Diese Referenzarchitektur zeigt eine in Azure Service Fabric bereitgestellte Microservices-Architektur. Zu sehen ist eine einfache Clusterkonfiguration, die als Ausgangspunkt für die meisten Bereitstellungen dienen kann.
 Eine Referenzimplementierung dieser Architektur ist auf GitHub verfügbar.
Eine Referenzimplementierung dieser Architektur ist auf GitHub verfügbar.
Aufbau

Laden Sie eine Visio-Datei dieser Architektur herunter.
Hinweis
Der Fokus dieses Artikels liegt auf dem Programmiermodell Reliable Services für Service Fabric. Die Nutzung von Service Fabric zur Bereitstellung und Verwaltung von Containern ist nicht Gegenstand dieses Artikels.
Workflow
Die Architektur umfasst die folgenden Komponenten. Informationen zu anderen Begriffen finden in der Übersicht über die Service Fabric-Terminologie.
Service Fabric-Cluster. Bei einem Cluster handelt es sich um eine Reihe virtueller Computer (VMs), die per Netzwerk verbunden sind und auf denen Sie Ihre Microservices bereitstellen und verwalten.
VM-Skalierungsgruppen. Mit VM-Skalierungsgruppen können Sie eine Gruppe identischer VMs mit Lastenausgleich und automatischer Skalierung erstellen und verwalten. Diese Computeressourcen stellen auch die Fehler- und Upgradedomänen bereit.
Knoten. Die Knoten sind die VMs, die dem Service Fabric-Cluster angehören.
Knotentypen. Ein Knotentyp stellt eine VM-Skalierungsgruppe dar, die eine Sammlung von Knoten bereitstellt. Ein Service Fabric-Cluster hat mindestens einen Knotentyp.
In einem Cluster mit mehreren Knotentypen müssen Sie den primären Knotentyp festlegen. Auf dem primären Knotentyp in Ihrem Cluster werden die Service Fabric-Systemdienste ausgeführt. Diese Dienste stellen die Plattformfunktionen von Service Fabric zur Verfügung. Der primäre Knotentyp fungiert auch als Seedknoten. Dabei handelt es sich um die Knoten, die die Verfügbarkeit des zugrunde liegenden Clusters aufrechterhalten.
Konfigurieren Sie zusätzliche Knotentypen zum Ausführen Ihrer Dienste.
Dienste. Ein Dienst übernimmt eine eigenständige Funktion und kann unabhängig von anderen Diensten gestartet und ausgeführt werden. Instanzen von Diensten werden auf Knoten im Cluster bereitgestellt. Es gibt in Service Fabric zwei Arten von Diensten:
- Zustandsloser Dienst: Ein zustandsloser Dienst behält seinen Zustand innerhalb des Diensts nicht bei. Wenn Zustandspersistenz erforderlich ist, wird der Zustand in einen externen Speicher, wie z.B. Azure Cosmos DB, geschrieben und aus diesem abgerufen.
- Zustandsbehafteter Dienst: Der Dienstzustand wird innerhalb des Diensts selbst gespeichert. Bei den meisten zustandsbehafteten Diensten wird dies über die Funktion Zuverlässige Sammlungen in Service Fabric implementiert.
Service Fabric Explorer. Bei Service Fabric Explorer handelt es sich um ein Open-Source-Tool zum Untersuchen und Verwalten von Service Fabric-Clustern.
Azure Pipelines. Azure Pipelines ist Teil von Azure DevOps Services und dient zum Durchführen von automatisierten Build-, Test- und Bereitstellungsvorgängen. Sie können auch CI/CD-Lösungen (Continuous Integration und Continuous Delivery) von Drittanbietern wie Jenkins verwenden.
Azure Monitor: Azure Monitor erfasst und speichert Metriken und Protokolle. Beispiele hierfür sind Plattformmetriken für die Azure-Dienste in der Lösung und Anwendungstelemetrie. Nutzen Sie diese Daten zum Überwachen der Anwendung, Einrichten von Warnungen und Dashboards und Durchführen von Analysen der Grundursache von Fehlern. Azure Monitor wird in Service Fabric integriert, um Metriken von Controllern, Knoten und Containern sowie Container- und Knotenprotokolle zu erfassen.
Azure Key Vault. Verwenden Sie Key Vault, um alle Anwendungsgeheimnisse zu speichern, die von den Microservices verwendet werden, wie z. B. Verbindungszeichenfolgen.
Azure API Management: In dieser Architektur fungiert API Management als API-Gateway, das Anforderungen von Clients entgegennimmt und an Ihre Dienste weiterleitet.
Überlegungen
Diese Überlegungen bilden die Säulen des Azure Well-Architected Framework, einer Reihe von Leitprinzipien zur Verbesserung der Qualität einer Workload.
Überlegungen zum Entwurf
Diese Referenzarchitektur konzentriert sich auf Architekturen von Microservices. Ein Microservice ist eine kleine unabhängige Codeeinheit mit Versionsangabe. Microservices können über Dienstermittlungsmethoden ermittelt werden und über APIs mit anderen Diensten kommunizieren. Jeder Dienst ist eigenständig und sollte eine einzige Geschäftsfunktion implementieren. Weitere Informationen darüber, wie Sie Ihre Anwendungsdomäne in Microservices aufteilen können, finden Sie unter Verwenden der Domänenanalyse zur Modellierung von Microservices.
Service Fabric bietet eine Infrastruktur für das effiziente Erstellen, Bereitstellen und Aktualisieren von Microservices. Der Dienst bietet auch Optionen für die automatische Skalierung, Zustandsverwaltung und -überwachung sowie für den Neustart von Diensten bei einem Ausfall.
Service Fabric arbeitet mit einem Anwendungsmodell, bei dem eine Anwendung eine Sammlung von Microservices ist. Die Anwendung wird in einer Anwendungsmanifestdatei beschrieben. Diese Datei definiert die Arten von Diensten, die die Anwendung enthält, sowie Verweise auf die unabhängigen Dienstpakete.
Das Anwendungspaket enthält in der Regel auch Parameter, die als Überschreibungen für bestimmte Einstellungen dienen, die von den Diensten verwendet werden. Jedes Dienstpaket enthält eine Manifestdatei, die die physischen Dateien und Ordner beschreibt, die für die Ausführung dieses Diensts erforderlich sind, einschließlich Binärdateien, Konfigurationsdateien und schreibgeschützte Daten. Dienste und Anwendungen können unabhängig voneinander mit Versionsangaben versehen und aktualisiert werden.
Optional kann das Anwendungsmanifest Dienste beschreiben, die automatisch bereitgestellt werden, wenn eine Instanz der Anwendung erstellt wird. Diese werden als Standarddienste bezeichnet. In diesem Fall beschreibt das Anwendungsmanifest auch, wie diese Dienste erstellt werden sollen. Diese Informationen umfassen den Namen des Diensts, die Anzahl der Instanzen, der Sicherheits- oder Isolationsrichtlinie und die Platzierungsbeschränkungen.
Hinweis
Vermeiden Sie die Verwendung von Standarddiensten, wenn Sie die Lebensdauer Ihrer Dienste steuern möchten. Standarddienste werden beim Erstellen der Anwendung erstellt und werden so lange ausgeführt, wie die Anwendung ausgeführt wird.
Weitere Informationen finden Sie unter Sie möchten sich über Service Fabric informieren?.
Anwendung-zu-Dienst-Paketerstellungsmodell
Ein Grundsatz von Microservices ist, dass jeder Dienst unabhängig bereitgestellt werden kann. Wenn Sie in Service Fabric alle Ihre Dienste in einem einzigen Anwendungspaket gruppieren und ein Upgrade für einen Dienst nicht durchgeführt werden kann, erfolgt ein Rollback des gesamten Upgrades der Anwendung. Dieses Rollback verhindert ein Upgrade der anderen Dienste.
Aus diesem Grund empfehlen wir in einer Microservices-Architektur die Verwendung mehrerer Anwendungspakete. Fassen Sie einen oder mehrere eng zusammengehörige Diensttypen zu einem einzigen Anwendungstyp zusammen. Platzieren Sie beispielsweise Diensttypen im gleichen Anwendungstyp, wenn Ihr Team für eine Reihe von Diensten verantwortlich ist, die eines der folgenden Attribute aufweisen:
- Die Dienste haben die gleiche Lebensdauer und müssen gleichzeitig aktualisiert werden.
- Die Dienste haben den gleichen Lebenszyklus.
- Die Dienste nutzen Ressourcen wie Abhängigkeiten oder Konfigurationen gemeinsam.
Service Fabric-Programmiermodelle
Wenn Sie einen Microservice einer Service Fabric-Anwendung hinzufügen, entscheiden Sie, ob er über einen Zustand oder Daten verfügt, die hochverfügbar und zuverlässig zur Verfügung gestellt werden müssen. Falls ja, können Daten extern gespeichert werden oder sind die Daten als Teil des Diensts enthalten? Wählen Sie einen zustandslosen Dienst, wenn Sie keine Daten speichern müssen oder Daten in einem externen Speicher speichern möchten. Ziehen Sie die Auswahl eines zustandsbehafteten Diensts in Betracht, wenn eine der folgenden Aussagen zutrifft:
- Sie möchten den Zustand oder die Daten als Teil des Diensts beibehalten. Diese Daten müssen sich beispielsweise im Arbeitsspeicher in der Nähe des Codes befinden.
- Sie können eine Abhängigkeit von einem externen Speicher nicht tolerieren.
Wenn Sie bereits Code haben, den Sie in Service Fabric ausführen möchten, können Sie ihn als ausführbare Gastdatei ausführen, also eine beliebige ausführbare Datei, die als Dienst ausgeführt wird. Alternativ können Sie die ausführbare Datei in einem Container packen, der alle Abhängigkeiten enthält, die Sie für die Bereitstellung benötigen.
Service Fabric modelliert sowohl Container als auch ausführbare Gastdateien als zustandslose Dienste. Eine Anleitung zur Wahl eines Modells finden Sie unter Übersicht über die Service Fabric-Programmiermodelle.
Sie sind für die Verwaltung der Umgebung verantwortlich, in der eine ausführbare Gastdatei ausgeführt wird. Angenommen, eine ausführbare Gastdatei verlangt Python. Wenn die ausführbare Datei nicht eigenständig ist, müssen Sie sicherstellen, dass die erforderliche Version von Python bereits in der Umgebung installiert ist. Service Fabric verwaltet die Umgebung nicht. Azure bietet mehrere Mechanismen zum Einrichten der Umgebung, einschließlich benutzerdefinierter VM-Images und -Erweiterungen.
Stellen Sie beim Zugreifen auf eine ausführbare Gastdatei über einen Reverseproxy sicher, dass Sie das Attribut UriScheme zum Element Endpoint im Dienstmanifest der ausführbaren Gastdatei hinzugefügt haben.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" UriScheme="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Wenn der Dienst zusätzliche Routen enthält, geben Sie die Routen im Wert PathSuffix an. Dem Wert sollte kein Präfix oder Suffix mit einem Schrägstrich (/) vorangestellt bzw. angehängt werden. Eine weitere Möglichkeit besteht darin, die Route zum Dienstnamen hinzuzufügen.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Weitere Informationen finden Sie unter
- Packen einer Anwendung
- Packen und Bereitstellen einer vorhandenen ausführbaren Datei für Service Fabric
API-Gateway
Ein API-Gateway (eingehend) befindet sich zwischen externen Clients und den Microservices. Es fungiert als Reverseproxy und leitet Anforderungen von Clients an Microservices weiter. Darüber hinaus kann es übergreifende Aufgaben wie Authentifizierung, SSL-Beendigung und Ratenbegrenzung übernehmen.
Azure API Management wird in den meisten Szenarien empfohlen, aber Traefik ist eine beliebte Open-Source-Alternative. Beide Technologieoptionen sind in Service Fabric integriert.
API Management. Macht eine öffentliche IP-Adresse verfügbar und leitet Datenverkehr an Ihre Dienste weiter. Die Lösung wird in einem dedizierten Subnetz im gleichen virtuellen Netzwerk wie der Service Fabric-Cluster ausgeführt.
API Management kann auf Dienste in einem Knotentyp zugreifen, der über einen Lastenausgleich mit einer privaten IP-Adresse verfügbar gemacht wird. Diese Option ist nur in den Tarifen „Premium“ und „Developer“ von API Management verfügbar. Wählen Sie für Produktionsworkloads den Premium-Tarif. Weitere Informationen zu den Preisen finden Sie unter API Management-Preise.
Weitere Informationen finden Sie unter Service Fabric mit Azure API Management-Übersicht.
Traefik. Unterstützt Features wie Routing, Ablaufverfolgung, Protokolle und Metriken. Traefik wird als zustandsloser Dienst im Service Fabric-Cluster ausgeführt. Die Dienstversionsverwaltung kann über Routing unterstützt werden.
Informationen darüber, wie Sie Traefik für eingehende Dienstdaten und als Reverseproxy innerhalb des Clusters einrichten, finden Sie unter Azure Service Fabric-Anbieter auf der Traefik-Website. Weitere Informationen zur Verwendung von Traefik mit Service Fabric finden Sie im Blogbeitrag Intelligent routing on Service Fabric with Traefik (Intelligentes Routing in Service Fabric mit Traefik).
Traefik verfügt im Gegensatz zu Azure API Management nicht über die Funktionalität, die Partition eines zustandsbehafteten Dienstes (mit mehr als einer Partition) aufzulösen, an den eine Anforderung weitergeleitet wird. Weitere Informationen finden Sie unter Hinzufügen eines Matchers für das Partitionieren von Diensten.
Weitere API Management-Optionen sind Azure Application Gateway und Azure Front Door. Sie können diese Dienste in Verbindung mit API Management verwenden, um Aufgaben wie Routing, SSL-Beendigung und Firewall abzudecken.
Kommunikation zwischen Diensten
Um die Dienst-zu-Dienst-Kommunikation zu erleichtern, sollten Sie die folgenden Empfehlungen berücksichtigen:
Kommunikationsprotokoll. In einer Microservices-Architektur müssen Dienste mit minimaler Kopplung zur Laufzeit miteinander kommunizieren. Um eine sprachunabhängige Kommunikation zu ermöglichen, ist HTTP ein Branchenstandard mit einer breiten Palette von Tools und HTTP-Servern, die in verschiedenen Sprachen verfügbar sind. Service Fabric unterstützt alle diese Tools und Server.
Für die meisten Workloads wird empfohlen, HTTP anstelle des in Service Fabric integrierten Dienstremotings zu verwenden.
Dienstermittlung: Um mit anderen Diensten innerhalb eines Clusters zu kommunizieren, muss ein Clientdienst den aktuellen Standort des Zieldiensts auflösen. In Service Fabric können Dienste zwischen Knoten verschoben werden und zu einer dynamischen Änderung der Dienstendpunkte führen.
Um Verbindungen mit veralteten Endpunkten zu vermeiden, können Sie den Namensdienst in Service Fabric verwenden, um aktualisierte Endpunktinformationen abzurufen. Service Fabric bietet jedoch auch einen integrierten Reverseproxydienst, der den Naming Service abstrahiert. Diese Option für die Dienstermittlung wird als Grundlage für die meisten Szenarien empfohlen, da sie einfacher zu verwenden ist und zu einfacherem Code führt.
Es folgen weitere Optionen für die Kommunikation zwischen Diensten:
- Traefik für erweitertes Routing.
- DNS für Kompatibilitätsszenarien, bei denen ein Dienst erwartet, dass DNS verwendet wird.
- Die Klasse ServicePartitionClient<TCommunicationClient>, die Dienstendpunkte zwischenspeichert. Diese kann eine bessere Leistung ermöglichen, da Aufrufe direkt zwischen Diensten ohne Vermittler oder benutzerdefinierte Protokolle erfolgen.
Skalierbarkeit
Service Fabric unterstützt die Skalierung dieser Clusterentitäten:
- Skalieren der Anzahl von Knoten für jeden Knotentyp
- Skalieren von Diensten
Dieser Abschnitt konzentriert sich auf die automatische Skalierung. In bestimmten Situationen können Sie die Skalierung manuell vornehmen. Ein manueller Eingriff kann beispielsweise erforderlich sein, um die Anzahl der Instanzen festzulegen.
Anfängliche Clusterkonfiguration für Skalierbarkeit
Wenn Sie einen Service Fabric-Cluster erstellen, stellen Sie die Knotentypen entsprechend Ihren Sicherheits- und Skalierungsanforderungen bereit. Jeder Knotentyp wird einer VM-Skalierungsgruppe zugeordnet und kann unabhängig skaliert werden.
- Erstellen Sie einen Knotentyp für jede Gruppe von Diensten, die unterschiedliche Skalierungs- oder Ressourcenanforderungen haben. Stellen Sie zunächst einen Knotentyp (der zum primären Knotentyp wird) für die Systemdienste von Service Fabric bereit. Erstellen Sie separate Knotentypen, um Ihre öffentlichen Dienste oder Front-End-Dienste auszuführen. Erstellen Sie nach Bedarf weitere Knotentypen für Ihre Back-End- und private oder isolierte Dienste. Geben Sie Platzierungseinschränkungen an, damit die Dienste nur für die vorgesehenen Knotentypen bereitgestellt werden.
- Geben Sie für jeden Knotentyp die Dauerhaftigkeitsstufe an. Die Dauerhaftigkeitsstufe beschreibt die Möglichkeit von Service Fabric, Updates und Wartungsvorgänge in VM-Skalierungsgruppen zu beeinflussen. Wählen Sie für Produktionsworkloads mindestens die Dauerhaftigkeitsstufe „Silber“ aus. Informationen zu den einzelnen Stufen finden Sie unter Dauerhaftigkeitsmerkmale des Clusters.
- Bei Verwendung der Dauerhaftigkeitsstufe „Bronze“ erfordern bestimmte Vorgänge manuelle Schritte. Knotentypen mit der Dauerhaftigkeitsstufe „Bronze“ erfordern zusätzliche Schritte während der Skalierung. Weitere Informationen zu Skalierungsvorgängen finden Sie in dieser Anleitung.
Skalieren von Knoten
Service Fabric bietet für das horizontale Hoch- und Herunterskalieren eine automatische Skalierung. Sie können jeden Knotentyp unabhängig für die automatische Skalierung konfigurieren.
Jeder Knotentyp kann maximal 100 Knoten enthalten. Beginnen Sie mit einer kleineren Gruppe von Knoten, und fügen Sie abhängig von der Last weitere Knoten hinzu. Wenn Sie mehr als 100 Knoten in einem Knotentyp benötigen, müssen Sie weitere Knotentypen hinzufügen. Einzelheiten finden Sie unter Überlegungen zur Kapazitätsplanung für Service Fabric-Cluster. Eine VM-Skalierungsgruppe wird nicht sofort skaliert, was Sie beim Einrichten von Regeln für die Autoskalierung berücksichtigen sollten.
Konfigurieren Sie für die automatische horizontale Herunterskalierung den Knotentyp mit der Dauerhaftigkeitsstufe „Silber“ oder „Gold“. Diese Konfiguration stellt sicher, dass die Skalierung verzögert wird, bis Service Fabric die Verlagerung von Diensten abgeschlossen hat. Außerdem wird sichergestellt, dass die VM-Skalierungsgruppen Service Fabric darüber informieren, dass die VMs entfernt und nicht nur vorübergehend heruntergefahren werden.
Weitere Informationen zum Skalieren auf Knoten- oder Clusterebene finden Sie unter Skalieren von Azure Service Fabric-Clustern.
Skalieren von Diensten
Zustandslose und zustandsbehaftete Dienste verfolgen bei der Skalierung unterschiedliche Ansätze.
Zustandsloser Dienst (automatische Skalierung):
- Verwenden Sie den Trigger bei durchschnittlicher Partitionslast. Dieser Trigger bestimmt, wann der Dienst horizontal herunter- oder hochskaliert wird, und zwar basierend auf einem in der Skalierungsrichtlinie angegebenen Schwellenwert für die Last. Sie können auch festlegen, wie oft der Trigger überprüft wird. Siehe Trigger für die durchschnittliche Partitionslast mit instanzbasierter Skalierung. Dieser Ansatz ermöglicht ein Hochskalieren auf die Anzahl verfügbarer Knoten.
- Legen Sie im Dienstmanifest
InstanceCountauf -1 fest, was Service Fabric anweist, auf jedem Knoten eine Instanz des Diensts auszuführen. Dieser Ansatz ermöglicht dem Dienst eine dynamische Skalierung entsprechend der Skalierung des Clusters. Wenn sich die Anzahl der Knoten im Cluster ändert, erstellt und löscht Service Fabric automatisch entsprechende Dienstinstanzen.
Hinweis
In einigen Fällen möchten Sie Ihren Dienst möglicherweise manuell skalieren. Wenn Sie beispielsweise einen Dienst haben, der Daten aus Azure Event Hubs liest, möchten Sie möglicherweise, dass eine dedizierte Instanz Daten aus jeder Event Hub-Partition liest. Auf diese Weise können Sie einen gleichzeitigen Zugriff auf die Partition vermeiden.
Bei einem zustandsbehafteten Dienst wird die Skalierung von der Anzahl der Partitionen, der Größe jeder Partition und der Anzahl der Partitionen oder Replikate bestimmt, die auf einer VM ausgeführt werden:
Wenn Sie partitionierte Dienste erstellen, achten Sie darauf, dass jeder Knoten ausreichende Replikate für eine gleichmäßige Verteilung der Workloads erhält, ohne Ressourcenkonflikte zu verursachen. Wenn Sie weitere Knoten hinzufügen, verteilt Service Fabric die Workloads standardmäßig auf die neuen VMs. Wenn es beispielsweise 5 Knoten und 10 Partitionen gibt, platziert Service Fabric standardmäßig auf jedem Knoten zwei primäre Replikate. Wenn Sie die Knoten aufskalieren, können Sie eine höhere Leistung erzielen, da die Verarbeitungsaufgaben gleichmäßig auf mehr Ressourcen verteilt werden.
Weitere Informationen zu Szenarien, die diese Strategie befolgen, finden Sie unter Skalierung in Service Fabric.
Das Hinzufügen oder Entfernen von Partitionen wird nicht sonderlich gut unterstützt. Eine weitere häufig verwendete Option zur Skalierung ist das dynamische Erstellen oder Löschen von Diensten oder ganzen Anwendungsinstanzen. Ein Beispiel dieser Vorgehensweise finden Sie unter Skalieren durch das Erstellen oder Entfernen von neuen benannten Diensten.
Weitere Informationen finden Sie unter
- Horizontales Hoch- oder Herunterskalieren eines Service Fabric-Clusters mithilfe von Regeln für die automatische Skalierung oder eines manuellen Verfahrens
- Programmgesteuertes Skalieren eines Service Fabric-Clusters
- Skalieren eines Service Fabric-Clusters durch Hinzufügen einer VM-Skalierungsgruppe
Verwenden von Metriken für den Lastenausgleich
Je nachdem, wie Sie die Partition entwerfen, kann es Knoten mit Replikaten geben, die mehr Datenverkehr erhalten als andere. Um dies zu vermeiden, partitionieren Sie den Dienstzustand so, dass er auf alle Partitionen verteilt wird. Verwenden Sie das Bereichspartitionierungsschema mit einem geeigneten Hashalgorithmus. Siehe Erste Schritte mit der Partitionierung.
Service Fabric verwendet Metriken, um zu wissen, wie Dienste innerhalb eines Clusters platziert und aufeinander abgestimmt werden sollen. Sie können beim Erstellen dieses Diensts für jede Metrik, die einem Dienst zugeordnet ist, eine Standardlast angeben. Service Fabric berücksichtigt diese Last anschließend bei der Platzierung des Diensts oder immer dann, wenn der Dienst verschoben werden muss (z. B. bei Upgrades), um die Knoten im Cluster in Einklang zu bringen.
Die anfänglich angegebene Standardlast für einen Dienst ändert sich während dessen Lebensdauer nicht. Um sich ändernde Metriken für einen Dienst zu erfassen, wird empfohlen, dass Sie Ihren Dienst überwachen und dann die Last dynamisch melden. Diese Methode ermöglicht Service Fabric, die Zuordnung basierend auf der gemeldeten Last zu einem gegebenen Zeitpunkt anzupassen. Verwenden Sie die IServicePartition.ReportLoad-Methode, um benutzerdefinierte Metriken zu melden. Weitere Informationen finden Sie unter Dynamische Last.
Verfügbarkeit
Platzieren Sie Ihre Dienste auf einem anderen Knotentyp als dem primären Knotentyp. Die Service Fabric-Systemdienste werden stets auf dem primären Knotentyp platziert. Wenn Ihre Dienste auf dem primären Knotentyp bereitgestellt werden, können sie mit Systemdiensten um Ressourcen konkurrieren (und Systemdienste stören). Wenn von einem Knotentyp erwartet wird, dass er zustandsbehaftete Dienste hostet, stellen Sie sicher, dass es mindestens fünf Knoteninstanzen gibt und dass Sie die Dauerhaftigkeitsstufe „Silber“ oder „Gold“ auswählen.
Erwägen Sie das Einschränken der Ressourcen Ihrer Dienste. Siehe Ressourcenkontrollmechanismus.
Hier einige allgemeine Überlegungen:
- Kombinieren Sie keine ressourcengesteuerten Dienste und nicht ressourcengesteuerten Dienste auf demselben Knotentyp. Die nicht gesteuerten Dienste beanspruchen möglicherweise zu viele Ressourcen und beeinträchtigen die gesteuerten Dienste. Geben Sie Platzierungseinschränkungen an, um sicherzustellen, dass diese Arten von Diensten nicht in der gleichen Gruppe von Knoten ausgeführt werden. (Dies ist eine Beispiel des Bulkhead-Musters.)
- Geben Sie die CPU-Kerne und Arbeitsspeichergröße an, die für eine Dienstinstanz reserviert werden. Informationen zur Verwendung und Einschränkungen von Richtlinien zur Ressourcenkontrolle finden Sie unter Ressourcenkontrolle.
Um einen Single Point of Failure (SPOF) zu vermeiden, stellen Sie sicher, dass die Anzahl der Zielinstanzen oder Replikate jedes Diensts größer als 1 ist. Die größtmögliche Anzahl von Dienstinstanzen oder Replikaten ist gleich der Anzahl der Knoten, die den Dienst beschränken.
Stellen Sie sicher, dass alle zustandsbehafteten Dienste mindestens über zwei aktive sekundäre Replikate verfügen. Für Produktionsworkloads werden fünf Replikate empfohlen.
Weitere Informationen finden Sie unter Verfügbarkeit der Service Fabric-Dienste.
Sicherheit
Sicherheit bietet Schutz vor vorsätzlichen Angriffen und dem Missbrauch Ihrer wertvollen Daten und Systeme. Weitere Informationen finden Sie unter Übersicht über die Säule „Sicherheit“.
Nachfolgend sind einige wichtige Punkte zur Absicherung Ihrer Anwendung in Service Fabric aufgeführt.
Virtuelles Netzwerk
Erwägen Sie, Subnetzgrenzen für jede VM-Skalierungsgruppe zu definieren, um den Kommunikationsfluss zu steuern. Jeder Knotentyp hat seine eigene VM-Skalierungsgruppe, die in einem Subnetz innerhalb des virtuellen Netzwerks des Service Fabric-Clusters festgelegt ist. Sie können Netzwerksicherheitsgruppen (NSGs) zu den Subnetzen hinzufügen, um Netzwerkdatenverkehr zuzulassen oder zu verweigern. Beispielsweise können Sie bei Front-End- und Back-End-Knotentypen dem Back-End-Subnetz eine NSG hinzufügen, um eingehenden Datenverkehr nur vom Front-End-Subnetz zu akzeptieren.
Verwenden Sie beim Aufrufen externer Azure-Dienste im Cluster die Dienstendpunkte des virtuellen Netzwerks, sofern der Azure-Dienst dies unterstützt. Durch die Verwendung eines Dienstendpunkts wird der Dienst nur im virtuellen Netzwerk des Clusters abgesichert.
Wenn Sie beispielsweise Azure Cosmos DB zum Speichern von Daten verwenden, konfigurieren Sie das Azure Cosmos DB-Konto mit einem Dienstendpunkt, um nur den Zugriff aus einem bestimmten Subnetz zuzulassen. Siehe Zugreifen auf Azure Cosmos DB-Ressourcen über virtuelle Netzwerke.
Endpunkte und Kommunikation zwischen Diensten
Erstellen Sie keinen ungeschützten Service Fabric-Cluster. Falls der Cluster Verwaltungsendpunkte im öffentlichen Internet verfügbar macht, können anonyme Benutzer eine Verbindung mit ihm herstellen. Nicht geschützte Cluster werden für Produktionsworkloads nicht unterstützt. Weitere Informationen finden Sie unter Szenarien für die Clustersicherheit in Service Fabric.
Möglichkeiten zum Schützen der Kommunikation zwischen Diensten:
- Erwägen Sie in Ihren ASP.NET Core- oder Java-Webdiensten das Aktivieren von HTTPS-Endpunkten.
- Richten Sie eine sichere Verbindung zwischen dem Reverseproxy und Diensten ein. Einzelheiten finden Sie unter Herstellen einer Verbindung mit einem sicheren Dienst.
Wenn Sie ein API-Gateway verwenden, können Sie die Authentifizierung an das Gateway auslagern. Stellen Sie sicher, dass die einzelnen Dienste nicht direkt (ohne das API-Gateway) erreicht werden können, es sei denn, es ist zusätzliche Sicherheit für die Authentifizierung von Nachrichten vorhanden.
Machen Sie den Service Fabric-Reverseproxy nicht öffentlich verfügbar. Dadurch sind alle Dienste, die HTTP-Endpunkte verfügbar machen, von außerhalb des Clusters adressierbar. Dies führt zu Sicherheitsrisiken und macht möglicherweise zusätzliche Informationen außerhalb des Clusters unnötig verfügbar. Wenn Sie auf einen Dienst öffentlich zugreifen möchten, verwenden Sie ein API-Gateway. Im Abschnitt API-Gateway weiter unten in diesem Artikel werden einige Optionen genannt.
Remotedesktop ist für die Diagnose und Problembehandlung nützlich, doch sollten Sie diese Anwendung unbedingt schließen. Wenn sie geöffnet bleibt, entsteht eine Sicherheitslücke.
Geheime Schlüssel und Zertifikate
Speichern Sie geheime Schlüssel, wie z. B. Verbindungszeichenfolgen zur Verbindung mit Datenspeichern, in einem Schlüsseltresor. Der Schlüsseltresor muss sich in derselben Region wie die VM-Skalierungsgruppe befinden. Verwenden Sie einen Schlüsseltresor auf folgende Weise:
Authentifizieren Sie den Zugriff des Diensts auf den Schlüsseltresor.
Aktivieren Sie die verwaltete Identität in der VM-Skalierungsgruppe, die den Dienst hostet.
Speichern Sie Ihre geheimen Schlüssel im Schlüsseltresor.
Fügen Sie geheime Schlüssel in einem Format hinzu, das in ein Schlüssel-Wert-Paar übersetzt werden kann. Verwenden Sie z. B.
CosmosDB--AuthKey. Beim Erstellen der Konfiguration wird der doppelte Bindestrich (--) in einen Doppelpunkt (:) konvertiert.Greifen Sie auf die geheimen Schlüssel in Ihrem Dienst zu.
Fügen Sie die Schlüsseltresor-URI in Ihrer Datei appSettings.json hinzu. Fügen Sie in Ihrem Dienst den Konfigurationsanbieter hinzu, der aus dem Schlüsseltresor liest, die Konfiguration erstellt und auf den geheimen Schlüssel aus der erstellten Konfiguration zugreift.
Hier ist ein Beispiel, bei dem der Workflowdienst einen geheimen Schlüssel im Format CosmosDB--Database im Schlüsseltresor speichert.
namespace Fabrikam.Workflow.Service
{
public class ServiceStartup
{
public static void ConfigureServices(StatelessServiceContext context, IServiceCollection services)
{
var preConfig = new ConfigurationBuilder()
…
.AddJsonFile(context, "appsettings.json");
var config = preConfig.Build();
if (config["AzureKeyVault:KeyVaultUri"] is var keyVaultUri && !string.IsNullOrWhiteSpace(keyVaultUri))
{
preConfig.AddAzureKeyVault(keyVaultUri);
config = preConfig.Build();
}
}
}
Um auf den geheimen Schlüssel zuzugreifen, geben Sie dessen Name in der erstellten Konfiguration an.
if(builtConfig["CosmosDB:Database"] is var database && !string.IsNullOrEmpty(database))
{
// Use the secret.
}
Verwenden Sie keine Clientzertifikate für den Zugriff auf Service Fabric Explorer. Verwenden Sie Microsoft Entra ID. Weitere Informationen finden Sie unter Azure-Dienste, die die Microsoft Entra-Authentifizierung unterstützen.
Verwenden Sie keine selbstsignierten Zertifikate in der Produktion.
Schutz ruhender Daten
Wenn Sie an die VM-Skalierungsgruppen im Service Fabric-Cluster Datenträger angefügt haben und Ihre Dienste Daten auf diesen Datenträgern speichern, müssen Sie die Datenträger verschlüsseln. Weitere Informationen finden Sie unter Verschlüsseln von Betriebssystem- und angefügten Datenträgern in einer VM-Skalierungsgruppe mit Azure PowerShell (Vorschauversion).
Weitere Informationen zum Absichern von Service Fabric finden Sie unter:
- Übersicht über die Azure Service Fabric-Sicherheit
- Bewährte Methoden für die Azure Service Fabric-Sicherheit
- Checkliste für die Azure Service Fabric-Sicherheit
Resilienz
Um Ausfälle zu beheben und einen voll funktionsfähigen Zustand aufrechtzuerhalten, muss die Anwendung bestimmte Resilienzmuster implementieren. Hier sind einige gängige Muster:
- Wiederholung: Um Fehler zu behandeln, die voraussichtlich nur vorübergehend sind, wie z. B. Ressourcen, die vorübergehend nicht verfügbar sind.
- Trennschalter: Um Fehler zu behandeln, deren Behebung möglicherweise länger dauert.
- Bulkhead: Zum Isolieren von Ressourcen für jeden Dienst.
Für diese Referenzimplementierung wird Polly verwendet. Dies ist eine Open-Source-Option, mit der alle diese Muster implementiert werden können.
Überwachung
Bevor Sie sich mit den Überwachungsoptionen befassen, wird empfohlen, den Artikel Diagnostizieren häufiger Szenarien mit Service Fabric zu lesen. Sie können sich Überwachungsdaten in diesen Kategorien vorstellen:
- Anwendungsmetriken und -protokolle
- Service Fabric-Integritäts- und Ereignisdaten
- Infrastrukturmetriken und -protokolle
- Metriken und Protokolle für abhängige Dienste
Es gibt zwei Hauptoptionen für die Analyse von Daten:
- Application Insights
- Log Analytics
Mit Azure Monitor können Sie Dashboards für die Überwachung einrichten und Warnmeldungen an Bediener senden. Einige Überwachungstools von Drittanbietern sind ebenfalls in Service Fabric integriert, z. B. Dynatrace. Einzelheiten finden Sie unter Partnerlösungen für die Überwachung von Azure Service Fabric.
Anwendungsmetriken und -protokolle
Die Anwendungstelemetrie liefert Daten, die Ihnen helfen können, die Integrität Ihres Diensts zu überwachen und Probleme zu erkennen. So fügen Sie Ihrem Dienst Ablaufverfolgungen und Ereignisse hinzu
- Verwenden Sie Microsoft.Extensions.Logging, wenn Sie Ihren Dienst mit ASP.NET Core entwickeln. Verwenden Sie für andere Frameworks eine Protokollierungsbibliothek Ihrer Wahl, z. B. Serilog.
- Fügen Sie Ihre eigene Instrumentierung hinzu, indem Sie die TelemetryClient-Klasse im SDK verwenden und die Daten in Application Insights anzeigen. Siehe Hinzufügen einer benutzerdefinierten Instrumentierung zu Ihrer Anwendung.
- Protokollieren Sie ETW-Ereignisse (Event Tracing for Windows, Ereignisablaufverfolgung für Windows) mithilfe von EventSource. Diese Option ist standardmäßig in einer Visual Studio Service Fabric-Lösung verfügbar.
Application Insights bietet zahlreiche integrierte Telemetriedaten: Anforderungen, Ablaufverfolgungen, Ereignisse, Ausnahmen, Metriken, Abhängigkeiten. Wenn Ihr Dienst HTTP-Endpunkte verfügbar macht, aktivieren Sie Application Insights, indem Sie die Erweiterungsmethode UseApplicationInsights für Microsoft.AspNetCore.Hosting.IWebHostBuilder aufrufen. Weitere Informationen zum Instrumentieren Ihres Diensts für Application Insights finden Sie in diesen Artikeln:
- Tutorial: Überwachen und Diagnostizieren einer ASP.NET Core-Anwendung in Service Fabric mithilfe von Application Insights
- Application Insights für ASP.NET Core
- Application Insights .NET SDK
- Application Insights SDK für Service Fabric
Verwenden Sie zum Anzeigen der Ablaufverfolgungs- und Ereignisprotokolle Application Insights als eine der Senken für die strukturierte Protokollierung. Konfigurieren Sie Application Insights mit Ihrem Instrumentierungsschlüssel, indem Sie die Erweiterungsmethode AddApplicationInsights aufrufen. In diesem Beispiel wird der Instrumentierungsschlüssel als geheimer Schlüssel im Schlüsseltresor gespeichert.
.ConfigureLogging((hostingContext, logging) =>
{
logging.AddApplicationInsights(hostingContext.Configuration ["ApplicationInsights:InstrumentationKey"]);
})
Wenn Ihr Dienst keine HTTP-Endpunkte verfügbar macht, müssen Sie eine benutzerdefinierte Erweiterung schreiben, die Ablaufverfolgungen an Application Insights sendet. Ein Beispiel finden Sie im Workflowdienst in der Referenzimplementierung.
ASP.NET Core-Dienste verwenden für die Anwendungsprotokollierung die ILogger-Schnittstelle. Um diese Anwendungsprotokolle in Azure Monitor verfügbar zu machen, übertragen Sie die ILogger-Ereignisse an Application Insights. Application Insights kann Korrelationseigenschaften zu ILogger-Ereignissen hinzufügen, was für die Visualisierung der verteilten Ablaufverfolgung nützlich ist.
Weitere Informationen finden Sie unter
Service Fabric-Integritäts- und Ereignisdaten
Service Fabric-Telemetrie enthält Integritätsmetriken und Ereignisse im Zusammenhang mit Betrieb und Leistung des Service Fabric-Clusters und seiner Entitäten: Knoten, Anwendungen, Dienste, Partitionen und Replikate. Integritäts- und Ereignisdaten können aus folgendem Quellen stammen:
EventStore. Dieser zustandsbehaftete Systemdienst erfasst Ereignisse im Zusammenhang mit dem Cluster und seinen Entitäten. Service Fabric verwendet EventStore, um Service Fabric-Ereignisse zu schreiben und Informationen über Ihren Cluster für Statusaktualisierungen, Problembehandlung und Überwachung bereitzustellen. EventStore kann auch Ereignisse aus verschiedenen Entitäten zu einem bestimmten Zeitpunkt korrelieren, um Probleme im Cluster zu erkennen. Der Dienst macht diese Ereignisse über eine REST-API verfügbar.
Informationen zum Abfragen der EventStore-APIs finden Sie unter Abfragen von EventStore-APIs nach Clusterereignissen. Sie können die Ereignisse aus EventStore in Log Analytics anzeigen, indem Sie Ihren Cluster mit der Azure-Diagnoseerweiterung für Windows (WAD) konfigurieren.
HealthStore. Dieser zustandsbehaftete Dienst bietet eine Momentaufnahme der aktuellen Integrität des Clusters. Er aggregiert alle von Entitäten gemeldeten Integritätsdaten in einer Hierarchie. Die Daten werden im Service Fabric Explorer visualisiert. HealthStore überwacht außerdem Anwendungsupgrades. Sie können Integritätsabfragen in PowerShell, einer .NET-Anwendung oder REST-APIs ausführen. Weitere Informationen finden Sie unter Einführung in die Service Fabric-Integritätsüberwachung.
Benutzerdefinierte Integritätsberichte. Ziehen Sie die Implementierung interner Watchdog-Dienste in Betracht, die in regelmäßigen Abständen benutzerdefinierte Integritätsdaten melden können, z. B. fehlerhafte Status ausgeführter Dienste. Sie können die Integritätsberichte in Service Fabric Explorer lesen.
Infrastrukturmetriken und -protokolle
Infrastrukturmetriken fördern das Verständnis der Ressourcenzuteilung im Cluster. Es folgen die wichtigsten Optionen zum Sammeln dieser Informationen:
- WAD. Dient zum Sammeln von Protokollen und Metriken auf Knotenebene unter Windows. Sie können WAD verwenden, indem Sie die VM-Erweiterung „IaaSDiagnostics“ für jede VM-Skalierungsgruppe konfigurieren, die einem Knotentyp zugeordnet ist, um Diagnoseereignisse zu sammeln. Diese Ereignisse können Windows-Ereignisprotokolle, Leistungsindikatoren, System- und Betriebsereignisse für ETW/Manifeste sowie benutzerdefinierte Protokolle umfassen.
- Log Analytics-Agent: Konfigurieren Sie die VM-Erweiterung „MicrosoftMonitoringAgent“, um Windows-Ereignisprotokolle, Leistungsindikatoren und benutzerdefinierte Protokolle an Log Analytics zu senden.
Es gibt einige Überlappungen bei der Art der Metriken, die von den vorhergehenden Mechanismen gesammelt wurden, wie beispielsweise Leistungsindikatoren. Wenn eine Überlappung vorliegt, wird der Log Analytics-Agent empfohlen. Da der Log Analytics-Agent keinen Azure-Speicher verwendet, ist die Latenz gering. Außerdem lassen sich die Leistungsindikatoren in „IaaSDiagnostics“ nicht einfach in Log Analytics einlesen.
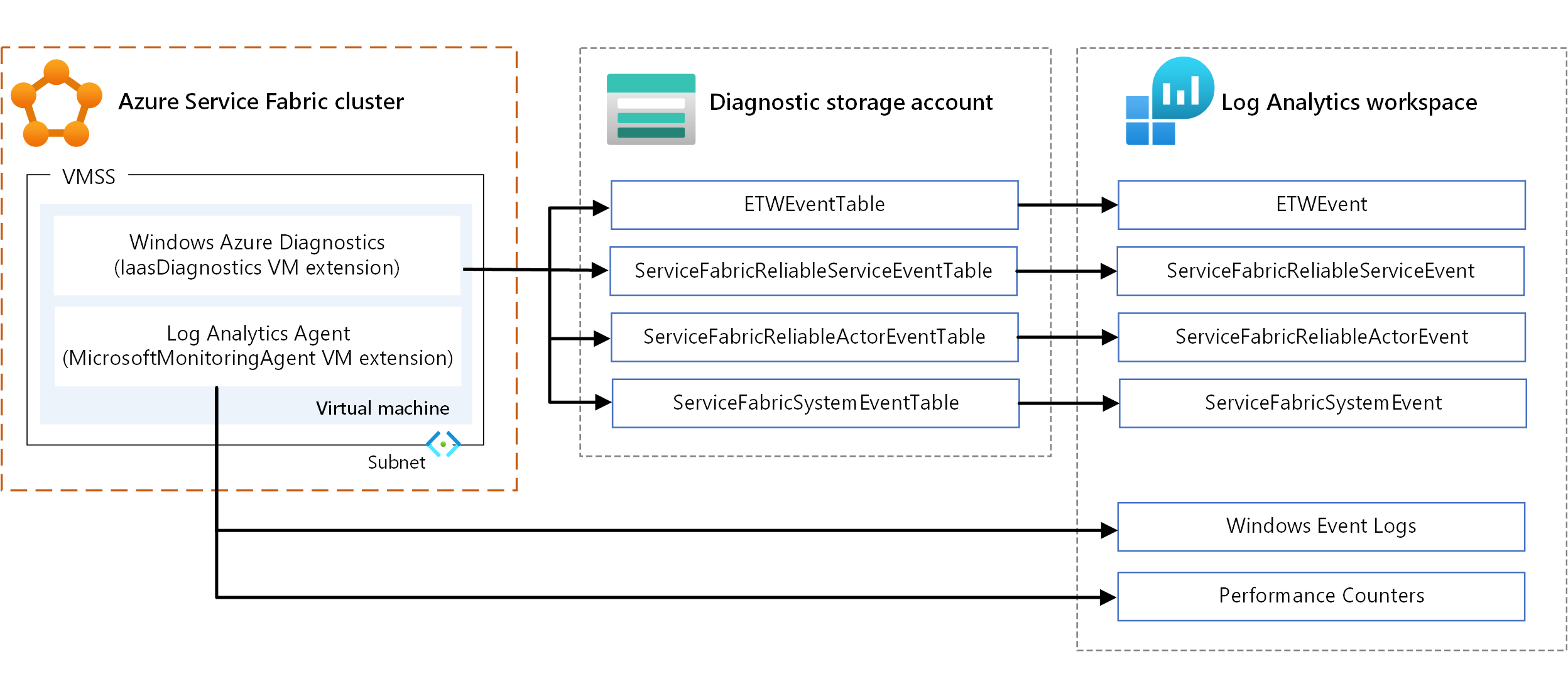
Informationen zu VM-Erweiterungen finden Sie unter Erweiterungen und Features für virtuelle Azure-Computer.
Um die Daten anzuzeigen, konfigurieren Sie Log Analytics so, dass die über WAD erfassten Daten angezeigt werden. Informationen zum Konfigurieren von Log Analytics zum Lesen von Ereignissen aus einem Speicherkonto finden Sie unter Einrichten von Log Analytics für einen Cluster.
Sie können auch Leistungsprotokolle und Telemetriedaten im Zusammenhang mit einem Service Fabric-Cluster, Workloads, Netzwerkdatenverkehr, anstehenden Updates und mehr anzeigen. Weitere Informationen finden Sie unter Leistungsüberwachung mit Log Analytics.
Die Dienstzuordnungslösung in Log Analytics bietet Informationen zur Topologie des Clusters (d. h. den Prozessen, die auf den einzelnen Knoten ausgeführt werden). Übertragen Sie die Daten im Speicherkonto an Application Insights. Es gibt möglicherweise eine Verzögerung beim Abrufen von Daten in Application Insights. Wenn Sie die Daten in Echtzeit sehen möchten, sollten Sie Event Hubs mit Senken und Kanälen konfigurieren. Weitere Informationen finden Sie unter Ereignisaggregation und -sammlung mit der Windows Azure-Diagnose.
Metriken abhängiger Dienste.
- Die Anwendungsübersicht in Application Insights zeigt die Topologie der Anwendung unter Verwendung von HTTP-Abhängigkeitsaufrufen zwischen Diensten mit dem installierten Application Insights SDK.
- Die Dienstzuordnung in Log Analytics bietet Informationen zum ein- und ausgehenden Datenverkehr von und zu externen Diensten. Die Dienstzuordnung kann in andere Lösungen wie Updates oder Sicherheit integriert werden.
- Benutzerdefinierte Watchdogs können Fehlerbedingungen in externen Diensten melden. Der Dienst kann beispielsweise einen Bericht zu Integritätsfehlern bereitstellen, wenn er nicht auf einen externen Dienst oder Datenspeicher (Azure Cosmos DB) zugreifen kann.
Verteilte Ablaufverfolgung
In einer Microservices-Architektur sind oft mehrere Dienste an der Erledigung einer Aufgabe beteiligt. Die Telemetriedaten von jedem dieser Dienste werden über Kontextfelder (z. B. Vorgangs-ID und Anforderungs-ID) in einer verteilten Ablaufverfolgung korreliert.
Mithilfe der Anwendungszuordnung in Application Insights können Sie die Ansicht verteilter logischer Vorgänge erstellen und den gesamten Dienstgraphen Ihrer Anwendung visualisieren. Sie können auch die Transaktionsdiagnose in Application Insights verwenden, um serverseitige Telemetrie zu korrelieren. Weitere Informationen finden Sie unter Einheitliche komponentenübergreifende Transaktionsdiagnose.
Es ist auch wichtig, Aufgaben zu korrelieren, die asynchron mithilfe einer Warteschlange verteilt werden. Weitere Informationen zum Senden korrelierter Telemetriedaten in eine Warteschlange finden Sie unter Warteschlangeninstrumentierung.
Weitere Informationen finden Sie unter
- Durchführen einer mehrere Ressourcen übergreifenden Abfrage
- Telemetriekorrelation in Application Insights
Warnungen und Dashboards
Application Insights und Log Analytics unterstützen mit Kusto eine umfassende Abfragesprache, mit der Sie Protokolldaten abrufen und analysieren können. Verwenden Sie die Abfragen, um Datasets zu erstellen und in Diagnosedashboards zu visualisieren.
Verwenden Sie Azure Monitor-Warnungen, um Systemadministratoren zu benachrichtigen, wenn spezifische Bedingungen in bestimmten Ressourcen auftreten. Die Benachrichtigung kann z. B. eine E-Mail, eine Azure-Funktion oder ein Webhook sein. Weitere Informationen finden Sie unter Warnungen in Azure Monitor.
Warnungsregeln für die Protokollsuche ermöglichen Ihnen das Definieren und regelmäßige Anwenden einer Kusto-Abfrage auf einen Log Analytics-Arbeitsbereich. Eine Warnung wird erstellt, wenn das Ergebnis der Abfrage mit einer bestimmten Bedingung übereinstimmt.
Kostenoptimierung
Verwenden Sie den Azure-Preisrechner, um die voraussichtlichen Kosten zu ermitteln. Weitere Überlegungen finden Sie unter der Säule „Kostenoptimierung“ des Microsoft Azure Well-Architected Framework.
Im Anschluss finden Sie einige Aspekte, die im Zusammenhang mit einigen der in dieser Architektur verwendeten Dienste berücksichtigt werden müssen.
Azure Service Fabric
Ihnen werden die Compute-Instanzen, Speicher- und Netzwerkressourcen sowie IP-Adressen in Rechnung gestellt, die Sie beim Erstellen eines Service Fabric-Clusters auswählen. Bei Service Fabric fallen Gebühren für die Bereitstellung an.
VM-Skalierungsgruppen
In dieser Architektur werden Microservices in Knoten bereitgestellt, bei denen es sich um VM-Skalierungsgruppen handelt. Ihnen werden die Azure-VMs in Rechnung gestellt, die als Teil des Clusters und der zugrundeliegenden Infrastrukturressourcen bereitgestellt werden, wie etwa Speicher und Netzwerk. Für die VM-Skalierungsgruppen selbst fallen keine zusätzlichen Gebühren an.
Azure API Management
Azure API Management ist ein Gateway, das Clientanforderungen an Ihre Dienste im Cluster weiterleitet.
Es gibt verschiedene Preisoptionen. Die Option für den Verbrauch wird auf Grundlage der nutzungsbasierten Bezahlung abgerechnet und umfasst eine Gatewaykomponente. Wählen Sie basierend auf der Workload eine Option aus, die unter API Management – Preise beschrieben ist.
Application Insights
Sie können Application Insights zum Sammeln von Telemetriedaten für alle Dienste und zum strukturierten Anzeigen von Ablaufverfolgungen und Ereignisprotokollen verwenden. Die Preise für Application Insights richten sich nach einem Modell mit nutzungsbasierter Bezahlung, das auf dem verbrauchten Datenvolumen und Optionen für die Datenaufbewahrung basiert. Weitere Informationen finden Sie unter Verwalten der Nutzung und der Kosten für Application Insights.
Azure Monitor
Bei Nutzung von Azure Monitor Log Analytics werden Datenerfassung und -aufbewahrung in Rechnung gestellt. Weitere Informationen finden Sie unter Azure Monitor-Preise.
Azure-Schlüsseltresor
Sie verwenden Azure Key Vault, um den Instrumentierungsschlüssel für Application Insights als Geheimnis zu speichern. Azure bietet Key Vault in zwei Dienstebenen. Wenn Sie keine HSM-geschützten Schlüssel benötigen, wählen Sie die Standardebene aus. Informationen zu den Funktionen in den einzelnen Ebenen finden Sie unter Key Vault – Preise.
Azure DevOps Services
Diese Referenzarchitektur verwendet Azure Pipelines für die Bereitstellung. Der Azure Pipelines-Dienst stellt einen kostenlosen, von Microsoft gehosteten Auftrag mit monatlich 1.800 Minuten für CI/CD sowie einen selbstgehosteten Auftrag ohne monatliche Minutenbegrenzung zur Verfügung. Für weitere Aufträge fallen Gebühren an. Weitere Informationen finden Sie unter Azure DevOps – Preisübersicht.
Informationen zu DevOps-Aspekten in einer Microservices-Architektur finden Sie unter CI/CD für Microservices.
Informationen zum Bereitstellen einer Containeranwendung mit CI/CD in einem Service Fabric-Cluster finden Sie in diesem Tutorial.
Bereitstellen dieses Szenarios
Führen Sie die Schritte im GitHub-Repository aus, um die Referenzimplementierung für diese Architektur bereitzustellen.
Nächste Schritte
- Training: Einführung in Azure Service Fabric
- Übersicht über Azure Service Fabric
- Dokumentation zu API Management
- Was ist Azure Pipelines?