Funktions-hash
Viktigt
Stödet för Machine Learning Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du byter till Azure Machine Learning innan dess.
Från och med den 1 december 2021 kan du inte längre skapa nya Machine Learning Studio-resurser (klassisk). Du kan fortsätta att använda befintliga Machine Learning Studio-resurser (klassisk) till och med den 31 augusti 2024.
- Se information om hur du flyttar maskininlärningsprojekt från ML Studio (klassisk) till Azure Machine Learning.
- Läs mer om Azure Machine Learning.
Dokumentationen om ML Studio (klassisk) håller på att dras tillbaka och kanske inte uppdateras i framtiden.
Konverterar textdata till heltalskodade funktioner med hjälp av Vowpal Wabbit-biblioteket
Kategori: Textanalys
Anteckning
Gäller endast för: Machine Learning Studio (klassisk)
Liknande dra och släpp-moduler finns i Azure Machine Learning designer.
Modulöversikt
Den här artikeln beskriver hur du använder modulen Funktionshashing i Machine Learning Studio (klassisk) för att omvandla en ström av engelsk text till en uppsättning funktioner som representeras som heltal. Du kan sedan skicka den här hashade funktionen till en maskininlärningsalgoritm för att träna en textanalysmodell.
Funktionen för hashning i den här modulen baseras på Vowpal Wabbit-ramverket. Mer information finns i Träna Vowpal Wabbit 7-4 Modell eller Träna Vowpal Wabbit 7-10 Modell.
Mer om funktionshashing
Funktionshashar fungerar genom att konvertera unika token till heltal. Den fungerar på de exakta strängar som du anger som indata och utför ingen språkanalys eller förbearbetning.
Ta till exempel en uppsättning enkla meningar som dessa, följt av en attitydpoäng. Anta att du vill använda den här texten för att skapa en modell.
| USERTEXT | KÄNSLA |
|---|---|
| Jag älskade den här boken | 3 |
| Jag hatade den här boken | 1 |
| Den här boken var bra | 3 |
| Jag älskar böcker | 2 |
Internt skapar modulen Funktionshashing en ordlista med n-gram. Till exempel skulle listan med bigrams för den här datamängden vara ungefär så här:
| TERM (bigrams) | FREKVENS |
|---|---|
| Den här boken | 3 |
| Jag älskade | 1 |
| Jag hatade | 1 |
| Jag älskar | 1 |
Du kan styra storleken på n-gram med hjälp av egenskapen N-gram . Om du väljer bigrams beräknas även unigram. Ordlistan skulle därför även innehålla enkla termer som dessa:
| Term (unigram) | FREKVENS |
|---|---|
| bok | 3 |
| I | 3 |
| böcker | 1 |
| Var | 1 |
När ordlistan har skapats konverterar funktionshashmodulen ordlistetermerna till hashvärden och beräknar om en funktion användes i varje fall. För varje rad med textdata matar modulen ut en uppsättning kolumner, en kolumn för varje hashfunktion.
Efter hashning kan till exempel funktionskolumnerna se ut ungefär så här:
| Omdöme | Hashningsfunktion 1 | Hashningsfunktion 2 | Hashningsfunktion 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Om värdet i kolumnen är 0 innehåller raden inte den hashade funktionen.
- Om värdet är 1 innehöll raden funktionen.
Fördelen med att använda funktionshashing är att du kan representera textdokument med variabel längd som numeriska funktionsvektorer med samma längd och uppnå dimensionsminskning. Om du däremot försökte använda textkolumnen för träning som den är, skulle den behandlas som en kategorisk funktionskolumn med många, många distinkta värden.
Om utdata är numeriska kan du också använda många olika maskininlärningsmetoder med data, inklusive klassificering, klustring eller informationshämtning. Eftersom uppslagsåtgärder kan använda heltalshasher i stället för strängjämförelser går det också mycket snabbare att hämta funktionsvikterna.
Så här konfigurerar du funktionshashing
Lägg till modulen Funktionshashing i experimentet i Studio (klassisk).
Anslut datauppsättningen som innehåller den text som du vill analysera.
Tips
Eftersom funktionshashing inte utför lexikala åtgärder, till exempel härstamning eller trunkering, kan du ibland få bättre resultat genom att utföra förbearbetning av text innan du tillämpar funktionshashing. Förslag finns i avsnitten Metodtips och Tekniska anteckningar .
För Målkolumner väljer du de textkolumner som du vill konvertera till hashade funktioner.
Kolumnerna måste vara strängdatatypen och måste markeras som en funktionskolumn .
Om du väljer flera textkolumner som ska användas som indata kan det ha en enorm effekt på funktionsdimensionaliteten. Om till exempel en 10-bitars hash används för en enda textkolumn innehåller utdata 1 024 kolumner. Om en 10-bitars hash används för två textkolumner innehåller utdata 2 048 kolumner.
Anteckning
Som standard markerar Studio (klassisk) de flesta textkolumner som funktioner, så om du markerar alla textkolumner kan du få för många kolumner, inklusive många som faktiskt inte är fritext. Använd alternativet Rensa funktion i Redigera metadata för att förhindra att andra textkolumner hashas.
Använd Hashing-bitstorlek för att ange hur många bitar som ska användas när du skapar hash-tabellen.
Standardbitstorleken är 10. För många problem är det här värdet mer än tillräckligt, men om det räcker för dina data beror på storleken på n-gram-vokabulären i träningstexten. Med en stor vokabulär kan mer utrymme behövas för att undvika kollisioner.
Vi rekommenderar att du provar att använda ett annat antal bitar för den här parametern och utvärdera prestanda för maskininlärningslösningen.
För N-gram skriver du ett tal som definierar den maximala längden på n-gram som ska läggas till i träningsordlistan. Ett n-gram är en sekvens med n ord som behandlas som en unik enhet.
N-gram = 1: Unigram eller enkla ord.
N-gram = 2: Bigrams eller tvåordssekvenser plus unigram.
N-gram = 3: Trigram eller treordssekvenser plus bigrams och unigram.
Kör experimentet.
Resultat
När bearbetningen är klar matar modulen ut en transformerad datauppsättning där den ursprungliga textkolumnen har konverterats till flera kolumner, där var och en representerar en funktion i texten. Beroende på hur stor ordlistan är kan den resulterande datamängden vara extremt stor:
| Kolumnnamn 1 | Kolumntyp 2 |
|---|---|
| USERTEXT | Ursprunglig datakolumn |
| KÄNSLA | Ursprunglig datakolumn |
| USERTEXT – Hashningsfunktion 1 | Hashad funktionskolumn |
| USERTEXT – Hashningsfunktion 2 | Hashad funktionskolumn |
| USERTEXT – Hashningsfunktion n | Hashad funktionskolumn |
| USERTEXT – Hashningsfunktion 1024 | Hashad funktionskolumn |
När du har skapat den transformerade datauppsättningen kan du använda den som indata till modulen Träna modell , tillsammans med en bra klassificeringsmodell, till exempel Tvåklasss stödvektordator.
Bästa praxis
Några metodtips som du kan använda när du modellerar textdata visas i följande diagram som representerar ett experiment
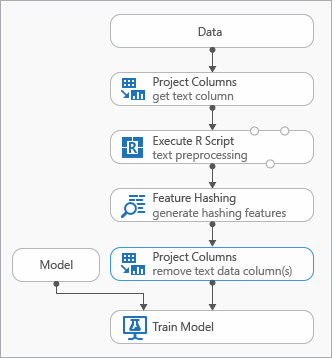
Du kan behöva lägga till en Execute R Script-modul innan du använder funktionshashing för att förbearbeta indatatexten. Med R-skript har du också flexibiliteten att använda anpassade vokabulärer eller anpassade transformeringar.
Du bör lägga till modulen Välj kolumner i datauppsättning efter modulen Funktionshassning för att ta bort textkolumnerna från utdatauppsättningen. Du behöver inte textkolumnerna när hash-funktionerna har genererats.
Du kan också använda modulen Redigera metadata för att rensa funktionsattributet från textkolumnen.
Överväg också att använda dessa förbearbetningsalternativ för text för att förenkla resultaten och förbättra noggrannheten:
- ordbrytning
- stoppa ordborttagning
- skiftlägesnormalisering
- borttagning av skiljetecken och specialtecken
- ningshantering.
Den optimala uppsättningen förbearbetningsmetoder som ska tillämpas i en enskild lösning beror på domän-, vokabulär- och affärsbehov. Vi rekommenderar att du experimenterar med dina data för att se vilka anpassade textbearbetningsmetoder som är mest effektiva.
