在机器学习工作室(经典)中评估模型性能
适用于: 机器学习工作室(经典)
机器学习工作室(经典) Azure 机器学习
Azure 机器学习
重要
对机器学习工作室(经典)的支持将于 2024 年 8 月 31 日结束。 建议在该日期之前转换到 Azure 机器学习。
从 2021 年 12 月 1 日开始,你将无法创建新的机器学习工作室(经典)资源。 在 2024 年 8 月 31 日之前,可继续使用现有的机器学习工作室(经典)资源。
ML 工作室(经典)文档即将停用,将来可能不会更新。
本文介绍可用于监视机器学习工作室(经典)中的模型性能的指标。 评估模型性能是数据科学过程的核心阶段之一。 它指示训练的模型为某个数据集评分的成功程度。 机器学习工作室(经典)通过它的两个主要机器学习模块支持模型评估:
这些模型允许查看模型在一些机器学习中常用的指标和统计信息方面性能如何。
在考虑对模型进行评估时,应同时考虑以下因素:
显示了三个常见的监督学习方案:
- 回归
- 二元分类
- 多类分类
评估与交叉验证
评估和交叉验证是测量模型性能的标准方法。 它们都生成可检查或与其他模型比较的评估指标。
评估模型预期使用评分数据集作为输入(如果要比较两个不同模型的性能,则为 2)。 因此,你需要使用训练模型模块训练模型并使用评分模型模块对某些数据集进行预测,才能评估结果。 评估基于评分标签/概率以及真实标签,所有这些均由评分模型模块输出。
此外,可使用交叉验证对输入数据的不同子集自动执行大量训练-评分-评估操作(10 折)。 输入数据拆分为 10 个部分,其中一个部分保留用于测试,其他 9 个部分用于训练。 此过程重复 10 次,取评估指标的平均值。 这有助于确定模型对新数据集的一般化程度。 交叉验证模型模块接受未训练的模型和某些已标记的数据集,并且除了平均结果以外,还输出 10 折中每一折的评估结果。
在以下部分中,我们将使用评估模型和交叉验证模型模块生成简单的回归和分类模型,并评估其性能。
评估回归模型
假设我们要使用某些特征(如尺寸、马力、引擎规格等)预测一辆汽车的价格。 这是典型的回归问题,其中目标变量(价格)是一个连续数值。 我们可以采用一个线性回归模型,该模型可在给定特定汽车的特征值的情况下预测该汽车的价格。 此回归模型可用于为我们训练所用的相同数据集评分。 得到预测的汽车价格后,我们可以通过查看预测与实际价格的平均偏离程度来评估模型性能。 为了演示此操作,我们使用机器学习工作室(经典)的“已保存数据集”部分中提供的汽车价格数据(原始)数据集。
创建实验
在机器学习工作室(经典)中将以下模块添加到工作区:
如下面的图 1 所示连接端口,并将训练模型模块的“标签”列设置为“价格”。
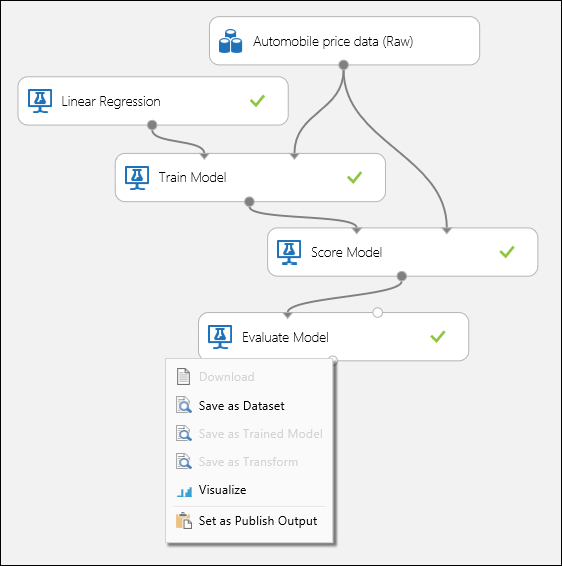
图 1. 评估回归模型。
检查评估结果
