對 Azure Service Fabric 進行監視和診斷
本文提供監視和診斷 Azure Service Fabric 的概觀。 不論任何雲端環境,針對工作負載的開發、測試及部署進行監視和診斷都極為重要。 例如,您可以追蹤應用程式被使用的方式、由 Service Fabric 平台所採取的動作、搭配效能計數器的資源使用量,以及叢集的整體健康情況。 您可以使用這些資訊來診斷並修正問題,並防止它們於未來再度發生。 接下來的幾節將會簡要說明應針對生產工作負載考量的每個 Service Fabric 監視區域。
注意
本文最近有所更新,改為使用「Azure 監視器記錄」一詞,而非 Log Analytics。 記錄資料仍儲存在 Log Analytics 工作區中,並仍由相同的 Log Analytics 服務收集和分析。 我們會持續更新術語,以更精確地反映 Azure 監視器記錄的角色。 如需詳細資料,請參閱 Azure 監視器遙測變更。
應用程式監視
應用程式監視會追蹤您應用程式的功能與元件使用情況。 您可以監視應用程式,以確定找出影響使用者的問題。 應用程式監視的責任會落在開發應用程式及其服務的使用者身上,因為它會專屬於您應用程式的商務邏輯。 在下列情況,監視應用程式可能非常有用:
- 我的應用程式正在處理多少流量? - 您是否需要調整服務以符合使用者需求,或解決應用程式中的潛在瓶頸?
- 我的服務對服務呼叫是否成功且順利被追蹤?
- 我應用程式的使用者採取了哪些動作? - 收集遙測可協助引導未來的功能開發,並對應用程式錯誤進行更佳的診斷
- 我的應用程式是否正在擲回未處理的例外狀況?
- 在我容器中執行的服務之內正在發生什麼事?
應用程式監視的好處,在於開發人員可以自由使用任何工具和架構,因為應用程式監視是存在於您應用程式的內容之內! 若要深入了解適用於搭配 Azure 監視器 Application Insights 進行應用程式監視的 Azure 解決方案,請參閱使用 Application Insights 進行事件分析。 我們也有提供如何針對 .NET 應用程式設定此功能的教學課程。 此教學課程會說明如何安裝正確的工具、提供在應用程式中撰寫自訂遙測的範例,以及說明如何在 Azure 入口網站中檢視應用程式診斷及遙測。
平台 (叢集) 監視
使用者可以控制應用程式會傳送哪些遙測,因為程式碼本身是使用者所撰寫的。但是來自 Service Fabric 平台的診斷又如何? Service Fabric 的其中一個目標是讓應用程式在硬體失敗時能夠復原。 這個目標可以透過 平台的系統服務偵測基礎結構問題,並快速地將工作負載容錯移轉到叢集中的其他節點來達成。 但是在這個特殊情況下,如果是系統服務本身有問題,會發生什麼情況? 或如果在嘗試部署或移動工作負載時違反了設置服務的規則,會發生麼情況? Service Fabric 能針對這些及其他情況提供診斷,以確保您能夠了解在您叢集中所發生的活動。 叢集監視的一些範例案例包括:
Service Fabric 提供一組完整的現成事件。 這些 Service Fabric 事件可以透過 EventStore 或作業通道 (平台公開的事件通道) 來存取。
Service Fabric 事件通道 - 在 Windows 上,透過一組用來挑選「作業和資料」與「傳訊」通道的相關
