Transformace dat pomocí aktivity Sparku ve službě Azure Data Factory a Synapse Analytics
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Aktivita Sparku v datové továrně a kanálech Synapse spouští program Spark ve vašem vlastním clusteru HDInsight nebo clusteru HDInsight na vyžádání. Tento článek vychází z článku o aktivitách transformace dat, který představuje obecný přehled transformace dat a podporovaných transformačních aktivit. Když používáte propojenou službu Sparku na vyžádání, služba automaticky vytvoří cluster Spark, který bude zpracovávat data za běhu, a po dokončení zpracování cluster odstraní.
Přidání aktivity Sparku do kanálu pomocí uživatelského rozhraní
Pokud chcete pro kanál použít aktivitu Sparku, proveďte následující kroky:
Vyhledejte Spark v podokně Aktivity kanálu a přetáhněte aktivitu Sparku na plátno kanálu.
Pokud ještě není vybraná, vyberte na plátně novou aktivitu Sparku.
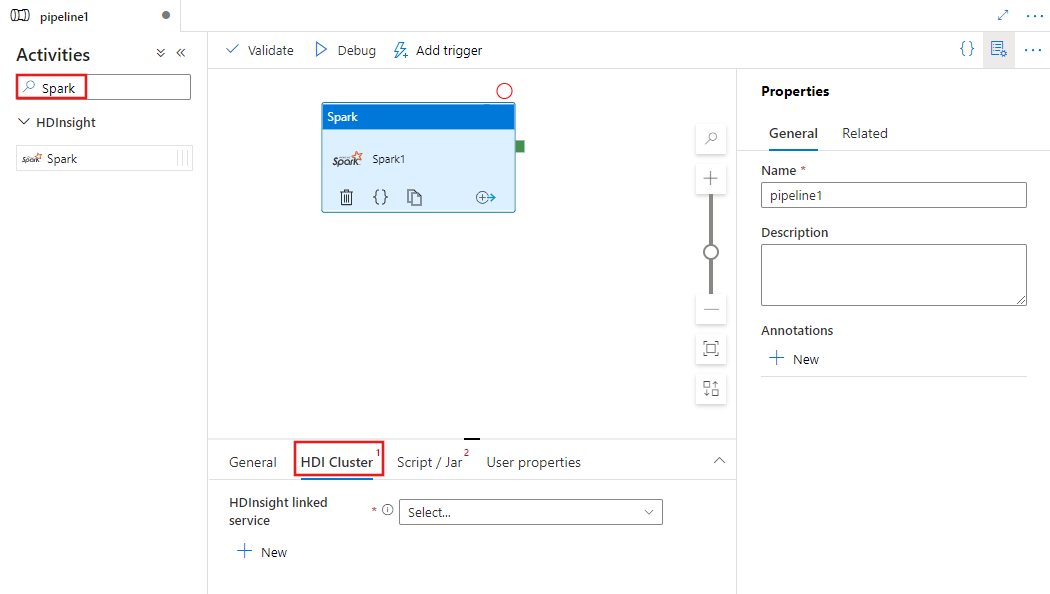
Výběrem karty Cluster HDI vyberte nebo vytvořte novou propojenou službu s clusterem HDInsight, který se použije ke spuštění aktivity Spark.
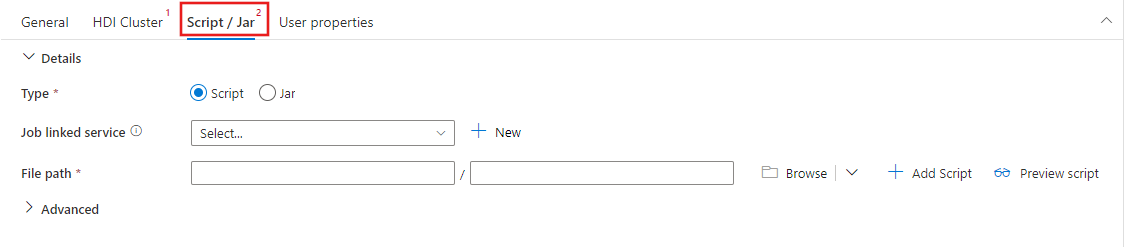
Vyberte kartu Skript / Jar a vyberte nebo vytvořte novou propojenou službu úlohy s účtem Azure Storage, který bude hostovat váš skript. Zadejte cestu k souboru, který se tam má spustit. Můžete také nakonfigurovat pokročilé podrobnosti, včetně uživatele proxy serveru, konfigurace ladění a argumentů a parametrů konfigurace Sparku, které se mají předat skriptu.
Vlastnosti aktivity Sparku
Tady je ukázková definice JSON aktivity Sparku:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
Následující tabulka popisuje vlastnosti JSON použité v definici JSON:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| name | Název aktivity v kanálu | Ano |
| description | Text popisující, co aktivita dělá. | No |
| type | U aktivity Sparku je typ aktivity HDInsightSpark. | Ano |
| linkedServiceName | Název propojené služby HDInsight Spark, na které běží program Spark. Další informace o této propojené službě najdete v článku o propojených službách Compute. | Ano |
| SparkJobLinkedService | Propojená služba Azure Storage, která obsahuje soubor úlohy Spark, závislosti a protokoly. Tady jsou podporované jenom propojené služby Azure Blob Storage a ADLS Gen2. Pokud pro tuto vlastnost nezadáte hodnotu, použije se úložiště přidružené ke clusteru HDInsight. Hodnota této vlastnosti může být pouze propojená služba Azure Storage. | No |
| rootPath | Kontejner a složka Azure Blob, která obsahuje soubor Spark. V názvu souboru se rozlišují malá a velká písmena. Podrobnosti o struktuře této složky najdete v části struktura složek (další oddíl). | Ano |
| entryFilePath | Relativní cesta ke kořenové složce kódu/balíčku Spark. Vstupní soubor musí být buď soubor Pythonu, nebo soubor .jar. | Ano |
| Classname | Hlavní třída Java/Spark aplikace | No |
| Argumenty | Seznam argumentů příkazového řádku pro program Spark. | No |
| proxyUser | Uživatelský účet, který se má zosobnit pro spuštění programu Spark | No |
| SparkConfig | Zadejte hodnoty pro vlastnosti konfigurace Sparku uvedené v tématu: Konfigurace Sparku – Vlastnosti aplikace. | No |
| getDebugInfo | Určuje, kdy se soubory protokolu Sparku zkopírují do úložiště Azure používaného clusterem HDInsight (nebo) určeným sparkJobLinkedService. Povolené hodnoty: Žádné, Vždy nebo Selhání. Výchozí hodnota: Žádný. | No |
Struktura složek
Úlohy Sparku jsou rozšiřitelnější než úlohy Pig/Hive. U úloh Sparku můžete zadat více závislostí, jako jsou balíčky JAR (umístěné v jazyce Java CLASSPATH), soubory Pythonu (umístěné v PYTHONPATH) a všechny další soubory.
Ve službě Azure Blob Storage, na kterou odkazuje propojená služba HDInsight, vytvořte následující strukturu složek. Potom nahrajte závislé soubory do příslušných podsložek v kořenové složce reprezentované entryFilePath. Například nahrajte soubory Pythonu do podsložky pyFiles a souborů JAR do podsložky jar kořenové složky. Za běhu služba očekává následující strukturu složek ve službě Azure Blob Storage:
| Cesta | Popis | Povinní účastníci | Typ |
|---|---|---|---|
. (root) |
Kořenová cesta úlohy Sparku v propojené službě úložiště | Ano | Složka |
| <definovaný uživatelem > | Cesta odkazující na vstupní soubor úlohy Sparku | Ano | Soubor |
| ./Sklenice | Všechny soubory v této složce se nahrají a umístí do cesty ke třídě Java clusteru. | No | Složka |
| ./pyFiles | Všechny soubory v této složce se nahrají a umístí do cesty PYTHONPATH clusteru. | No | Složka |
| ./Soubory | Všechny soubory v této složce se nahrají a umístí do pracovního adresáře exekutoru. | No | Složka |
| ./Archiv | Všechny soubory v této složce jsou nekomprimované. | No | Složka |
| ./Protokoly | Složka, která obsahuje protokoly z clusteru Spark. | No | Složka |
Tady je příklad úložiště obsahující dva soubory úloh Sparku ve službě Azure Blob Storage, na které odkazuje propojená služba HDInsight.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Související obsah
Podívejte se na následující články, které vysvětlují, jak transformovat data jinými způsoby: