Kurz 2: Trénování modelů úvěrového rizika – Machine Learning Studio (classic)
PLATÍ PRO: Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Důležité
Podpora studia Machine Learning (Classic) skončí 31. srpna 2024. Doporučujeme do tohoto data přejít na službu Azure Machine Learning.
Od 1. prosince 2021 nebude možné vytvářet nové prostředky studia Machine Learning (Classic). Do 31. srpna 2024 můžete pokračovat v používání stávajících prostředků studia Machine Learning (Classic).
- Přečtěte si informace o přesunu projektů strojového učení ze sady ML Studio (Classic) do Služby Azure Machine Learning.
- Další informace o službě Azure Machine Learning
Dokumentace ke studiu ML (Classic) se vyřazuje z provozu a v budoucnu se nemusí aktualizovat.
V tomto kurzu se podíváte na proces vývoje řešení prediktivní analýzy. V nástroji Machine Learning Studio (classic) vyvíjíte jednoduchý model. Model pak nasadíte jako webovou službu Machine Learning. Tento nasazený model může vytvářet předpovědi pomocí nových dat. Tento kurz je součástí třídílné série kurzů.
Předpokládejme, že potřebujete předpovědět úvěrové riziko u jednotlivých zákazníků na základě údajů, které uvedli v žádosti o úvěr.
Posouzení úvěrového rizika je složitý problém, ale tento kurz ho trochu zjednoduší. Použijete ho jako příklad, jak můžete vytvořit řešení prediktivní analýzy pomocí nástroje Machine Learning Studio (classic). Pro toto řešení použijete Machine Learning Studio (classic) a webovou službu Machine Learning.
V tomto třídílném kurzu začnete s veřejně dostupnými daty o úvěrovém riziku. Pak vyvíjíte a trénujete prediktivní model. Nakonec model nasadíte jako webovou službu.
V jedné části kurzu jste vytvořili pracovní prostor Machine Learning Studio (classic), nahraná data a vytvořili experiment.
V této části kurzu:
- Trénování více modelů
- Skóre a vyhodnocení modelů
Ve třetí části kurzu nasadíte model jako webovou službu.
Požadavky
Dokončete část kurzu.
Trénování více modelů
Jednou z výhod použití nástroje Machine Learning Studio (classic) pro vytváření modelů strojového učení je možnost vyzkoušet v jednom experimentu více než jeden typ modelu a porovnat výsledky. Tento typ experimentování vám pomůže najít nejlepší řešení vašeho problému.
V experimentu, který vyvíjíme v tomto kurzu, vytvoříte dva různé typy modelů a pak porovnáte výsledky hodnocení a rozhodnete se, který algoritmus chcete použít v našem posledním experimentu.
Můžete si vybrat z různých modelů. Pokud chcete zobrazit dostupné modely, rozbalte uzel Machine Learning na paletě modulů a pak rozbalte inicializovat model a uzly pod ním. Pro účely tohoto experimentu vyberete moduly SVM (Two-Class Support Vector Machine) a Dvoutřídní rozhodovací strom.
V tomto experimentu přidáte modul Dvoutřídní rozhodovací strom boosted i modul Dvoutřídní vektorový stroj podpory .
Posílený rozhodovací strom se dvěma třídami
Nejprve nastavte model posíleného rozhodovacího stromu.
Najděte modul Rozhodovací strom se dvěma třídami na paletě modulů a přetáhněte ho na plátno.
Najděte modul Trénování modelu , přetáhněte ho na plátno a pak připojte výstup modulu Dvoutřídní rozhodovací strom s levým vstupním portem modulu Trénování modelu .
Modul Rozhodovací strom se dvěma třídami inicializuje obecný model a trénování modelu používá trénovací data k trénování modelu.
Připojte levý výstup modulu Execute R Script k pravému vstupnímu portu modulu Trénování modelu (v tomto kurzu jste použili data přicházející z levé strany modulu Split Data pro trénování).
Tip
Nepotřebujete dva vstupy a jeden z výstupů modulu Execute R Script pro tento experiment, takže je můžete nechat nepřipojené.
Tato část experimentu teď vypadá nějak takto:

Teď potřebujete sdělit modulu Trénování modelu , že má model předpovědět hodnotu úvěrového rizika.
Vyberte modul Trénování modelu . V podokně Vlastnosti klepněte na tlačítko Spustit selektor sloupců.
V dialogovém okně Vybrat jeden sloupec do vyhledávacího pole v části Dostupné sloupce zadejte "úvěrové riziko" a klikněte na tlačítko šipka vpravo (>) a přesuňte "Úvěrové riziko" do vybraných sloupců.
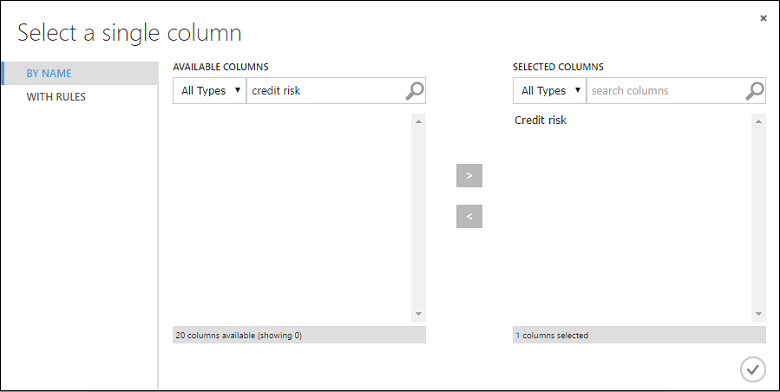
Klikněte na značku zaškrtnutí OK .
Support Vector Machine (SVM) se dvěma třídami
Dále nastavíte model SVM.
Nejdřív trochu vysvětlení SVM. Posílené rozhodovací stromy dobře fungují s funkcemi libovolného typu. Vzhledem k tomu, že modul SVM generuje lineární klasifikátor, má model, který generuje, nejlepší testovací chybu, když všechny číselné funkce mají stejné měřítko. Pokud chcete převést všechny číselné funkce na stejné měřítko, použijte transformaci "Tanh" (s modulem Normalizovat data ). Tím se naše čísla transformují do rozsahu [0,1]. Modul SVM převede řetězcové funkce na kategorické funkce a potom na binární funkce 0/1, takže nemusíte ručně transformovat funkce řetězců. Také nechcete transformovat sloupec Úvěrové riziko (sloupec 21) – jedná se o číselnou hodnotu, ale jedná se o hodnotu, kterou model trénujeme tak, aby předpověděl, takže ho musíte nechat sám.
Pokud chcete nastavit model SVM, postupujte takto:
Najděte modul Dvoutřídní vektorový stroj podpory v paletě modulů a přetáhněte ho na plátno.
Klikněte pravým tlačítkem na modul Trénování modelu , vyberte Kopírovat a potom klikněte pravým tlačítkem myši na plátno a vyberte Vložit. Kopie modulu Trénování modelu má stejný výběr sloupce jako původní.
Připojte výstup modulu Two-Class Support Vector Machine k levému vstupnímu portu druhého modulu Trénování modelu .
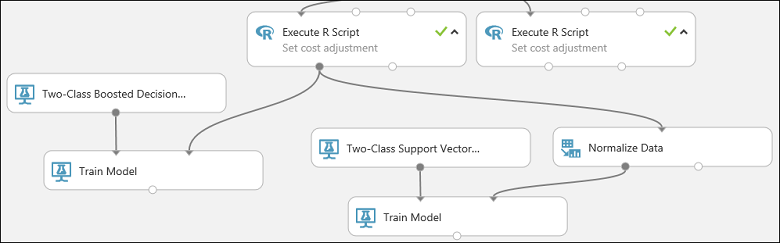
Najděte modul Normalizovat data a přetáhněte ho na plátno.
Připojte levý výstup modulu Execute R Script ke vstupu tohoto modulu (všimněte si, že výstupní port modulu může být připojený k více než jednomu jinému modulu).
Připojte levý výstupní port modulu Normalizovat data ke správnému vstupnímu portu druhého modulu Trénování modelu .
Tato část našeho experimentu by teď měla vypadat nějak takto:
Teď nakonfigurujte modul Normalizovat data :
Kliknutím vyberte modul Normalizovat data . V podokně Vlastnosti vyberte Tanh pro parametr metody Transformace .
Klikněte na Tlačítko Spustit selektor sloupců, vyberte "Žádné sloupce" pro začátek, vyberte Zahrnout do prvního rozevíracího seznamu, vyberte typ sloupce v druhém rozevíracím seznamu a vyberte Číselný v třetím rozevíracím seznamu. Určuje, že se transformují všechny číselné sloupce (a pouze číselné).
Klikněte na znaménko plus (+) napravo od tohoto řádku – tím se vytvoří řádek rozevíracích seznamu. V prvním rozevíracím seznamu vyberte vyloučitnázvy sloupců v druhém rozevíracím seznamu a do textového pole zadejte "Úvěrové riziko". Určuje, že sloupec Úvěrové riziko by se měl ignorovat (musíte to udělat, protože tento sloupec je číselný a proto by se transformoval, pokud jste ho nevyloučili).
Klikněte na značku zaškrtnutí OK .

Modul Normalizovat data je teď nastavený tak, aby prováděl transformaci Tanh u všech číselných sloupců s výjimkou sloupce Úvěrové riziko.
Skóre a vyhodnocení modelů
použijete testovací data oddělená modulem Split Data k hodnocení našich trénovaných modelů. Výsledky těchto dvou modelů pak můžete porovnat a zjistit, které vygenerované lepší výsledky.
Přidání modulů modelu skóre
Najděte modul Score Model a přetáhněte ho na plátno.
Připojte modul Trénování modelu , který je připojený k modulu Dvoutřídní rozhodovací strom s vyššími třídami, k levému vstupnímu portu modulu Score Model .
Připojte správný modul Execute R Script (naše testovací data) ke správnému vstupnímu portu modulu Score Model .

Modul Score Model teď může získat informace o kreditu z testovacích dat, spustit je prostřednictvím modelu a porovnat předpovědi, které model generuje se skutečným sloupcem úvěrového rizika v testovacích datech.
Zkopírujte a vložte modul Score Model a vytvořte druhou kopii.
Připojte výstup modelu SVM (tj. výstupní port modulu Trénování modelu , který je připojený k modulu Dvou tříd podpůrných vektorů) ke vstupnímu portu druhého modulu Model skóre .
Pro model SVM musíte provést stejnou transformaci na testovací data jako u trénovacích dat. Proto zkopírujte a vložte modul Normal Data a vytvořte druhou kopii a připojte ho ke správnému modulu Spustit skript R .
Připojte levý výstup druhého modulu Normalizovat data k pravému vstupnímu portu druhého modulu Model skóre .
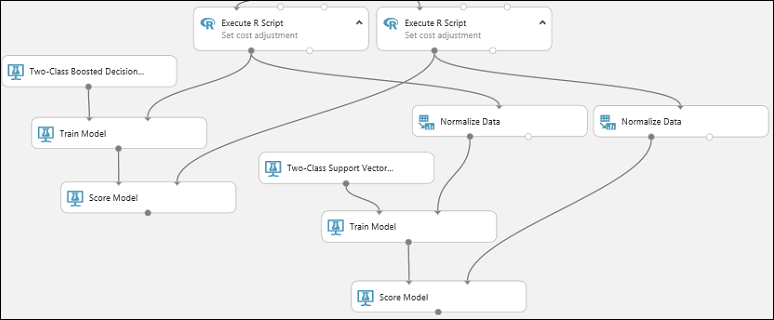
Přidání modulu Vyhodnocení modelu
Pokud chcete vyhodnotit dva výsledky vyhodnocování a porovnat je, použijte modul Vyhodnotit model .
Najděte modul Vyhodnotit model a přetáhněte ho na plátno.
Připojte výstupní port modulu Score Model přidružený k modelu posíleného rozhodovacího stromu k levému vstupnímu portu modulu Vyhodnotit model .
Připojte druhý modul Model skóre ke správnému vstupnímu portu.
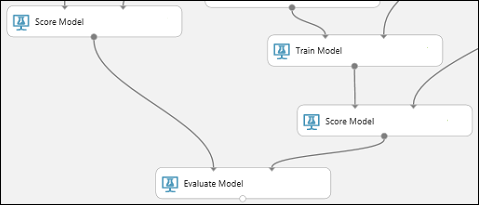
Spuštění experimentu a kontrola výsledků
Pokud chcete experiment spustit, klikněte na tlačítko SPUSTIT pod plátnem. Může to trvat několik minut. Indikátor otáčení v každém modulu ukazuje, že je spuštěný, a po dokončení modulu se zobrazí zelená značka zaškrtnutí. Jakmile všechny moduly mají značku zaškrtnutí, experiment se dokončil.
Experiment by teď měl vypadat nějak takto:
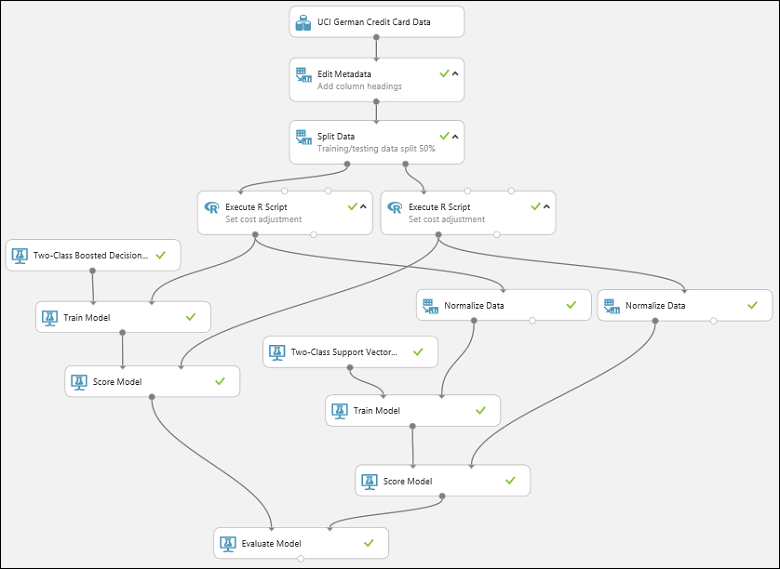
Pokud chcete zkontrolovat výsledky, klikněte na výstupní port modulu Vyhodnotit model a vyberte Vizualizovat.
Modul Vyhodnotit model vytvoří dvojici křivek a metrik, které umožňují porovnat výsledky dvou výkonnostních modelů. Výsledky můžete zobrazit jako křivky charakteristické pro operátor příjemce (ROC), křivky přesnosti a úplnosti nebo křivky lift. Další zobrazená data zahrnují konfuzní matici, kumulativní hodnoty oblasti pod křivkou (AUC) a další metriky. Prahovou hodnotu můžete změnit přesunutím posuvníku doleva nebo doprava a zjistit, jak ovlivňuje sadu metrik.
Napravo od grafu klikněte na vyhodnocenou datovou sadu nebo datovou sadu s skóre, abyste mohli porovnat přidruženou křivku a zobrazit přidružené metriky níže. V legendě pro křivky odpovídá hodnota "Scored dataset" (Vyhodnocená datová sada) levý vstupní port modulu Vyhodnotit model – v našem případě se jedná o model posíleného rozhodovacího stromu. "Výsledná datová sada pro porovnání" odpovídá správnému vstupnímu portu – modelu SVM v našem případě. Když kliknete na některý z těchto popisků, zvýrazní se křivka daného modelu a zobrazí se odpovídající metriky, jak je znázorněno na následujícím obrázku.
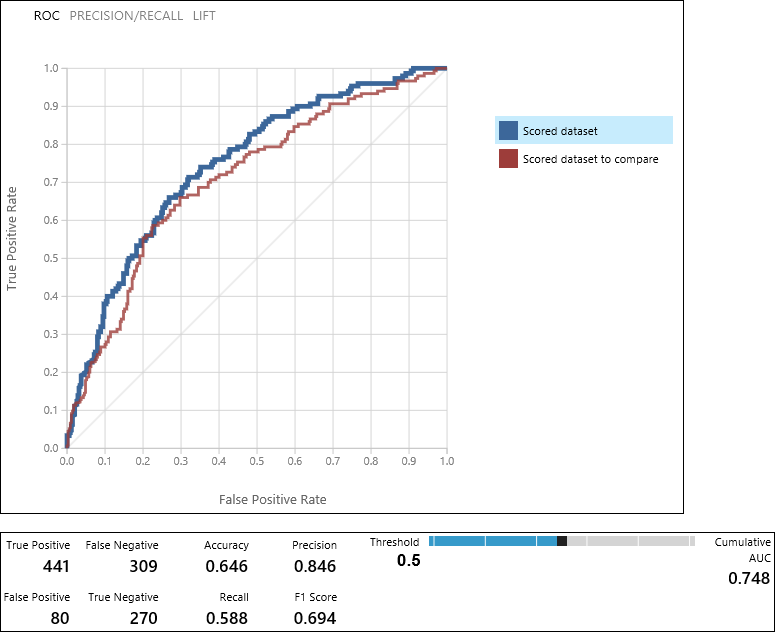
Prozkoumáním těchto hodnot se můžete rozhodnout, který model je nejblíže k tomu, abyste měli výsledky, které hledáte. V experimentu se můžete vrátit a iterovat změnou hodnot parametrů v různých modelech.
Věda a umění interpretování těchto výsledků a ladění výkonu modelu je mimo rozsah tohoto kurzu. Další nápovědu najdete v následujících článcích:
- Vyhodnocení výkonu modelu v nástroji Machine Learning Studio (classic)
- Volba parametrů pro optimalizaci algoritmů v nástroji Machine Learning Studio (classic)
- Interpretace výsledků modelu v nástroji Machine Learning Studio (classic)
Tip
Pokaždé, když experiment spustíte, se záznam této iterace uchovává v historii spuštění. Tyto iterace můžete zobrazit a vrátit se k některému z nich kliknutím na ZOBRAZIT HISTORII SPUŠTĚNÍ pod plátnem. Můžete také kliknout na Předchozí spuštění v podokně Vlastnosti a vrátit se k iteraci bezprostředně před tím, než jste otevřeli.
Kopii libovolné iterace experimentu můžete vytvořit kliknutím na ULOŽIT AS pod plátnem. Pomocí vlastností souhrnu a popisu experimentu můžete uchovávat záznam o tom, co jste se pokusili v iteraci experimentu.
Další informace najdete v tématu Správa iterací experimentů v nástroji Machine Learning Studio (classic).
Vyčištění prostředků
Pokud už nepotřebujete prostředky, které jste vytvořili pomocí tohoto článku, odstraňte je, abyste se vyhnuli poplatkům. Přečtěte si, jak v článku exportovat a odstranit uživatelská data v produktu.
Další kroky
V tomto kurzu jste dokončili tyto kroky:
- Vytvoření experimentu
- Trénování více modelů
- Skóre a vyhodnocení modelů
Teď jste připraveni nasadit modely pro tato data.