Pokyny pro relaci 1:1
Tento článek se zaměřuje na modelátora dat, který pracuje s Power BI Desktopem. Poskytuje pokyny k práci s relacemi modelu 1:1. Relaci 1:1 je možné vytvořit, když obě tabulky obsahují sloupec společných a jedinečných hodnot.
Poznámka:
Úvod do relací modelu není popsaný v tomto článku. Pokud nejste úplně obeznámeni s relacemi, jejich vlastnostmi nebo jejich konfigurací, doporučujeme, abyste si nejdřív přečetli relace modelu v článku Power BI Desktopu .
Je také důležité, abyste porozuměli návrhu hvězdicového schématu. Další informace najdete v tématu Vysvětlení hvězdicového schématu a důležitosti pro Power BI.
Existují dva scénáře, které zahrnují relace 1:1:
Degenerované dimenze: Degenerované dimenze můžete odvodit z tabulky typu fakta.
Data řádků jsou rozložená mezi tabulkami: Jedna obchodní entita nebo předmět se načte jako dvě (nebo více) tabulek modelu, protože jejich data pocházejí z různých úložišť dat. Tento scénář může být běžný pro tabulky typu dimenze. Například hlavní podrobnosti o produktech jsou uloženy v provozním prodejním systému a doplňkové podrobnosti o produktu jsou uloženy v jiném zdroji.
Je ale neobvyklé, že byste s relacemi typu 1:1 vzájemně souviseli se dvěma tabulkami typu fakta. Je to proto, že obě tabulky typu fakta by musely mít stejnou dimenzionalitu a členitost. Každá tabulka typu fakta by také potřebovala jedinečné sloupce, aby bylo možné vytvořit relaci modelu.
Degenerované dimenze
Pokud se sloupce z tabulky typu fakta používají k filtrování nebo seskupování, můžete zvážit jejich zpřístupnění v samostatné tabulce. Tímto způsobem oddělíte sloupce použité pro filtrování nebo seskupení, od těchto sloupců, které slouží k sumarizaci řádků faktů. Toto oddělení může:
- Snížení úložného prostoru
- Zjednodušení výpočtů modelu
- Přispívání ke zlepšení výkonu dotazů
- Zajištění intuitivnějšího prostředí podokna Pole autorům sestav
Představte si zdrojovou tabulku prodeje, která ukládá podrobnosti o prodejní objednávce ve dvou sloupcích.

Sloupec OrderNumber ukládá číslo objednávky a sloupec OrderLineNumber ukládá posloupnost řádků v rámci objednávky.
V následujícím diagramu modelu si všimněte, že se do tabulky Sales nenačetly sloupce čísla objednávky a řádku objednávky. Místo toho se jejich hodnoty použily k vytvoření náhradního sloupce klíče s názvem SalesOrderLineID. (Hodnota klíče se vypočítá vynásobením čísla objednávky číslem 1000 a následným přidáním čísla řádku objednávky.)
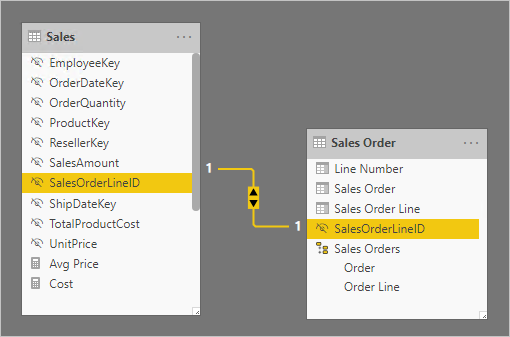
Tabulka Sales Order (Prodejní objednávka) poskytuje bohaté prostředí pro autory sestav se třemi sloupci: Sales Order (Prodejní objednávka), Sales Order Line (Řádek prodejní objednávky) a Line Number (Číslo řádku). Zahrnuje také hierarchii. Tyto prostředky tabulky podporují návrhy sestav, které potřebují filtrovat, seskupovat nebo procházet podrobnosti podle objednávek a řádků objednávek.
Vzhledem k tomu, že tabulka Sales Order (Prodejní objednávka ) je odvozená z dat o prodeji, měla by být v každé tabulce přesně stejný počet řádků. Dále by měly existovat odpovídající hodnoty mezi jednotlivými sloupci SalesOrderLineID .
Data řádků napříč tabulkami
Představte si příklad zahrnující dvě tabulky typu dimenze typu 1:1: Product (Produkt) a Product Category (Kategorie produktu). Každá tabulka představuje importovaná data a obsahuje sloupec SKU (Skladová jednotka), který obsahuje jedinečné hodnoty.
Tady je částečný modelový diagram dvou tabulek.
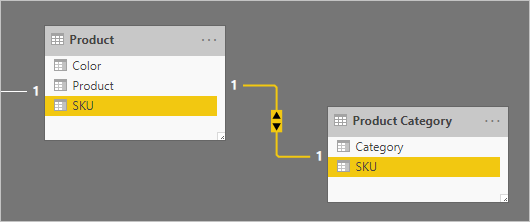
První tabulka má název Product (Produkt) a obsahuje tři sloupce: Color (Barva), Product (Produkt) a SKU (SKU). Druhá tabulka má název Product Category (Kategorie produktu) a obsahuje dva sloupce: Category (Kategorie) a SKU (SKU). Relace 1:1 spojuje dva sloupce SKU . Relace filtruje v obou směrech, což je vždy případ relací 1:1.
Abychom mohli popsat, jak funguje šíření filtru relací, diagram modelu byl upraven tak, aby zobrazil řádky tabulky. Všechny příklady v tomto článku jsou založené na těchto datech.
Poznámka:
V diagramu modelu Power BI Desktopu není možné zobrazit řádky tabulky. V tomto článku se podporuje diskuze s jasnými příklady.
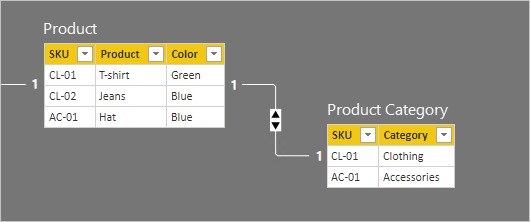
Podrobnosti o řádku pro tyto dvě tabulky jsou popsány v následujícím seznamu s odrážkami:
- Tabulka Product obsahuje tři řádky:
- SKU CL-01, Tričko produktu , Barva zelená
- SKU CL-02, Produkt džíny, Barva modrá
- SKU AC-01, Produktový klobouk, barva modrá
- Tabulka Kategorie produktu obsahuje dva řádky:
- Skladová položka CL-01, Oblečení kategorie
- SKU AC-01, Příslušenství kategorie
Všimněte si, že tabulka Kategorie produktu neobsahuje řádek pro skladovou položku produktu CL-02. Důsledky tohoto chybějícího řádku probereme dále v tomto článku.
V podokně Pole autoři sestav vyhledá pole související s produktem ve dvou tabulkách: Product (Produkt) a Product Category (Kategorie produktu).
Pojďme se podívat, co se stane, když se pole z obou tabulek přidají do vizuálu tabulky. V tomto příkladu je sloupec SKU zdrojový z tabulky Product .
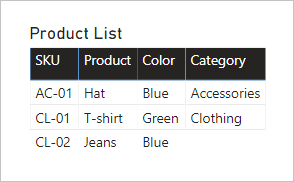
Všimněte si, že hodnota Kategorie pro skladovou položku produktu CL-02 je PRÁZDNÁ. Je to proto, že v tabulce Product Category (Kategorie produktu) pro tento produkt neexistuje žádný řádek.
Doporučení
Pokud je to možné, doporučujeme, abyste se vyhnuli vytváření relací modelu 1:1, když data řádků překlenují mezi tabulkami modelu. Je to proto, že tento návrh může:
- Přispívání do podokna Pole – nepotřebné, výpis více tabulek, než je potřeba
- Ztěžte autorům sestav vyhledání souvisejících polí, protože jsou distribuovaná napříč několika tabulkami.
- Omezte možnost vytvářet hierarchie, protože jejich úrovně musí být založené na sloupcích ze stejné tabulky.
- Vytvoření neočekávaných výsledků v případech, kdy mezi tabulkami není úplná shoda řádků
Konkrétní doporučení se liší v závislosti na tom, jestli je relace 1:1 uvnitř zdrojové skupiny nebo mezi zdrojovou skupinou. Další informace o vyhodnocení relací najdete v tématu Relace modelu v Power BI Desktopu (vyhodnocení relací).
Relace 1:1 v rámci zdrojové skupiny
Pokud mezi tabulkami existuje relace 1:1 uvnitř zdrojové skupiny , doporučujeme data konsolidovat do jedné tabulky modelu. To se provádí sloučením dotazů Power Query.
Následující kroky představují metodologii pro konsolidaci a modelování dat souvisejících s 1:1:
Sloučit dotazy: Při kombinování těchto dvou dotazů je potřeba vzít v úvahu úplnost dat v každém dotazu. Pokud jeden dotaz obsahuje úplnou sadu řádků (například hlavní seznam), sloučí s ním druhý dotaz. Nakonfigurujte transformaci sloučení tak, aby používala levé vnější spojení, což je výchozí typ spojení. Tento typ spojení zajistí, že budete uchovávat všechny řádky prvního dotazu a doplnit je všemi odpovídajícími řádky druhého dotazu. Rozbalte všechny požadované sloupce druhého dotazu do prvního dotazu.
Zakázat načtení dotazu: Nezapomeňte zakázat načtení druhého dotazu. Tímto způsobem se výsledek nenačte jako tabulka modelu. Tato konfigurace zmenšuje velikost úložiště datového modelu a pomáhá zpřehltit podokno Pole .
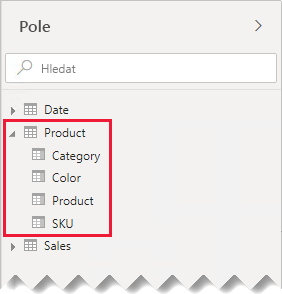
V našem příkladu teď autoři sestav najdou v podokně Pole jednu tabulku s názvem Produkt. Obsahuje všechna pole související s produktem.
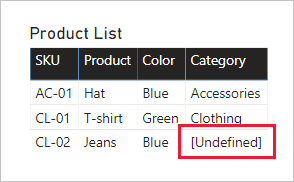
Nahrazení chybějících hodnot: Pokud druhý dotaz obsahuje chybějící řádky, hodnoty NUL Se zobrazí ve sloupcích zavedených z něj. V případě potřeby zvažte nahrazení hodnot NUL hodnotou tokenu. Nahrazení chybějících hodnot je zvlášť důležité, když autoři sestav filtrují nebo seskupují podle hodnot sloupců, protože v vizuálech sestav se můžou zobrazovat prázdné hodnoty.
V následujícím vizuálu tabulky si všimněte, že kategorie skladové položky produktu CL-02 teď čte [Undefined]. V dotazu byly kategorie null nahrazeny touto textovou hodnotou tokenu.
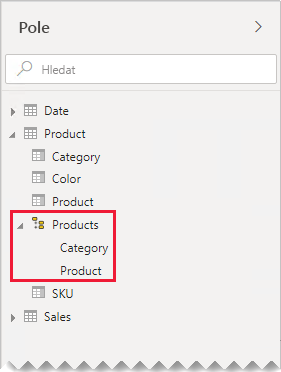
Vytváření hierarchií: Pokud mezi sloupci nyní sloučené tabulky existují relace, zvažte vytvoření hierarchií. Autoři sestav tak rychle identifikují příležitosti k procházení vizuálů sestav.
V našem příkladu teď můžou autoři sestav používat hierarchii, která má dvě úrovně: Category (Kategorie ) a Product (Produkt).
Pokud se vám líbí, jak samostatné tabulky pomáhají uspořádat pole, doporučujeme slučovat do jedné tabulky. Pole můžete pořád uspořádat, ale místo toho můžete použít složky zobrazení.
V našem příkladu můžou autoři sestav najít pole Kategorie ve složce Zobrazení marketingu.
Pokud je to možné, stále se rozhodnete definovat relace 1:1 uvnitř zdrojové skupiny v modelu, pokud je to možné, ujistěte se, že v souvisejících tabulkách jsou odpovídající řádky. Vzhledem k tomu, že relace 1:1 uvnitř zdrojové skupiny se vyhodnocuje jako běžná relace, můžou se problémy s integritou dat ve vizuálech sestavy zobrazit jako prázdné hodnoty. (Příklad seskupení BLANK můžete vidět v prvním vizuálu tabulky, který je uvedený v tomto článku.)
Relace 1:1 mezi zdrojovými skupinami
Pokud mezi tabulkami existuje relace 1:1 mezi zdroji , neexistuje žádný alternativní návrh modelu – pokud data ve zdrojích dat předem nekonsolidujete. Power BI vyhodnotí relaci modelu 1:1 jako omezenou relaci. Proto dbejte na to, aby se v souvisejících tabulkách shodovaly řádky, protože výsledky dotazu nebudou mít odpovídající řádky.
Pojďme se podívat, co se stane, když se pole z obou tabulek přidají do vizuálu tabulky a mezi tabulkami existuje omezená relace.
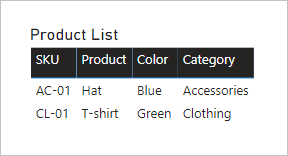
Tabulka zobrazuje pouze dva řádky. Skladová položka produktu CL-02 chybí, protože v tabulce Product Category neexistuje žádný odpovídající řádek.
Související obsah
Další informace týkající se tohoto článku najdete v následujících zdrojích informací:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro