从存储池虚拟化 CSV 数据(大数据群集)
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
SQL Server 大数据群集可以从 HDFS 中的 CSV 文件虚拟化数据。 此过程允许将数据保留在其原始位置,但可以从 SQL Server 实例进行查询(如同任何其他表一样)。 此功能使用 PolyBase 连接器,可最大程度减少对 ETL 过程的需求。 有关数据虚拟化的详细信息,请参阅利用 PolyBase 引入数据虚拟化
先决条件
选择或上传 CSV 文件以进行数据虚拟化
在 Azure Data Studio (ADS) 中,连接到大数据群集的 SQL Server 主实例。 连接后,在对象资源管理器中展开 HDFS 元素,以找到要进行数据虚拟化的 CSV 文件。
在本教程中,创建一个名为 Data 的新目录。
- 右键单击 HDFS 根目录上下文菜单。
- 选择“新建目录”。
- 将新目录命名为 Data 。
上传示例数据。 对于简单演练,可以使用示例 csv 数据文件。 本文使用来自美国运输部的航班延迟原因数据。 下载原始程序,然后将数据提取到计算机。 将文件命名为 airline_delay_causes.csv 。
在提取示例文件之后上传:
- 在 Azure Data Studio 中,右键单击所创建的新目录 。
- 选择“上传文件”。
Azure Data Studio 将文件上传到大数据群集上的 HDFS 中。
在目标数据库中创建存储池外部数据源
存储池外部数据源默认不会创建在大数据群集中的数据库里。 先使用以下 Transact-SQL 查询在目标数据库中创建默认 SqlStoragePool 外部数据源 ,然后才能创建外部表。 请确保首先将查询的上下文更改为目标数据库。
-- Create the default storage pool source for SQL Big Data Cluster
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool')