logLevelKeywordFilters,就能從單一 ETW 提供者取得 Service Fabric 事件 - 這是我們在需要時區分出待篩選傳出 Service Fabric 事件的方法。 在 Linux 上,Service Fabric 事件會經過 LTTng 並放入一個儲存體資料表,您可以視需要從這個資料表篩選事件。 這些通道包含經過策劃、結構化的事件,可用來進一步了解您的叢集狀態。 叢集建立時預設會啟用診斷,這會建立一個 Azure 儲存體表格,來自這些通道的事件會傳送到這個表格,供您將來查詢之用。EventStore - EventStore 是平台所提供的功能,提供可在 Service Fabric Explorer 中和透過 REST API 取得的 Service Fabric 平台事件。 您可以看到快照集檢視,其中顯示每個實體 (例如節點、服務、應用程式) 在叢集中發生什麼情況,並根據事件的時間進行查詢。 您也可以在 EventStore 概觀進一步了解 EventStore。
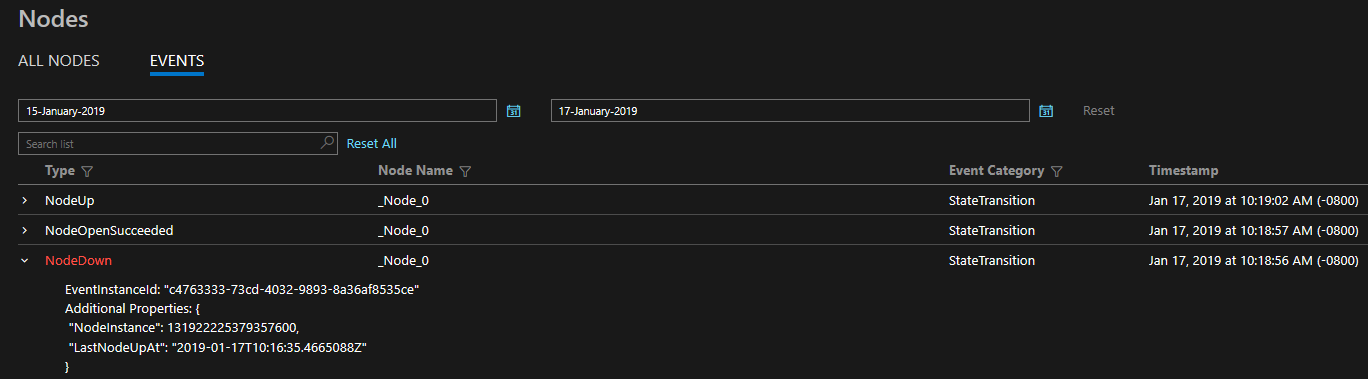
所提供的診斷預設便是以一組詳盡事件的形式提供。 這些 Service Fabric 事件能說明平台針對各種不同的實體 (例如節點、應用程式、服務、分割區等) 所執行的動作。在上述的最後一個案例中,如果節點發生故障,平台將會發出 NodeDown 事件,且您所選擇的監視工具將會立即通知您。 其他常見的範例包括容錯移轉期間的 ApplicationUpgradeRollbackStarted 或 PartitionReconfigured。 Windows 和 Linux 叢集上都會提供相同的事件。
這些事件會透過 Windows 和 Linux 上的標準通道傳送,並可由任何支援這些通道的監視工具讀取。 Azure 監視器的解決方案是 Azure 監視器記錄。 歡迎深入了解我們的 Azure 監視器記錄整合,其中包含適用於您叢集的自訂作業儀表板,以及可用來建立警示的一些範例查詢。 如需更多叢集監視概念,請參閱平台層級事件和記錄產生。
健康狀態監視
Service Fabric 平台包括健康情況模型,針對叢集中的實體狀態提供可延伸的健康情況報告。 每個節點、應用程式、服務、分割區、複本或執行個體,都有可持續更新的健康情況狀態。 健康情況狀態可以是「良好」、「警告」或「錯誤」。 您可以將 Service Fabric 事件想成從叢集到各種實體的「動詞」,並將健康情況想成針對每個實體的「形容詞」。 每當某個實體的健康情況轉換時,系統也會發出事件。 如此一來,您便可以使用和其他事件相同的方式,在自己所選的監視工具中針對健康情況事件設定查詢和警示。
此外,我們還會讓使用者覆寫實體的健康情況。 如果您在應用程式升級後遇到驗證測試失敗的問題,您可以使用健康情況 API 寫入 Service Fabric 健康情況,以表明您的應用程式的健康情況已不再良好,而 Service Fabric 將會自動復原該升級! 如需健康情況模型的詳細資訊,請參閱 Service Fabric 健康情況監視簡介
監視程式
一般而言,監視程式是一個單獨的服務,可以觀察服務之間的健康情況和負載、偵測端點,並回報叢集中非預期的健康情況事件。 這可以避免在單一服務效能中無法偵測到的錯誤。 監視程式也很適合裝載程式碼,以執行不需要使用者互動的補救動作,例如依特定間隔時間清除儲存體中的記錄檔。 如果想要有完整實作的開放原始碼 SF 監視程式服務,其中包含易於使用的監視程式擴充性模型,而且在 Windows 和 Linux 叢集上執行,請參閱 FabricObserver 專案。 FabricObserver 是生產就緒的軟體。 建議將 FabricObserver 部署到測試和生產叢集,然後透過其外掛程式模型,或派生並撰寫您自己的內建觀察者,加以延伸來滿足您的需求。 前者 (外掛程式) 是建議的方法。
基礎結構 (效能) 監視
我們已經涵蓋了應用程式及平台中的診斷,那麼又要如何得知硬體已正確運作? 監視根本的基礎結構是了解叢集狀態和資源使用率的關鍵部分。 測量系統效能需要仰賴許多會因工作負載不同而變動的因素。 這些因素通常是透過效能計數器來測量。 這些效能計數器可能會來自各種不同的來源,包括作業系統、.NET 架構,或是 Service Fabric 平台本身。 適用它們的一些案例為
- 我是否正在有效地使用我的硬體? 您想要使 CPU 的運作率達 90% 或 10%。 這在調整您的叢集,或是對您應用程式的處理序進行最佳化時很有用。
- 我是否能主動預測基礎結構問題? 許多問題在發生之前,效能會有突然的變化 (降低),因此您可以使用如網路 I/O 和 CPU 使用率等效能計數器,來主動地預測和診斷問題。
您可以在效能計量找到在基礎結構層級應該收集的效能計數器清單。
Service Fabric 也會提供一組效能計數器,以供 Reliable Services 和動作項目程式設計模型使用。 如果您使用上述其中一種模型,這些效能計數器可以提供資訊,以協助確保您的動作項目正確向上和向下微調,或者您的可靠服務要求處理的速度夠快。 如需詳細資訊,請參閱可靠服務遠端的監視和 Reliable Actors 的效能監視。
和平台層級的監視相同,收集這些資料的 Azure 監視器解決方案是 Azure 監視器記錄。 您應該使用 Log Analytics 代理程式來收集適當的效能計數器,並在 Azure 監視器記錄中檢視它們。
建議設定
我們已說明監視的每個區域及範例案例,以下是監視上述所有區域所需之 Azure 監視工具及設定的摘要。
- 搭配 Application Insights 進行應用程式監視監視
- 搭配診斷代理程式和 Azure 監視器記錄進行叢集監視
- 使用 Azure 監視器記錄來監視基礎結構
您也可以使用及修改位於這裡的範例 ARM 範例,來將所有必要資源和代理程式的部署自動化。
其他記錄解決方案
雖然我們建議兩個解決方案,但是 Azure 監視器記錄和 Application Insights 已內建在 Service Fabric 的整合中,所以許多事件會透過 ETW 提供者寫出來並可利用其他記錄解決方案延伸。 您也應該研究 Elastic Stack (尤其是當您考慮在離線環境中執行叢集時)、Dynatrace,或您偏好的其他任何平台。 我們在這裡提供一份整合的合作夥伴清單。
不論選擇何種平台,重點在於您對於其所提供的使用者介面、查詢能力、可用的自訂視覺化與儀表板,以及可強化監視體驗的其他工具所抱持的感受。
下一步
- 若要開始檢測您的應用程式,請參閱應用程式層級事件和記錄產生。
- 透過監視和診斷 Service Fabric 上的 ASP.NET Core 應用程式中的步驟,來針對您的應用程式設定 Application Insights。
- 在平台層級事件和記錄產生深入了解監視平台,以及監視 Service Fabric 提供給您的事件。
- 在設定叢集的 Azure 監視器記錄上設定 Azure 監視器記錄與 Service Fabric 的整合
- 了解如何設定 Azure 監視器記錄以監視容器 - 監視和診斷 Azure Service Fabric 中的 Windows 容器。
- 請參閱診斷常見案例中的 Service Fabric 範例診斷問題和解決方案
- 查看 Service Fabric 診斷合作夥伴中與 Service Fabric 整合的其他診斷產品
- 了解 Azure 資源的一般監視建議:最佳做法 - 監視和診斷。