你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
了解和调整流分析流单元
了解流单元和流节点
流单元 (SU) 表示分配用于执行流分析作业的计算资源。 SU 数目越大,为作业分配的 CPU 和内存资源就越多。 此容量使你能够专注于查询逻辑,并且无需管理及时运行流分析作业所需的硬件。
Azure 流分析支持两种流单元结构:SU V1(即将弃用)和 SU V2(推荐)。
SU V1 模型是 ASA 的原始产品/服务,其中每 6 个 SU 对应于作业的单个流节点。 作业也可使用 1 和 3 个 SU 运行,它们对应于分数型流节点。 通过添加提供分布式计算资源的更多流节点,在 6 个 SU 作业之外以 6 为增量缩放到 12、18、24 及更高。
SU V2 模型(推荐)是一种简化的结构,对相同的计算资源具有优惠的定价。 在 SU V2 模型中,1 个 SU V2 对应于作业的一个流节点。 2 个 SU V2 对应于 2 个节点、3 个对应于 3 个节点,以此类推。 具有 1/3 和 2/3 SU V2 的作业也可用于一个流节点,但只是计算资源的一小部分。 1/3 SU 和 2/3 SU V2 作业为需要较小规模的工作负载提供了一种经济高效的选项。
V1 和 V2 流单元的基础计算能力如下所示:

有关 SU 定价的信息,请访问 Azure 流分析定价页。
了解流单元转换及其应用场景
流单元从 REST API 层自动转换为 UI(Azure 门户和 Visual Studio Code)。 你会注意到活动日志中的此转换,以及 SU 值与 UI 上的值不同的位置。 这是设计原因,原因是 REST API 字段仅限于整数值,ASA 作业支持小数节点(1/3 和 2/3 流单元)。 ASA 的 UI 显示节点值 1/3、2/3、1、2、3、... 等,而后端(活动日志、REST API 层)显示的值分别与 3、7、10、20、30 相乘 10。
| 标准 | 标准 V2 (UI) | 标准 V2 (后端(例如日志、Rest API 等) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
这样,我们就可以传达相同的粒度,并消除 V2 SKU 的 API 层的小数点。 此转换是自动的,不会影响作业的性能。
了解消耗量和内存利用率
为了实现低延迟流式处理,Azure 流分析作业将执行内存中的所有处理。 内存不足时,流式处理作业会失败。 因此,对于生产作业,请务必监视流式处理作业的资源使用情况,并确保分配有足够的资源来保持作业的全天候运行。
SU 利用率指标的范围为 0% 到 100%,描述工作负荷的内存消耗量。 对于占用最小内存的流式处理作业,此指标通常介于 10% 到 20%。 如果 SU 利用率较高(超过 80%)或者输入事件积压(即使 SU 利用率很低,因为它不显示 CPU 使用率),则可能表示工作负载需要更多的计算资源,这就需要增加流单元的数目。 最好保持低于 80% 的 SU 指标,以应对偶发的峰值。 为了应对工作负荷的增加和流单元的增加,考虑设置一个警报,在 SU 利用率指标为 80% 时发出。 此外,可以使用水印延迟和积压的事件指标来查看是否有影响。
配置流分析流单元 (SU)
登录到 Azure 门户。
在资源列表中,找到要缩放的流分析作业,然后将其打开。
在作业页中的“配置”标题下,选择“缩放”。 创建作业时,SU 的默认数量为 1。
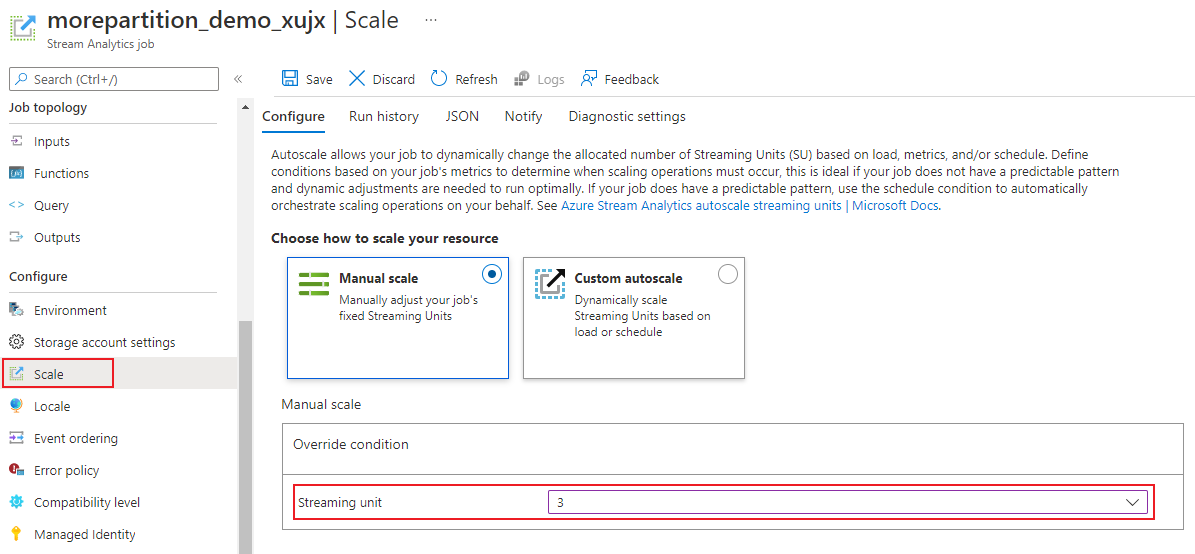
在下拉列表中选择 SU 选项以设置作业的 SU。 请注意,你只能使用特定的 SU 范围。
在作业运行时,可以更改分配给它的 SU 数量。 如果你的作业使用非分区输出,或者具有带有不同 PARTITION BY 值的多步骤查询,则当作业正在运行时,你可能只能从一组 SU 值中进行选择。
监视作业性能
使用 Azure 门户可以跟踪作业的性能相关指标。 若要了解指标定义,请参阅 Azure 流分析作业指标。 若要详细了解门户中的指标监视,请参阅使用 Azure 门户监视流分析作业。
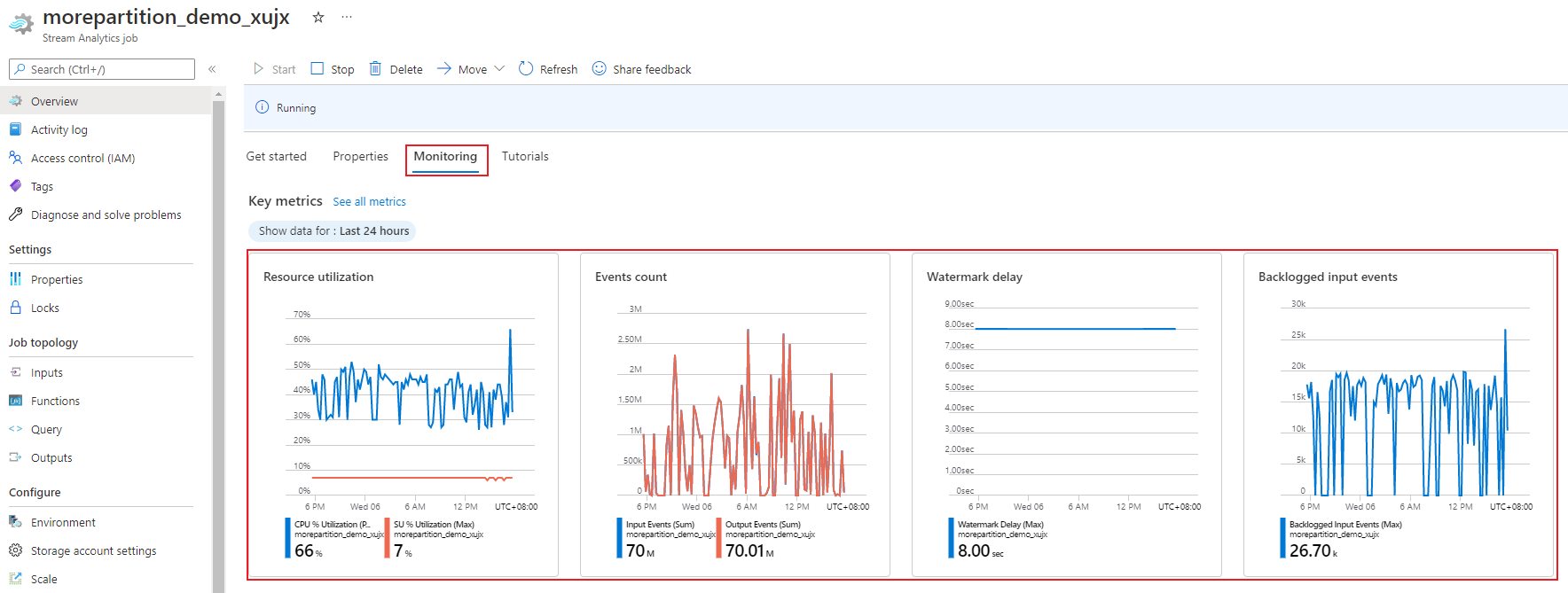
计算工作负荷的预期吞吐量。 如果吞吐量低于预期,则可调整输入分区和查询,并为作业添加 SU。
一个作业需要多少 SU?
为特定作业选择所需的 SU 数量时,需要根据输入的分区配置以及在作业内定义的查询来决定。 可以使用“缩放” 页设置正确的 SU 数量。 分配的 SU 数最好超过所需的数量。 流分析处理引擎会针对延迟和吞吐量进行优化,不过,代价是需要分配额外的内存。
通常情况下,最佳做法是一开始为不使用 PARTITION BY 的查询分配 1 个 SU V2。 然后,在传递了具有代表性的数据量并检查了 SU 利用率指标后,使用修改 SU 数量的试用和错误方法来确定最佳数量。 流分析作业所能使用的最大流单元数取决于为作业定义的查询中的步骤数,以及每一步中的分区数。 可在此处了解更多有关限制的信息。
有关选择适当数量的 SU 的详细信息,请参阅此页:缩放 Azure 流分析作业以增加吞吐量。
注意
选择特定作业所需的 SU 数目时,需根据输入的分区配置以及为作业定义的查询来决定。 可为作业选择的最大数目为 SU 配额。 有关 Azure 流分析订阅配额的信息,请访问流分析限制。 若要增加订阅的 SU 数,使其超过此配额,请联系 Microsoft 支持部门。 每个作业的 SU 的有效值为 1/3、2/3、1、2、3 等。
可以提高 SU% 利用率的因素
时态(时间导向)的查询元素是流分析提供的有状态运算符的核心集。 流分析通过管理内存消耗量、为复原创建检查点,并在服务升级期间恢复状态,代表用户在内部管理这些操作的状态。 尽管流分析能够全面管理状态,但用户还是应该考虑许多最佳做法建议。
请注意,具有复杂查询逻辑的作业即使在不连续接收输入事件时也可能具有较高的 SU% 利用率。 这可能发生在输入和输出事件突然激增之后。 如果查询很复杂,作业可能会继续在内存中维护状态。
在回到预期水平之前,SU% 利用率可能会在短时间内突然降至 0。 发生这种情况是由于暂时性错误或系统启动升级。 如果查询未完全并行,增加作业的流单元数量可能不会降低 SU% 利用率。
比较一段时间内的利用率时,请使用事件速率指标。 InputEvents 和 OutputEvents 指标显示读取和处理的事件数量。 还有一些指标可以指示错误事件的数量,如反序列化错误。 当每个时间单位的事件数增加时,大多数情况下 SU% 会增加。
时态元素中的有状态查询逻辑
Azure 流分析作业的独有功能之一是执行有状态的处理,如开窗聚合、临时联接和临时分析函数。 其中的每个运算符都会保存状态信息。 这些查询元素的最大窗口大小为 7 天。
多个流分析查询元素中都出现了时态窗口的概念:
开窗聚合:翻转窗口、跳跃窗口和滑动窗口 GROUP BY
时态联接:JOIN with DATEDIFF 函数
时态分析函数:ISFIRST、LAST 和 LAG with LIMIT DURATION
以下因素影响流分析作业使用的内存(流单元指标部分):
开窗聚合
开窗聚合的消耗内存(状态大小)并不始终与窗口大小成正比。 消耗内存与数据基数或者每个时间窗口中的组数成正比。
例如,在以下查询中,与 clusterid 关联的数字就是查询的基数。
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
若要缓解前面查询中由高基数导致的任何问题,可以将事件发送到按 clusterid 分区的事件中心,并通过允许系统使用 PARTITION BY 分别处理每个输入分区来横向扩展查询,如以下示例所示:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
将查询分区后,它会分散到多个节点中。 因此,可以通过减少依据运算符分组的基数来减少传入每个节点的 clusterid 值数。
事件中心分区应根据分组键进行分区,以避免减少步骤的需要。 有关详细信息,请参阅事件中心概述。
时态联接
时态联接的消耗内存(状态大小)与联接的时态调整空间中的事件数量(即事件输入速率乘以调整空间大小)成正比。 换而言之,联接消耗的内存与 DateDiff 时间范围乘以平均事件速率的结果成正比。
联接中的不匹配事件数会影响查询的内存利用率。 以下查询将查找产生点击量的广告印象:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
在本示例中,有可能显示了很多广告,但很少有人点击它们,并且需要保留该时间范围内的所有事件。 内存消耗量与时间范围大小和事件发生速率成比例。
若要修正此问题,请将事件发送到依据联接键(在此情况下为 ID)分区的事件中心,并通过允许系统使用 PARTITION BY 分别处理每个输入分区来横向扩展查询,如下所示:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
将查询分区后,它会分散到多个节点中。 因此,可以通过减小保留在联接窗口中状态的大小来减少传入每个节点的事件数。
时态分析函数
时态分析函数的消耗内存(状态大小)与事件速率和持续时间的乘积成正比。 分析函数消耗的内存与窗口大小不成正比,而是与每个时间窗口中的分区计数成正比。
修正的方法类似于临时联接。 你可以使用 PARTITION BY 来横向扩展查询。
无序缓冲区
在“事件排序配置”窗格中,用户可以配置无序的缓冲区大小。 可以使用缓冲区来保留窗口持续时间内的输入,并对其进行重新排序。 缓冲区的大小与事件输入速率和无序窗口大小的乘积成正比。 默认窗口大小为 0。
若要修正失序缓冲区溢出,请使用 PARTITION BY 横向扩展查询。 将查询分区后,它会分散到多个节点中。 因此,可以通过减少每个重新排序缓冲区中的事件数来减少传入每个节点的事件数。
输入分区计数
作业输入的每个输入分区都有一个缓冲区。 输入分区数量越大,作业所消耗的资源越多。 对于每个流单元,Azure 流分析大致可以处理 7 MB/秒的输入。 因此,可以通过将流分析流单元数与事件中心内的分区数进行匹配来进行优化。
通常,使用 1/3 流单元配置的作业足以满足包含两个分区(事件中心至少包含两个分区)的事件中心。 如果事件中心具有更多分区,流分析作业将耗用更多资源,但不一定使用事件中心提供的额外吞吐量。
对于具有 1 个 V2 流单元的作业,可能需要事件中心的 4 个或 8 个分区。 但是,请避免过多的不必要分区,否则可能会超出资源用量。 例如,在包含 1 个流单元的流分析作业中,使用包含 16 个分区的事件中心或更大的事件中心。
引用数据
ASA 中的引用数据会被加载到内存中,以便快速查找。 在当前的实现中,每个带有引用数据的联接操作都在内存中保留有一份引用数据,即使你多次使用相同的引用数据进行联接也是如此。 对于使用 PARTITION BY 的查询,每个分区都有一份引用数据,因此,这些分区是完全分离的。 通过倍增效应,如果多次使用多个分区联接引用数据,内存使用率很快就会变得非常高。
使用 UDF 函数
当添加 UDF 函数时,Azure 流分析会将 JavaScript 运行时加载到内存中。 这将影响 SU%。