解决方案构想
本文是一种解决方案构想。 如果你希望我们在内容中扩充更多信息,例如潜在用例、备用服务、实现注意事项或定价指南,请通过提供 GitHub 反馈来告知我们。
在 Azure 中实现自定义自然语言处理 (NLP) 解决方案。 将 Spark NLP 用于主题和情绪检测与分析等任务。
Apache®、Apache Spark 和火焰徽标是 Apache Software Foundation 在美国和/或其他国家/地区的商标或注册商标。 使用这些标记并不暗示获得 Apache Software Foundation 的认可。
体系结构

下载此体系结构的 Visio 文件。
工作流
- Azure 事件中心、Azure 数据工厂或两个服务都接收文档或非结构化文本数据。
- 事件中心和数据工厂以文件格式将数据存储在 Azure Data Lake Storage 中。 建议设置符合业务需求的目录结构。
- Azure 计算机视觉 API 使用其光学字符识别 (OCR) 功能来处理数据。 然后,API 将数据写入 bronze 层。 此消耗平台采用 lakehouse 体系结构。
- 在 bronze 层中,各种 Spark NLP 功能对文本进行预处理。 示例包括拆分、更正拼写、清理和理解语法。 建议在 bronze 层运行文档分类,然后将结果写入 silver 层。
- 在 silver 层中,高级 Spark NLP 功能执行文档分析任务,例如命名实体识别、摘要和信息检索。 在某些体系结构中,结果将写入 gold 层。
- 在 gold 层中,Spark NLP 对文本数据运行各种语言视觉对象分析。 这些分析提供语言依赖项的见解,并帮助可视化 NER 标签。
- 用户以数据框的形式查询 gold 层文本数据,并在 Power BI 或 Web 应用中查看结果。
在处理步骤中,Azure Databricks、Azure Synapse Analytics 和 Azure HDInsight 与 Spark NLP 配合使用,以提供 NLP 功能。
组件
- Data Lake Storage 是与 Hadoop 兼容的文件系统,具有集成的分层命名空间以及 Azure Blob 存储的规模效应和经济高效性。
- Azure Synapse Analytics 是用于数据仓库和大数据系统的分析服务。
- Azure Databricks 是一种适用于大数据的分析服务,易于使用、促进协作,并且基于 Apache Spark。 Azure Databricks 专为数据科学和数据工程而设计。
- 事件中心引入客户端应用程序生成的数据流。 事件中心存储流式处理数据并保留收到的事件序列。 使用者可以连接到中心终结点,以检索要处理的消息。 如该解决方案所示,事件中心与 Data Lake Storage 集成。
- Azure HDInsight 是面向企业的云中的托管、全方位、开源分析服务。 可以将开源框架与 Azure HDInsight 结合使用,例如 Hadoop、Apache Spark、Apache Hive、LLAP、Apache Kafka、Apache Storm 和 R。
- 数据工厂自动在安全级别不同的存储帐户之间移动数据,以确保职责分离。
- 计算机视觉使用文本识别 API 来识别图像中的文本并提取该信息。 读取 API 使用最新的识别模型,并针对有大量文本的大型文档和杂乱图像进行了优化。 OCR API 未针对大型文档进行优化,但支持的语言比读取 API 多。 该解决方案使用 OCR 生成 hOCR 格式的数据。
方案详细信息
自然语言处理 (NLP) 有很多用途:情绪分析、主题检测、语言检测、关键短语提取和文档归类。
Apache Spark 是并行处理框架,支持使用内存中处理来提升大数据分析应用程序的性能。 Azure Synapse Analytics、Azure HDInsight 和 Azure Databricks 提供对 Spark 的访问权限,并利用其处理能力。
对于自定义 NLP 工作负载,开源库 Spark NLP 充当处理大量文本的有效框架。 本文介绍了 Azure 中大规模自定义 NLP 的解决方案。 该解决方案使用 Spark NLP 功能来处理和分析文本。 有关 Spark NLP 的详细信息,请参阅本文后面的 Spark NLP 功能和管道。
可能的用例
文档分类:Spark NLP 提供了多个文本分类选项:
- Spark NLP 中的文本预处理和基于 Spark ML 的机器学习算法
- Spark NLP 和机器学习算法(如 GloVe、BERT 和 ELMo)中的文本预处理和单词嵌入
- Spark NLP 和机器学习算法以及通用句子编码器等模型中的文本预处理和句子嵌入
- Spark NLP 中的文本预处理和分类,使用 ClassifierDL 注释器并基于 TensorFlow
名称实体提取 (NER):在 Spark NLP 中,只需几行代码,就可以训练使用 BERT 的 NER 模型,并且可以达到最先进的准确度。 NER 是信息提取的子任务。 NER 在非结构化文本中定位命名实体,并将它们分类为预定义的类别,例如人名、组织、位置、医疗代码、时间表达式、数量、货币价值和百分比。 Spark NLP 使用具有 BERT 的最先进的 NER 模型。 该模型的灵感来自于以前的 NER 模型双向 LSTM-CNN。 此前身模型使用一种新颖的神经网络体系结构,可以自动检测单词级别和字符级别的特征。 为此,该模型采用了混合的双向 LSTM 和 CNN 体系结构,因此无需进行大部分的特征工程。
情绪和情感检测:Spark NLP 可以自动检测语言的正面、负面和中立面。
词性 (POS):此功能为输入文本中的每个标记分配一个语法标签。
句子检测 (SD):SD 基于一种常规用途神经网络模型进行句子边界检测,用于识别文本中的句子。 许多 NLP 任务将句子作为输入单元。 这些任务的示例包括 POS 标记、依赖项分析、命名实体识别和机器翻译。
Spark NLP 功能和管道
Spark NLP 提供 Python、Java 和 Scala 库,这些库提供传统 NLP 库(例如 spaCy、NLTK、Stanford CoreNLP 和 Open NLP)的全部功能。 Spark NLP 还提供拼写检查、情绪分析和文档分类等功能。 Spark NLP 通过提供最先进的准确度、速度和可伸缩性,改进了以前的工作。
Spark NLP 是迄今为止最快的开源 NLP 库。 最近的公开基准表明,Spark NLP 比 spaCy 快 38 倍和 80 倍,在训练自定义模型方面准确度相当。 Spark NLP 是唯一可以使用分布式 Spark 群集的开放源代码库。 Spark NLP 是 Spark ML 的本机扩展,可直接对数据帧进行操作。 因此,在群集上加速会导致另一个数量级的性能增益。 由于每个 Spark NLP 管道都是 Spark ML 管道,因此 Spark NLP 非常适合生成统一的 NLP 和机器学习管道,例如文档分类、风险预测和推荐管道。
除了卓越的性能,Spark NLP 还为越来越多的 NLP 任务提供了最先进的准确度。 Spark NLP 团队定期阅读最新的相关学术论文,生成最准确的模型。
对于 NLP 管道的执行顺序,Spark NLP 遵循与传统 Spark ML 机器学习模型相同的开发概念。 但 Spark NLP 应用 NLP 技术。 下图显示了 Spark NLP 管道的核心组件。
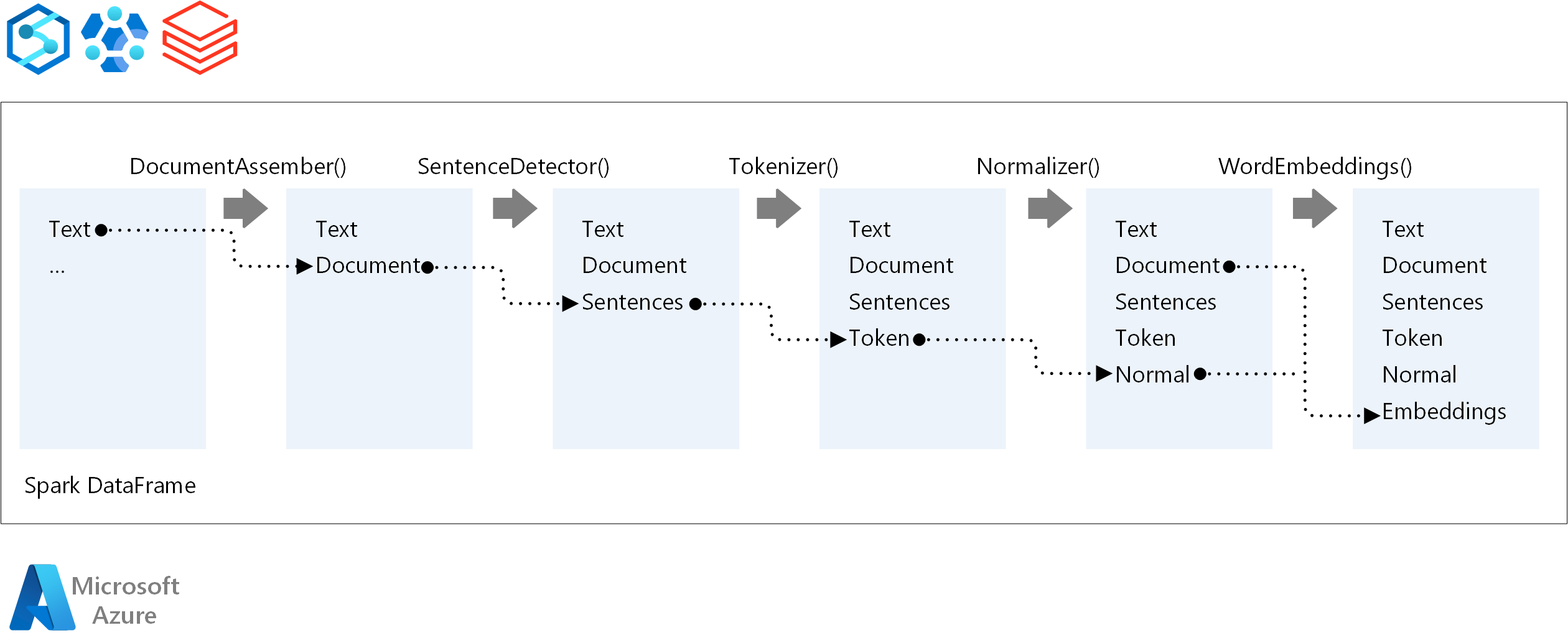
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
主要作者:
- Moritz Steller | 高级云解决方案架构师
后续步骤
Spark NLP 文档:
Azure 组件: