Vysvětlení hvězdicového schématu a důležitosti pro Power BI
Tento článek se zaměřuje na modelátory dat Power BI Desktopu. Popisuje návrh hvězdicového schématu a jeho význam pro vývoj datových modelů Power BI optimalizovaných pro výkon a použitelnost.
Tento článek nemá v úmyslu poskytnout úplnou diskuzi o návrhu hvězdicového schématu. Další podrobnosti najdete přímo v publikovaném obsahu, například The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling (3. vydání, 2013) od Ralph Kimball a dalších.
Přehled hvězdicové schéma
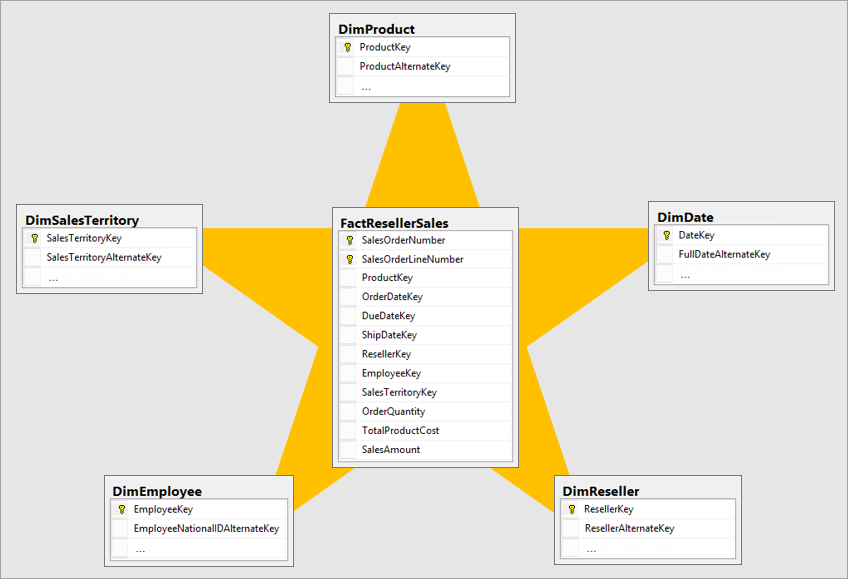
Hvězdicové schéma je vyspělý přístup k modelování široce přijímaný relačními datovými sklady. Vyžaduje, aby modelátoři klasifikovali tabulky modelu jako dimenze nebo fakta.
Tabulky dimenzí popisují obchodní entity – věci, které modelujete. Entity můžou zahrnovat produkty, lidi, místa a koncepty včetně samotného času. Nejkonzistence tabulky, kterou najdete ve hvězdicovém schématu, je tabulka dimenzí kalendářních dat. Tabulka dimenzí obsahuje klíčový sloupec (nebo sloupce), který funguje jako jedinečný identifikátor a popisné sloupce.
Tabulky faktů ukládají pozorování nebo události a mohou to být prodejní objednávky, zůstatky zásob, směnné kurzy, teploty atd. Tabulka faktů obsahuje klíčové sloupce dimenzí, které souvisejí s tabulkami dimenzí a sloupci číselné míry. Klíčové sloupce dimenze určují dimenzionalitu tabulky faktů, zatímco hodnoty klíče dimenze určují členitost tabulky faktů. Představte si například tabulku faktů navrženou tak, aby ukládaly cíle prodeje, které mají dva klíčové sloupce dimenze Date a ProductKey. Je snadné pochopit, že tabulka má dvě dimenze. Členitost však nelze určit bez ohledu na hodnoty klíče dimenze. V tomto příkladu vezměte v úvahu, že hodnoty uložené ve sloupci Datum jsou prvním dnem každého měsíce. V tomto případě je členitost na úrovni měsíčního produktu.
Obecně platí, že tabulky dimenzí obsahují relativně malý počet řádků. Tabulky faktů na druhé straně můžou obsahovat velmi velký počet řádků a v průběhu času pokračovat v růstu.
Normalizace vs. denormalizace
Abyste pochopili některé koncepty hvězdicových schémat popsaných v tomto článku, je důležité znát dva termíny: normalizaci a denormalizaci.
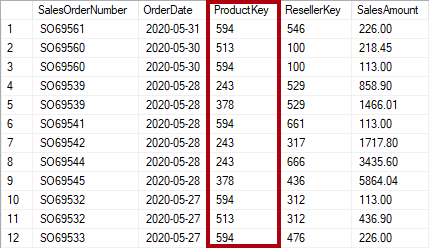
Normalizace je termín použitý k popisu dat uložených způsobem, který repetitní data snižuje. Představte si tabulku produktů, která má sloupec jedinečné klíčové hodnoty, například kód Product Key, a další sloupce popisující charakteristiky produktu, včetně názvu produktu, kategorie, barvy a velikosti. Tabulka prodejů se považuje za normalizovanou, když ukládá jenom klíče, jako je kód Product Key. Na následujícím obrázku si všimněte, že produkt zaznamenává pouze sloupec ProductKey .
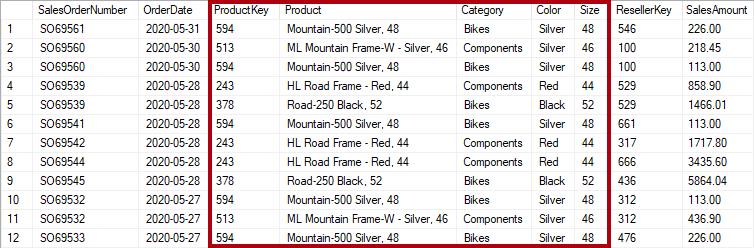
Pokud ale tabulka sales ukládá podrobnosti o produktu nad rámec tohoto klíče, považuje se za nenormalizovaný. Na následujícím obrázku si všimněte, že ProductKey a další sloupce související s produktem zaznamenávají produkt.
Když zdrojujete data ze souboru exportu nebo extrahování dat, je pravděpodobné, že představuje denormalizovanou sadu dat. V tomto případě pomocí Power Query transformujte a tvarujte zdrojová data do několika normalizovaných tabulek.
Jak je popsáno v tomto článku, měli byste se snažit vyvíjet optimalizované datové modely Power BI s tabulkami, které představují normalizovaná data faktů a dimenzí. Existuje však jedna výjimka, kdy by se měla denormalizovat dimenze sněhové vločky, aby se vytvořila jedna tabulka modelu.
Relevance hvězdicových schémat pro modely Power BI
Návrh hvězdicového schématu a mnoho souvisejících konceptů představených v tomto článku jsou vysoce relevantní pro vývoj modelů Power BI, které jsou optimalizované pro výkon a použitelnost.
Vezměte v úvahu, že každý vizuál sestavy Power BI generuje dotaz, který se odešle do modelu Power BI (který služba Power BI volá sémantický model – dříve označovaný jako datová sada). Tyto dotazy slouží k filtrování, seskupování a sumarizaci dat modelu. Dobře navržený model je pak ten, který poskytuje tabulky pro filtrování a seskupování a tabulky pro shrnutí. Tento návrh dobře odpovídá principům hvězdicového schématu:
- Tabulky dimenzí podporují filtrování a seskupování
- Tabulky faktů podporují souhrny.
Neexistuje žádná vlastnost tabulky, kterou modelátoři nastavují tak, aby typ tabulky nakonfigurovali jako dimenzi nebo fakt. Ve skutečnosti je určen relacemi modelu. Relace modelu vytvoří cestu šíření filtru mezi dvěma tabulkami a je to vlastnost kardinality relace, která určuje typ tabulky. Společná kardinalita relace je 1:N nebo její inverzní funkce M:1. Strana "jedna" je vždy tabulka typu dimenze, zatímco strana N je vždy tabulka typu fakta. Další informace o relacích najdete v tématu Relace modelu v Power BI Desktopu.
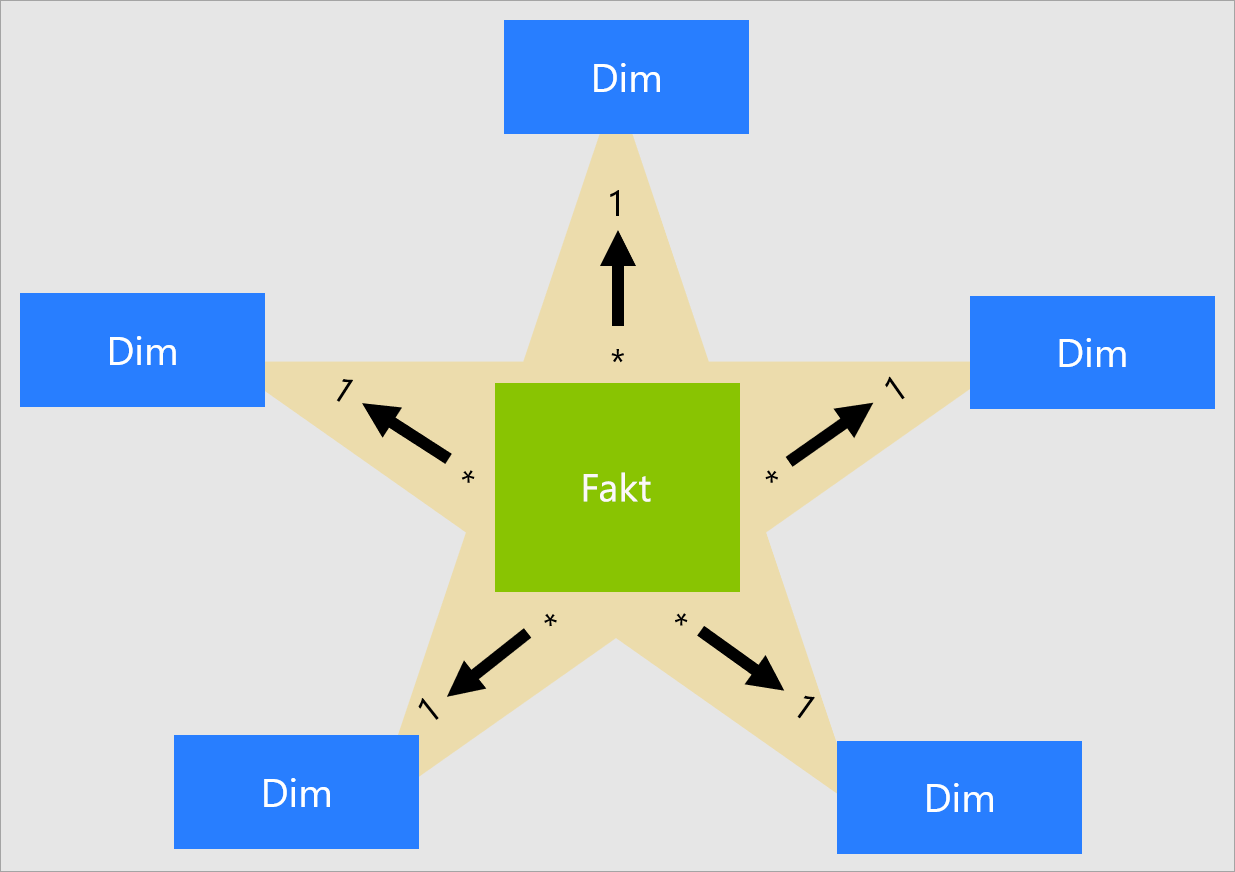
Dobře strukturovaný návrh modelu by měl zahrnovat tabulky, které jsou tabulky typu dimenze nebo tabulky typu fakta. Vyhněte se kombinování těchto dvou typů pro jednu tabulku. Doporučujeme také, abyste se snažili zajistit správný počet tabulek se správnými relacemi. Je také důležité, aby tabulky faktů vždy načítá data s konzistentním agregačním intervalem.
Nakonec je důležité pochopit, že optimální návrh modelu je part science and part art. Někdy se můžete porušit dobrými pokyny, když to dává smysl.
Existuje mnoho dalších konceptů souvisejících s návrhem hvězdicového schématu, které je možné použít u modelu Power BI. Mezi tyto koncepty patří:
- Opatření
- Náhradní klíče
- Sněhové vločkové rozměry
- Dimenze rolí
- Pomalu se měnící dimenze
- Rozměry nevyžádané pošty
- Degenerovat dimenze
- Tabulky faktů bez faktů
Opatření
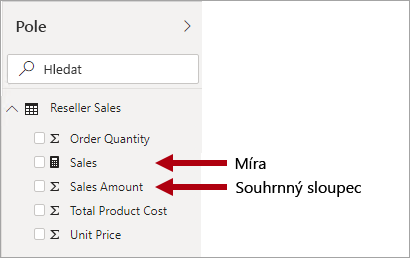
V návrhu hvězdicového schématu je míra sloupec tabulky faktů, který ukládá hodnoty, které se mají shrnout.
V modelu Power BI má míra jinou (ale podobnou) definici. Jedná se o vzorec napsaný v jazyce DAX (Data Analysis Expressions), který umožňuje sumarizaci. Výrazy měr často využívají agregační funkce JAZYKA DAX, jako je SUM, MIN, MAX, AVERAGE atd. k vytvoření výsledku skalární hodnoty v době dotazu (hodnoty se nikdy neukládají v modelu). Výraz míry může být v rozsahu od jednoduchých agregací sloupců až po sofistikovanější vzorce, které přepisují kontext filtru nebo šíření relací. Další informace najdete v článku Základy jazyka DAX v Power BI Desktopu .
Je důležité si uvědomit, že modely Power BI podporují druhou metodu pro dosažení souhrnu. Libovolný sloupec (a obvykle číselné sloupce) je možné shrnout vizuálem sestavy nebo Q&A. Tyto sloupce se označují jako implicitní míry. Nabízejí vám pohodlí jako vývojář modelu, protože v mnoha případech nemusíte vytvářet míry. Například sloupec Sales Amount prodejce Adventure Works může být sumarizovat mnoha způsoby (součet, počet, průměr, medián, minimum, maximum atd.), aniž by bylo nutné vytvořit míru pro každý možný typ agregace.
Existují však tři přesvědčivé důvody pro vytváření měr, a to i pro jednoduché souhrny na úrovni sloupců:
- Pokud víte, že autoři sestav budou dotazovat model pomocí multidimenzionálních výrazů (MDX), musí model obsahovat explicitní míry. Explicitní míry jsou definovány pomocí jazyka DAX. Tento přístup k návrhu je vysoce relevantní v případě, že se datová sada Power BI dotazuje pomocí jazyka MDX, protože jazyk MDX nemůže dosáhnout souhrnu hodnot sloupců. Při provádění funkce Analyzovat v aplikaci Excel se použije zejména jazyk MDX, protože kontingenční tabulky vydávají dotazy MDX.