Exempel
Exempel på hur funktionshashing används för textanalys finns i Azure AI-galleriet:
Nyhetskategorisering: Använder funktionshashing för att klassificera artiklar i en fördefinierad lista med kategorier.
Liknande företag: Använder texten i Wikipedia-artiklar för att kategorisera företag.
Textklassificering: Det här exemplet i fem delar använder text från Twitter-meddelanden för att utföra attitydanalys.
Tekniska anteckningar
Det här avsnittet innehåller implementeringsinformation, tips och svar på vanliga frågor.
Tips
Förutom att använda funktionshashing kanske du vill använda andra metoder för att extrahera funktioner från text. Exempel:
- Använd modulen Förbearbetningstext för att ta bort artefakter som stavfel eller för att förenkla förberedelse av text till hashning.
- Använd Extrahera nyckelfraser för att använda bearbetning av naturligt språk för att extrahera fraser.
- Använd Namngiven entitetsigenkänning för att identifiera viktiga entiteter.
Machine Learning Studio (klassisk) innehåller en mall för textklassificering som hjälper dig att använda modulen Funktionshashing för extrahering av funktioner.
Implementeringsdetaljer
Modulen Funktionshashing använder ett snabbt maskininlärningsramverk med namnet Vowpal Wabbit som hashar funktionsord i minnesinterna index, med hjälp av en populär öppen källkod hash-funktion som kallas murmurhash3. Den här hash-funktionen är en icke-kryptografisk hashalgoritm som mappar textindata till heltal och är populär eftersom den fungerar bra i en slumpmässig fördelning av nycklar. Till skillnad från kryptografiska hashfunktioner kan den enkelt ångras av en angripare, så att den är olämplig för kryptografiska ändamål.
Syftet med hashning är att konvertera textdokument med variabel längd till numeriska funktionsvektorer med lika längd, för att stödja dimensionsminskning och göra sökningen av funktionsvikter snabbare.
Varje hash-funktion representerar en eller flera n-gram textfunktioner (unigram eller enskilda ord, bi-gram, tri-gram osv.), beroende på antalet bitar (representeras som k) och antalet n-gram som anges som parametrar. Den projicerar funktionsnamn till det osignerade ordet för maskinarkitekturen med hjälp av algoritmen murmurhash v3 (endast 32-bitars) som sedan är AND-ed med (2^k)-1. Hash-värdet projiceras alltså ned till de första k lägre bitarna och de återstående bitarna nollställs. Om det angivna antalet bitar är 14 kan hash-tabellen innehålla 214–1 (eller 16 383) poster.
För många problem är standard-hashtabellen (bitsize = 10) mer än tillräcklig. Beroende på storleken på n-gram-vokabulären i träningstexten kan dock mer utrymme behövas för att undvika kollisioner. Vi rekommenderar att du provar att använda ett annat antal bitar för parametern Hashing bitsize och utvärdera prestanda för maskininlärningslösningen.
Förväntade indata
| Namn | Typ | Description |
|---|---|---|
| Datamängd | Datatabell | Indatauppsättning |
Modulparametrar
| Name | Intervall | Typ | Standardvärde | Description |
|---|---|---|---|---|
| Målkolumner | Valfri | ColumnSelection | StringFeature | Välj de kolumner som hashning ska tillämpas på. |
| Hashing bitsize | [1;31] | Integer | 10 | Ange antalet bitar som ska användas när du hashar de valda kolumnerna |
| N-gram | [0;10] | Integer | 2 | Ange antalet N-gram som genereras under hash-värdet. Som standard extraheras både unigram och bigrams |
Utdata
| Namn | Typ | Description |
|---|---|---|
| Transformerad datauppsättning | Datatabell | Mata ut datauppsättning med hashade kolumner |
Undantag
| Undantag | Description |
|---|---|
| Fel 0001 | Ett undantagsfel uppstår om en eller flera angivna kolumner i datauppsättningen inte kunde hittas. |
| Fel 0003 | Ett undantag inträffar om en eller flera indata är null eller tomma. |
| Fel 0004 | Ett undantag inträffar om parametern är mindre än eller lika med ett visst värde. |
| Fel 0017 | Ett undantag inträffar om en eller flera angivna kolumner har en typ som inte stöds av den aktuella modulen. |
En lista över fel som är specifika för Studio-moduler (klassiska) finns i Machine Learning Felkoder.
En lista över API-undantag finns i Machine Learning REST API-felkoder.