller Python kod till arbetsytan
I experimentområdet i Machine Learning Studio (klassisk) klickar du på Datauppsättningar och sedan på Ny.
Välj alternativet Från lokal fil.
I dialogrutan Upload en ny datauppsättning klickar du på listrutan för Välj en typ för den nya datauppsättningen och väljer alternativet Zip-fil (.zip).
Klicka på Bläddra för att hitta den komprimerade filen.
Ange ett nytt namn som ska användas på arbetsytan. Det namn som du tilldelar till datauppsättningen blir namnet på mappen på arbetsytan där de inneslutna filerna extraheras.
När du har laddat upp det zippade paketet till Studio (klassisk) kontrollerar du att den komprimerade filen är tillgänglig i listan Sparade datauppsättningar och ansluter sedan datauppsättningen till indataporten för skriptpaket .
Alla filer som finns i ZIP-filen är tillgängliga för användning under körning: till exempel exempel exempeldata, skript eller nya Python paket.
Om den zippade filen innehåller bibliotek som inte redan är installerade i Machine Learning Studio (klassisk) måste du installera Python-bibliotekspaketet som en del av ditt anpassade skript.
Om det fanns en katalogstruktur bevaras den. Du måste dock ändra koden för att förbereda katalogen src till sökvägen.
Felsöka Python kod
Modulen Execute Python Script fungerar bäst när koden har vägts in som en funktion med tydligt definierade indata och utdata, i stället för en sekvens med löst relaterade körbara instruktioner.
Den här Python-modulen stöder inte funktioner som Intellisense och felsökning. Om modulen misslyckas vid körning kan du visa viss felinformation i utdataloggen för modulen. Den fullständiga Python stackspårningen är dock inte tillgänglig. Därför rekommenderar vi att användarna utvecklar och felsöker sina Python skript i en annan miljö och sedan importerar koden till modulen.
Några vanliga problem som du kan leta efter:
Kontrollera datatyperna i dataramen som du returnerar från
azureml_main. Fel är sannolikt om kolumner innehåller andra datatyper än numeriska typer och strängar.Ta bort NA-värden från datauppsättningen med hjälp av
dataframe.dropna()vid export från Python skript. När du förbereder dina data använder du modulen Rensa data som saknas .Kontrollera den inbäddade koden för indrag och blankstegsfel. Om du får felet "IndentationError: förväntade ett indraget block" kan du läsa följande resurser för vägledning:
Kända begränsningar
Python-körningen är begränsat och tillåter inte åtkomst till nätverket eller till det lokala filsystemet på ett beständigt sätt.
Alla filer som sparas lokalt isoleras och tas bort när modulen är klar. Den Python koden kan inte komma åt de flesta kataloger på den dator som den körs på, undantaget är den aktuella katalogen och dess underkataloger.
När du anger en zippad fil som resurs kopieras filerna från arbetsytan till experimentets körningsutrymme, packas upp och används sedan. Kopiering och uppackning av resurser kan förbruka minne.
Modulen kan mata ut en enda dataram. Det går inte att returnera godtyckliga Python objekt, till exempel tränade modeller direkt tillbaka till Studio-körningen (klassisk). Du kan dock skriva objekt till lagring eller till arbetsytan. Ett annat alternativ är att använda
pickleför att serialisera flera objekt till en bytematris och sedan returnera matrisen inuti en dataram.
Exempel
Exempel på integrering av Python skript med Studio-experiment (klassisk) finns i följande resurser i Azure AI-galleriet:
- Kör Python skript: Använd texttokenisering, ordstamsbearbetning och annan bearbetning av naturligt språk med hjälp av modulen Execute Python Script (Kör Python-skript).
- Anpassade R- och Python-skript i Azure ML: Vägleder dig genom processen att lägga till anpassad kod a(R eller Python), bearbeta data och visualisera resultaten.
- Analysera PyPI-data för att fastställa Python 3-stöd: Beräkna tidpunkten när efterfrågan på Python 3 överträffar den för Python 2.7 med python.