Kopieren von Daten in Azure Data Explorer mithilfe von Azure Data Factory
Wichtig
Dieser Connector kann in Echtzeitanalyse in Microsoft Fabric verwendet werden. Verwenden Sie die Anweisungen in diesem Artikel mit den folgenden Ausnahmen:
- Erstellen Sie bei Bedarf Datenbanken mithilfe der Anweisungen unter Erstellen einer KQL-Datenbank.
- Erstellen Sie bei Bedarf Tabellen mithilfe der Anweisungen unter Erstellen einer leeren Tabelle.
- Rufen Sie Abfrage- oder Erfassungs-URIs mithilfe der Anweisungen unter Kopieren des URI ab.
- Führen Sie Abfragen in einem KQL-Abfrageset aus.
Azure Data Explorer ist ein schneller, vollständig verwalteter Datenanalysedienst. Er bietet Echtzeitanalysen großer Datenmengen, die aus vielfältigen Quellen wie Anwendungen, Websites und IoT-Geräten gestreamt werden. Mit Azure Data Explorer können Sie Daten interaktiv erkunden und Muster und Anomalien ermitteln, um Produkte zu verbessern, die Benutzerfreundlichkeit zu optimieren, Geräte zu überwachen und Vorgänge zu beschleunigen. Sie können neue Fragen überprüfen und Antworten in wenigen Minuten erhalten.
Azure Data Factory ist ein vollständig verwalteter und cloudbasierter Datenintegrationsdienst. Mit diesem Dienst können Sie Ihre Azure Data Explorer-Datenbank mit Daten aus Ihrem vorhandenen System füllen. Dadurch können Sie beim Erstellen von Analyselösungen Zeit sparen.
Wenn Sie Daten in Azure Data Explorer laden, bietet Data Factory die folgenden Vorteile:
- Mühelose Einrichtung: Intuitiver Assistent mit fünf Schritten. Keine Skripterstellung erforderlich.
- Unterstützung für umfangreiche Datenspeicher: Integrierte Unterstützung für umfangreiche lokale und cloudbasierte Datenspeicher. Eine ausführliche Liste finden Sie in der Tabelle Unterstützte Datenspeicher.
- Sicher und kompatibel: Daten werden über HTTPS oder Azure ExpressRoute übertragen. Globale Dienste stellen sicher, dass Ihre Daten nie die geografische Grenze verlassen.
- Hohe Leistung: Datenladegeschwindigkeit von bis zu 1 Gigabyte pro Sekunde (GBit/s) in Azure Data Explorer. Weitere Informationen finden Sie unter Leistung der Kopieraktivität.
In diesem Artikel verwenden Sie das Data Factory-Tool „Daten kopieren“, um von Daten aus Amazon Simple Storage Service (S3) in Azure Data Explorer zu laden. Ähnliche Schritte können Sie zum Kopieren von Daten aus anderen Datenspeichern ausführen, z. B.:
Voraussetzungen
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto.
- Ein Azure Data Explorer-Cluster und eine Datenbank Erstellen eines Clusters und einer Datenbank
- Eine Datenquelle
Erstellen einer Data Factory
Melden Sie sich beim Azure-Portal an.
Wählen Sie im linken Bereich die Optionen Ressource erstellen>Analysen>Data Factory aus.

Geben Sie im Bereich Neue Data Factory die Werte für die Felder in der folgenden Tabelle an:

Einstellung Einzugebender Wert Name Geben Sie in diesem Feld einen global eindeutigen Namen für die Data Factory ein. Wenn die Fehlermeldung Die Data Factory mit dem Namen „LoadADXDemo“ ist nicht verfügbar angezeigt wird, geben Sie einen anderen Namen für die Data Factory ein. Regeln zum Benennen von Data Factory-Artefakten finden Sie unter Azure Data Factory – Benennungsregeln. Abonnement Wählen Sie in der Dropdownliste das Azure-Abonnement aus, in dem die Data Factory erstellt werden soll. Ressourcengruppe Wählen Sie Neu erstellen aus, und geben Sie dann den Namen einer neuen Ressourcengruppe ein. Wenn Sie bereits über eine Ressourcengruppe verfügen, wählen Sie Vorhandene verwenden aus. Version Wählen Sie in der Dropdownliste die Option V2 aus. Location Wählen Sie in der Dropdownliste den Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Die in der Data Factory verwendeten Datenspeicher können an anderen Standorten oder in anderen Regionen vorhanden sein. Klicken Sie auf Erstellen.
Wählen Sie auf der Symbolleiste die Option Benachrichtigungen aus, um den Erstellungsvorgang zu überwachen. Nachdem Sie die Data Factory erstellt haben, wählen Sie sie aus.
Der Bereich Data Factory wird geöffnet.
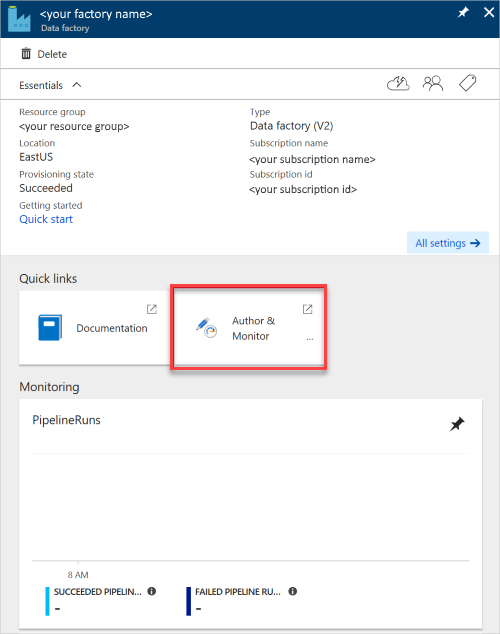
Wählen Sie die Kachel Erstellen und überwachen aus, um die Anwendung in einem separaten Bereich zu öffnen.