- Pokud víte, že autoři sestav vytvoří stránkované sestavy Power BI pomocí návrháře dotazů MDX, musí model obsahovat explicitní míry. Agregace serverů podporuje pouze návrhář dotazů MDX. Takže pokud autoři sestav potřebují mít míry vyhodnocené Power BI (nikoli stránkovaným modulem sestav), musí použít návrháře dotazů MDX.
- Pokud potřebujete zajistit, aby autoři sestav mohli shrnout sloupce jenom určitými způsoby. Například sloupec Sales Unit Price prodejce (který představuje jednotkovou sazbu) lze shrnout, ale pouze pomocí konkrétních agregačních funkcí. Nikdy by se neměl sečíst, ale je vhodné shrnout pomocí dalších agregačních funkcí, jako je min, max, průměr atd. V tomto případě může modeler skrýt sloupec Jednotková cena a vytvořit míry pro všechny příslušné agregační funkce.
Tento přístup k návrhu funguje dobře pro sestavy vytvořené v služba Power BI a pro Q&A. Živá připojení Power BI Desktopu ale autorům sestav umožňují zobrazit skrytá pole v podokně Pole , což může vést k obcházení tohoto přístupu k návrhu.
Náhradní klíče
Náhradní klíč je jedinečný identifikátor, který přidáte do tabulky pro podporu modelování hvězdicového schématu. Podle definice není definován nebo uložen ve zdrojových datech. Do tabulek dimenzí relačního datového skladu se obvykle přidávají náhradní klíče, které poskytují jedinečný identifikátor pro každý řádek tabulky dimenzí.
Relace modelu Power BI jsou založené na jednom jedinečném sloupci v jedné tabulce, který šíří filtry do jednoho sloupce v jiné tabulce. Pokud tabulka typu dimenze v modelu neobsahuje jediný jedinečný sloupec, musíte přidat jedinečný identifikátor, který se stane "jednou" stranou relace. V Power BI Desktopu můžete tento požadavek snadno dosáhnout vytvořením indexového sloupce Power Query.

Tento dotaz musíte sloučit s dotazem na straně N, abyste do něj mohli přidat také indexový sloupec. Když tyto dotazy načtete do modelu, můžete mezi tabulkami modelu vytvořit relaci 1:N.
Sněhové vločkové rozměry
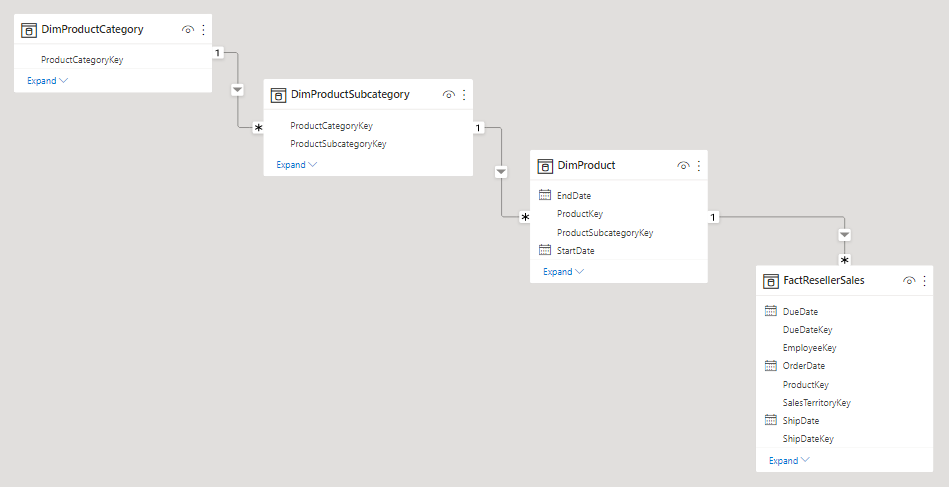
Dimenze sněhové vločky je sada normalizovaných tabulek pro jednu obchodní entitu. Například Adventure Works klasifikuje produkty podle kategorie a podkategorie. Produkty se přiřazují k podkategorií a podkategorie jsou zase přiřazené kategoriím. V relačním datovém skladu Společnosti Adventure Works se dimenze produktu normalizuje a ukládá ve třech souvisejících tabulkách: DimProductCategory, DimProductSubcategory a DimProduct.
Pokud používáte svoji fantazii, můžete si představit normalizované tabulky umístěné ven z tabulky faktů, které tvoří sněhové vločky návrh.
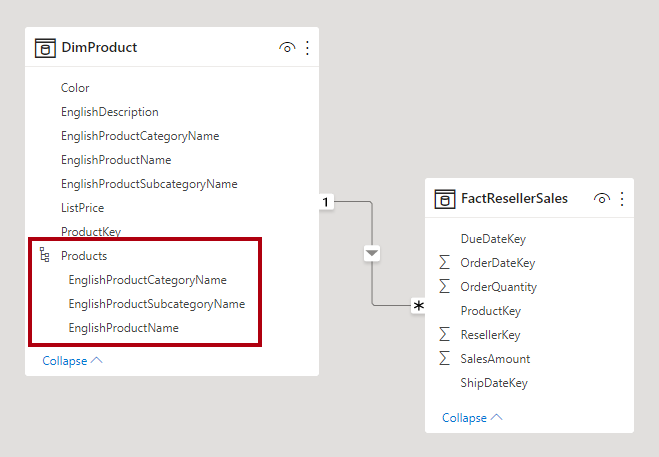
V Power BI Desktopu můžete napodobovat návrh sněhové vločkové dimenze (možná proto, že zdrojová data dělá) nebo integrovat (denormalizovat) zdrojové tabulky do jedné tabulky modelu. Obecně platí, že výhody jedné tabulky modelu převáží nad výhodami více tabulek modelu. Nejoptimálnější rozhodnutí může záviset na objemech dat a požadavcích na použitelnost modelu.
