Träna en regressionsmodell med AutoML och Python (SDK v1)
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här artikeln får du lära dig hur du tränar en regressionsmodell med Azure Machine Learning Python SDK med hjälp av automatiserad ML i Azure Machine Learning. Den här regressionsmodellen förutsäger NYC-taxipriser.
Den här processen accepterar träningsdata och konfigurationsinställningar och itererar automatiskt genom kombinationer av olika funktionsnormaliserings-/standardiseringsmetoder, modeller och hyperparameterinställningar för att komma fram till den bästa modellen.
Du skriver kod med hjälp av Python SDK i den här artikeln. Du lär dig följande uppgifter:
- Ladda ned, transformera och rensa data med hjälp av Azure Open Datasets
- Träna en automatiserad regressionsmodell för maskininlärning
- Beräkna modellnoggrannhet
Prova följande självstudier för AutoML utan kod:
Förutsättningar
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning idag.
- Slutför snabbstarten : Kom igång med Azure Machine Learning om du inte redan har en Azure Machine Learning-arbetsyta eller en beräkningsinstans.
- När du har slutfört snabbstarten:
- Välj Notebook-filer i studion.
- Välj fliken Exempel .
- Öppna notebook-filen SDK v1/tutorials/regression-automl-nyc-taxi-data/regression-automated-ml.ipynb.
- Om du vill köra varje cell i självstudien väljer du Klona den här notebook-filen
Den här artikeln är också tillgänglig på GitHub om du vill köra den i din egen lokala miljö. Hämta de nödvändiga paketen genom att
- Installera den fullständiga
automlklienten. - Kör
pip install azureml-opendatasets azureml-widgetsför att hämta de paket som krävs.
Ladda ned och förbereda data
Importera nödvändiga paket. Paketet Öppna datauppsättningar innehåller en klass som representerar varje datakälla (NycTlcGreen till exempel) för att enkelt filtrera datumparametrar innan du laddar ned.
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Börja med att skapa en dataram för att lagra taxidata. När du arbetar i en icke-Spark-miljö tillåter Open Datasets endast nedladdning av en månads data i taget med vissa klasser att undvika MemoryError med stora datamängder.
Om du vill ladda ned taxidata hämtar du iterativt en månad i taget och innan du lägger till dem i green_taxi_df slumpmässigt urval av 2 000 poster från varje månad för att undvika att dataramen svälls upp. Förhandsgranska sedan data.
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | Extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 131969 | 2 | 2015-01-11 05:34:44 | 2015-01-11 05:45:03 | 3 | 4,84 | Ingen | Ingen | -73.88 | 40.84 | -73.94 | ... | 2 | 15,00 | 0.50 | 0.50 | 0,3 | 0,00 | 0,00 | Nan | 16.30 |
| 1129817 | 2 | 2015-01-20 16:26:29 | 2015-01-20 16:30:26 | 1 | 0.69 | Ingen | Ingen | -73.96 | 40.81 | -73.96 | ... | 2 | 4,50 | 1,00 | 0.50 | 0,3 | 0,00 | 0,00 | Nan | 6.30 |
| 1278620 | 2 | 2015-01-01 05:58:10 | 2015-01-01 06:00:55 | 1 | 0,45 | Ingen | Ingen | -73.92 | 40.76 | -73.91 | ... | 2 | 4,00 | 0,00 | 0.50 | 0,3 | 0,00 | 0,00 | Nan | 4.80 |
| 348430 | 2 | 2015-01-17 02:20:50 | 2015-01-17 02:41:38 | 1 | 0,00 | Ingen | Ingen | -73.81 | 40.70 | -73.82 | ... | 2 | 12.50 | 0.50 | 0.50 | 0,3 | 0,00 | 0,00 | Nan | 13.80 |
| 1269627 | 1 | 2015-01-01 05:04:10 | 2015-01-01 05:06:23 | 1 | 0.50 | Ingen | Ingen | -73.92 | 40.76 | -73.92 | ... | 2 | 4,00 | 0.50 | 0.50 | 0 | 0,00 | 0,00 | Nan | 5.00 |
| 811755 | 1 | 2015-01-04 19:57:51 | 2015-01-04 20:05:45 | 2 | 1.10 | Ingen | Ingen | -73.96 | 40.72 | -73.95 | ... | 2 | 6.50 | 0.50 | 0.50 | 0,3 | 0,00 | 0,00 | Nan | 7,80 |
| 737281 | 1 | 2015-01-03 12:27:31 | 2015-01-03 12:33:52 | 1 | 0.90 | Ingen | Ingen | -73.88 | 40.76 | -73.87 | ... | 2 | 6,00 | 0,00 | 0.50 | 0,3 | 0,00 | 0,00 | Nan | 6.80 |
| 113951 | 1 | 2015-01-09 23:25:51 | 2015-01-09 23:39:52 | 1 | 3.30 | Ingen | Ingen | -73.96 | 40.72 | -73.91 | ... | 2 | 12.50 | 0.50 | 0.50 | 0,3 | 0,00 | 0,00 | Nan | 13.80 |
| 150436 | 2 | 2015-01-11 17:15:14 | 2015-01-11 17:22:57 | 1 | 1.19 | Ingen | Ingen | -73.94 | 40.71 | -73.95 | ... | 1 | 7.00 | 0,00 | 0.50 | 0,3 | 1,75 | 0,00 | Nan | 9.55 |
| 432136 | 2 | 2015-01-22 23:16:33 2015-01-22 23:20:13 1 0.65 | Ingen | Ingen | -73.94 | 40.71 | -73.94 | ... | 2 | 5.00 | 0.50 | 0.50 | 0,3 | 0,00 | 0,00 | Nan | 6.30 |
Ta bort några av de kolumner som du inte behöver för träning eller andra funktioner. Automatisera maskininlärning hanterar automatiskt tidsbaserade funktioner som lpepPickupDatetime.
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Rensa data
describe() Kör funktionen på den nya dataramen för att se sammanfattningsstatistik för varje fält.
green_taxi_df.describe()
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | month_num day_of_month | day_of_week | hour_of_day |
|---|---|---|---|---|---|---|---|---|---|---|
| antal | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 |
| medelvärde | 1.78 | 1,37 | 2,87 | -73.83 | 40.69 | -73.84 | 40.70 | 14.75 | 6.50 | 15.13 |
| st.av | 0.41 | 1,04 | 2.93 | 2.76 | 1.52 | 2.61 | 1.44 | 12.08 | 3.45 | 8.45 |
| min | 1.00 | 0,00 | 0,00 | -74.66 | 0,00 | -74.66 | 0,00 | -300.00 | 1.00 | 1.00 |
| 25 % | 2.00 | 1,00 | 1.06 | -73.96 | 40.70 | -73.97 | 40.70 | 7,80 | 3.75 | 8.00 |
| 50 % | 2.00 | 1,00 | 1.90 | -73.94 | 40.75 | -73.94 | 40.75 | 11.30 | 6.50 | 15,00 |
| 75 % | 2.00 | 1,00 | 3.60 | -73.92 | 40.80 | -73.91 | 40.79 | 17.80 | 9.25 | 22,00 |
| max | 2.00 | 09:00 | 97.57 | 0,00 | 41.93 | 0,00 | 41.94 | 450.00 | 12,00 | 30,00 |
I sammanfattningsstatistiken ser du att det finns flera fält som har avvikande värden eller värden som minskar modellens noggrannhet. Filtrera först lat/long-fälten så att de är inom gränserna för Manhattan-området. Detta filtrerar bort längre taxiresor eller resor som är avvikande när det gäller deras relation till andra funktioner.
Filtrera dessutom fältet så att det tripDistance är större än noll men mindre än 31 miles (haversinavståndet mellan de två lat/långa paren). Detta eliminerar långa avvikande resor som har inkonsekventa resekostnader.
Slutligen har fältet totalAmount negativa värden för taxipriser, vilket inte är meningsfullt i samband med vår modell, och passengerCount fältet har dåliga data med minimivärdena noll.
Filtrera bort dessa avvikelser med hjälp av frågefunktioner och ta sedan bort de sista kolumnerna som inte behövs för träning.
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Anropa describe() igen på data för att säkerställa att rensningen fungerade som förväntat. Nu har du en förberedd och rengjord uppsättning taxi-, semester- och väderdata som ska användas för maskininlärningsmodellträning.
final_df.describe()
Konfigurera arbetsyta
Skapa ett arbetsyteobjekt från den befintliga arbetsytan. En arbetsyta är en klass som accepterar din Azure-prenumeration och resursinformation. Den skapar också en molnresurs för att övervaka och spåra dina körningar i modellen. Workspace.from_config() läser filen config.json och läser in autentiseringsinformationen i ett objekt med namnet ws. ws används i resten av koden i den här artikeln.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Dela data till uppsättningar för träning och testning
Dela upp data i tränings- och testuppsättningar med hjälp train_test_split av funktionen i scikit-learn biblioteket. Den här funktionen separerar data i datauppsättningen x (funktioner) för modellträning och datauppsättningen y (värden att förutsäga) för testning.
Parametern test_size anger procentandelen av data som ska allokeras till testning. Parametern random_state anger ett frö till den slumpmässiga generatorn, så att dina träningstestsplitter är deterministiska.
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Syftet med det här steget är att ha datapunkter för att testa den färdiga modell som inte har använts för att träna modellen, detta för att mäta den äkta noggrannheten.
Med andra ord bör en korrekt tränad modell kunna göra noggranna förutsägelser från data som den inte redan har sett. Nu har du data förberedda för automatisk träning av en maskininlärningsmodell.
Träna en modell automatiskt
För att träna en modell automatiskt gör du följande:
- Definiera inställningar för körningen av experimentet. Koppla dina träningsdata till konfigurationen och ändra de inställningar som styr träningsprocessen.
- Skicka experimentet för modelljustering. När experimentet har skickats itererar processen genom olika maskininlärningsalgoritmer och inställningar för hyperparametrar enligt dina definierade begränsningar. Den väljer den modell som passar bäst genom att optimera ett noggrannhetsmått.
Definiera träningsinställningar
Definiera experimentparametern och modellinställningarna för träning. Visa hela listan med inställningar. Det tar ungefär 5–20 min att skicka experimentet med dessa standardinställningar, men om du vill ha en kortare körningstid kan du minska parametern experiment_timeout_hours .
| Property | Värde i den här artikeln | beskrivning |
|---|---|---|
| iteration_timeout_minutes | 10 | Tidsgräns i minuter för varje iteration. Öka det här värdet för större datamängder som behöver mer tid för varje iteration. |
| experiment_timeout_hours | 0,3 | Maximal tid i timmar som alla iterationer tillsammans kan ta innan experimentet avslutas. |
| enable_early_stopping | Sant | Flagga för att aktivera tidig avslutning om poängen inte förbättras på kort sikt. |
| primary_metric | spearman_correlation | Mått som du vill optimera. Modellen med bästa passform väljs baserat på det här måttet. |
| funktionalisering | auto | Genom att använda automatiskt kan experimentet förbearbeta indata (hantera saknade data, konvertera text till numeriskt osv.) |
| verbosity | logging.INFO | Styr loggningsnivån. |
| n_cross_validations | 5 | Antal korsvalideringsdelningar som ska utföras när valideringsdata inte har angetts. |
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Använd dina definierade träningsinställningar som en **kwargs parameter för ett AutoMLConfig objekt. Ange även dina träningsdata och modelltypen, som i det här fallet är regression.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Kommentar
Förbearbetningssteg för automatiserad maskininlärning (funktionsnormalisering, hantering av saknade data, konvertering av text till numeriska osv.) blir en del av den underliggande modellen. När du använder modellen för förutsägelser tillämpas samma förbearbetningssteg som tillämpas under träningen på dina indata automatiskt.
Träna den automatiska regressionsmodellen
Skapa ett experimentobjekt på din arbetsyta. Ett experiment fungerar som en container för dina enskilda jobb. Skicka det definierade automl_config objektet till experimentet och ange utdata till True för att visa förloppet under jobbet.
När experimentet har startats uppdateras de utdata som visas live när experimentet körs. För varje iteration ser du modelltypen, körningens varaktighet samt träningens noggrannhet. Fältet BEST spårar den bästa löpande körningspoängen utifrån din måttyp.
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Utforska resultaten
Utforska resultatet av automatisk träning med en Jupyter-widget. Med widgeten kan du se ett diagram och en tabell med alla enskilda jobb-iterationer, tillsammans med träningsnoggrannhetsmått och metadata. Dessutom kan du filtrera på olika noggrannhetsmått än ditt primära mått med listruteväljaren.
from azureml.widgets import RunDetails
RunDetails(local_run).show()
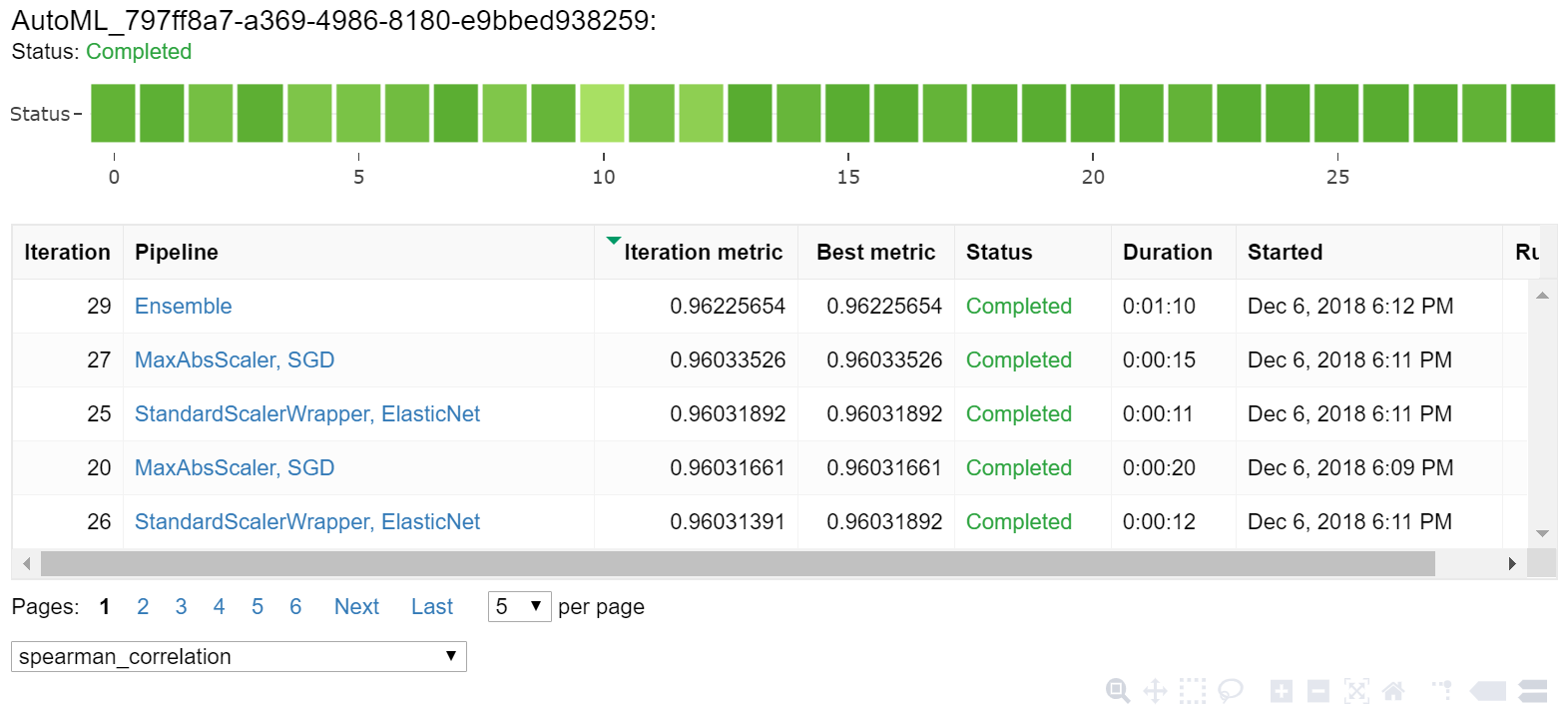
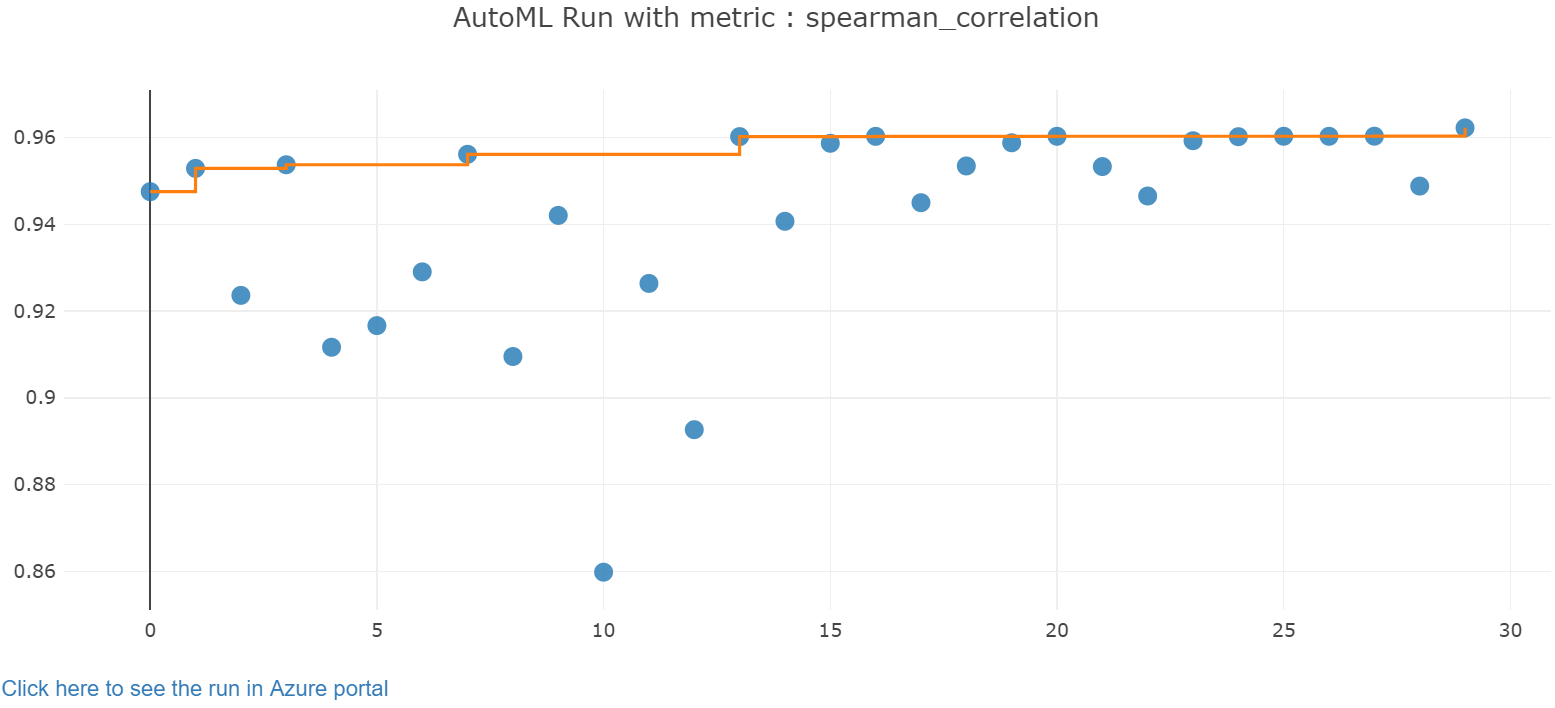
Hämta den bästa modellen
Välj den bästa modellen från dina iterationer. Funktionen get_output returnerar den bästa körningen och den anpassade modellen för den senaste anropet. Genom att använda överlagringarna på get_outputkan du hämta den bästa körningsmodellen och den anpassade modellen för alla loggade mått eller en viss iteration.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Testa den bästa modellens precision
Använd den bästa modellen för att köra förutsägelser på testdatauppsättningen för att förutsäga taxipriser. Funktionen predict använder den bästa modellen och förutsäger värdena för y, resekostnad, från datauppsättningen x_test . Skriv ut de 10 första förutsagda kostnadsvärdena från y_predict.
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Beräkna root mean squared error för resultatet. Konvertera dataramen y_test till en lista för att jämföra med de förutsagda värdena. Funktionen mean_squared_error tar emot två matriser med värden och beräknar det genomsnittliga kvadratfelet mellan dem. Att ta kvadratroten ur resultatet ger ett fel i samma enheter som y-variabeln, kostnad. Det indikerar ungefär hur långt taxiprisförutsägelserna är från de faktiska priserna.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Kör följande kod för att beräkna genomsnittligt absolut procentfel (MAPE) med hjälp av de fullständiga y_actual datauppsättningarna och y_predict datauppsättningarna. Det här måttet beräknar en absolut skillnad mellan varje förväntat och faktiskt värde och summerar alla skillnaderna. Sedan uttrycker den summan som en procent av summan av de faktiska värdena.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
Från de två förutsägelsenoggrannhetsmåtten ser du att modellen är ganska bra på att förutsäga taxipriser från datamängdens funktioner, vanligtvis inom +- 4,00 USD och cirka 15 % fel.
Utvecklingsprocessen för maskininlärningsmodeller är mycket resurskrävande och fordrar betydande domänkunskap och tid för att köra och jämföra resultat från flera olika modeller. Användning av automatisk maskininlärning är ett bra sätt att snabbt testa flera olika modeller för ett scenario.
Rensa resurser
Slutför inte det här avsnittet om du planerar att köra andra Azure Machine Learning-självstudier.
Stoppa beräkningsinstansen
Om du använde en beräkningsinstans stoppar du den virtuella datorn när du inte använder den för att minska kostnaderna.
På din arbetsyta väljer du Beräkning.
I listan väljer du namnet på beräkningsinstansen.
Välj Stoppa.
När du är redo att använda servern igen väljer du Start.
Ta bort allt
Om du inte planerar att använda de resurser som du har skapat tar du bort dem så att du inte debiteras några avgifter.
- I Azure-portalen väljer du Resursgrupper längst till vänster.
- Välj den resursgrupp i listan som du har skapat.
- Välj Ta bort resursgrupp.
- Ange resursgruppsnamnet. Välj sedan ta bort.
Du kan också behålla resursgruppen men ta bort en enstaka arbetsyta. Visa arbetsytans egenskaper och välj Ta bort.
Nästa steg
I den här automatiserade maskininlärningsartikeln utförde du följande uppgifter:
- Konfigurerat en arbetsyta och förberett data för ett experiment.
- Tränat med hjälp av en automatiserad regressionsmodell lokalt med anpassade parametrar.
- Utforskat och granskat träningsresultat.
Konfigurera AutoML för att träna modeller för visuellt innehåll med Python (v1)