Bu makalede, mikro hizmet mimarisindeki verileri yönetmeyle ilgili önemli noktalar açıklanmaktadır. Her mikro hizmet kendi verilerini yönettiğinden, veri bütünlüğü ve veri tutarlılığı kritik zorluklardır.
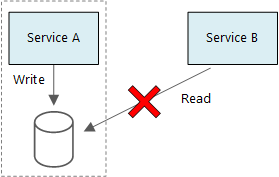
Mikro hizmetlerin temel ilkelerinden biri, her hizmetin kendi verilerini yönetmesidir. İki hizmet veri depolarını paylaşmamalıdır. Bunun yerine her hizmet, diğer hizmetlerin doğrudan erişemediği kendi özel veri deposundan sorumludur.
Bu kuralın nedeni, hizmetler arasında yanlışlıkla eşleştirmeyi önlemektir; bu da hizmetlerin aynı temel veri şemalarını paylaşması durumunda sonuçlanabilir. Veri şemasında bir değişiklik varsa, değişikliğin bu veritabanına bağlı olan her hizmette eşgüdümlü olması gerekir. Her hizmetin veri deposunu yalıtarak, değişiklik kapsamını sınırlandırabilir ve gerçekten bağımsız dağıtımların çevikliğini koruyabiliriz. Bir diğer neden de her mikro hizmetin kendi veri modellerine, sorgularına veya okuma/yazma desenlerine sahip olmasıdır. Paylaşılan veri deposu kullanmak, her ekibin kendi hizmetleri için veri depolama alanını iyileştirme becerisini sınırlar.
Bu yaklaşım doğal olarak çok yönlü kalıcılığa yol açar; tek bir uygulama içinde birden çok veri depolama teknolojisinin kullanılması. Bir hizmet, belge veritabanının şema üzerinde okuma özelliklerini gerektirebilir. Bir diğerinde ise RDBMS tarafından sağlanan bilgi tutarlılığı gerekebilir. Her ekip, hizmetleri için en iyi seçimi yapmak için ücretsizdir.
Dekont
Hizmetlerin aynı fiziksel veritabanı sunucusunu paylaşması normaldir. Sorun, hizmetler aynı şemayı paylaştığında veya aynı veritabanı tabloları kümesine okuma ve yazma gerçekleştirdiğinde oluşur.
Zorluklar
Verileri yönetmeye yönelik bu dağıtılmış yaklaşımdan kaynaklanan bazı zorluklar ortaya çıkar. İlk olarak, veri depolarında yedeklilik olabilir ve aynı veri öğesi birden çok yerde görünür. Örneğin, veriler bir işlemin parçası olarak depolanabilir, ardından analiz, raporlama veya arşivleme için başka bir yerde depolanabilir. Yinelenen veya bölümlenmiş veriler, veri bütünlüğü ve tutarlılığı sorunlarına yol açabilir. Veri ilişkileri birden çok hizmete yayıldığında, ilişkileri zorunlu kılmak için geleneksel veri yönetimi tekniklerini kullanamazsınız.
Geleneksel veri modellemesi "tek bir yerde bir olgu" kuralını kullanır. Her varlık şemada tam olarak bir kez görünür. Diğer varlıklar, başvurularını barındırabilir ancak yinelemeyebilir. Geleneksel yaklaşımın belirgin avantajı, güncelleştirmelerin tek bir yerde yapılmasıdır ve bu da veri tutarlılığıyla ilgili sorunları önler. Mikro hizmet mimarisinde güncelleştirmelerin hizmetler arasında nasıl yayıldığından ve veriler güçlü tutarlılık olmadan birden çok yerde göründüğünde nihai tutarlılığın nasıl yönetileceğini düşünmeniz gerekir.
Verileri yönetme yaklaşımları
Her durumda doğru olan tek bir yaklaşım yoktur, ancak mikro hizmet mimarisindeki verileri yönetmeye yönelik bazı genel yönergeler aşağıdadır.
Mümkün olduğunda nihai tutarlılık yaklaşımını benimseyin. Sistemde güçlü tutarlılık veya ACID işlemlerine ihtiyaç duyduğunuz yerleri ve nihai tutarlılığın kabul edilebilir olduğu yerleri anlayın.
Güçlü tutarlılık garantilerine ihtiyacınız olduğunda, bir hizmet api aracılığıyla kullanıma sunulan belirli bir varlığın gerçek kaynağını temsil edebilir. Diğer hizmetler, verilerin kendi kopyasını veya verilerin bir alt kümesini barındırabilir. Bu, nihai olarak ana verilerle tutarlıdır ancak gerçek kaynağı olarak kabul edilmez. Örneğin, müşteri sipariş hizmeti ve öneri hizmeti içeren bir e-ticaret sistemi düşünün. Öneri hizmeti sipariş hizmetinden gelen olayları dinlenebilir, ancak müşteri para iadesi isterse, işlem geçmişinin tamamına sahip olan öneri hizmeti değil sipariş hizmetidir.
İşlemler için, çeşitli hizmetlerde verilerin tutarlı olmasını sağlamak için Scheduler Aracı Gözetmen ve Telafi İşlemi gibi desenleri kullanın. Birden çok hizmet arasında kısmi hata oluşmasını önlemek için birden çok hizmete yayılan bir çalışma biriminin durumunu yakalayan ek bir veri parçası depolamanız gerekebilir. Örneğin, çok adımlı bir işlem devam ederken bir iş öğesini dayanıklı bir kuyrukta tutun.
Yalnızca bir hizmetin ihtiyaç duyduğu verileri depolayın. Bir hizmetin yalnızca bir etki alanı varlığıyla ilgili bir bilgi alt kümesine ihtiyacı olabilir. Örneğin, Sevkiyat sınırlanmış bağlamında, belirli bir teslimatla ilişkili müşteriyi bilmemiz gerekir. Ancak müşterinin Hesap sınırlanmış bağlamı tarafından yönetilen fatura adresine ihtiyacımız yoktur. Etki alanı hakkında dikkatli düşünmek ve bir DDD yaklaşımı kullanmak burada yardımcı olabilir.
Hizmetlerinizin uyumlu ve gevşek bir şekilde bağlı olup olmadığını göz önünde bulundurun. İki hizmet birbiriyle sürekli bilgi alışverişinde bulunuyorsa ve bu da sohbetli API'lerle sonuçlanıyorsa, iki hizmeti birleştirerek veya işlevlerini yeniden düzenleyerek hizmet sınırlarınızı yeniden çizmeniz gerekebilir.
Olay temelli mimari stili kullanın. Bu mimari stilinde bir hizmet, ortak modellerinde veya varlıklarında değişiklikler olduğunda bir olay yayımlar. İlgili hizmetler bu olaylara abone olabilir. Örneğin, başka bir hizmet sorguları için daha uygun olan verilerin gerçekleştirilmiş bir görünümünü oluşturmak için olayları kullanabilir.
Olayların sahibi olan bir hizmet, yayımcılar ve aboneler arasında sıkı bir bağlantı oluşmasını önlemek için olayları seri hale getirmek ve seri durumdan çıkarma işlemini otomatikleştirmek için kullanılabilecek bir şema yayımlamalıdır. JSON şemasını veya Microsoft Bond, Protobuf veya Avro gibi bir çerçeveyi göz önünde bulundurun.
Yüksek ölçekte olaylar sistemde bir performans sorununa neden olabilir, bu nedenle toplam yükü azaltmak için toplama veya toplu işlem kullanmayı göz önünde bulundurun.
Örnek: İnsansız Hava Aracı ile Teslimat uygulaması için veri depolarını seçme
Bu serinin önceki makalelerinde çalışan bir örnek olarak insansız hava aracı teslim hizmeti ele alınıyor. Senaryo ve ilgili başvuru uygulaması hakkında daha fazla bilgiyi burada okuyabilirsiniz. Bu örnek, uçak ve havacılık sektörleri için idealdir.
Özetlemek gerekirse, bu uygulama insansız hava aracıyla teslimatları zamanlamak için birkaç mikro hizmet tanımlar. Kullanıcı yeni bir teslimat zamanladığında, istemci isteği teslim alma ve bırakma konumları gibi teslimatla ilgili bilgileri ve paketle ilgili boyut ve ağırlık gibi bilgileri içerir. Bu bilgiler bir çalışma birimini tanımlar.
Çeşitli arka uç hizmetleri, istekteki bilgilerin farklı bölümlerini dikkate alır ve ayrıca farklı okuma ve yazma profillerine sahiptir.
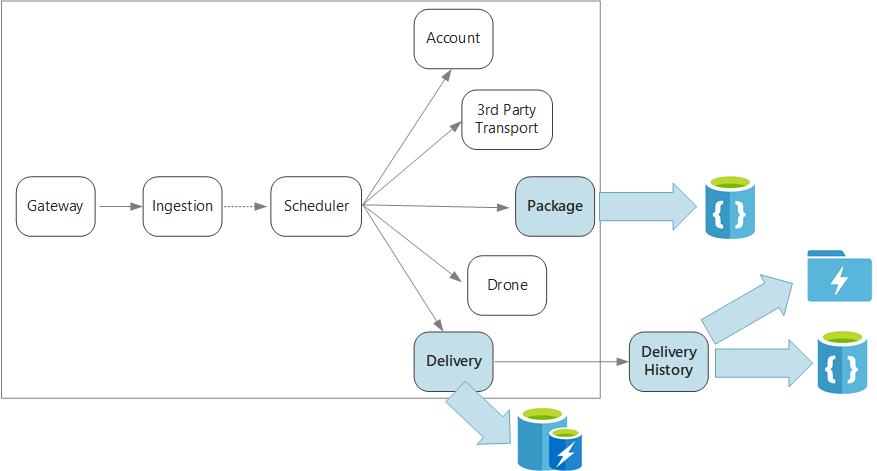
Teslimat hizmeti
Teslim hizmeti, şu anda zamanlanmış veya devam eden her teslimatla ilgili bilgileri depolar. İnsansız hava araçlarından gelen olayları dinler ve devam eden teslimatların durumunu izler. Ayrıca, teslim durumu güncelleştirmeleri olan etki alanı olaylarını da gönderir.
Kullanıcıların paketi beklerken sık sık teslim durumunu denetlemesi beklenir. Bu nedenle Teslim hizmeti, uzun süreli depolama alanı üzerinde aktarım hızını (okuma ve yazma) vurgulayan bir veri deposu gerektirir. Ayrıca, Teslim hizmeti herhangi bir karmaşık sorgu veya analiz gerçekleştirmez, yalnızca belirli bir teslim için en son durumu getirir. Teslim hizmeti ekibi, yüksek okuma-yazma performansı için Redis için Azure Cache seçti. Redis'te depolanan bilgiler nispeten kısa ömürlüdür. Teslim tamamlandıktan sonra Teslim Geçmişi hizmeti kayıt sistemidir.
Teslimat Geçmişi hizmeti
Teslim Geçmişi hizmeti, Teslim hizmetinden gelen teslim durumu olaylarını dinler. Bu verileri uzun vadeli depolama alanında depolar. Bu geçmiş veriler için farklı veri depolama gereksinimlerine sahip iki farklı kullanım örneği vardır.
İlk senaryo, işletmeyi iyileştirmek veya hizmetin kalitesini artırmak için verileri veri analizi amacıyla toplamaktır. Teslim Geçmişi hizmetinin verilerin gerçek analizini gerçekleştirmediğini unutmayın. Yalnızca alım ve depolamadan sorumludur. Bu senaryoda, depolamanın çeşitli veri kaynaklarını barındırmak için okundu şeması yaklaşımı kullanılarak büyük bir veri kümesi üzerinde veri analizi için en iyi duruma getirilmelidir. Azure Data Lake Store bu senaryo için uygundur. Data Lake Store, Hadoop Dağıtılmış Dosya Sistemi (HDFS) ile uyumlu bir Apache Hadoop dosya sistemidir ve veri analizi senaryoları için performans için ayarlanmıştır.
Diğer senaryo ise kullanıcıların teslimat tamamlandıktan sonra teslim geçmişini aramalarını sağlamaktır. Azure Data Lake bu senaryo için iyileştirilmemiştir. En iyi performans için Microsoft, zaman serisi verilerinin Data Lake'te tarihe göre bölümlenmiş klasörlerde depolanmasını önerir. (Bkz. Performans için Azure Data Lake Store'un ayarlanması). Ancak bu yapı, kimliklerine göre tek tek kayıtları aramak için uygun değildir. Zaman damgasını da bilmiyorsanız, kimliğine göre arama, koleksiyonun tamamını taramayı gerektirir. Bu nedenle, Teslim Geçmişi hizmeti daha hızlı arama için Azure Cosmos DB'de geçmiş verilerin bir alt kümesini de depolar. Kayıtların süresiz olarak Azure Cosmos DB'de kalması gerekmez. Eski teslimatlar bir ay sonra arşivlenebilir. Bu, ara sıra bir toplu işlem çalıştırılarak yapılabilir. Eski verilerin arşivlenmesi Cosmos DB maliyetlerini düşürürken, verileri Data Lake'ten geçmişe dönük raporlama için kullanılabilir durumda tutmaya devam edebilir.
Paket hizmeti
Paket hizmeti tüm paketler hakkındaki bilgileri depolar. Paket için depolama gereksinimleri şunlardır:
- Uzun süreli depolama.
- Yüksek yazma aktarım hızı gerektiren yüksek hacimli paketleri işleyebilir.
- Paket kimliğine göre basit sorguları destekleyin. Bilgi tutarlılığı için karmaşık birleşimler veya gereksinimler yoktur.
Paket verileri ilişkisel olmadığından, belge odaklı bir veritabanı uygundur ve Azure Cosmos DB parçalı koleksiyonları kullanarak yüksek aktarım hızı elde edebilir. Paket hizmeti üzerinde çalışan ekip MEAN yığınına (MongoDB, Express.js, AngularJS ve Node.js) aşina olduğundan Azure Cosmos DB için MongoDB API'sini seçer. Bu sayede MongoDB ile mevcut deneyimlerinden yararlanarak yönetilen bir Azure hizmeti olan Azure Cosmos DB'nin avantajlarından yararlanabilirler.
Sonraki adımlar
Mikro hizmet mimarisindeki bazı yaygın zorlukları azaltmaya yardımcı olabilecek tasarım desenleri hakkında bilgi edinin.