Když se rozhodnete napodobovat návrh sněhové vločkové dimenze:
- Power BI načte více tabulek, což je méně efektivní z hlediska úložiště a výkonu. Tyto tabulky musí obsahovat sloupce pro podporu relací modelu a výsledkem může být větší velikost modelu.
- Delší řetězce šíření filtru relací bude potřeba projít, což bude pravděpodobně méně efektivní než filtry použité u jedné tabulky.
- Podokno Pole představuje autorům sestav více tabulek modelu, což může vést k méně intuitivnímu prostředí, zejména v případě, že tabulky dimenzí sněhové vločky obsahují jenom jeden nebo dva sloupce.
- Není možné vytvořit hierarchii, která zahrnuje tabulky.
Když se rozhodnete integrovat do jedné tabulky modelu, můžete také definovat hierarchii, která zahrnuje nejvyšší a nejnižší úroveň dimenze. Úložiště redundantních denormalizovaných dat může mít za následek větší velikost úložiště modelu, zejména u velmi velkých tabulek dimenzí.
Pomalu se měnící dimenze
Pomalu se měnící dimenze (SCD) je ta, která v průběhu času správně spravuje změnu členů dimenze. Platí, když se hodnoty obchodních entit mění v průběhu času a ad hoc. Dobrým příkladem pomalu se měnící dimenze je dimenze zákazníka, konkrétně sloupce podrobností o kontaktu, jako je e-mailová adresa a telefonní číslo. Naproti tomu některé dimenze se považují za rychle se měnící, když se atribut dimenze často mění, například tržní cena akcií. Běžným přístupem k návrhu v těchto instancích je ukládání rychle se měnících hodnot atributů do míry tabulky faktů.
Teorie návrhu hvězdicového schématu odkazuje na dva běžné typy SCD: Typ 1 a Typ 2. Tabulka typu dimenze může být Typu 1 nebo Typ 2 nebo podporuje oba typy současně pro různé sloupce.
Typ 1 – SCD
ScD typu 1vždy odráží nejnovější hodnoty a při zjištění změn zdrojových dat se přepíšou data tabulky dimenzí. Tento přístup k návrhu je běžný u sloupců, které ukládají doplňkové hodnoty, například e-mailovou adresu nebo telefonní číslo zákazníka. Když se změní e-mailová adresa zákazníka nebo telefonní číslo, tabulka dimenzí aktualizuje řádek zákazníka o nové hodnoty. Je to jako by zákazník měl vždy tyto kontaktní informace.
Nekrementální aktualizace tabulky dimenzí modelu Power BI dosáhne výsledku scD typu 1. Aktualizuje data tabulky, aby se zajistilo načtení nejnovějších hodnot.
Typ 2 – SCD
ScD typu 2podporuje správu verzí členů dimenze. Pokud zdrojový systém neukládá verze, je to obvykle proces načítání datového skladu, který detekuje změny a správně spravuje změnu v tabulce dimenzí. V tomto případě musí tabulka dimenzí použít náhradní klíč k poskytnutí jedinečného odkazu na verzi člena dimenze. Obsahuje také sloupce, které definují platnost rozsahu kalendářních dat verze (například StartDate a EndDate) a případně sloupec příznaku (například IsCurrent), aby bylo možné snadno filtrovat podle aktuálních členů dimenze.
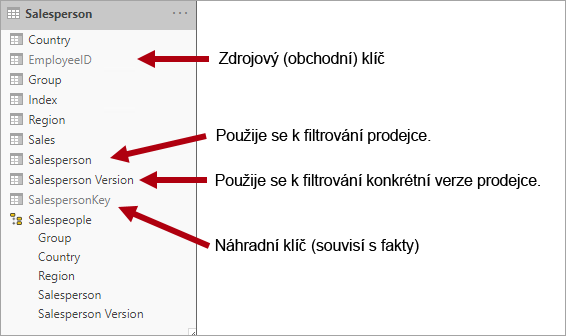
Například Adventure Works přiřazuje prodejcům prodejní oblast. Když prodejce přemístí oblast, musí být vytvořena nová verze prodejce, aby se zajistilo, že historická fakta zůstanou přidružená k bývalé oblasti. Aby byla podpora přesné historické analýzy prodeje podle prodejce, musí tabulka dimenzí ukládat verze prodejců a jejich přidružených oblastí. Tabulka by také měla obsahovat hodnoty počátečního a koncového data pro definování doby platnosti. Aktuální verze můžou definovat prázdné koncové datum (nebo 12. 31. 9999), které označuje, že řádek je aktuální verzí. Tabulka musí také definovat náhradní klíč, protože obchodní klíč (v tomto případě ID zaměstnance) nebude jedinečný.
Je důležité vědět, že pokud zdrojová data neukládají verze, musíte k detekci a uložení změn použít zprostředkující systém (například datový sklad). Proces načtení tabulky musí zachovat existující data a detekovat změny. Po zjištění změny musí proces načtení tabulky vypršet aktuální verzi. Tyto změny zaznamenává aktualizací hodnoty EndDate a vložením nové verze s hodnotou StartDate od předchozí hodnoty EndDate. Související fakta také musí použít vyhledávání založené na čase k načtení hodnoty klíče dimenze relevantní pro datum faktu. Tento výsledek nemůže vytvořit model Power BI, který používá Power Query. Může ale načíst data z předem načtené tabulky dimenzí TYPU 2.
Model Power BI by měl podporovat dotazování historických dat pro člena bez ohledu na změnu a pro verzi člena, která představuje konkrétní stav člena v čase. V kontextu společnosti Adventure Works umožňuje tento návrh dotazovat prodejce bez ohledu na přiřazenou prodejní oblast nebo pro konkrétní verzi prodejce.
K dosažení tohoto požadavku musí tabulka dimenzí modelu Power BI obsahovat sloupec pro filtrování prodejce a jiný sloupec pro filtrování konkrétní verze prodejce. Je důležité, aby sloupec verze poskytoval nejednoznačný popis, například "Michael Blythe (12. 15. 2008-06.26.2019)" nebo "Michael Blythe (aktuální)". Je také důležité informovat autory sestav a uživatele o základech SCD Type 2 a o tom, jak dosáhnout vhodných návrhů sestav pomocí správných filtrů.
Je také dobrým postupem návrhu zahrnout hierarchii, která umožňuje vizuálům přejít k podrobnostem na úrovni verze.
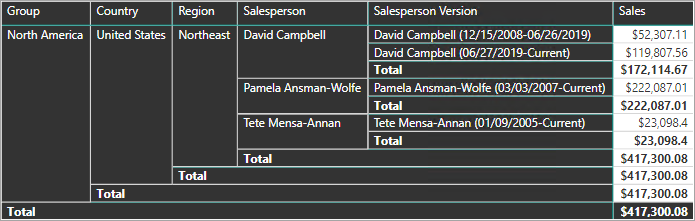
Dimenze role
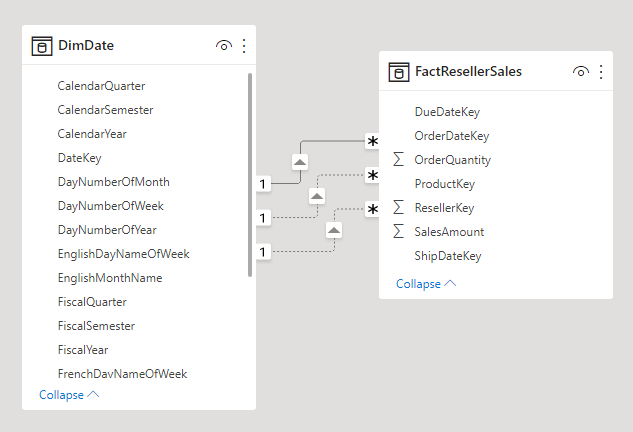
Dimenze role je dimenze , která může filtrovat související fakta odlišně. Například v Adventure Works má tabulka dimenzí kalendářních dat tři relace s fakty o prodeji prodejců. Stejnou tabulku dimenzí lze použít k filtrování faktů podle data objednávky, data expedice nebo data doručení.
V datovém skladu je akceptovaným přístupem k návrhu definovat jednu tabulku dimenzí kalendářních dat. V době dotazu je "role" dimenze data stanovena sloupcem faktů, který používáte ke spojení tabulek. Když například analyzujete prodej podle data objednávky, spojení tabulky se vztahuje ke sloupci data prodejní objednávky prodejce.
V modelu Power BI může být tento návrh napodobován vytvořením více relací mezi dvěma tabulkami. V příkladu Adventure Works by tabulky kalendářních dat a prodejů prodejců měly tři relace. I když je tento návrh možný, je důležité si uvědomit, že mezi dvěma tabulkami modelu Power BI může existovat jenom jedna aktivní relace. Všechny zbývající relace musí být nastavené na neaktivní. Když máte jednu aktivní relaci, znamená to, že existuje výchozí šíření filtru od data do prodeje prodejců. V tomto případě je aktivní relace nastavená na nejběžnější filtr, který používá sestavy, což v Adventure Works je relace data objednávky.
Jediným způsobem, jak použít neaktivní relaci, je definovat výraz DAX, který používá funkci USERELATIONSHIP. V našem příkladu musí vývojář modelu vytvořit míry, které umožní analýzu prodeje prodejců podle data expedice a data doručení. Tato práce může být zdlouhavá, zejména pokud tabulka prodejců definuje mnoho měr. Vytvoří také nepotřebné podokno Pole s nadměrnou sadou měr. Existují i další omezení:
- Když autoři sestav spoléhají na sumarizaci sloupců místo definování měr, nemůžou dosáhnout sumarizace neaktivních relací, aniž by museli psát míru na úrovni sestavy. Míry na úrovni sestav se dají definovat jenom při vytváření sestav v Power BI Desktopu.
- S pouze jednou aktivní cestou relace mezi datem a prodejem prodejců není možné současně filtrovat prodej prodejců podle různých typů kalendářních dat. Nemůžete například vytvořit vizuál, který vykresluje prodej data objednávky podle expedovaných prodejů.
Pro vyřešení těchto omezení je běžnou technikou modelování Power BI vytvoření tabulky typu dimenze pro každou instanci role. Pomocí jazyka DAX obvykle vytvoříte další tabulky dimenzí jako počítané tabulky. Pomocí počítaných tabulek může model obsahovat tabulku Kalendářní datum , tabulku Datum expedice a tabulku Datum doručení, z nichž každá má jednu a aktivní relaci s příslušnými sloupci tabulky prodejů prodejců.
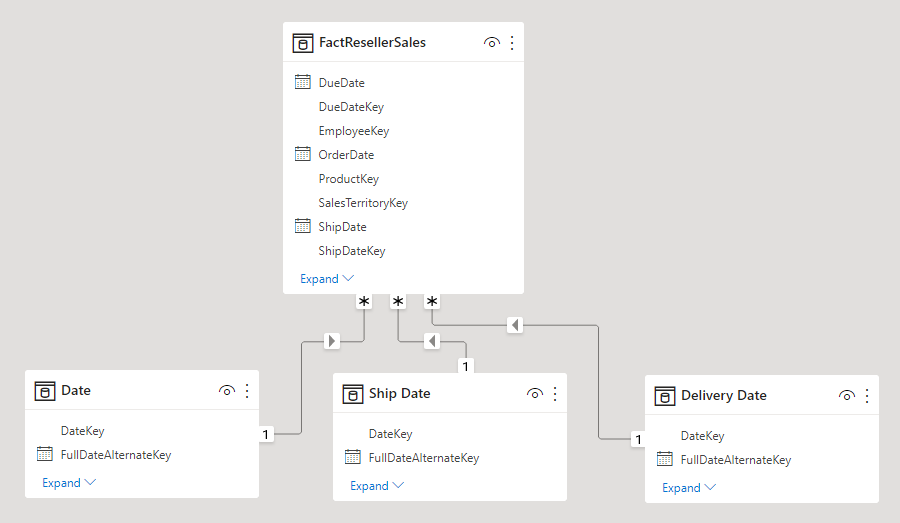
Tento přístup k návrhu nevyžaduje definování více měr pro různé role kalendářních dat a umožňuje souběžné filtrování podle různých rolí kalendářních dat. Při použití tohoto návrhového přístupu je však menší cena, která bude duplikovat tabulku dimenzí kalendářních dat, což vede ke zvýšení velikosti úložiště modelu. Vzhledem k tomu, že tabulky typu dimenze obvykle ukládají méně řádků vzhledem k tabulkám faktů, je to jen zřídkakdy problém.
Při vytváření tabulek dimenzí modelu pro každou roli si projděte následující osvědčené postupy návrhu:
- Ujistěte se, že názvy sloupců popisují samy sebe. I když je možné mít sloupec Year ve všech tabulkách kalendářních dat (názvy sloupců jsou jedinečné v rámci tabulky), ve výchozím nastavení není popisující názvy vizuálů. Zvažte přejmenování sloupců v každé tabulce rolí dimenzí, aby tabulka Datum expedice obsahuje sloupec rok s názvem Ship Year atd.
- Pokud je to relevantní, ujistěte se, že popisy tabulek poskytují autorům sestav zpětnou vazbu (prostřednictvím popisů podokna Pole ) o konfiguraci šíření filtru. Tato přehlednost je důležitá, když model obsahuje obecně pojmenovanou tabulku, jako je Datum, která slouží k filtrování mnoha tabulek faktů. V případě, že má tato tabulka například aktivní relaci se sloupcem data prodejní objednávky prodejce, zvažte zadání popisu tabulky, například "Filtruje prodej prodejců podle data objednávky".
Další informace najdete v tématu Aktivní vs. Pokyny k neaktivním relacím.
Rozměry nevyžádané pošty
Nevyžádaná dimenze je užitečná, pokud existuje mnoho dimenzí, zejména skládající se z několika atributů (třeba jednoho) a když mají tyto atributy několik hodnot. Mezi vhodné kandidáty patří sloupce stavu objednávky nebo demografické sloupce zákazníků (pohlaví, věková skupina atd.).
Cílem návrhu nevyžádané dimenze je konsolidovat mnoho "malých" dimenzí do jedné dimenze, aby se zmenšila velikost úložiště modelu a také zmenšila nepotřebná podokno Pole tím, že zmenšuje méně tabulek modelu.
Tabulka nevyžádaných dimenzí je obvykle kartézský součin všech členů atributů dimenze se sloupcem náhradního klíče. Náhradní klíč poskytuje jedinečný odkaz na každý řádek v tabulce. Dimenzi můžete vytvořit v datovém skladu nebo pomocí Power Query vytvořit dotaz, který provede úplné spojení s vnějšími dotazy, a pak přidá náhradní klíč (indexový sloupec).
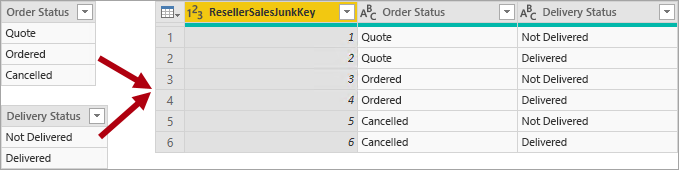
Tento dotaz načtete do modelu jako tabulku typu dimenze. Tento dotaz také musíte sloučit s dotazem faktů, takže se indexový sloupec načte do modelu, aby podporoval vytvoření relace modelu 1:N.
Degenerované dimenze
Degenerovaná dimenze odkazuje na atribut tabulky faktů, který je nutný pro filtrování. V Adventure Works je dobrým příkladem číslo prodejní objednávky prodejce. V tomto případě nemá smysl pro návrh modelu vytvořit nezávislou tabulku, která se skládá jenom z tohoto jednoho sloupce, protože by se zvětšila velikost úložiště modelu a výsledkem by byla nepotřebná podokno Pole .
V modelu Power BI může být vhodné přidat sloupec čísla prodejní objednávky do tabulky typu fakta, aby bylo možné filtrovat nebo seskupovat podle čísla prodejní objednávky. Jedná se o výjimku z dříve zavedeného pravidla, které byste neměli kombinovat typy tabulek (obecně platí, že tabulky modelu by měly být typu dimenze nebo typu fakta).
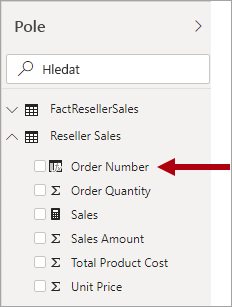
Pokud má tabulka prodejů společnosti Adventure Works číslo objednávky a čísla řádku objednávky a jsou potřeba k filtrování, je vhodný návrh tabulky degenerované dimenze. Další informace najdete v tématu Pokyny k relacím 1:1 (degenerované dimenze).
Tabulky faktů bez faktů
Tabulka faktů bez faktů neobsahuje žádné sloupce měr. Obsahuje pouze klíče dimenzí.
Tabulka faktů bez faktů může ukládat pozorování definovaná klíči dimenzí. Například u konkrétního data a času se konkrétní zákazník přihlásil k vašemu webu. Můžete definovat míru, která spočítá řádky tabulky faktů bez faktů, abyste mohli provádět analýzu toho, kdy a kolik zákazníků se přihlásilo.
Poutavějším použitím tabulky faktů bez faktů je ukládání relací mezi dimenzemi a jedná se o přístup návrhu modelu Power BI, který doporučujeme definovat relace dimenzí M:N. V návrhu relací dimenzí M:N se tabulka faktů bez faktů označuje jako přemostění tabulky.
Představte si například, že prodejce je možné přiřadit k jedné nebo více prodejním oblastem. Tabulka přemostění by byla navržena jako tabulka faktů bez faktů skládající se ze dvou sloupců: klíč prodejce a klíč oblasti. Duplicitní hodnoty lze uložit do obou sloupců.
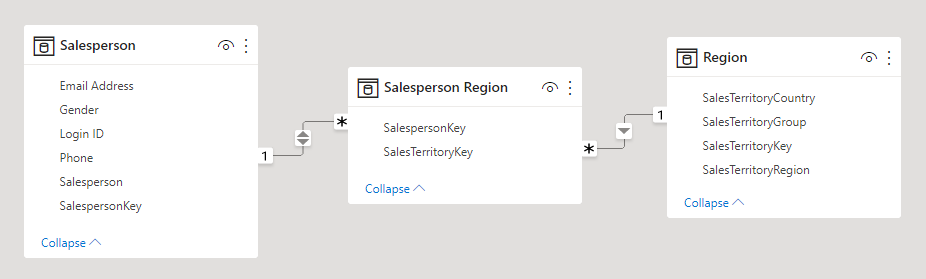
Tento přístup návrhu M:N je dobře zdokumentovaný a dá se dosáhnout bez přemostění tabulky. Přístup k přemostění tabulky se však považuje za osvědčený postup při spojování dvou dimenzí. Další informace najdete v tématu Pokyny k relacím M:N (Propojení dvou tabulek typu dimenze).
Související obsah
Další informace o návrhu hvězdicového schématu nebo návrhu modelu Power BI najdete v následujících článcích:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro