Pokyny k relacím M:N
Tento článek se zaměřuje na modelátora dat, který pracuje s Power BI Desktopem. Popisuje tři různé scénáře modelování M:N. Poskytuje také pokyny k úspěšnému návrhu v modelech.
Poznámka:
Úvod do relací modelu není popsaný v tomto článku. Pokud nejste úplně obeznámeni s relacemi, jejich vlastnostmi nebo jejich konfigurací, doporučujeme, abyste si nejdřív přečetli relace modelu v článku Power BI Desktopu .
Je také důležité, abyste porozuměli návrhu hvězdicového schématu. Další informace najdete v tématu Vysvětlení hvězdicového schématu a důležitosti pro Power BI.
Ve skutečnosti existují tři scénáře M:N. K nim může dojít v případě, že potřebujete:
- Vytvořit relaci dvou tabulek typu dimenze
- Spojit dvě tabulky typu fakta
- Spojovat tabulky vyššího typu faktů, pokud tabulka typu fakta ukládá řádky s vyšším agregačním intervalem než řádky tabulky typu dimenze
Poznámka:
Power BI teď nativně podporuje relace M:N. Další informace najdete v tématu Použití relací M:N v Power BI Desktopu.
Spojit dimenze M:N
Podívejme se na první typ scénáře M:N s příkladem. Klasický scénář souvisí se dvěma entitami: bankovními zákazníky a bankovními účty. Vezměte v úvahu, že zákazníci můžou mít více účtů a účty můžou mít více zákazníků. Pokud má účet více zákazníků, běžně se jim říká společní držitelé účtů.
Modelování těchto entit je jednoduché. Jedna tabulka typu dimenze ukládá účty a jiná tabulka typu dimenze ukládá zákazníky. Jak je charakteristické pro tabulky typu dimenze, v každé tabulce je sloupec ID. K modelování relace mezi těmito dvěma tabulkami se vyžaduje třetí tabulka. Tato tabulka se běžně označuje jako přemostění tabulky. V tomto příkladu je účelem uložit jeden řádek pro každé přidružení účtu zákazníka. Zajímavé je, že když tato tabulka obsahuje jenom sloupce ID, nazývá se tabulka faktů bez faktů.
Tady je zjednodušený modelový diagram tří tabulek.
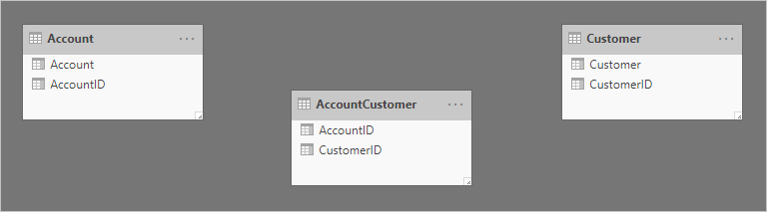
První tabulka má název Account (Účet) a obsahuje dva sloupce: AccountID (ID účtu) a Account (Účet). Druhá tabulka má název AccountCustomer a obsahuje dva sloupce: AccountID a CustomerID. Třetí tabulka má název Customer (Zákazník) a obsahuje dva sloupce: CustomerID (ID zákazníka) a Customer (Zákazník). Relace mezi žádnou z tabulek neexistují.
K propojení tabulek se přidají dvě relace 1:N. Tady je aktualizovaný diagram modelu souvisejících tabulek. Byla přidána tabulka typu fakta s názvem Transakce . Zaznamenává transakce účtů. Tabulka přemostění a všechny sloupce ID jsou skryté.
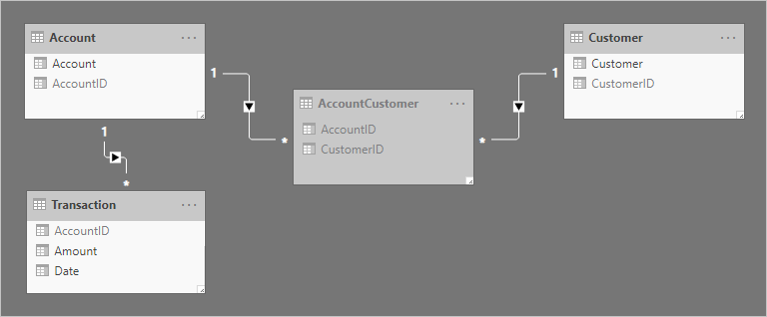
Abychom mohli popsat, jak funguje šíření filtru relací, diagram modelu byl upraven tak, aby zobrazil řádky tabulky.