运行实验后,可单击评估模型模块的输出端口,并选择“可视化”来查看评估结果。 可用于回归模型的评估指标包括:平均绝对误差、根平均绝对误差、相对绝对误差、相对方误差和决定系数。
术语“误差”在此处表示预测值和真实值之间的差。 通常会计算此差的绝对值或平方来捕获所有实例上的误差总量,因为预测值和真实值之差在某些情况下可能为负。 误差指标通过预测与真实值之间的平均偏差来测量回归模型的预测性能。 误差值较低意味着模型在预测方面更准确。 总体错误指标为零意味着模型与数据完美拟合。
决定系数(也称为 R 平方)也是测量模型与数据拟合程度的标准方法。 它可以解释为变化中由模型解释的比例。 在此情况下比例越高越好,其中 1 表示完美拟合。
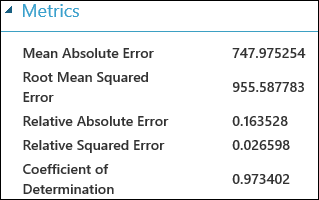
图 2. 线性回归评估指标。
使用交叉验证
如前所述,可使用交叉验证模型模块自动执行重复训练、评分和评估。 在此情况下只需要一个数据集、一个未训练的模型和一个交叉验证模型模块(请参阅下图)。 需要在交叉验证模型模块的属性中将标签列设置为“价格”。
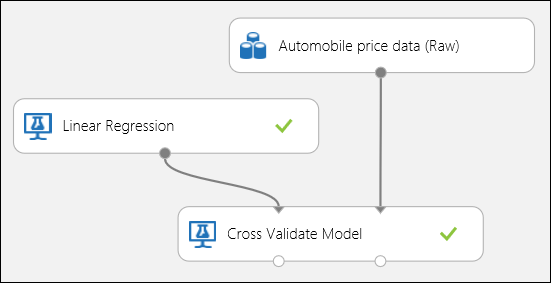
图 3. 交叉验证回归模型。
运行实验后,可通过单击交叉验证模型模块的右输出端口检查评估结果。 这会提供每次迭代(折)的指标的详细视图和每个指标的平均结果(图 4)。
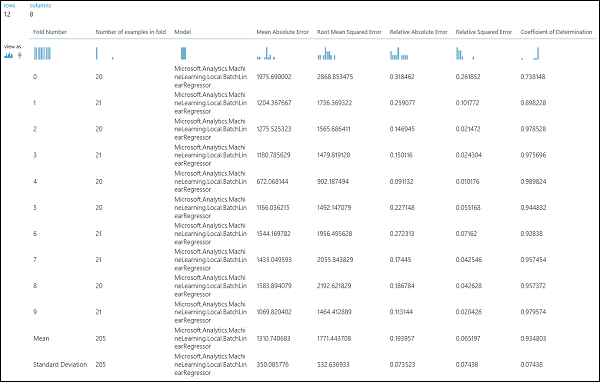
图 4。 回归模型的交叉验证结果。
评估二元分类模型
在二元分类方案中,目标变量只有两个可能的结果,例如: {0, 1} 或 {false, true}、{negative, positive}。 假设为你提供了一个具有人口统计和雇用变量的成年员工数据集,要求你预测收入水平,此处的收入水平是一个值范围为 {"<=50 K", ">50 K"} 的二进制变量。 换而言之,负类表示年收入小于或等于 50K 的员工,正类表示所有其他员工。 和在回归方案中一样,我们可以训练一个模型、评分一些数据,并评估结果。 此处的主要区别是所选的机器学习工作室(经典)计算并输出的指标。 为了演示收入级别预测方案,我们将使用成年人数据集创建工作室(经典)试验并评估双类逻辑回归模型(一种常用的二元分类器)。
创建实验
在机器学习工作室(经典)中将以下模块添加到工作区:
如下面的图 5 所示连接端口,并将训练模型模块的“标签”列设置为“收入”。
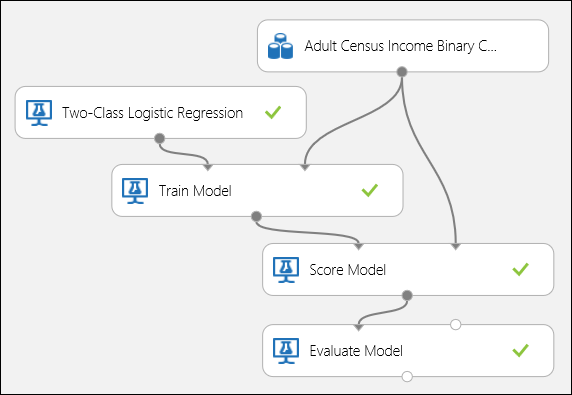
图 5。 评估二元分类模型。
检查评估结果
运行实验后,可单击评估模型模块的输出端口,并选择“可视化”来查看评估结果(图 7)。 可用于二元分类模型的评估指标包括:准确性、精度、召回率、F1 分数和 AUC。 此外,模块输出一个显示真正、假负、假正和真负的混淆矩阵,以及 ROC、精度/召回率和升力曲线。
准确性就是正确分类的实例的比例。 它通常是评估分类器时所查看的第一个指标。 但是,当测试数据不平衡(即大部分实例属于其中一个类)时,或者你对其中任一类上的性能更感兴趣时,准确性无法真正捕获分类器的有效性。 在收入级别分类器方案中,假设在测试的数据中,99% 的实例代表每年收入小于或等于 50K 的人。 通过为所有实例预测类“<=50K”,可能达到 0.99 的准确性。 此情况下的分类器看起来总体上表现不错,但实际上,它未能正确分类任何高收入个体(那 1% 的人)。
因此,计算捕获评估的更具体方面的其他指标很有帮助。 在详细讨论此类指标之前,了解二元分类评估的混淆矩阵很重要。 训练集中的类标签只能采用两个可能的值,我们通常称其为正或负。 分类器正确预测的正和负实例分别称为真正 (TP) 和真负 (TN)。 同样,错误分类的实例称为假正和 (FP) 和假负 (FN)。 混淆矩阵就是一个显示归入这四个类别中的每一个的实例数量的表。 机器学习工作室(经典)自动确定数据集中哪两个类为正类。 如果类标签是布尔值或整数,则向标记为“true”或“1”的实例分配正类。 如果标签是字符串(例如使用收入数据集时),则标签按字母顺序排序,并且第一个级别选择为负类,而第二个级别为正类。
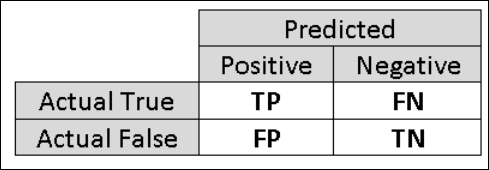
图 6。 二元分类混淆矩阵。
回到收入分类问题,我们可能要问若干个评估问题,以帮助我们了解所使用的分类器的性能。 一个自然而然的问题是:“在模型预测收入 >50 K 的个体中 (TP+FP),有多少是分类正确 (TP) 的?” 可通过查看模型的精度来回答此问题,该指标是分类正确的正的比例:TP/(TP+FP)。 另一个常见问题是“在所有收入 >50 K 的高收入员工中 (TP+FN),分类器正确分类了多少 (TP)”。 这实际上是召回率或真正率:分类器的 TP/(TP+FN)。 可能注意到精度和召回率之间存在明显的权衡。 例如,给定一个相对均衡的数据集,预测大多数正实例的分类器将具有高召回率,但精度较低,因为许多负实例会被错误分类,从而导致大量假正。 若要查看这两个指标的变化图,可单击评估结果输出页中的“精度/召回率”曲线(图 7 左上角)。
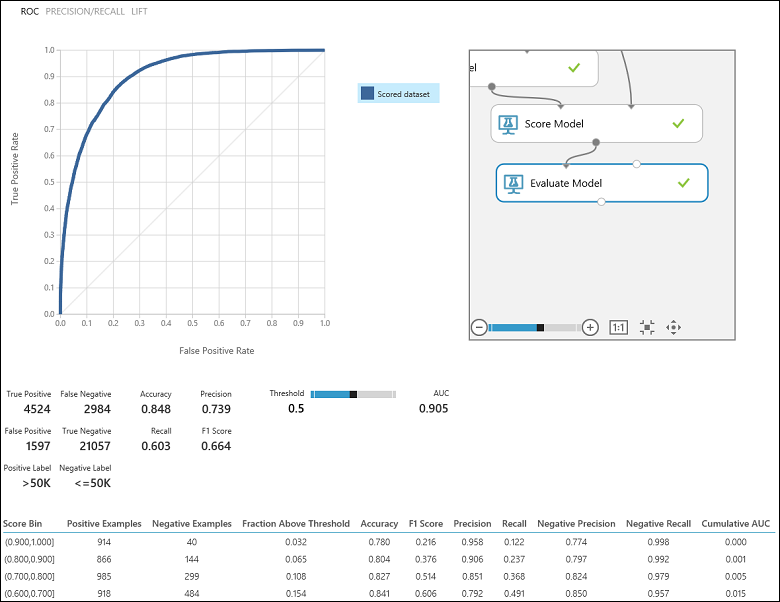
图 7。 二元分类评估结果。
另一个常用的相关指标是 F1 分数,该指标同时考虑精度和召回率。 它是这两个指标的调和平均值,计算方式如下:F1 = 2(精度 x 召回率)/(精度 + 召回率)。 F1 分数是以单个数字总结评估的好方法,但是,同时查看精准率和召回率以更好地了解分类器行为始终是一种良好的做法。
此外,可在“受试者工作特性曲线 (ROC)”曲线和对应的“曲线下面积 (AUC)”值中检查真正与假正的比率。 此曲线离左上角越近,分类器的性能越好(即,最大程度提高真正率,同时最大程度减少假正率)。 离图的对角线很近的曲线,产生自倾向于进行接近随机猜测的预测的分类器。
使用交叉验证
和在回归示例中一样,我们执行交叉验证以自动重复训练、评分和评估数据的不同子集。 同样,我们可以使用交叉验证模型模块、一个未训练的逻辑回归模型和一个数据集。 必须在交叉验证模型模块的属性中将标签列设置为“收入”。 运行实验并单击交叉验证模型模块的右输出端口后,除了每一折的平均和标准偏差,我们可以看到每一折的二元分类指标值。
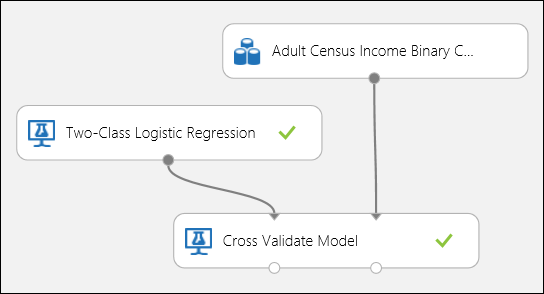
图 8。 交叉验证二元分类模型。
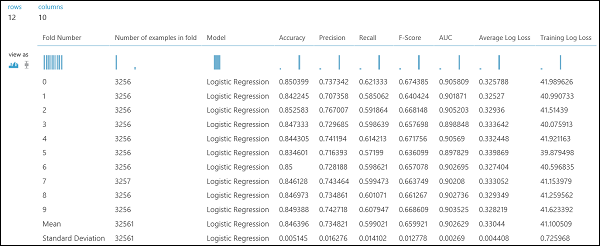
图 9. 二元分类器的交叉验证结果。
评估多类分类模型
在此试验中,我们将使用常用的 Iris 数据集,其中包含三种不同类型(类)的鸢尾属植物的实例。 每个实例有四个特征值(花萼长度/宽度和花瓣长度/宽度)。 在之前的试验中,我们使用相同的数据集训练并测试了模型。 此处,我们将使用拆分数据模块创建数据的两个子集、对第一个子集训练,然后对第二个子集评分和评估。 鸢尾花数据集在 UCI 机器学习存储库中公开提供,并且可使用导入数据模块下载。
创建实验
在机器学习工作室(经典)中将以下模块添加到工作区:
连接端口,如下面的图 10 所示。
将训练模型模块的标签列索引设置为 5。 数据集不再具有标题行,但我们知道类标签在第五列。
单击导入数据模块并将“数据源”属性设置为 “基于 HTTP 的 Web URL” ,将 URL 设置为 http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data 。
在拆分数据模块中将部分实例设置为用于训练(例如 0.7)。
图 10. 评估多类分类器
检查评估结果
运行试验并单击评估模型的输出端口。 在此情况下,评估结果以混淆矩阵形式显示。 矩阵显示所有三个类的实际和预测实例。
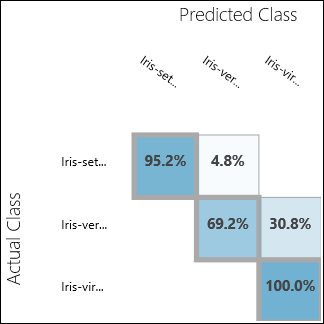
图 11. 多类分类评估结果。
使用交叉验证
如前所述,可使用交叉验证模型模块自动执行重复训练、评分和评估。 将需要一个数据集、一个未训练的模型和一个交叉验证模型模块(请参阅下图)。 再次需要设置交叉验证模型模块的标签列(在此情况下为列索引 5)。 运行试验并单击交叉验证模型模块的右输出端口后,可检查每一折的指标值以及平均和标准偏差。 此处显示的指标类似于二元分类案例中讨论的指标。 但是,在多类分析中,通过按每类计数来计算真正/负和假正/负,因为不存在总体的正或负类。 例如,当计算“Iris-setosa”类的精准率或召回率时,假设这是正类,其他全部为负类。

图 12. 交叉验证多类分类模型。
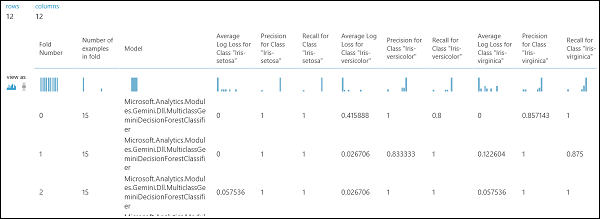
图 13. 多类分类模型的交叉验证结果。