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
创建外部表
在 ADS 中,右键单击 CSV 文件,然后从上下文菜单中选择“从 CSV 文件中创建外部表” 。 还可以从 HDFS 中的目录中的 CSV 文件创建外部表(如果目录下的文件遵循相同架构)。 这将允许在目录级别虚拟化数据,而无需处理单个文件,并获得组合数据的联接结果集。 Azure Data Studio 将指导你完成创建外部表的步骤。
指定数据库、数据源、表名、架构和表外部文件格式的名称。
选择“下一页”。
预览数据
Azure Data Studio 提供导入数据的预览。
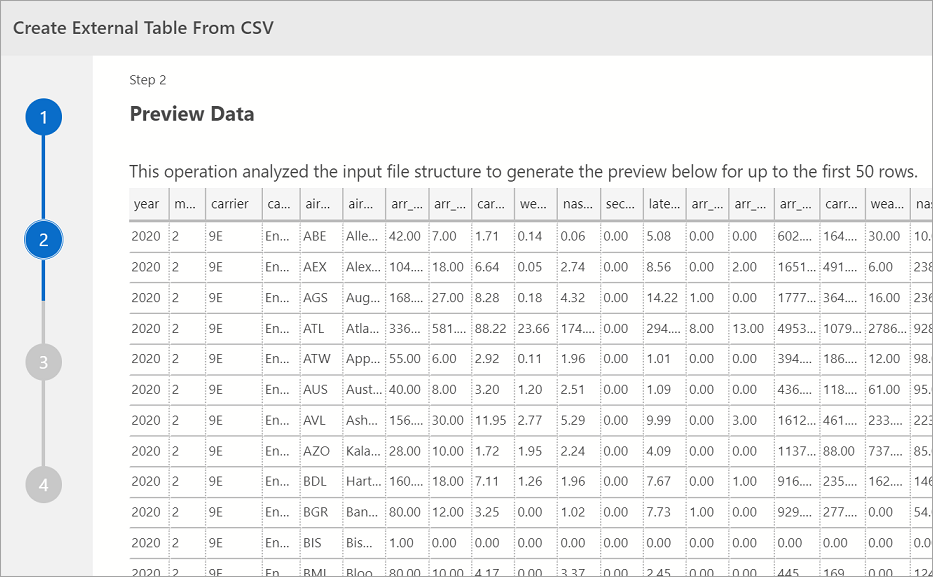
完成查看预览后,选择“下一步”继续
修改列
在下一个窗口中,你可以修改要创建的外部表的列。 你将能够更改列名称、更改数据类型并允许可为 Null 的行。
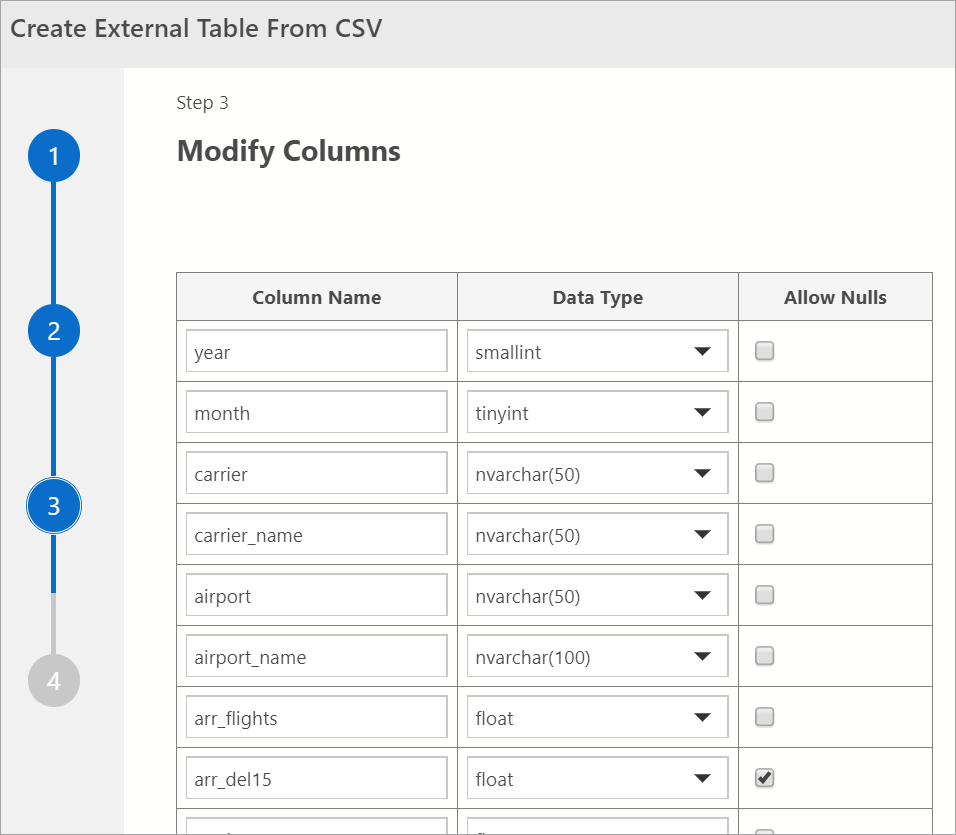
验证目标列之后,选择“下一步”。
总结
此步骤提供所选对象的摘要。 它提供 SQL Server 名称、数据库名称、表名、表架构和外部表信息。 在此步骤中,可以选择生成脚本或创建表。 “生成脚本”会使用 T-SQL 创建脚本以创建外部数据源。 “创建表”会创建外部数据源。
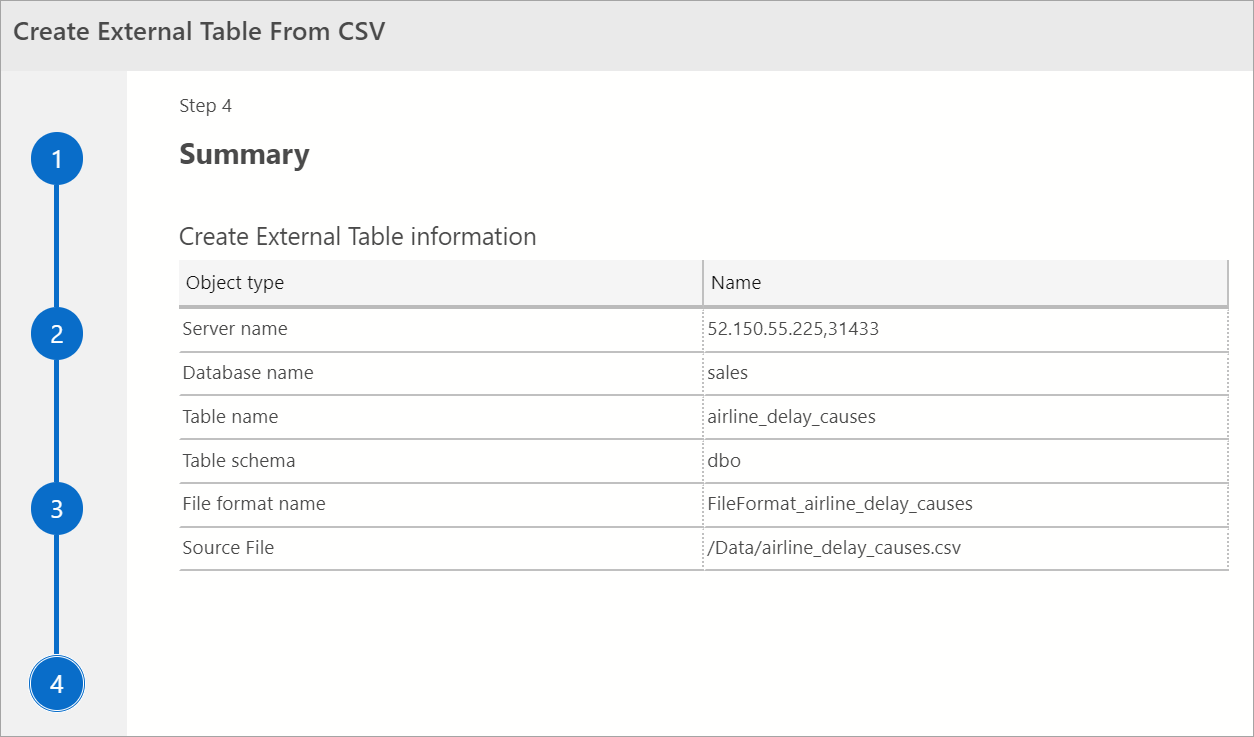
如果选择“创建表”,则 SQL Server 会在目标数据库中创建外部表。
如果选择“生成脚本”,则 Azure Data Studio 会创建用于创建外部表的 T-SQL 查询。
创建后,现在可以直接使用 T-SQL 从 SQL Server 实例查询表。
后续步骤
有关 SQL Server 大数据群集和相关方案的详细信息,请参阅 SQL Server 大数据群集简介。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