Poznámka:
V diagramu modelu Power BI Desktopu není možné zobrazit řádky tabulky. V tomto článku se podporuje diskuze s jasnými příklady.

Podrobnosti o řádku pro čtyři tabulky jsou popsány v následujícím seznamu s odrážkami:
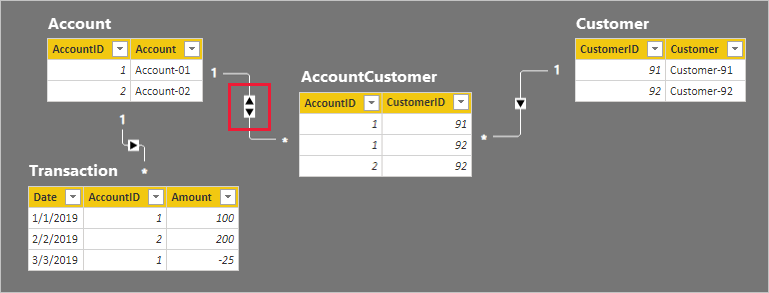
- Tabulka Account (Účet) má dva řádky:
- AccountID 1 je pro Account-01.
- AccountID 2 je pro Account-02.
- Tabulka Customer (Zákazník) má dva řádky:
- CustomerID 91 je pro zákazníka-91.
- CustomerID 92 je pro zákazníka-92.
- Tabulka AccountCustomer má tři řádky:
- Id účtu 1 je přidružené k ID zákazníka 91.
- AccountID 1 je přidružený k CustomerID 92
- AccountID 2 je přidruženo k CustomerID 92
- Tabulka Transakce má tři řádky:
- Datum 1. ledna 2019, AccountID 1, Amount 100
- Datum 2. února 2019, AccountID 2, Částka 200
- Datum 3. března 2019, AccountID 1, Amount -25
Pojďme se podívat, co se stane, když se model dotazuje.
Níže jsou dva vizuály, které shrnují sloupec Amount z tabulky Transakce . První vizuál seskupí podle účtu, takže součet sloupců Částka představuje zůstatek na účtu. Druhý vizuál seskupí podle zákazníka, takže součet sloupců Částka představuje zůstatek zákazníka.
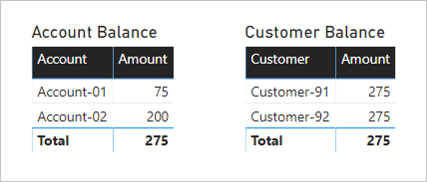
První vizuál má název Zůstatek na účtu a má dva sloupce: Account (Účet) a Amount (Částka). Zobrazí následující výsledek:
- Zůstatek na účtu 01 je 75
- Zůstatek na účtu 02 je 200
- Celkový počet je 275
Druhý vizuál má název Zůstatek zákazníka a má dva sloupce: Customer (Zákazník) a Amount (Částka). Zobrazí následující výsledek:
- Částka zůstatku customer-91 je 275
- Částka zůstatku customer-92 je 275
- Celkový počet je 275
Rychlý pohled na řádky tabulky a vizuál Zůstatek účtu odhalí, že výsledek je správný pro každý účet a celkovou částku. Je to proto, že každé seskupení účtů vede k šíření filtru do tabulky Transakce pro daný účet.
U vizuálu Customer Balance se ale něco nezobrazuje správně. Každý zákazník ve vizuálu Zůstatek zákazníka má stejný zůstatek jako celkový zůstatek. Tento výsledek by mohl být správný pouze v případě, že každý zákazník byl společným držitelem účtu každého účtu. To není případ v tomto příkladu. Problém souvisí s šířením filtru. Není tok až do tabulky Transaction .
Postupujte podle pokynů filtru relací z tabulky Customer (Zákazník ) do tabulky Transaction (Transakce ). Je zřejmé, že relace mezi tabulkou Account a AccountCustomer se šíří nesprávným směrem. Směr filtru pro tuto relaci musí být nastaven na Obě.
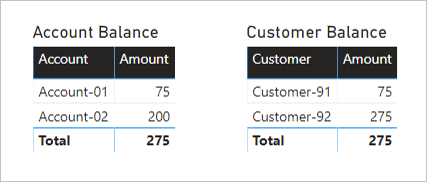
Podle očekávání nedošlo k žádné změně vizuálu Zůstatek účtu.
Vizuály Customer Balance ale teď zobrazují následující výsledek:
- Částka zůstatku customer-91 je 75
- Částka zůstatku customer-92 je 275
- Celkový počet je 275
Vizuál Customer Balance teď zobrazuje správný výsledek. Postupujte podle pokynů filtru pro sebe a podívejte se, jak se vypočítaly zůstatky zákazníků. Mějte také na vědomí, že celkový součet vizuálu znamená všechny zákazníky.
Někdo neznámý s relacemi modelu by mohl dojít k závěru, že výsledek je nesprávný. Mohou se zeptat: Proč není celkový zůstatek pro Customer-91 a Customer-92 roven 350 (75 + 275)?
Odpověď na jejich otázku spočívá v pochopení vztahu M:N. Každý zůstatek zákazníka může představovat sčítání více zůstatků účtů, takže zůstatek zákazníků není sčítá.
Pokyny k relacím dimenzí M:N
Pokud máte relaci M:N mezi tabulkami typu dimenze, poskytujeme následující doprovodné materiály:
- Přidejte každou entitu související s M:N jako tabulku modelu a ujistěte se, že má sloupec jedinečného identifikátoru (ID).
- Přidání přemostění tabulky pro uložení přidružených entit
- Vytvoření relací 1:N mezi třemi tabulkami
- Nakonfigurujte jednu obousměrnou relaci tak, aby umožňovala šíření filtru i nadále do tabulek typu fakta.
- Pokud není vhodné mít chybějící hodnoty ID, nastavte vlastnost Is Nullable sloupců ID na NEPRAVDA – aktualizace dat se nezdaří, pokud chybějící hodnoty jsou zdrojové.
- Skryjte tabulku přemostění (pokud neobsahuje další sloupce nebo míry potřebné pro vytváření sestav).
- Skryjte všechny sloupce ID, které nejsou vhodné pro vytváření sestav (například pokud jsou ID náhradními klíči).
- Pokud má smysl ponechat sloupec ID viditelný, ujistěte se, že je na snímku relace "jeden" – vždy skryjte sloupec na straně N. Výsledkem je nejlepší výkon filtru.
- Abyste se vyhnuli nejasnostem nebo nesprávné interpretaci, sdělte uživatelům sestavy vysvětlení – popisy můžete přidat pomocí textových polí nebo popisů záhlaví vizuálu.
Nedoporučujeme přímo propojit tabulky typu dimenze M:N. Tento přístup návrhu vyžaduje konfiguraci relace s kardinalitou M:N. Koncepčně se dá dosáhnout, ale znamená to, že související sloupce budou obsahovat duplicitní hodnoty. Je to dobře uznávaný postup návrhu, ale že tabulky typu dimenze mají sloupec ID. Tabulky typu dimenze by měly vždy používat sloupec ID jako stranu 1 relace.
Související fakta M:N
Druhý typ scénáře M:N zahrnuje korelaci dvou tabulek typu fakta. Dvě tabulky typu fakta můžou souviset přímo. Tato technika návrhu může být užitečná pro rychlé a jednoduché zkoumání dat. Obecně ale tento přístup k návrhu nedoporučujeme. Vysvětlíme si, proč později v této části.
Pojďme se podívat na příklad, který zahrnuje dvě tabulky typu fakta: Order (Objednávka ) a Fulfillment (Plnění). Tabulka Order (Objednávka ) obsahuje jeden řádek na řádek objednávky a tabulka Fulfillment (Plnění ) může obsahovat nula nebo více řádků na řádek objednávky. Řádky v tabulce Order představují prodejní objednávky. Řádky v tabulce Fulfillment (Plnění) představují položky objednávky, které byly odeslány. Relace M:N spojuje dva sloupce OrderID s šířením filtru pouze z tabulky Objednávky (Objednávka filtruje Plnění).
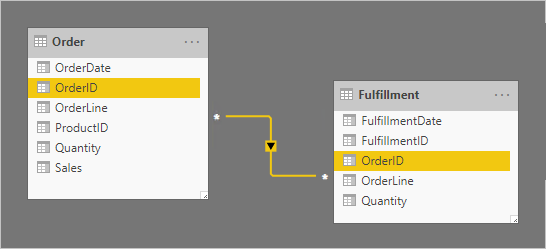
Kardinalita relace je nastavená na M:N, aby podporovala ukládání duplicitních hodnot OrderID v obou tabulkách. V tabulce Objednávky mohou existovat duplicitní hodnoty ORDERID, protože objednávka může mít více řádků. V tabulce Fulfillment (Plnění) můžou existovat duplicitní hodnoty OrderID (IDobjednávky), protože objednávky můžou mít více řádků a řádky objednávek mohou být splněny mnoha zásilkami.
Teď se podíváme na řádky tabulky. V tabulce Fulfillment (Plnění) si všimněte, že řádky objednávek mohou být splněny několika zásilkami. (Absence řádku objednávky znamená, že objednávka ještě není splněna.)
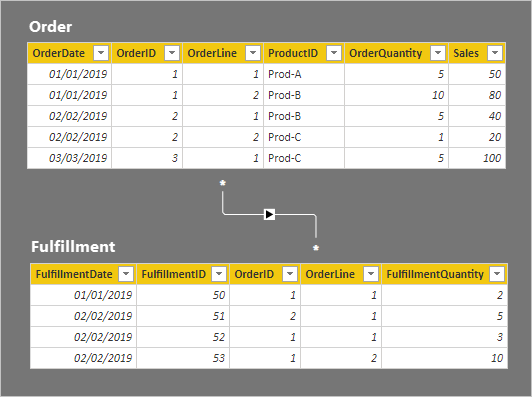
Podrobnosti o řádku pro tyto dvě tabulky jsou popsány v následujícím seznamu s odrážkami:
- Tabulka Order obsahuje pět řádků:
- OrderDate January 1 2019, OrderID 1, OrderLine 1, ProductID Prod-A, OrderQuantity 5, Sales 50
- OrderDate January 1 2019, OrderID 1, OrderLine 2, ProductID Prod-B, OrderQuantity 10, Sales 80
- OrderDate February 2 2019, OrderID 2, OrderLine 1, ProductID Prod-B, OrderQuantity 5, Sales 40
- OrderDate February 2 2019, OrderID 2, OrderLine 2, ProductID Prod-C, OrderQuantity 1, Sales 20
- OrderDate March 3 2019, OrderID 3, OrderLine 1, ProductID Prod-C, OrderQuantity 5, Sales 100
- Tabulka Fulfillment (Plnění ) má čtyři řádky:
- FulfillmentDate January 1 2019, FulfillmentID 50, OrderID 1, OrderLine 1, FulfillmentQuantity 2
- FulfillmentDate February 2 2019, FulfillmentID 51, OrderID 2, OrderLine 1, FulfillmentQuantity 5
- FulfillmentDate February 2 2019, FulfillmentID 52, OrderID 1, OrderLine 1, FulfillmentQuantity 3
- FulfillmentDate January 1 2019, FulfillmentID 53, OrderID 1, OrderLine 2, FulfillmentQuantity 10
Pojďme se podívat, co se stane, když se model dotazuje. Tady je vizuál tabulky, který porovnává množství objednávek a plnění podle sloupce Order table OrderID (ID objednávky).