Laden von Daten in Azure Data Explorer
Sie können Daten aus verschiedenen Typen von Datenspeichern in Azure Data Explorer laden. In diesem Artikel wird erläutert, wie Daten aus Amazon S3 geladen werden.
Sie können die Daten mit einer der folgenden Methoden laden:
- Wählen Sie auf der Azure Data Factory-Benutzeroberfläche im linken Bereich das Symbol Autor aus. Dies wird im Abschnitt „Erstellen einer Data Factory“ des Artikels zum Erstellen einer Data Factory über die Azure Data Factory-Benutzeroberfläche gezeigt.
- Im Azure Data Factory-Tool „Daten kopieren“, wie unter Kopieren von Daten mithilfe des Tools zum Kopieren von Daten erläutert.
Kopieren von Daten aus Amazon S3 (Quelle)
Öffnen Sie im Bereich Erste Schritte das Tool zum Kopieren von Daten durch Auswählen von Daten kopieren.
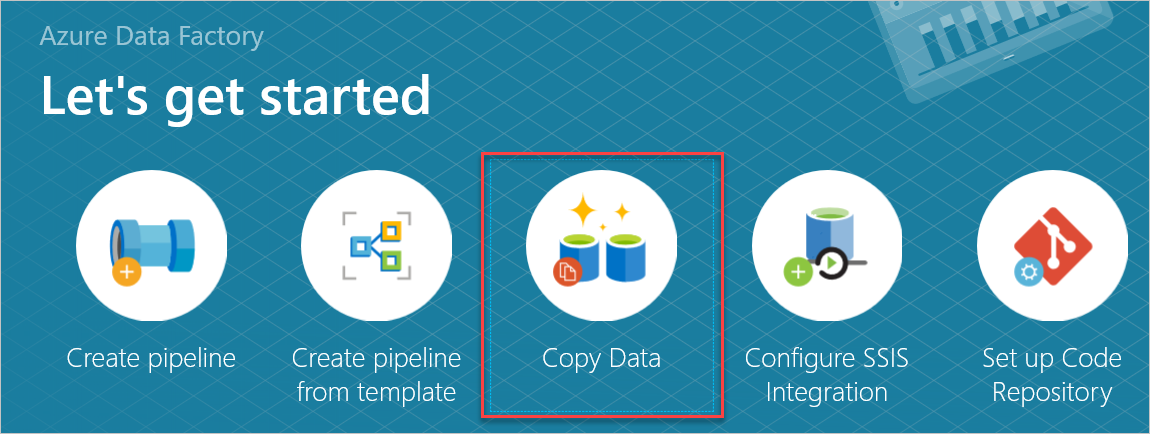
Geben Sie im Bereich Eigenschaften im Feld Aufgabenname einen Namen ein, und wählen Sie dann Weiter aus.
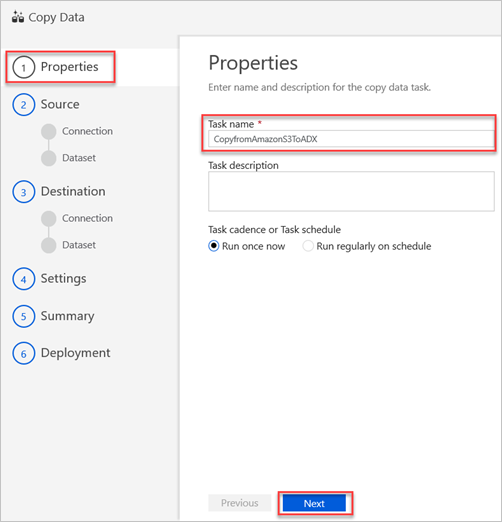
Wählen Sie im Bereich Quelldatenspeicher die Option Neue Verbindung erstellen aus.
Wählen Sie Amazon S3 und anschließend Weiter aus.
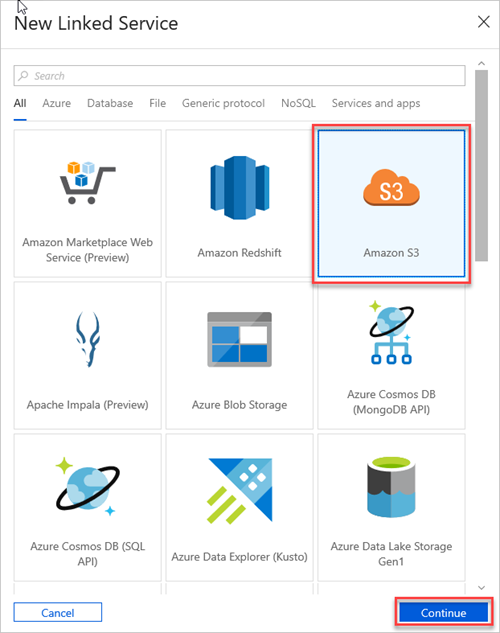
Gehen Sie im Bereich Neuer verknüpfter Dienst (Amazon S3) wie folgt vor:
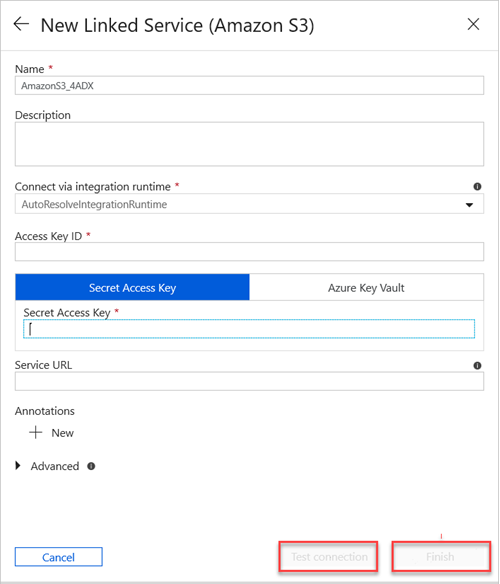
a. Geben Sie im Feld Name den Namen des neuen verknüpften Diensts ein.
b. Wählen Sie in der Dropdownliste Connect via integration runtime (Verbindung per Integration Runtime herstellen) den entsprechenden Wert aus.
c. Geben Sie im Feld Zugriffsschlüssel-ID den entsprechenden Wert ein.
Hinweis
Wählen Sie in Amazon S3 zum Suchen Ihres Zugriffsschlüssels Ihren Amazon-Benutzernamen auf der Navigationsleiste aus, und navigieren Sie dann zu My Security Credentials (Meine Sicherheitsanmeldeinformationen).
d. Geben Sie im Feld Secret Access Key (Geheimer Zugriffsschlüssel) einen Wert ein.
e. Wählen Sie Verbindung testen aus, um die erstellte Verbindung mit dem verknüpften Dienst zu testen.
f. Wählen Sie Fertig stellen aus.
Im Bereich Quelldatenspeicher wird die neue Verbindung „AmazonS31“ angezeigt.
Wählen Sie Weiter aus.

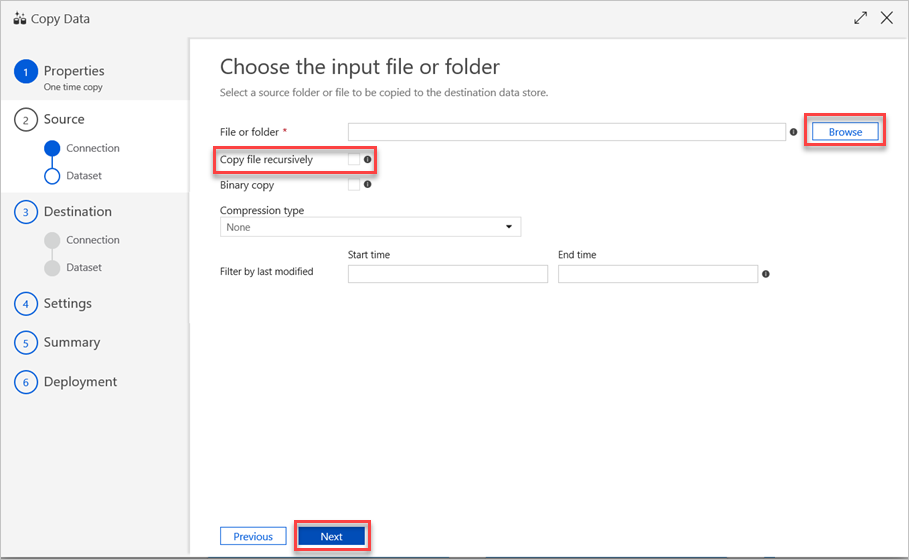
Führen Sie im Bereich Eingabedatei oder -ordner auswählen die folgenden Schritte aus:
a. Navigieren Sie zu der Datei oder dem Ordner, die bzw. den Sie kopieren möchten, und wählen Sie sie bzw. ihn aus.
b. Wählen Sie das gewünschte Kopierverhalten aus. Stellen Sie sicher, dass das Kontrollkästchen Binary Copy (Binärkopie) deaktiviert ist.
c. Klicken Sie auf Weiter.
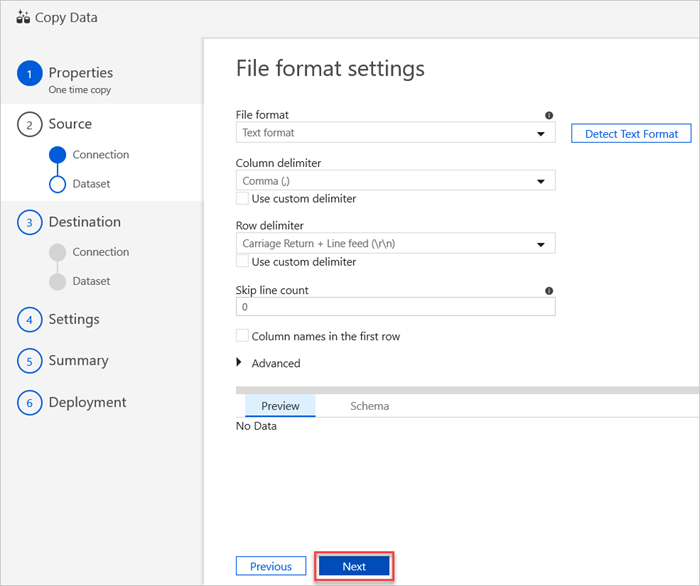
Wählen Sie im Bereich File format settings (Einstellungen für Dateiformate) die relevanten Einstellungen für die Datei aus, und wählen Sie dann Weiter aus.
Kopieren von Daten in Azure Data Explorer (Ziel)
Der neue verknüpfte Azure Data Explorer-Dienst wird erstellt, um die Daten in die in diesem Abschnitt angegebene Azure Data Explorer-Zieltabelle (Senke) zu kopieren.
Hinweis
Verwenden Sie die Azure Data Factory-Befehlsaktivität, um Azure Data Explorer-Verwaltungsbefehle auszuführen und einen der Erfassungsbefehle aus Abfragebefehlen wie zu .set-or-replaceverwenden.
Erstellen des verknüpften Azure Data Explorer-Diensts
Führen Sie zum Erstellen des verknüpften Azure Data Explorer-Diensts die folgenden Schritte aus:
Zum Verwenden einer vorhandenen Datenspeicherverbindung oder Angeben eines neuen Datenspeichers wählen Sie im Bereich Zieldatenspeicher die Option Neue Verbindung erstellen aus.
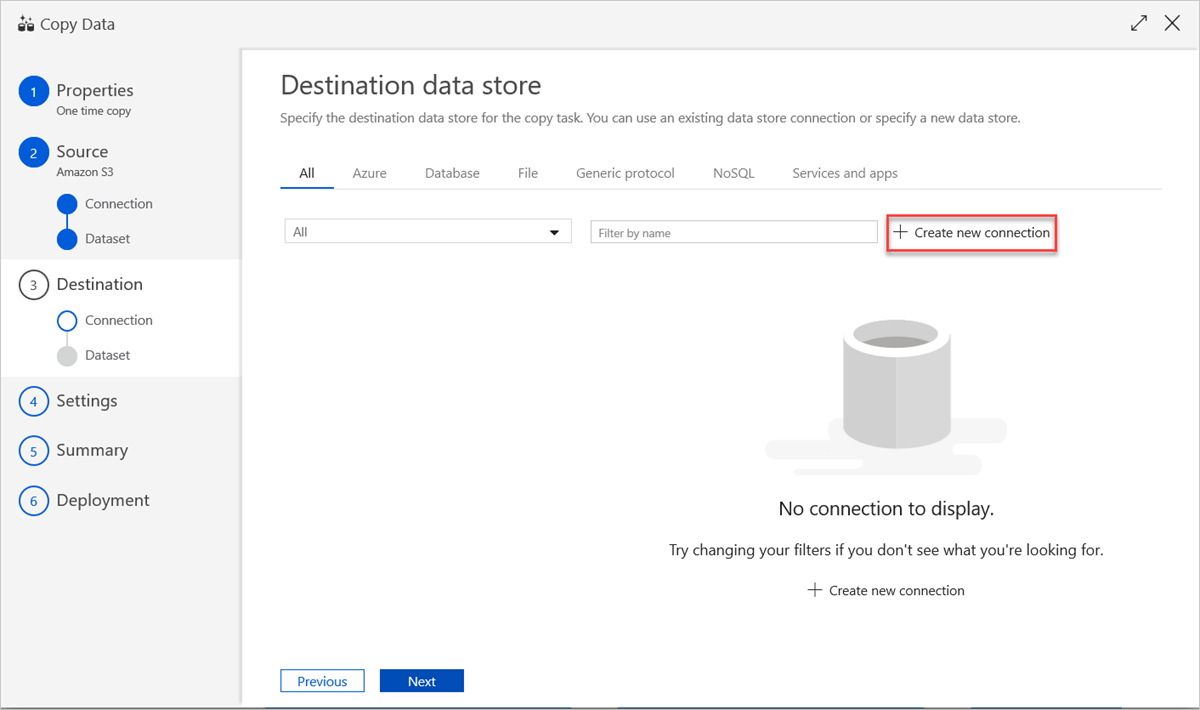
Wählen Sie im Bereich Neuer verknüpfter Dienst die Option Azure Data Explorer und dann Weiter aus.

Führen Sie im Bereich Neuer verknüpfter Dienst (Azure Data Explorer) die folgenden Schritte aus:
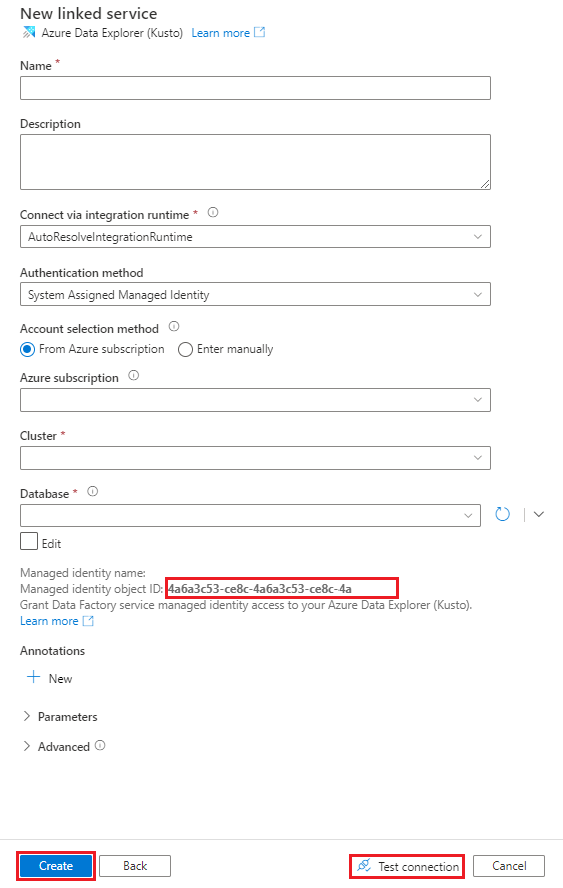
Geben Sie im Feld Name einen Namen für den verknüpften Azure Data Explorer-Dienst ein.
Wählen Sie unter Authentifizierungsmethode die Option Systemseitig zugewiesene verwaltete Identität oder Dienstprinzipal.
Um sich mit einer verwalteten Identität zu authentifizieren, gewähren Sie dieser mithilfe der Option Name der verwalteten Identität oder Objekt-ID der verwalteten Identität Zugriff auf die Datenbank.
So erfolgt die Authentifizierung mit einem Dienstprinzipal
- Geben Sie im Feld Mandant den Namen des Mandanten ein.
- Geben Sie im Feld Dienstprinzipal-ID die Dienstprinzipal-ID ein.
- Wählen Sie Dienstprinzipalschlüssel aus, und geben Sie dann im Feld Dienstprinzipalschlüssel den Wert für den Schlüssel ein.
Hinweis
- Der Dienstprinzipal wird von Azure Data Factory für den Zugriff auf den Azure Data Explorer-Dienst verwendet. Um einen Dienstprinzipal zu erstellen, wechseln Sie zum Erstellen eines Microsoft Entra Dienstprinzipals.
- Informationen zum Zuweisen von Berechtigungen zu einer verwalteten Identität oder einem Dienstprinzipal finden Sie unter Verwalten von Berechtigungen.
- Verwenden Sie nicht die Azure Key Vault-Methode oder benutzerseitig zugewiesene verwaltete Identität.
Wählen Sie unter Kontoauswahlmethode eine der folgenden Optionen aus:
Wählen Sie From Azure subscription (Aus Azure-Abonnement) und dann in den jeweiligen Dropdownlisten Ihr Azure-Abonnement und Ihren Cluster aus.
Hinweis
- In der Dropdownliste Cluster sind nur Cluster aufgeführt, die Ihrem Abonnement zugeordnet sind.
- Für Ihren Cluster muss eine geeignete SKU festgelegt sein, damit die optimale Leistung erzielt werden kann.
Wählen Sie Manuell eingeben aus, und geben Sie dann den Endpunkt ein.
Wählen Sie in der Dropdownliste Datenbank den Namen der Datenbank aus. Alternativ können Sie das Kontrollkästchen Bearbeiten aktivieren und dann den Namen der Datenbank eingeben.
Wählen Sie Verbindung testen aus, um die erstellte Verbindung mit dem verknüpften Dienst zu testen. Wenn Sie eine Verbindung mit dem verknüpften Dienst herstellen können, wird im Bereich ein grünes Häkchensymbol und die Meldung Verbindung erfolgreich angezeigt.
Wählen Sie Verbindung testen aus, um die erstellte Verbindung mit dem verknüpften Dienst zu testen. Wenn Sie eine Verbindung mit dem verknüpften Dienst herstellen können, wird im Bereich ein grünes Häkchensymbol und die Meldung Verbindung erfolgreich angezeigt.
Wählen Sie Erstellen aus, um die Erstellung des verknüpften Diensts abzuschließen.
Konfigurieren der Azure Data Explorer-Datenverbindung
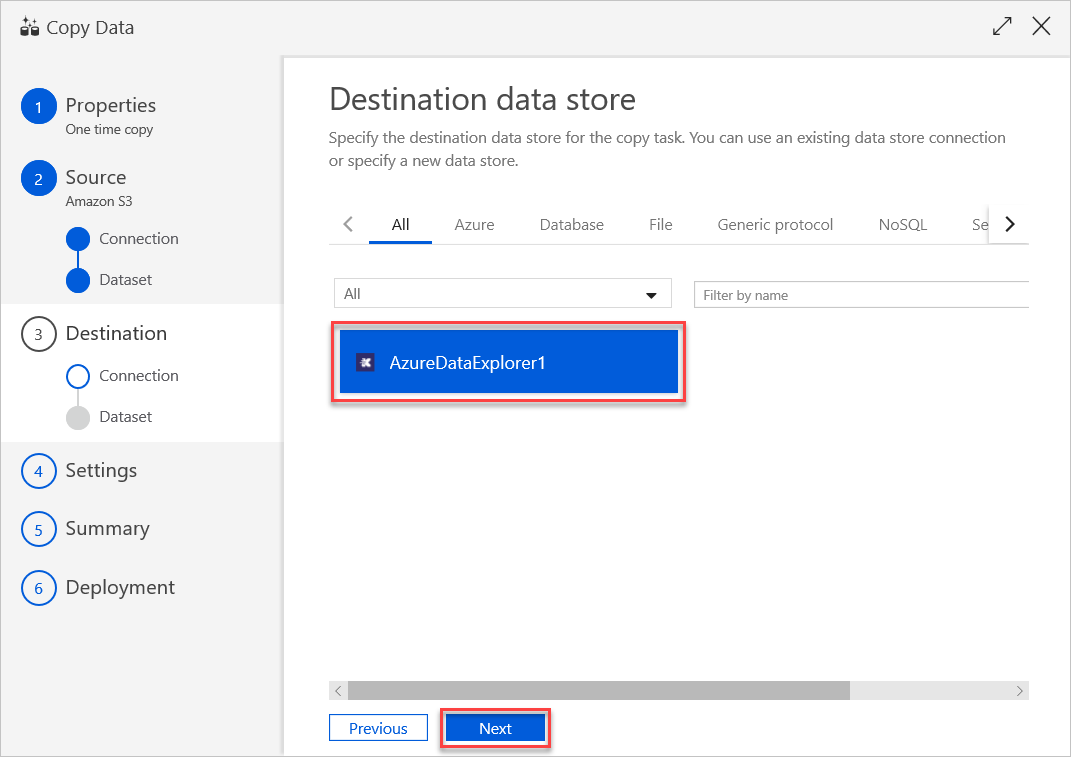
Nach dem Erstellen der Verbindung für den verknüpften Dienst wird der Bereich Zieldatenspeicher geöffnet, und die erstellte Verbindung ist zur Verwendung verfügbar. Führen Sie zum Konfigurieren der Verbindung die folgenden Schritte aus:
Wählen Sie Weiter aus.
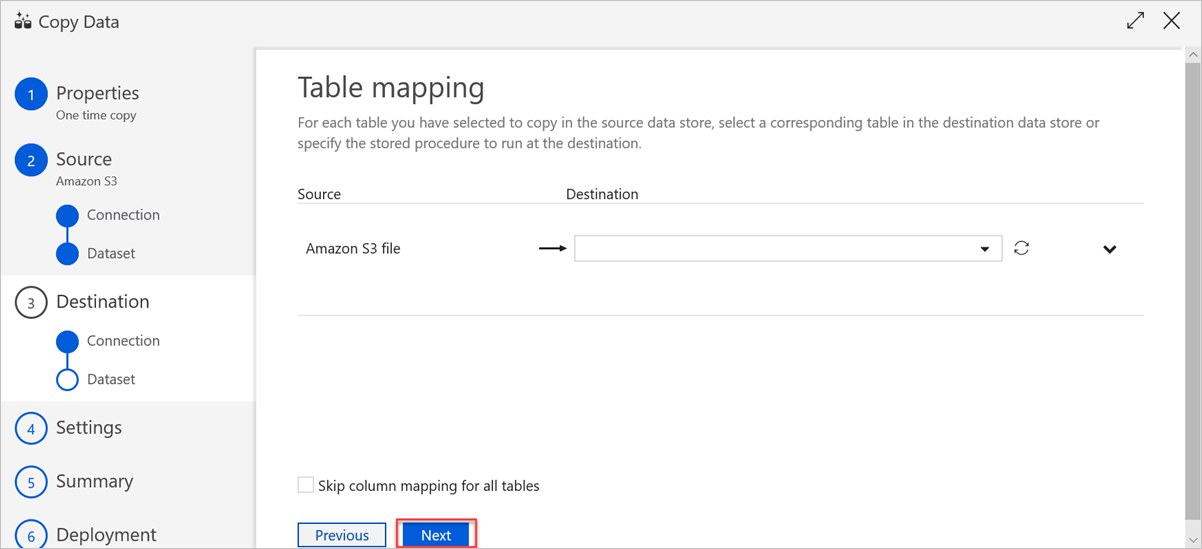
Legen Sie im Bereich Tabellenmapping den Namen der Zieltabelle fest, und wählen Sie Weiter aus.
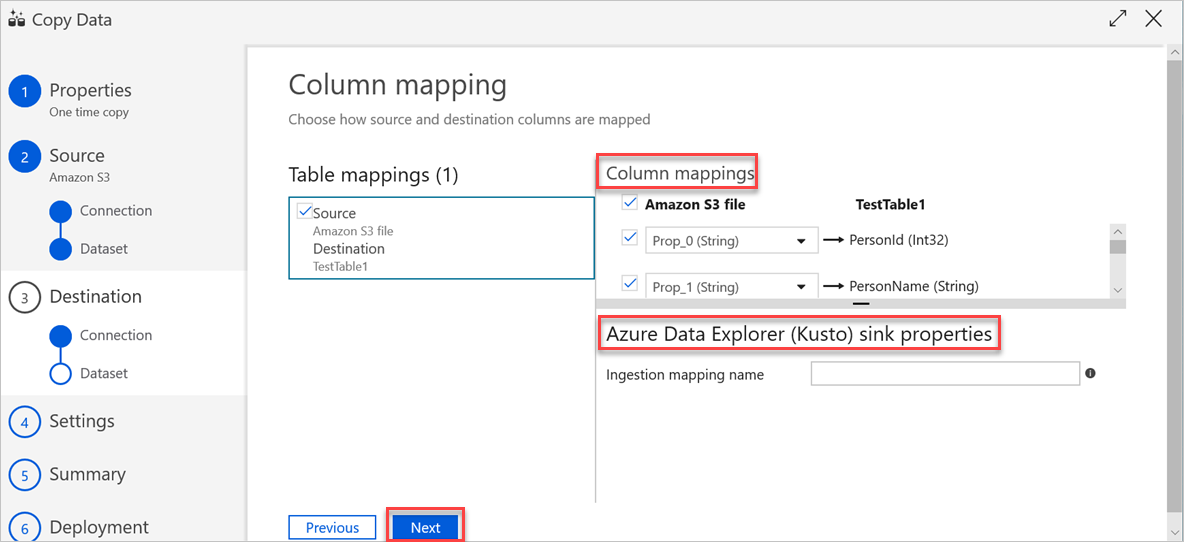
Im Bereich Spaltenzuordnung werden die folgenden Zuordnungen durchgeführt:
a. Die erste Zuordnung erfolgt in Azure Data Factory entsprechend der Azure Data Factory-Schemazuordnung. Gehen Sie folgendermaßen vor:
Legen Sie die Column mappings (Spaltenzuordnungen) für die Azure Data Factory-Zieltabelle fest. Die Standardzuordnung von der Quelle zur Azure Data Factory-Zieltabelle wird angezeigt.
Heben Sie die Auswahl der Spalten auf, die Sie zum Definieren der Spaltenzuordnung nicht benötigen.
b. Die zweite Zuordnung erfolgt, wenn diese tabellarischen Daten in Azure Data Explorer erfasst werden. Die Zuordnung erfolgt gemäß den CSV-Zuordnungsregeln. Selbst wenn die Quelldaten nicht im CSV-Format vorliegen, werden sie in Azure Data Factory in ein Tabellenformat umgewandelt. Daher ist die CSV-Zuordnung in dieser Phase die einzige relevante Zuordnung. Gehen Sie folgendermaßen vor:
(Optional:) Fügen Sie unter Azure Data Explorer (Kusto) sink properties (Azure Data Explorer-Senkeneigenschaften (Kusto)) den relevanten Ingestion mapping name (Name der Erfassungszuordnung) hinzu, sodass die Spaltenzuordnung verwendet werden kann.
Wenn kein Wert für Ingestion mapping name (Name der Erfassungszuordnung) angegeben wird, wird die Zuordnungsreihenfolge nach Name angewandt, die im Abschnitt Spaltenzuordnungen definiert wurde. Wenn bei der Zuordnung nach Name Fehler auftreten, versucht Azure Data Explorer, die Daten mittels Zuordnung nach Spaltenposition zu erfassen (d. h., Zuordnungen werden standardmäßig nach Position vorgenommen).
Wählen Sie Weiter aus.
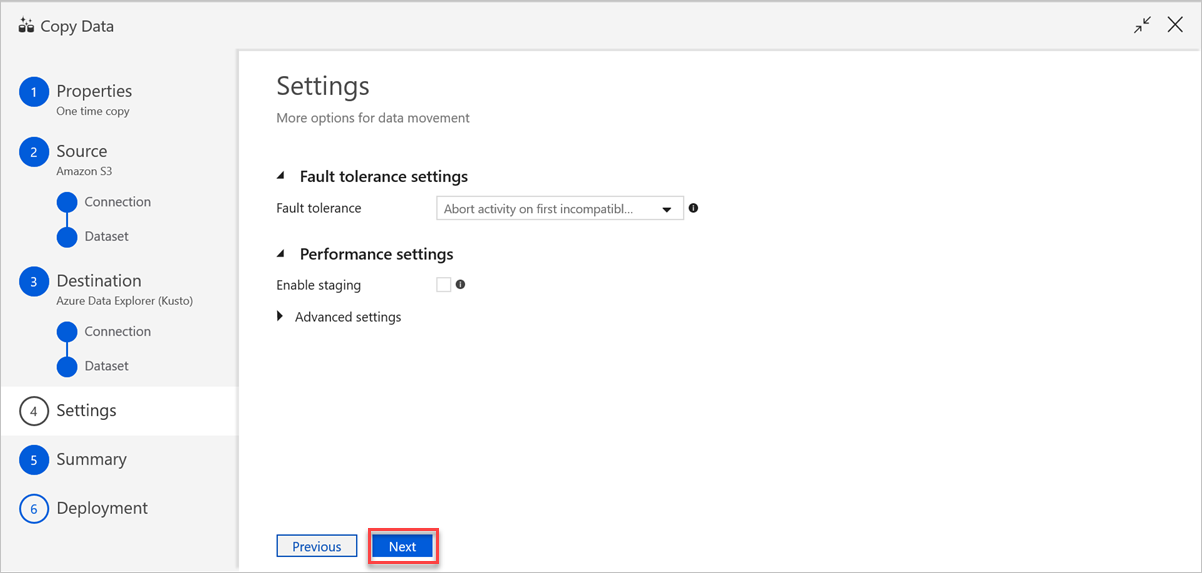
Führen Sie im Bereich Einstellungen die folgenden Schritte aus:
a. Geben Sie unter Fault tolerance settings (Fehlertoleranzeinstellungen) die relevanten Einstellungen ein.
b. Unter Leistungseinstellungen ist Enable staging (Staging aktivieren) nicht anwendbar, und Erweiterte Einstellungen schließt Kostenberücksichtigungen ein. Sofern keine spezifischen Anforderungen vorliegen, lassen Sie die Einstellungen unverändert.
c. Klicken Sie auf Weiter.
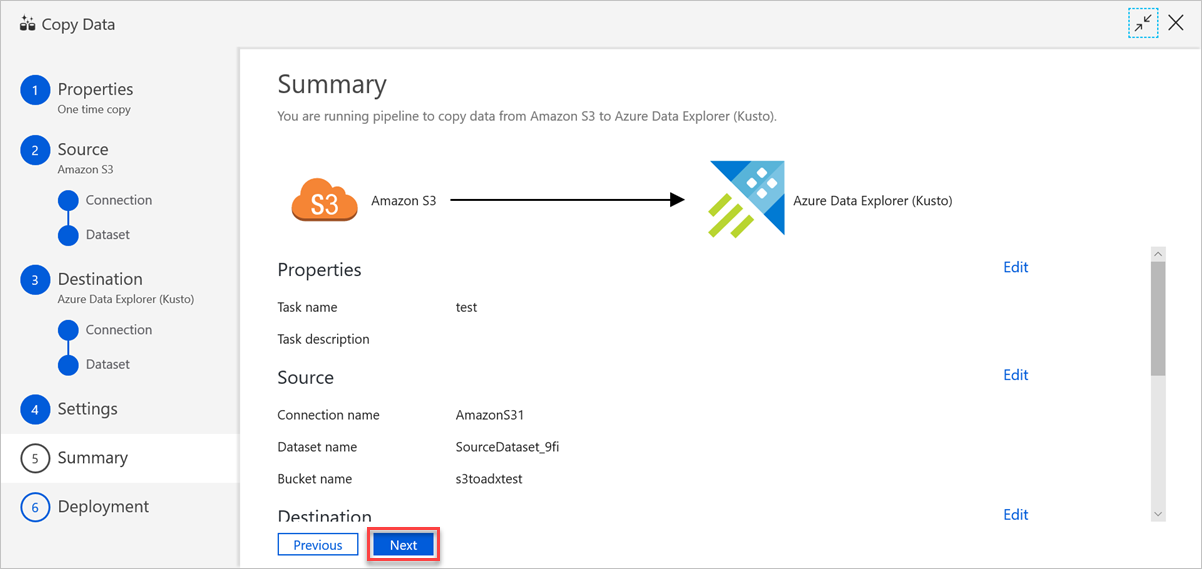
Überprüfen Sie im Bereich Zusammenfassung die Einstellungen, und wählen Sie anschließend Weiter aus.
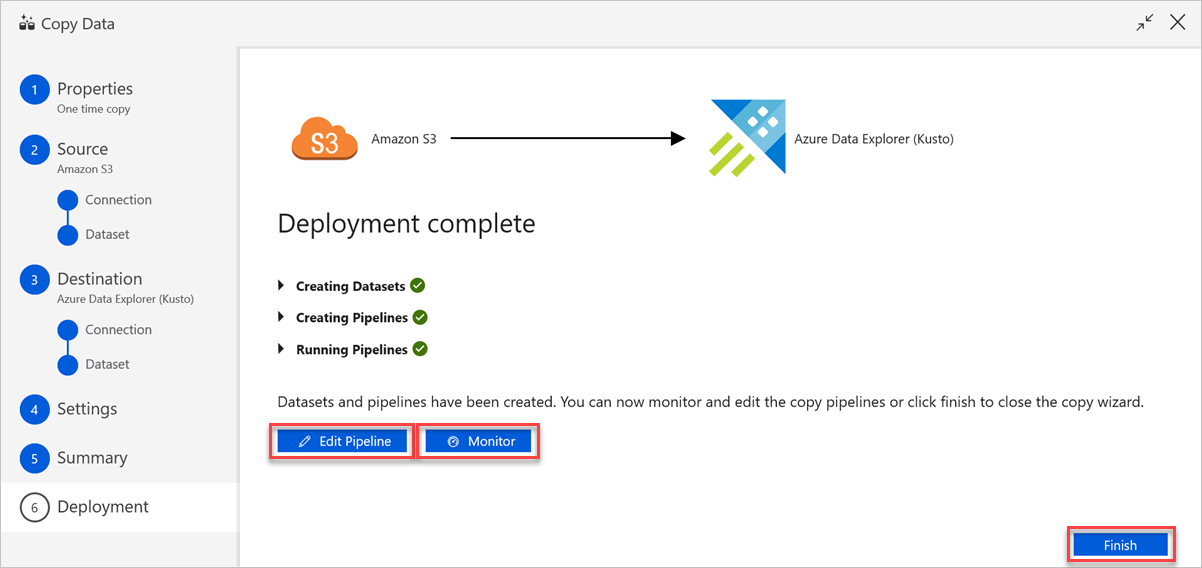
Führen Sie im Bereich Deployment complete (Bereitstellung abgeschlossen) die folgenden Schritte aus:
a. Wählen Sie Überwachung aus, um zur Registerkarte Überwachung zu wechseln und den Status der Pipeline (Fortschritt, Fehler und Datenfluss) zu überwachen.
b. Wählen Sie Pipeline bearbeiten aus, um verknüpfte Dienste, Datasets und Pipelines zu bearbeiten.
c. Wählen Sie Fertig stellen aus, um die Aufgabe „Daten kopieren“ abzuschließen.
Verwandte Inhalte
- Erfahren Sie mehr über den Azure Data Explorer Connector für Azure Data Factory.
- Bearbeiten Sie verknüpfte Dienste, Datasets und Pipelines auf der Data Factory-Benutzeroberfläche.
- Abfragen von Daten auf der Azure Data Explorer-Weboberfläche.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für