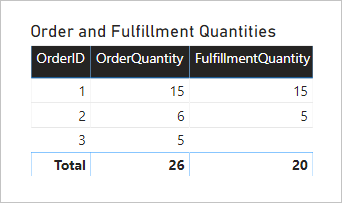
Vizuál představuje přesný výsledek. Užitečnost modelu je však omezená – můžete filtrovat nebo seskupovat pouze podle sloupce OrderID tabulky OrderID ( OrderID).
Pokyny k faktům M:N
Obecně nedoporučujeme spojování dvou tabulek typu fakta přímo pomocí kardinality M:N. Hlavním důvodem je to, že model nebude poskytovat flexibilitu ve způsobech filtrování nebo seskupení vizuálů sestav. V tomto příkladu je možné vizuály filtrovat nebo seskupovat pouze podle sloupce Order table OrderID (ID objednávky). Další důvod souvisí s kvalitou vašich dat. Pokud mají vaše data problémy s integritou, je možné, že během dotazování se některé řádky vynechaly kvůli povaze omezené relace. Další informace najdete v tématu Relace modelu v Power BI Desktopu (vyhodnocení relací).
Místo přímé korelace tabulek faktů doporučujeme použít principy návrhu hvězdicového schématu . Provedete to přidáním tabulek typu dimenze. Tabulky typu dimenze se pak vztahují k tabulkám typu fakta pomocí relací 1:N. Tento přístup k návrhu je robustní, protože nabízí flexibilní možnosti vytváření sestav. Umožňuje filtrovat nebo seskupovat pomocí libovolného sloupce typu dimenze a shrnout všechny související tabulky typu fakta.
Pojďme se podívat na lepší řešení.
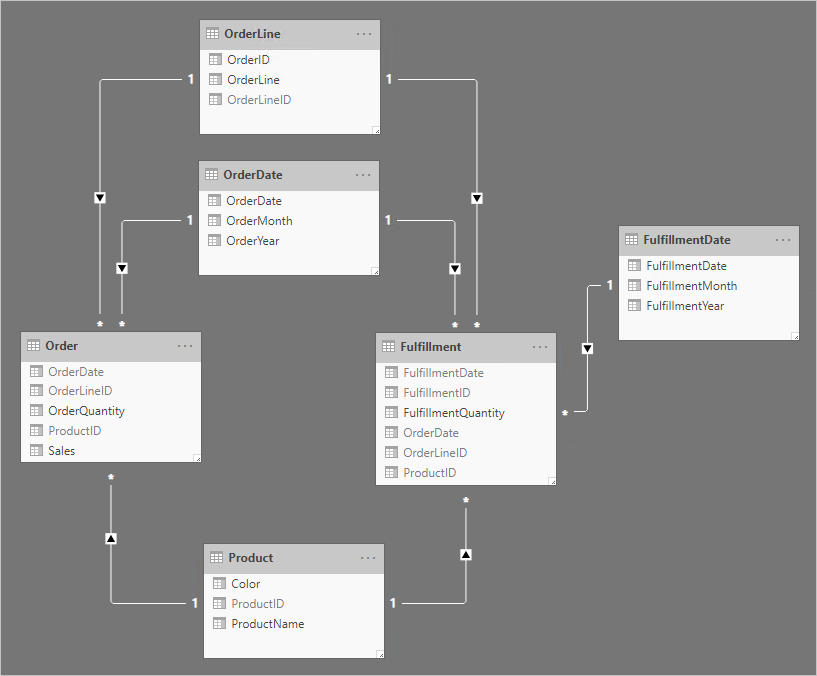
Všimněte si následujících změn návrhu:
- Model teď obsahuje čtyři další tabulky: OrderLine (Řádekobjednávky), OrderDate (DatumObjednávky), Product (Produkt) a FulfillmentDate (Datum plnění).
- Čtyři další tabulky jsou všechny tabulky typu dimenze a relace 1:N souvisejí s tabulkami typu fakta.
- Tabulka OrderLine obsahuje sloupec OrderLineID , který představuje hodnotu OrderID vynásobenou hodnotou 100 a hodnotou OrderLine – jedinečný identifikátor pro každý řádek objednávky.
- Tabulky Objednávky a Plnění teď obsahují sloupec OrderLineID a už neobsahují sloupce OrderID a OrderLine.
- Tabulka Fulfillment (Plnění) teď obsahuje sloupce OrderDate (DatumObjednávky) a ProductID (ID produktu).
- Tabulka FulfillmentDate se vztahuje pouze k tabulce Fulfillment (Plnění)
- Všechny sloupce jedinečného identifikátoru jsou skryté.
Používání principů návrhu hvězdicového schématu přináší následující výhody:
- Vizuály sestavy můžou filtrovat nebo seskupovat podle libovolného viditelného sloupce z tabulek typu dimenze.
- Vizuály sestavy můžou shrnout libovolný viditelný sloupec z tabulek typu faktů.
- Filtry použité u tabulek OrderLine, OrderDate nebo Product se rozšíří do obou tabulek typu fakta.
- Všechny relace jsou 1:N a každá relace je normální. Problémy s integritou dat nebudou maskovány. Další informace najdete v tématu Relace modelu v Power BI Desktopu (vyhodnocení relací).
Související fakta vyšší úrovně
Tento scénář M:N se od ostatních dvou popsaných v tomto článku velmi liší.
Podívejme se na příklad zahrnující čtyři tabulky: Date (Datum), Sales ( Prodej), Product (Produkt) a Target (Cíl). Date a Product jsou tabulky typu dimenze a relace 1:N se vztahují k tabulce Fakta Sales. Zatím představuje dobrý návrh hvězdicového schématu. Cílová tabulka ale zatím nesouvisí s ostatními tabulkami.
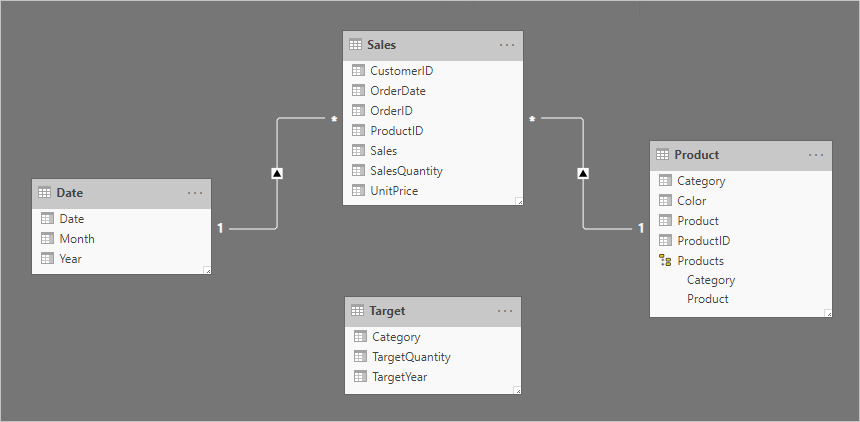
Tabulka Target (Cíl ) obsahuje tři sloupce: Category (Kategorie), TargetQuantity (TargetQuantity) a TargetYear (Cílová kategorie). Řádky tabulky odhalí členitost roku a kategorie produktů. Jinými slovy, cíle používané k měření prodejního výkonu se pro každou kategorii produktů nastavují každý rok.
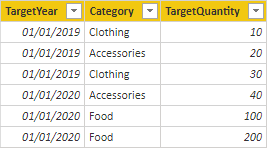
Vzhledem k tomu, že cílová tabulka ukládá data na vyšší úrovni než tabulky typu dimenze, nelze vytvořit relaci 1:N. No, je to pravda jen pro jednu z těchto vztahů. Pojďme se podívat, jak může cílová tabulka souviset s tabulkami typu dimenze.
Spojit vyšší časová období
Relace mezi tabulkami Date a Target by měla být relace 1:N. Je to proto, že hodnoty sloupce TargetYear jsou kalendářní data. V tomto příkladu je každá hodnota sloupce TargetYear prvním datem cílového roku.
Tip
Při ukládání faktů v delším časovém intervalu než den nastavte datový typ sloupce na Datum (nebo Kdo le číslo, pokud používáte klíče kalendářních dat). Ve sloupci uložte hodnotu představující první den časového období. Například roční období se zaznamenává jako 1. ledna roku a měsíční období se zaznamená jako první den daného měsíce.
Je však potřeba dbát na to, aby filtry na úrovni měsíců nebo kalendářních dat měly smysluplný výsledek. Bez jakékoli zvláštní logiky výpočtu můžou vizuály sestav hlásit, že cílová data jsou doslova prvním dnem každého roku. Všechny ostatní dny a všechny měsíce kromě ledna shrnou cílové množství jako BLANK.
Následující maticový vizuál ukazuje, co se stane, když uživatel sestavy přejde z roku na jeho měsíce. Vizuál shrnuje sloupec TargetQuantity . (Zobrazení položek bez možnosti dat bylo pro řádky matice povolené.)
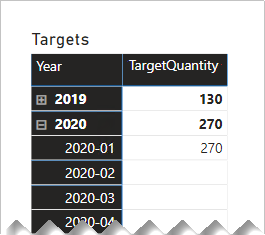
Abyste se tomuto chování vyhnuli, doporučujeme řídit souhrn dat faktů pomocí měr. Jedním ze způsobů, jak řídit sumarizaci, je vrátit prázdnou hodnotu při dotazování na časová období nižší úrovně. Dalším způsobem, který je definovaný pomocí některých sofistikovaných jazyka DAX, je apportion hodnot napříč nižšími časovými obdobími.
Představte si následující definici míry, která používá funkci DAX ISFILTERED . Vrátí hodnotu pouze v případech, kdy nejsou filtrované sloupce Date nebo Month .
Target Quantity =
IF(
NOT ISFILTERED('Date'[Date])
&& NOT ISFILTERED('Date'[Month]),
SUM(Target[TargetQuantity])
)
Následující maticový vizuál teď používá míru Cílové množství . Ukazuje, že všechna měsíční cílová množství jsou PRÁZDNÁ.

Spojit vyšší agregační interval (jiné než datum)
Při korelaci sloupce bez kalendářního data z tabulky typu dimenze k tabulce typu fakta se vyžaduje jiný přístup návrhu (a je vyšší než tabulka typu dimenze).
Sloupce Kategorie (z tabulek Product i Target) obsahují duplicitní hodnoty. Takže neexistuje žádný "jeden" pro relaci 1:N. V tomto případě budete muset vytvořit relaci M:N. Relace by měla šířit filtry jedním směrem z tabulky typu dimenze do tabulky typu fakta.
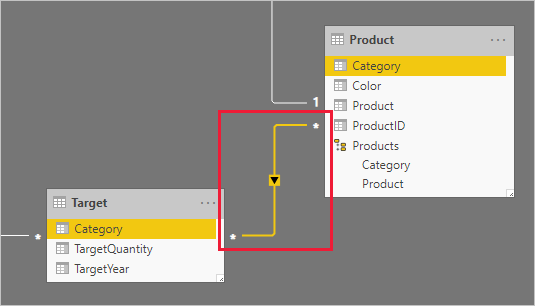
Teď se podíváme na řádky tabulky.
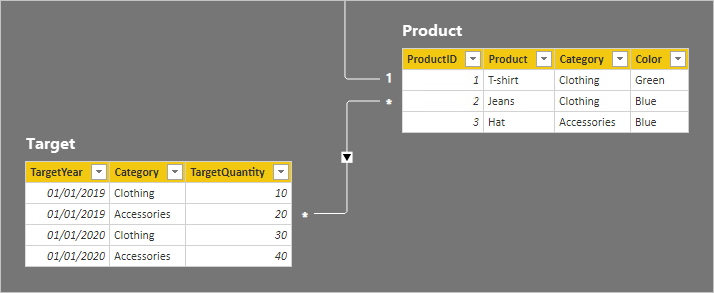
V cílové tabulce jsou čtyři řádky: dva řádky pro každý cílový rok (2019 a 2020) a dvě kategorie (Oblečení a příslušenství). V tabulce Product (Produkt) jsou tři produkty. Dvě patří do kategorie oblečení a jedna patří do kategorie příslušenství. Jedna z barev oblečení je zelená a zbývající dvě barvy jsou modré.
Vizuál tabulky seskupující podle sloupce Category (Kategorie ) z tabulky Product (Produkt ) vytvoří následující výsledek.
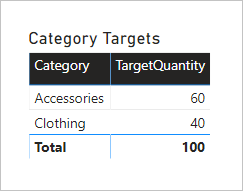
Tento vizuál vytvoří správný výsledek. Pojďme se teď podívat, co se stane, když se sloupec Color z tabulky Product použije k seskupení cílového množství.

Vizuál vytvoří nesprávnou reprezentaci dat. Co se tady děje?
Výsledkem filtru sloupce Color (Barva) z tabulky Product (Produkt) jsou dva řádky. Jeden z řádků je pro kategorii Oblečení a druhý je pro kategorii Příslušenství. Tyto dvě hodnoty kategorií se šíří jako filtry do cílové tabulky. Jinými slovy, protože barva modrá je používána produkty ze dvou kategorií, tyto kategorie se používají k filtrování cílů.
Abyste se tomuto chování vyhnuli, jak je popsáno výše, doporučujeme řídit souhrn dat faktů pomocí měr.
Zvažte následující definici míry. Všimněte si, že filtry testují všechny sloupce tabulky Product , které jsou pod úrovní kategorií.
Target Quantity =
IF(
NOT ISFILTERED('Product'[ProductID])
&& NOT ISFILTERED('Product'[Product])
&& NOT ISFILTERED('Product'[Color]),
SUM(Target[TargetQuantity])
)
Následující vizuál tabulky teď používá míru Cílové množství . Ukazuje, že všechna cílová množství barev jsou PRÁZDNÁ.
Konečný návrh modelu vypadá takto:
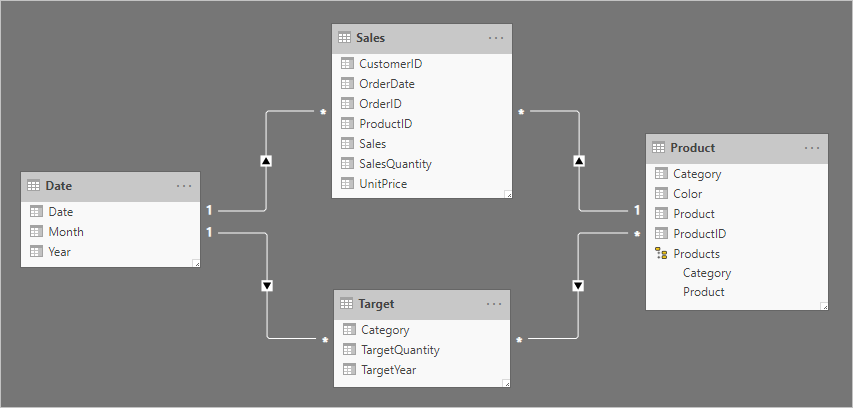
Související doprovodné materiály k vyšším podrobnostem
Pokud potřebujete propojit tabulku typu dimenze s tabulkou typu fakta a tabulka typu fakta ukládá řádky s vyšší úrovní než řádky tabulky typu dimenze, poskytujeme následující pokyny:
- Pro data vyšších faktů:
- V tabulce typu fakta uložte první datum časového období.
- Vytvoření relace 1:N mezi tabulkou kalendářních dat a tabulkou typu fakta
- Další fakta vyšší úrovně:
- Vytvoření relace M:N mezi tabulkou typu dimenze a tabulkou typu fakta
- Pro oba typy:
- Shrnutí ovládacích prvků pomocí logiky míry – vrátí prázdnou hodnotu, pokud se sloupce typu dimenze nižší úrovně používají k filtrování nebo seskupení.
- Skrytí souhrnných sloupců tabulky typu fakta – tímto způsobem lze k sumarizaci tabulky faktů použít pouze míry.
Související obsah
Další informace týkající se tohoto článku najdete v následujících zdrojích informací:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro