Kopieren und Transformieren von Daten in Azure Blob Storage mithilfe von Azure Data Factory oder Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- und Azure Synapse-Pipelines verwenden, um Daten aus und in Azure Blob Storage zu kopieren. Außerdem erfahren Sie, wie Sie die Data Flow-Aktivität zum Transformieren von Daten in Azure Blob Storage verwenden. Weitere Informationen finden Sie in den Einführungsartikeln zu Azure Data Factory und Azure Synapse Analytics.
Tipp
Für Data Lake- oder Data Warehouse-Migrationsszenarios finden Sie weitere Informationen unter Migrieren von Daten aus einem Data Lake oder Data Warehouse zu Azure.
Unterstützte Funktionen
Dieser Azure Blob Storage-Connector wird für die folgenden Aktivitäten unterstützt:
| Unterstützte Funktionen | IR | Verwalteter privater Endpunkt |
|---|---|---|
| Kopieraktivität (Quelle/Senke) | 1.6 | ✓ Speicherkonto V1 ausschließen |
| Zuordnungsdatenfluss (Quelle/Senke) | 0 | ✓ Speicherkonto V1 ausschließen |
| Lookup-Aktivität | 1.6 | ✓ Speicherkonto V1 ausschließen |
| GetMetadata-Aktivität | 1.6 | ✓ Speicherkonto V1 ausschließen |
| Delete-Aktivität | 1.6 | ✓ Speicherkonto V1 ausschließen |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Bei der Kopieraktivität unterstützt dieser Blob Storage-Connector Folgendes:
- Kopieren von Daten in bzw. aus Azure Storage-Konten für allgemeine Zwecke und heißen/kalten Blob Storage.
- Kopieren von Blobs mithilfe eines Kontoschlüssels, der Dienst-SAS (Shared Access Signature), des Dienstprinzipals oder verwalteter Identitäten für die Azure-Ressourcenauthentifizierung
- Kopieren von Blobs aus Block-, Anfüge- oder Seitenblobs und Kopieren von Daten ausschließlich in Blockblobs.
- Kopieren von Blobs im jeweiligen Zustand oder Analysieren bzw. Generieren von Blobs mit unterstützten Dateiformaten und Komprimierungscodecs
- Beibehalten von Dateimetadaten beim Kopieren
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Azure Blob Storage-Diensts über die Benutzeroberfläche
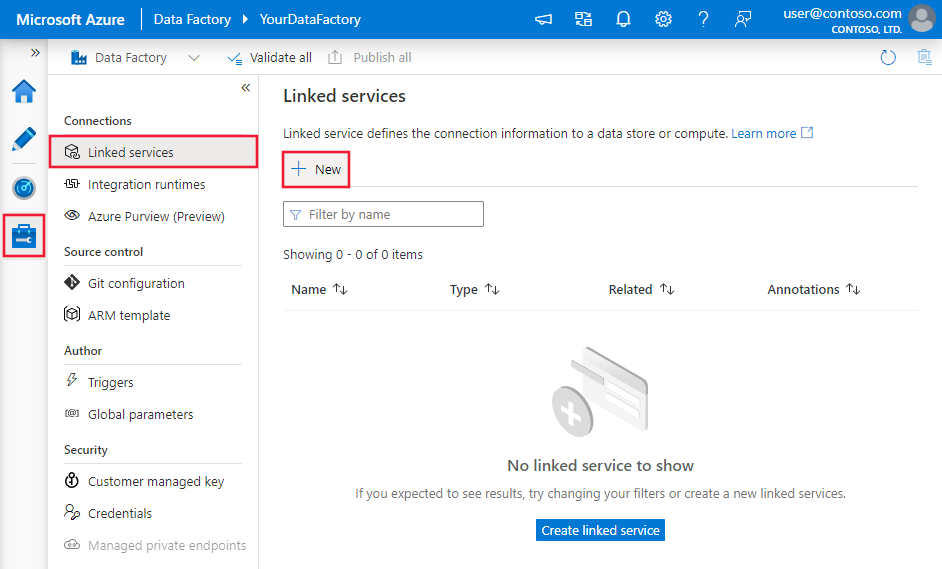
Führen Sie die folgenden Schritte aus, um einen verknüpften Azure Blobspeicherdienst in der Azure-Portal-Benutzeroberfläche zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte „Verwalten“, und wählen Sie „Verknüpfte Dienste“ und anschließend „Neu“ aus:
Suchen Sie nach Blob, und wählen Sie den Connector „Azure Blob Storage“ aus.
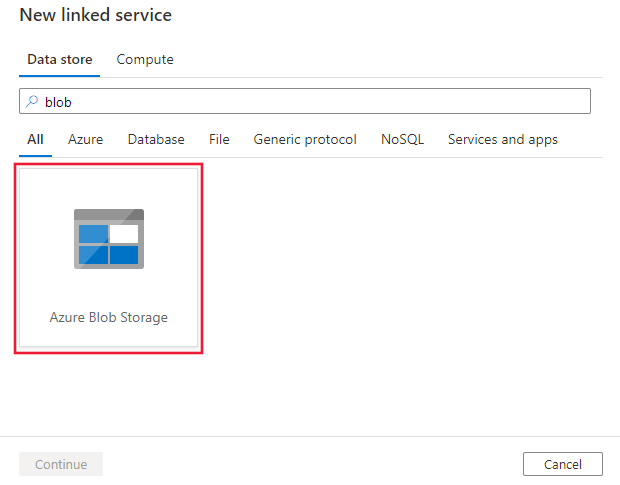
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
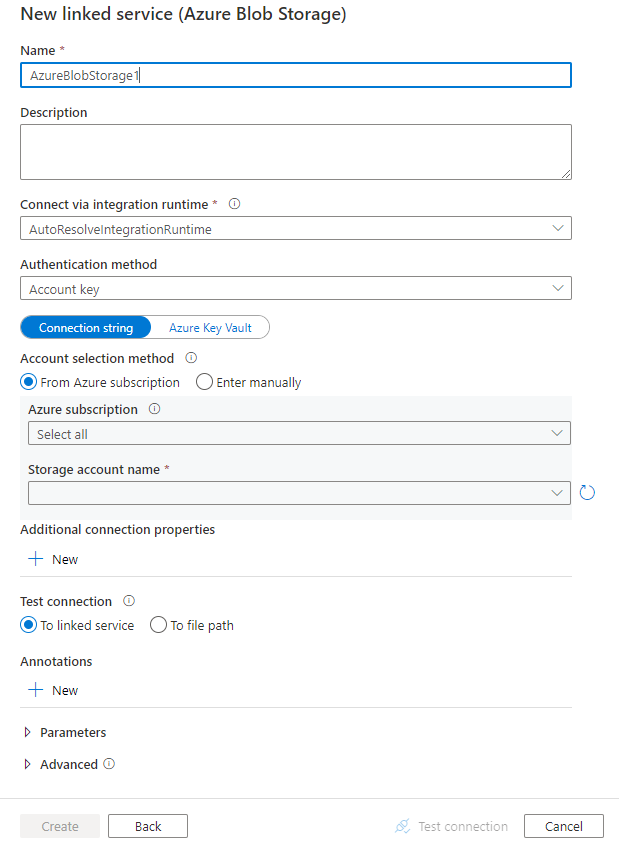
Details zur Connectorkonfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zur Definition von Data Factory- und Synapse-Pipeline-Entitäten speziell für Blobspeicher verwendet werden.
Eigenschaften des verknüpften Diensts
Dieser Blob Storage-Connector unterstützt die folgenden Authentifizierungsypen. Weitere Informationen finden Sie in den entsprechenden Abschnitten.
- Anonyme Authentifizierung
- Kontoschlüsselauthentifizierung
- SAS-Authentifizierung (Shared Access Signature)
- Dienstprinzipalauthentifizierung
- Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
- Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Hinweis
- Wenn Sie die öffentliche Azure Integration Runtime-Instanz zum Herstellen einer Verbindung mit Blob Storage verwenden möchten, indem Sie in der Azure Storage-Firewall die Option Vertrauenswürdigen Microsoft-Diensten den Zugriff auf dieses Speicherkonto erlauben aktivieren, müssen Sie die Authentifizierung per verwalteter Identität verwenden. Weitere Informationen zu den Einstellungen von Azure Storage-Firewalls finden Sie unter Konfigurieren von Azure Storage-Firewalls und virtuellen Netzwerken.
- Wenn Sie Daten mit PolyBase oder der COPY-Anweisung in Azure Synapse Analytics laden und Ihr Quell- oder Stagingblobspeicher mit einem Azure Virtual Network-Endpunkt konfiguriert wurde, müssen Sie die Authentifizierung per verwalteter Identität – wie für Azure Synapse erforderlich – verwenden. Im Abschnitt Verwaltete Identitäten für Azure-Ressourcenauthentifizierung sind weitere Konfigurationsvoraussetzungen aufgeführt.
Hinweis
Azure HDInsight- und Azure Machine Learning-Aktivitäten unterstützen nur die Authentifizierung mit Azure Blob Storage-Kontoschlüsseln.
Anonyme Authentifizierung
Die folgenden Eigenschaften werden für die Authentifizierung von Speicherkontoschlüsseln in Azure Data Factory- oder Synapse-Pipelines unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf AzureBlobStorage (empfohlen) oder AzureStorage (siehe Hinweise unten) festgelegt werden. |
Ja |
| containerUri | Angeben des Azure Blob-Container-URI mit dem aktivierten anonymen Lesezugriff unter Verwendung des Formats https://<AccountName>.blob.core.windows.net/<ContainerName> und Konfigurieren des anonymen öffentlichen Lesezugriffs für Container und Blobs |
Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn diese Eigenschaft nicht angegeben ist, verwendet der Dienst die normale Azure Integration Runtime. | Nein |
Beispiel:
{
"name": "AzureBlobStorageAnonymous",
"properties": {
"annotations": [],
"type": "AzureBlobStorage",
"typeProperties": {
"containerUri": "https:// <accountname>.blob.core.windows.net/ <containername>",
"authenticationType": "Anonymous"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiele-Benutzeroberfläche:
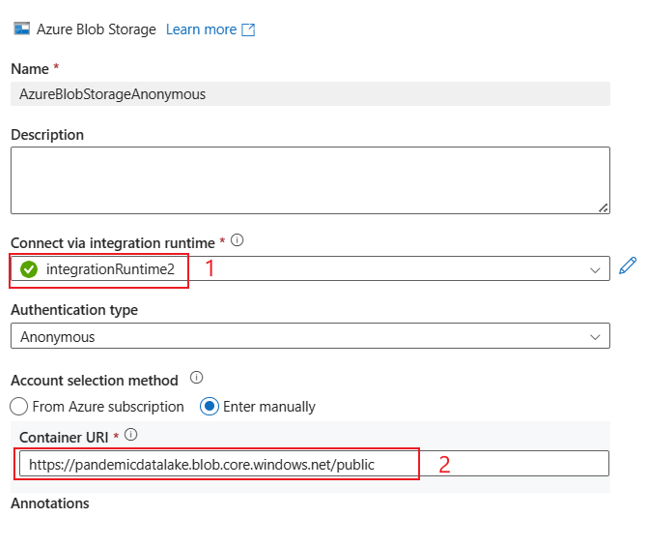
Die Benutzeroberfläche entspricht der folgenden Abbildung. In diesem Beispiel wird das offene Azure-Dataset als Quelle verwendet. Wenn Sie das offene Dataset bing_covid-19_data.csv abrufen möchten, müssen Sie für den Authentifizierungstyp lediglich Anonym auswählen und den Container-URI mit https://pandemicdatalake.blob.core.windows.net/public ausfüllen.
Kontoschlüsselauthentifizierung
Die folgenden Eigenschaften werden für die Authentifizierung von Speicherkontoschlüsseln in Azure Data Factory- oder Synapse-Pipelines unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf AzureBlobStorage (empfohlen) oder AzureStorage (siehe Hinweise unten) festgelegt werden. |
Ja |
| connectionString | Geben Sie für die connectionString-Eigenschaft die Informationen ein, die zum Herstellen einer Verbindung mit Azure Storage erforderlich sind. Sie können auch den Kontoschlüssel in Azure Key Vault speichern und die accountKey-Konfiguration aus der Verbindungszeichenfolge pullen. Weitere Informationen finden Sie in den folgenden Beispielen und im Artikel Speichern von Anmeldeinformationen in Azure Key Vault. |
Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn diese Eigenschaft nicht angegeben ist, verwendet der Dienst die normale Azure Integration Runtime. | Nein |
Hinweis
Ein sekundärer Blob-Dienstendpunkt wird bei Verwendung der Kontoschlüsselauthentifizierung nicht unterstützt. Sie können andere Authentifizierungstypen verwenden.
Hinweis
Wenn Sie den verknüpften Dienst vom Typ AzureStorage verwenden, wird er weiterhin unverändert unterstützt. Sie sollten jedoch in Zukunft den neuen verknüpften Dienst vom Typ AzureBlobStorage verwenden.
Beispiel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Speichern des Kontoschlüssels in Azure Key Vault
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
SAS-Authentifizierung (Shared Access Signature)
Shared Access Signatures bieten delegierten Zugriff auf Ressourcen in Ihrem Speicherkonto. Sie können eine SAS verwenden, um einem Client für einen bestimmten Zeitraum eingeschränkte Berechtigungen für Objekte in Ihrem Speicherkonto zu gewähren.
Sie müssen die Zugriffsschlüssel für Ihr Konto nicht freigeben. Die SAS ist ein URI, dessen Abfrageparameter alle erforderlichen Informationen für den authentifizierten Zugriff auf eine Speicherressource enthalten. Um mit der SAS auf Speicherressourcen zuzugreifen, muss der Client diese nur an den entsprechenden Konstruktor bzw. die entsprechende Methode übergeben.
Weitere Informationen zu Shared Access Signatures finden Sie unter Shared Access Signatures (SAS): Verstehen des Shared Access Signature-Modells.
Hinweis
- Der Dienst unterstützt jetzt SAS (Shared Access Signatures) für Dienste sowie für Konten. Weitere Informationen zu SAS (Shared Access Signatures) finden Sie unter Gewähren von eingeschränktem Zugriff auf Azure Storage-Ressourcen mithilfe von SAS (Shared Access Signature).
- Bei späteren Datasetkonfigurationen ist der Ordnerpfad der absolute Pfad ab der Containerebene. Sie müssen einen Pfad konfigurieren, der sich am Pfad in Ihrem SAS-URI orientiert.
Für die Verwendung der SAS-Authentifizierung werden die folgenden Eigenschaften unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf AzureBlobStorage (empfohlen) oder AzureStorage (siehe Hinweise unten) festgelegt werden. |
Ja |
| sasUri | Geben Sie den SAS-URI für Azure Storage-Ressourcen wie Blobs oder Container an. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern. Sie können auch das SAS-Token in Azure Key Vault speichern, um die automatische Rotation zu nutzen und den Tokenabschnitt zu entfernen. Weitere Informationen finden Sie in den folgenden Beispielen sowie unter Speichern von Anmeldeinformationen in Azure Key Vault. |
Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn diese Eigenschaft nicht angegeben ist, verwendet der Dienst die normale Azure Integration Runtime. | Nein |
Hinweis
Wenn Sie den verknüpften Dienst vom Typ AzureStorage verwenden, wird er weiterhin unverändert unterstützt. Sie sollten jedoch in Zukunft den neuen verknüpften Dienst vom Typ AzureBlobStorage verwenden.
Beispiel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Speichern des Kontoschlüssels in Azure Key Vault
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Berücksichtigen Sie beim Erstellen eines SAS-URIs die folgenden Aspekte:
- Legen Sie geeignete Lese-/Schreib-Berechtigungen für Objekte fest, basierend auf der Verwendung des verknüpften Diensts (Lesen, Schreiben, Lesen/Schreiben).
- Legen Sie für Ablaufzeit einen geeigneten Wert fest. Stellen Sie sicher, dass der Zugriff auf Storage-Objekte nicht während des aktiven Zeitraums der Pipeline abläuft.
- Der URI sollte je nach Bedarf auf der richtigen Container- oder Blobebene erstellt werden. Ein SAS-URI zu einem Blob ermöglicht der Data Factory- oder Synapse-Pipeline den Zugriff auf dieses spezielle Blob. Ein SAS-URI zu einem Blobspeichercontainer ermöglicht der Data Factory- oder Synapse-Pipeline das Durchlaufen von Blobs in diesem Container. Wenn Sie den Zugriff später auf mehr Objekte ausweiten oder auf weniger Objekte beschränken oder den SAS-URI aktualisieren möchten, denken Sie daran, den verknüpften Dienst mit dem neuen URI zu aktualisieren.
Dienstprinzipalauthentifizierung
Allgemeine Informationen zur Dienstprinzipalauthentifizierung für Azure Storage finden Sie unter Autorisieren des Zugriffs auf Azure Storage mit Microsoft Entra ID.
Zum Verwenden der Dienstprinzipalauthentifizierung führen Sie die folgenden Schritte aus:
Registrieren einer Anwendung bei der Microsoft Identity Platform. Eine Anleitung finden Sie unter Schnellstart: Registrieren einer Anwendung bei Microsoft Identity Platform. Notieren Sie sich die folgenden Werte, die Sie zum Definieren des verknüpften Diensts verwenden können:
- Anwendungs-ID
- Anwendungsschlüssel
- Mandanten-ID
Erteilen Sie dem Dienstprinzipal die entsprechenden Berechtigung in Azure Blob Storage. Weitere Informationen zu den Rollen finden Sie unter Zuweisen einer Azure-Rolle für den Zugriff auf Blob- und Warteschlangendaten über das Azure-Portal.
- Erteilen Sie ihm als Quelle in der Zugriffssteuerung (IAM) mindestens die Rolle Storage-Blobdatenleser.
- Weisen Sie ihm Als Senke in der Zugriffssteuerung (IAM) mindestens die Rolle Mitwirkender an Storage-Blobdaten zu.
Diese Eigenschaften werden für den mit Azure Blob Storage verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureBlobStorage festgelegt sein. | Ja |
| serviceEndpoint | Geben Sie den Azure Blob Storage-Dienstendpunkt mit dem Muster https://<accountName>.blob.core.windows.net/ an. |
Ja |
| accountKind | Geben Sie die Art Ihres Speicherkontos an. Zulässige Werte sind: Storage (Universell v1), StorageV2 (Universell v2), BlobStorage oder BlockBlobStorage. Bei Verwendung des mit Azure Blob verknüpften Diensts im Datenfluss wird die Authentifizierung per verwalteter Identität oder Dienstprinzipal nicht unterstützt, wenn der Kontotyp leer ist oder der Wert „Storage“ lautet. Geben Sie die richtige Kontoart an, wählen Sie eine andere Authentifizierung aus, oder aktualisieren Sie Ihr Speicherkonto auf „Universell v2“. |
Nein |
| servicePrincipalId | Geben Sie die Client-ID der Anwendung an. | Ja |
| servicePrincipalCredentialType | Die Art von Anmeldeinformationen, die für die Authentifizierung beim Dienstprinzipal verwendet werden. Gültige Werte sind ServicePrincipalKey und ServicePrincipalCert. | Ja |
| servicePrincipalCredential | Die Anmeldeinformationen für den Dienstprinzipal. Wenn Sie ServicePrincipalKey als Anmeldeinformationstyp verwenden, geben Sie den Schlüssel der Anwendung an. Markieren Sie dieses Feld als einen SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. Wenn Sie ServicePrincipalCert als Anmeldeinformationen verwenden, verweisen Sie auf ein Zertifikat in Azure Key Vault, und stellen Sie sicher, dass der Zertifikatsinhaltstyp PKCS #12 lautet. |
Ja |
| tenant | Geben Sie die Mandanteninformationen (Domänenname oder Mandanten-ID) für Ihre Anwendung an. Diese können Sie abrufen, indem Sie im Azure-Portal mit der Maus auf den Bereich oben rechts zeigen. | Ja |
| azureCloudType | Geben Sie für die Dienstprinzipalauthentifizierung die Art der Azure-Cloudumgebung an, bei der Ihre Microsoft Entra-Anwendung registriert ist. Zulässige Werte sind AzurePublic, AzureChina, AzureUsGovernment und AzureGermany. Standardmäßig wird die Cloudumgebung der Data Factory oder der Synapse-Pipeline verwendet. |
Nein |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn diese Eigenschaft nicht angegeben ist, verwendet der Dienst die normale Azure Integration Runtime. | Nein |
Hinweis
- Wenn für Ihr Blobkonto die Option Vorläufiges Löschen aktiviert ist, wird die Authentifizierung des Dienstprinzipals im Datenfluss nicht unterstützt.
- Wenn Sie über einen privaten Endpunkt mithilfe von Data Flow auf den Blob-Speicher zugreifen, müssen Sie beachten, dass Data Flow bei Verwendung von Dienstprinzipalauthentifizierung mit dem ADLS Gen2-Endpunkt statt mit dem Blob-Endpunkt verbunden wird. Stellen Sie sicher, dass Sie den entsprechenden privaten Endpunkt in Ihrer Data Factory oder Ihrem Synapse-Arbeitsbereich erstellen, um den Zugriff zu ermöglichen.
Hinweis
Die Dienstprinzipalauthentifizierung wird nur durch den verknüpften Dienst vom Typ „AzureBlobStorage“unterstützt, nicht jedoch vom vorherigen verknüpften Dienst vom Typ „AzureStorage“.
Beispiel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
Eine Data Factory- oder Synapse-Pipeline kann einer systemseitig zugewiesenen verwalteten Identität für Azure-Ressourcen zugeordnet werden, die diese Ressource für die Authentifizierung bei anderen Azure-Diensten darstellt. Sie können diese systemseitig zugewiesene verwaltete Identität direkt für die Blob Storage-Authentifizierung verwenden, ähnlich wie bei der Verwendung Ihres eigenen Dienstprinzipals. Sie erlaubt dieser bestimmten Ressource den Zugriff auf und das Kopieren von Daten aus bzw. in Blob Storage. Weitere Informationen zu verwalteten Identitäten für Azure-Ressourcen finden Sie unter Verwaltete Identitäten für Azure-Ressourcen
Weitere allgemeine Informationen zur Azure Storage-Authentifizierung finden Sie unter Autorisieren des Zugriffs auf Azure Storage mit Microsoft Entra ID. Wenn Sie verwaltete Identitäten für die Azure-Ressourcenauthentifizierung verwenden möchten, gehen Sie folgendermaßen vor:
Rufen Sie die Informationen zur systemseitig zugewiesenen verwalteten Identität ab, indem Sie den Wert der Objekt-ID der systemseitig zugewiesenen verwalteten Identität kopieren, die zusammen mit Ihrer Factory- oder Ihrem Synapse-Arbeitsbereich generiert wurde.
Erteilen Sie der verwalteten Identität Berechtigungen in Azure Blob Storage. Weitere Informationen zu den Rollen finden Sie unter Zuweisen einer Azure-Rolle für den Zugriff auf Blob- und Warteschlangendaten über das Azure-Portal.
- Erteilen Sie ihm als Quelle in der Zugriffssteuerung (IAM) mindestens die Rolle Storage-Blobdatenleser.
- Weisen Sie ihm Als Senke in der Zugriffssteuerung (IAM) mindestens die Rolle Mitwirkender an Storage-Blobdaten zu.
Diese Eigenschaften werden für den mit Azure Blob Storage verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureBlobStorage festgelegt sein. | Ja |
| serviceEndpoint | Geben Sie den Azure Blob Storage-Dienstendpunkt mit dem Muster https://<accountName>.blob.core.windows.net/ an. |
Ja |
| accountKind | Geben Sie die Art Ihres Speicherkontos an. Zulässige Werte sind: Storage (Universell v1), StorageV2 (Universell v2), BlobStorage oder BlockBlobStorage. Bei Verwendung des mit Azure Blob verknüpften Diensts im Datenfluss wird die Authentifizierung per verwalteter Identität oder Dienstprinzipal nicht unterstützt, wenn der Kontotyp leer ist oder der Wert „Storage“ lautet. Geben Sie die richtige Kontoart an, wählen Sie eine andere Authentifizierung aus, oder aktualisieren Sie Ihr Speicherkonto auf „Universell v2“. |
Nein |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn diese Eigenschaft nicht angegeben ist, verwendet der Dienst die normale Azure Integration Runtime. | Nein |
Beispiel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Eine Data Factory kann mit einer oder mehreren benutzerseitig zugewiesenen verwalteten Identitäten zugewiesen werden. Sie können diese benutzerseitig zugewiesene verwaltete Identität für die Blob Storage-Authentifizierung verwenden, die den Zugriff auf und das Kopieren von Daten aus oder in Blobspeicher ermöglicht. Weitere Informationen zu verwalteten Identitäten für Azure-Ressourcen finden Sie unter Verwaltete Identitäten für Azure-Ressourcen
Weitere allgemeine Informationen zur Azure Storage-Authentifizierung finden Sie unter Autorisieren des Zugriffs auf Azure Storage mit Microsoft Entra ID. Führen Sie die folgenden Schritte aus, um die Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität zu verwenden:
Erstellen Sie eine oder mehrere benutzerseitig zugewiesene verwaltete Identitäten, und gewähren Sie ihnen Berechtigungen in Azure Blob Storage. Weitere Informationen zu den Rollen finden Sie unter Zuweisen einer Azure-Rolle für den Zugriff auf Blob- und Warteschlangendaten über das Azure-Portal.
- Erteilen Sie ihm als Quelle in der Zugriffssteuerung (IAM) mindestens die Rolle Storage-Blobdatenleser.
- Weisen Sie ihm Als Senke in der Zugriffssteuerung (IAM) mindestens die Rolle Mitwirkender an Storage-Blobdaten zu.
Weisen Sie Ihrer Data Factory eine oder mehrere benutzerseitig zugewiesene verwaltete Identitäten zu, und erstellen Sie Anmeldeinformationen für jede benutzerseitig zugewiesene verwaltete Identität.
Diese Eigenschaften werden für den mit Azure Blob Storage verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureBlobStorage festgelegt sein. | Ja |
| serviceEndpoint | Geben Sie den Azure Blob Storage-Dienstendpunkt mit dem Muster https://<accountName>.blob.core.windows.net/ an. |
Ja |
| accountKind | Geben Sie die Art Ihres Speicherkontos an. Zulässige Werte sind: Storage (Universell v1), StorageV2 (Universell v2), BlobStorage oder BlockBlobStorage. Bei Verwendung des mit Azure Blob verknüpften Diensts im Datenfluss wird die Authentifizierung per verwalteter Identität oder Dienstprinzipal nicht unterstützt, wenn der Kontotyp leer ist oder der Wert „Storage“ lautet. Geben Sie die richtige Kontoart an, wählen Sie eine andere Authentifizierung aus, oder aktualisieren Sie Ihr Speicherkonto auf „Universell v2“. |
Nein |
| Anmeldeinformationen | Geben Sie die benutzerseitig zugewiesene verwaltete Identität als Anmeldeinformationsobjekt an. | Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn diese Eigenschaft nicht angegeben ist, verwendet der Dienst die normale Azure Integration Runtime. | Nein |
Beispiel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Wichtig
Wenn Sie Daten mithilfe von PolyBase oder der COPY-Anweisung aus Blob Storage (als Quelle oder Stagingkomponente) in Azure Synapse Analytics laden und dazu die Authentifizierung per verwalteter Identität für Blob Storage verwenden, müssen Sie unbedingt auch die Schritte 1 bis 3 in dieser Anleitung befolgen. Mit diesen Schritten wird der Server bei Microsoft Entra ID registriert, und Ihrem Server wird die Rolle „Mitwirkender an Storage-Blobdaten“ zugewiesen. Data Factory kümmert sich um den Rest. Wenn Sie Blob Storage mit einem Azure Virtual Network-Endpunkt konfigurieren, muss außerdem im Einstellungsmenü Firewalls und virtuelle Netzwerke des Azure Storage-Kontos die Option Vertrauenswürdigen Microsoft-Diensten den Zugriff auf dieses Speicherkonto erlauben aktiviert sein (wie für Azure Synapse erforderlich).
Hinweis
- Wenn für Ihr Blobkonto die Option Vorläufiges Löschen aktiviert ist, wird die Authentifizierung von systemseitig/benutzerseitig zugewiesenen verwalteten Identitäten im Datenfluss nicht unterstützt.
- Wenn Sie über einen privaten Endpunkt mithilfe von Data Flow auf den Blob-Speicher zugreifen, müssen Sie beachten, dass das Datenfluss bei Verwendung von Authentifizierung mit systemseitig/benutzerseitig zugewiesenen verwalteten Identitäten mit dem ADLS Gen2-Endpunkt statt mit dem Blob-Endpunkt verbunden wird. Stellen Sie sicher, dass Sie den entsprechenden privaten Endpunkt in ADF erstellen, um den Zugriff zu ermöglichen.
Hinweis
Systemseitig/benutzerseitig zugewiesene verwaltete Identitäten für die Azure-Ressourcenauthentifizierung werden nur vom verknüpften Dienst vom Typ „AzureBlobStorage“ unterstützt, nicht jedoch vom vorherigen verknüpften Dienst vom Typ „AzureStorage“.
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets.
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Textformat mit Trennzeichen
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Folgende Eigenschaften werden für Azure Blob Storage unter den location-Einstellungen in formatbasierten Datasets unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Speicherorts im Dataset muss auf AzureBlobStorageLocation festgelegt werden. | Ja |
| Container | Der BLOB-Container. | Ja |
| folderPath | Der Pfad zum Ordner unter dem angegebenen Container. Wenn Sie einen Platzhalter verwenden möchten, um den Ordner zu filtern, überspringen Sie diese Einstellung, und geben Sie entsprechende Aktivitätsquelleneinstellungen an. | Nein |
| fileName | Der Dateiname unter dem angegebenen Container und Ordnerpfad. Wenn Sie Platzhalter verwenden möchten, um Dateien zu filtern, überspringen Sie diese Einstellung, und geben Sie dies entsprechend in den Aktivitätsquelleneinstellungen an. | Nein |
Beispiel:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste mit Eigenschaften, die von der Blob Storage-Quelle und -Senke unterstützt werden.
Blob Storage als Quelltyp
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Textformat mit Trennzeichen
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Folgende Eigenschaften werden für Azure Blob Storage unter den storeSettings-Einstellungen in formatbasierten Kopierquellen unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft unter storeSettings muss auf AzureBlobStorageReadSettings festgelegt werden. |
Ja |
| Suchen Sie die zu kopierenden Dateien: | ||
| OPTION 1: statischer Pfad |
Kopieren Sie aus dem angegebenen Container oder Ordner/Dateipfad, der im Dataset angegeben ist. Wenn Sie alle Blobs aus einem Container oder Ordner kopieren möchten, geben Sie zusätzlich wildcardFileName als * an. |
|
| Option 2: Blobpräfix – prefix |
Präfix für den Blobnamen unter dem angegebenen Container, der in einem Dataset zum Filtern von Quellblobs konfiguriert wurde. Es werden die Blobs ausgewählt, deren Namen mit container_in_dataset/this_prefix beginnen. Für Blob Storage wird der serverseitige Filter verwendet, dessen Leistung besser ist als die eines Platzhalterfilters.Wenn Sie das Präfix verwenden und in eine dateibasierte Senke mit Beibehaltung der Hierarchie kopieren, wird der Unterpfad nach dem letzten „/“ im Präfix beibehalten. Wenn Sie beispielsweise container/folder/subfolder/file.txt als Quelle haben und das Präfix als folder/sub konfigurieren, lautet der beibehaltene Dateipfad subfolder/file.txt. |
Nein |
| OPTION 3: Platzhalter – wildcardFolderPath |
Der Ordnerpfad mit Platzhalterzeichen unter dem angegebenen Container, der in einem Dataset für das Filtern von Quellordnern konfiguriert ist. Folgende Platzhalter sind zulässig: * (entspricht null [0] oder mehr Zeichen) und ? (entspricht null [0] oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr Ordnername einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Nein |
| OPTION 3: Platzhalter – wildcardFileName |
Der Dateiname mit Platzhalterzeichen unter dem angegebenen Container und Ordnerpfad (oder Platzhalterordnerpfad) für das Filtern von Quelldateien. Folgende Platzhalter sind zulässig: * (entspricht null [0] oder mehr Zeichen) und ? (entspricht null [0] oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn der tatsächliche Dateiname einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Ja |
| OPTION 4: eine Liste von Dateien – fileListPath |
Gibt an, dass eine bestimmte Dateigruppe kopiert werden soll. Verweisen Sie auf eine Textdatei, die eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile. Dies ist der relative Pfad zu dem im Dataset konfigurierten Pfad. Wenn Sie diese Option verwenden, geben Sie keinen Dateinamen im Dataset an. Weitere Beispiele finden Sie unter Beispiele für Dateilisten. |
Nein |
| Zusätzliche Einstellungen: | ||
| recursive | Gibt an, ob die Daten rekursiv aus den Unterordnern oder nur aus dem angegebenen Ordner gelesen werden. Beachten Sie Folgendes: Wenn recursive auf TRUE festgelegt ist und es sich bei der Senke um einen dateibasierten Speicher handelt, wird ein leerer Ordner oder Unterordner nicht in die Senke kopiert und dort auch nicht erstellt. Zulässige Werte sind true (Standard) und false. Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| deleteFilesAfterCompletion | Gibt an, ob die Binärdateien nach dem erfolgreichen Verschieben in den Zielspeicher aus dem Quellspeicher gelöscht werden. Der Dateilöschvorgang erfolgt pro Datei. Bei einem Fehler der Kopieraktivität stellen Sie daher fest, dass einige Dateien bereits ins Ziel kopiert und aus der Quelle gelöscht wurden, wohingegen sich andere weiterhin im Quellspeicher befinden. Diese Eigenschaft ist nur im Szenario zum Kopieren von Binärdateien gültig. Standardwert: FALSE. |
Nein |
| modifiedDatetimeStart | Die Dateien werden anhand des Attributs „Letzte Änderung“ gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format „2018-12-01T05:00:00Z“ angewendet. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewendet wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEndNULL ist, werden die Dateien ausgewählt, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd den datetime-Wert aufweist, aber modifiedDatetimeStartNULL ist, werden die Dateien ausgewählt, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist.Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| modifiedDatetimeEnd | Identisch mit der vorherigen Eigenschaft. | Nein |
| enablePartitionDiscovery | Geben Sie bei partitionierten Dateien an, ob die Partitionen anhand des Dateipfads analysiert und als zusätzliche Quellspalten hinzugefügt werden sollen. Zulässige Werte sind false (Standard) und true. |
Nein |
| partitionRootPath | Wenn die Partitionsermittlung aktiviert ist, geben Sie den absoluten Stammpfad an, um partitionierte Ordner als Datenspalten zu lesen. Wenn dieser Wert nicht angegeben ist, gilt standardmäßig Folgendes: - Wenn Sie den Dateipfad im Dataset oder die Liste der Dateien in der Quelle verwenden, ist der Partitionsstammpfad der im Dataset konfigurierte Pfad. Wenn Sie einen Platzhalterordnerfilter verwenden, ist der Stammpfad der Partition der Unterpfad vor dem ersten Platzhalter. Wenn Sie Präfix verwenden, ist der Stammpfad der Partition ein Unterpfad vor dem letzten „/“. Angenommen, Sie konfigurieren den Pfad im Dataset als „root/folder/year=2020/month=08/day=27“: - Wenn Sie den Stammpfad der Partition als „root/folder/year=2020“ angeben, generiert die Kopieraktivität zusätzlich zu den Spalten in den Dateien die beiden weiteren Spalten month und day mit den Werten „08“ bzw. „27“.- Wenn kein Stammpfad für die Partition angegeben wird, werden keine zusätzlichen Spalten generiert. |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
Hinweis
Beim Parquet-Format/Textformat mit Trennzeichen wird die im nächsten Abschnitt beschriebene Quelle der Kopieraktivität vom Typ BlobSource aus Gründen der Abwärtskompatibilität weiterhin unverändert unterstützt. Es wird allerdings empfohlen, das neue Modell zu verwenden, bis die Erstellungsoberfläche für die Generierung dieser neuen Typen angepasst wurde.
Beispiel:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Hinweis
Der Container $logs, der während der Aktivierung von Storage Analytics für eine Speicherkonto automatisch erstellt wird, wird beim Ausführen eines Auflistungsvorgangs für Container über die Benutzeroberfläche nicht angezeigt. Der Dateipfad muss direkt angegeben werden, damit Ihre Data Factory- oder Synapse-Pipeline Dateien aus dem Container $logs verwenden kann.
Blob Storage als Senkentyp
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
Folgende Eigenschaften werden für Azure Blob Storage unter den storeSettings-Einstellungen in formatbasierten Kopiersenken unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft unter storeSettings muss auf AzureBlobStorageWriteSettings festgelegt werden. |
Ja |
| copyBehavior | Definiert das Kopierverhalten, wenn es sich bei der Quelle um Dateien aus einem dateibasierten Datenspeicher handelt. Zulässige Werte sind: - PreserveHierarchy (Standard): Behält die Dateihierarchie im Zielordner bei. Der relative Pfad der Quelldatei zum Quellordner ist mit dem relativen Pfad der Zieldatei zum Zielordner identisch. - FlattenHierarchy: Alle Dateien aus dem Quellordner befinden sich auf der ersten Ebene des Zielordners. Die Namen für die Zieldateien werden automatisch generiert. - MergeFiles: Alle Dateien aus dem Quellordner werden in einer Datei zusammengeführt. Wenn der Datei- oder Blobname angegeben wurde, entspricht der Name der Zusammenführungsdatei dem angegebenen Namen. Andernfalls wird der Dateiname automatisch generiert. |
Nein |
| blockSizeInMB | Geben Sie die Blockgröße, die zum Schreiben von Daten in Blockblobs verwendet wird, in Megabyte an. Informieren Sie sich ausführlicher über Blockblobs. Der zulässige Wert liegt zwischen 4 und 100 MB. Standardmäßig bestimmt der Dienst automatisch die Blockgröße, basierend auf dem Quellspeichertyp und den Daten. Bei einer nicht binären Kopie in Blob Storage beträgt die Standardblockgröße 100 MB, damit sie in maximal 4,95 TB Daten passt. Dies ist möglicherweise nicht optimal, wenn Ihre Daten nicht groß sind – insbesondere, wenn Sie die selbstgehostete Integration Runtime mit einer schlechten Netzwerkverbindung verwenden, was zu einem Timeout des Vorgangs oder Leistungsproblemen führt. Sie können explizit eine Blockgröße angeben und gleichzeitig sicherstellen, dass blockSizeInMB*50000 groß genug ist, um die Daten zu speichern. Andernfalls tritt bei der Ausführung der Kopieraktivität ein Fehler auf. |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
| metadata | Hiermit werden beim Kopieren in die Senke benutzerdefinierte Metadaten festgelegt. Jedes Objekt unter dem Array metadata stellt eine zusätzliche Spalte dar. name definiert den Namen des Metadatenschlüssels, und value gibt den Datenwert dieses Schlüssels an. Wenn das Feature zum Beibehalten von Attributen verwendet wird, werden die angegebenen Metadaten mit den Metadaten der Quelldatei vereint/überschrieben.Zulässige Datenwerte sind: - $$LASTMODIFIED: Eine reservierte Variable gibt an, dass der Zeitpunkt der letzten Änderung der Quelldateien gespeichert werden soll. Gilt nur für dateibasierte Quellen im Binärformat.– Ausdruck - Statischer Wert |
Nein |
Beispiel:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobStorageWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
Beispiele für Ordner- und Dateifilter
Dieser Abschnitt beschreibt das sich ergebende Verhalten für den Ordnerpfad und den Dateinamen mit Platzhalterfiltern.
| folderPath | fileName | recursive | Quellordnerstruktur und Filterergebnis (Dateien mit Fettformatierung werden abgerufen.) |
|---|---|---|---|
container/Folder* |
(empty, use default) | false | Container FolderA Datei1.csv File2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
container/Folder* |
(empty, use default) | true | Container FolderA Datei1.csv File2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
container/Folder* |
*.csv |
false | Container FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
container/Folder* |
*.csv |
true | Container FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Beispiele für Dateilisten
In diesem Abschnitt wird das resultierende Verhalten beschrieben, wenn ein Dateilistenpfad in der Quelle einer Kopieraktivität verwendet wird.
Angenommen, Sie haben die folgende Quellordnerstruktur und möchten die Dateien kopieren, deren Namen fett formatiert sind:
| Beispielquellstruktur | Inhalt in „FileListToCopy.txt“ | Konfiguration |
|---|---|---|
| Container FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv Metadaten FileListToCopy.txt |
Datei1.csv Unterordner1/Datei3.csv Unterordner1/Datei5.csv |
Im Dataset: – Container: container– Ordnerpfad: FolderAIn der Quelle der Kopieraktivität: – Dateilistenpfad: container/Metadata/FileListToCopy.txt Der Dateilistenpfad verweist auf eine Textdatei im selben Datenspeicher, der eine Liste der Dateien enthält, die Sie kopieren möchten. Er enthält eine Datei pro Zeile mit dem relativen Pfad zu dem im Dataset konfigurierten Pfad. |
Beispiele für „recursive“ und „copyBehavior“
Dieser Abschnitt beschreibt das resultierende Verhalten des Kopiervorgangs für verschiedene Kombinationen von recursive- und copyBehavior-Werten.
| recursive | copyBehavior | Struktur des Quellordners | Resultierendes Ziel |
|---|---|---|---|
| true | preserveHierarchy | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der gleichen Struktur erstellt wie die Quelle: Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
| true | flattenHierarchy | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Automatisch generierter Name für Datei1 Automatisch generierter Name für Datei2 Automatisch generierter Name für Datei3 Automatisch generierter Name für Datei4 Automatisch generierter Name für Datei5 |
| true | mergeFiles | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Die Inhalte von Datei1 + Datei2 + Datei3 + Datei4 + Datei5 werden in einer Datei mit einem automatisch generierten Dateinamen zusammengeführt. |
| false | preserveHierarchy | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Datei1 Datei2 Unterordner1 mit Datei3, Datei4 und Datei5 wird nicht übernommen. |
| false | flattenHierarchy | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Automatisch generierter Name für Datei1 Automatisch generierter Name für Datei2 Unterordner1 mit Datei3, Datei4 und Datei5 wird nicht übernommen. |
| false | mergeFiles | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Die Inhalte von Datei1 + Datei2 werden in einer Datei mit einem automatisch generierten Dateinamen zusammengeführt. Automatisch generierter Name für Datei1 Unterordner1 mit Datei3, Datei4 und Datei5 wird nicht übernommen. |
Beibehalten von Metadaten beim Kopieren
Beim Kopieren von Dateien von Amazon S3, Azure Blob Storage oder Azure Data Lake Storage Gen2 nach Azure Data Lake Storage Gen2 oder Azure Blob Storage können Sie festlegen, dass die Dateimetadaten zusätzlich zu den Daten beibehalten werden sollen. Weitere Informationen finden Sie unter Beibehalten von Metadaten.
Eigenschaften von Mapping Data Flow
Wenn Sie Daten in Zuordnungsdatenflüsse transformieren, können Sie Dateien aus Azure Blob Storage in den folgenden Formaten lesen und schreiben:
Formatspezifische Einstellungen finden Sie in der Dokumentation für das jeweilige Format. Weitere Informationen finden Sie unter Quelltransformation in einem Zuordnungsdatenfluss und Senkentransformation in einem Zuordnungsdatenfluss.
Quellentransformation
Bei der Quelltransformation können Sie in Azure Blob Storage Daten aus einem Container, Ordner oder einer einzelnen Datei lesen. Über die Registerkarte Source options (Quellenoptionen) können Sie verwalten, wie die Dateien gelesen werden.
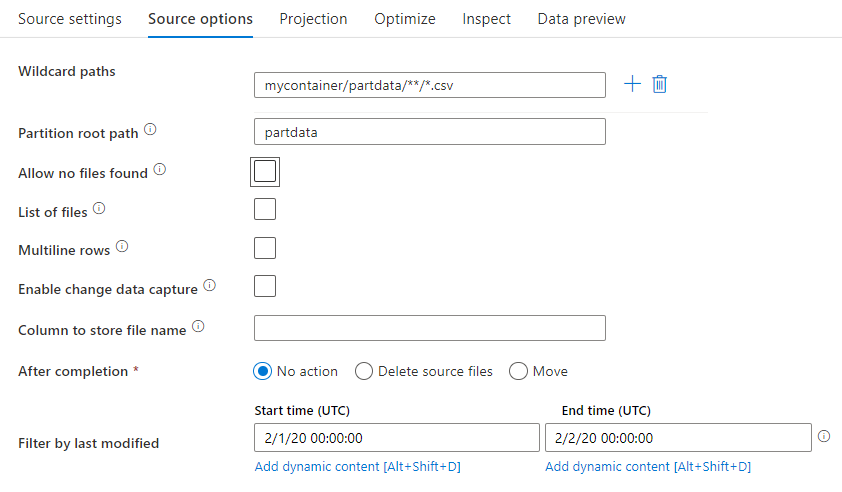
Platzhalterpfade: Mithilfe eines Platzhaltermusters wird der Dienst angewiesen, die einzelnen übereinstimmenden Ordner und Dateien in einer einzigen Quelltransformation zu durchlaufen. Dies ist eine effektive Methode zur Verarbeitung von mehreren Dateien in einem einzigen Datenfluss. Über das Pluszeichen (+), das angezeigt wird, wenn Sie mit dem Cursor auf Ihr vorhandenes Platzhaltermuster zeigen, können Sie weitere Platzhaltermuster hinzufügen.
Wählen Sie in Ihrem Quellcontainer eine Reihe von Dateien aus, die einem Muster entsprechen. Es kann nur ein Container im Dataset angegeben werden. Daher muss Ihr Platzhalterpfad auch den Ordnerpfad des Stammordners enthalten.
Beispiele für Platzhalter:
*: stellt eine beliebige Zeichenfolge dar**: stellt eine rekursive Verzeichnisschachtelung dar?: ersetzt ein Zeichen[]: stimmt mit mindestens einem Zeichen in den Klammern überein/data/sales/**/*.csv: ruft alle CSV-Dateien unter „/data/sales“ ab/data/sales/20??/**/: ruft alle Dateien aus dem 20. Jahrhundert ab/data/sales/*/*/*.csv: ruft CSV-Dateien auf zwei Ebenen unter „/data/sales“ ab/data/sales/2004/*/12/[XY]1?.csv: ruft alle CSV-Dateien von Dezember 2004 ab, die mit X oder Y und einer zweistelligen Zahl als Präfix beginnen
Partitionsstammpfad: Wenn Ihre Dateiquelle partitionierte Ordner mit dem Format key=value (z. B. year=2019) enthält, können Sie die oberste Ebene dieser Ordnerstruktur einem Spaltennamen im Datenstrom Ihres Datenflusses zuweisen.
Legen Sie zunächst einen Platzhalter fest, um darin alle Pfade, die die partitionierten Ordner sind, sowie die Blattdateien einzuschließen, die gelesen werden sollen.
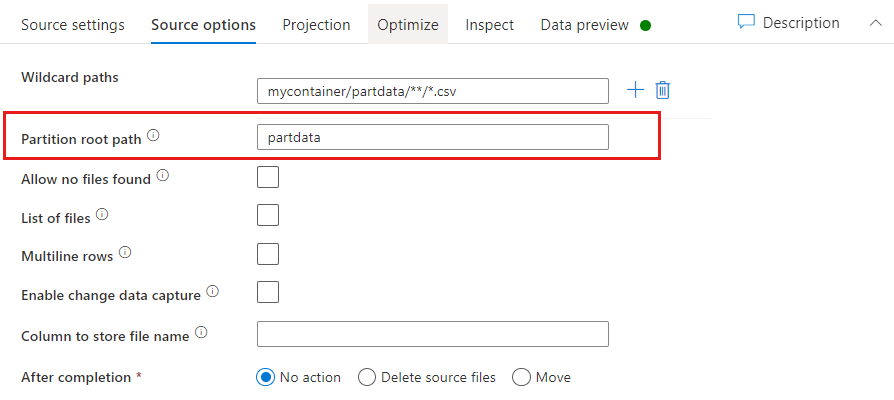
Verwenden Sie die Einstellung Partition root path (Partitionsstammpfad), um zu definieren, was die oberste Ebene der Ordnerstruktur ist. Wenn Sie die Inhalte Ihrer Daten über die Datenvorschau anzeigen, sehen Sie, dass der Dienst die aufgelösten Partitionen hinzufügt, die auf den einzelnen Ordnerebenen gefunden werden.
Liste der Dateien: Dies ist eine Dateigruppe. Erstellen Sie eine Textdatei mit einer Liste der relativen Pfade der zu verarbeitenden Dateien. Verweisen Sie auf diese Textdatei.
Spalte für die Speicherung im Dateinamen: Speichern Sie den Namen der Quelldatei in einer Spalte in den Daten. Geben Sie hier einen neuen Spaltennamen ein, um die Zeichenfolge für den Dateinamen zu speichern.
Nach der Fertigstellung: Wählen Sie aus, ob Sie nach dem Ausführen des Datenflusses nichts mit der Quelldatei anstellen, die Quelldatei löschen oder die Quelldateien verschieben möchten. Die Pfade für das Verschieben sind relative Pfade.
Um Quelldateien an einen anderen Speicherort nach der Verarbeitung zu verschieben, wählen Sie zuerst für den Dateivorgang die Option „Verschieben“ aus. Legen Sie dann das Quellverzeichnis („from“/„aus“) fest. Wenn Sie keine Platzhalter für Ihren Pfad verwenden, entspricht die Einstellung „from“ dem Quellordner.
Wenn Sie über einen Quellpfad mit Platzhalter verfügen, sieht Ihre Syntax wie folgt aus:
/data/sales/20??/**/*.csv
Geben Sie „from“ beispielsweise wie folgt an:
/data/sales
„To“ können Sie wie folgt angeben:
/backup/priorSales
In diesem Fall werden alle Dateien, die aus /data/sales erstellt wurden, in /backup/priorSales verschoben.
Hinweis
Die Dateivorgänge werden nur ausgeführt, wenn der Datenfluss anhand der Aktivität zum Ausführen des Datenflusses in einer Pipeline über eine Pipelineausführung ausgeführt wird (Debuggen der Pipeline oder Ausführung). Dateivorgänge werden nicht im Datenfluss-Debugmodus ausgeführt.
Nach der letzten Änderung filtern: Sie können einen Datumsbereich angeben, um die zu verarbeitenden Dateien nach der letzten Änderung zu filtern. Alle Datums-/Uhrzeitangaben erfolgen in UTC.
Change Data Capture aktivieren: Bei einer Festlegung auf TRUE erhalten Sie neue oder geänderte Dateien nur aus der letzten Ausführung. Das erste Laden der vollständigen Momentaufnahmedaten erfolgt immer bei der ersten Ausführung, gefolgt von der Erfassung neuer oder geänderter Dateien nur in den nächsten Ausführungen.
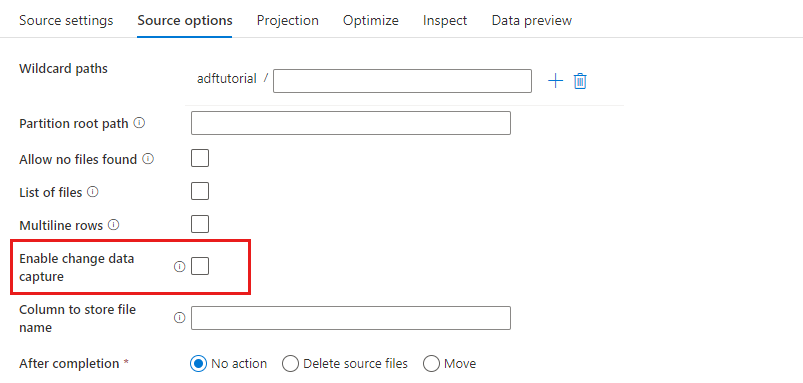
Senkeneigenschaften
In der Senkentransformation können Sie in Azure Blob Storage in einen Container oder Ordner schreiben. Über die Registerkarte Einstellungen können Sie verwalten, wie die Dateien geschrieben werden.

Ordner löschen: Bestimmt, ob der Zielordner vor dem Schreiben der Daten gelöscht wird.
Dateinamenoption: Bestimmt, wie die Zieldateien im Zielordner benannt werden. Es gibt folgende Dateinamenoptionen:
- Standard: Lassen Sie zu, dass Spark Dateien basierend auf den PART-Standards benennt.
- Muster: Geben Sie ein Muster ein, das Ihre Ausgabedateien pro Partition aufführt. Beispiel:
loans[n].csverstelltloans1.csv,loans2.csvusw. - Pro Partition: Geben Sie einen Dateinamen pro Partition ein.
- Wie Daten in Spalte: Legen Sie die Ausgabedatei auf den Wert einer Spalte fest. Der Pfad ist relativ zum Datasetcontainer und nicht zum Zielordner. Wenn Ihr Dataset einen Ordnerpfad enthält, wird er überschrieben.
- Ausgabe in eine einzelne Datei: Mit dieser Option werden die partitionierten Ausgabedateien in einer einzelnen Datei kombiniert. Der Pfad ist relativ zum Datasetordner. Bedenken Sie, dass der Zusammenführungsvorgang je nach Knotengröße zu Fehlern führen kann. Diese Option wird für große Datasets nicht empfohlen.
Alle in Anführungszeichen: bestimmt, ob alle Werte in Anführungszeichen stehen sollen.
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Eigenschaften der GetMetadata-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter GetMetadata-Aktivität.
Eigenschaften der Delete-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Delete-Aktivität.
Legacy-Modelle
Hinweis
Die folgenden Modelle werden aus Gründen der Abwärtskompatibilität weiterhin unverändert unterstützt. Es wird empfohlen, das oben erwähnte neue Modell zu verwenden. Die Erstellungsbenutzeroberfläche für die Erstellung ist zum Generieren des neuen Modells gewechselt.
Legacy-Datasetmodell
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft des Datasets muss auf AzureBlob festgelegt sein. |
Ja |
| folderPath | Der Pfad zum Container und Ordner in Blob Storage. Für den Pfad mit Ausnahme des Containernamens werden Platzhalterfilter unterstützt. Folgende Platzhalter sind zulässig: * (entspricht null [0] oder mehr Zeichen) und ? (entspricht null [0] oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr Ordnername einen Platzhalter oder dieses Escapezeichen enthält. Ein Beispiel ist myblobcontainer/myblobfolder/. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
„Ja“ für die Kopier- oder Suchaktivität, „Nein“ für die GetMetadata-Aktivität |
| fileName | Name oder Platzhalterfilter für die Blobs unter dem angegebenen Wert für folderPath. Wenn Sie für diese Eigenschaft keinen Wert angeben, zeigt das Dataset auf alle Blobs im Ordner. Für Filter sind folgende Platzhalter zulässig: * (entspricht null (0) oder mehr Zeichen) und ? (entspricht null (0) oder einem einzelnen Zeichen).- Beispiel 1: "fileName": "*.csv"- Beispiel 2: "fileName": "???20180427.txt"Verwenden Sie ^ als Escapezeichen, wenn der tatsächliche Dateiname einen Platzhalter oder dieses Escapezeichen enthält.Wenn fileName nicht für ein Ausgabedataset und preserveHierarchy nicht in der Aktivitätssenke angegeben ist, generiert die Kopieraktivität den Blobnamen automatisch mit dem folgenden Muster: Data.[GUID der Aktivitätsausführungs-ID].[GUID bei Verwendung von „FlattenHierarchy“].[Format, sofern konfiguriert].[Komprimierung, sofern konfiguriert] . Beispiel: „Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz“. Wenn Sie Daten aus einer Quelle im Tabellenformat kopieren und dabei anstelle einer Abfrage den Tabellennamen verwenden, lautet das Namensmuster [table name].[format].[compression if configured]. Beispiel: „MyTable.csv“. |
Nein |
| modifiedDatetimeStart | Die Dateien werden anhand des Attributs „Letzte Änderung“ gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format „2018-12-01T05:00:00Z“ angewandt. Hinweis: Die Aktivierung dieser Einstellung wirkt sich auf die Gesamtleistung der Datenverschiebung aus, wenn Sie große Dateimengen filtern möchten. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewendet wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEndNULL ist, werden die Dateien ausgewählt, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd den datetime-Wert aufweist, aber modifiedDatetimeStartNULL ist, werden die Dateien ausgewählt, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist. |
Nein |
| modifiedDatetimeEnd | Die Dateien werden anhand des Attributs „Letzte Änderung“ gefiltert. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format „2018-12-01T05:00:00Z“ angewandt. Hinweis: Die Aktivierung dieser Einstellung wirkt sich auf die Gesamtleistung der Datenverschiebung aus, wenn Sie große Dateimengen filtern möchten. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewendet wird. Wenn modifiedDatetimeStart einen datetime-Wert aufweist, aber modifiedDatetimeEndNULL ist, werden die Dateien ausgewählt, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd den datetime-Wert aufweist, aber modifiedDatetimeStartNULL ist, werden die Dateien ausgewählt, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist. |
Nein |
| format | Wenn Sie Dateien unverändert zwischen dateibasierten Speichern kopieren möchten (binäre Kopie), überspringen Sie den Formatabschnitt in den Definitionen der Eingabe- und Ausgabedatasets. Für das Analysieren oder Generieren von Dateien mit einem bestimmten Format werden die folgenden Dateiformattypen unterstützt: TextFormat, JsonFormat, AvroFormat, OrcFormat und ParquetFormat. Sie müssen die type-Eigenschaft unter format auf einen dieser Werte festlegen. Weitere Informationen finden Sie in den Abschnitten Textformat, JSON-Format, Avro-Format, Orc-Format und Parquet-Format. |
Nein (nur für Szenarien mit Binärkopien) |
| compression | Geben Sie den Typ und den Grad der Komprimierung für die Daten an. Weitere Informationen finden Sie unter Unterstützte Dateiformate und Codecs für die Komprimierung. Unterstützte Typen sind GZip, Deflate, BZIP2 und ZipDeflate. Unterstützte Grade sind Optimal und Schnellste. |
Nein |
Tipp
Um alle Blobs in einem Ordner zu kopieren, geben Sie nur folderPath an.
Sie können einen einzelnen Blob mit einem angegebenen Namen kopieren, indem Sie folderPath für den Ordner und fileName für den Dateinamen angeben.
Sie können eine Teilmenge der Blobs in einen Ordner kopieren, indem Sie folderPath für den Ordner und fileName für den Platzhalterfilter angeben.
Beispiel:
{
"name": "AzureBlobDataset",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Legacyquellmodell für die Kopieraktivität
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf BlobSource festgelegt werden. |
Ja |
| recursive | Gibt an, ob die Daten rekursiv aus den Unterordnern oder nur aus dem angegebenen Ordner gelesen werden. Wenn recursive auf true festgelegt ist und es sich bei der Senke um einen dateibasierten Speicher handelt, wird ein leerer Ordner oder Unterordner nicht in die Senke kopiert oder dort erstellt.Zulässige Werte sind true (Standard) und false. |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
Beispiel:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Blob input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "BlobSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Legacysenkenmodell für die Kopieraktivität
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Senke der Kopieraktivität muss auf BlobSink festgelegt werden. |
Ja |
| copyBehavior | Definiert das Kopierverhalten, wenn es sich bei der Quelle um Dateien aus einem dateibasierten Datenspeicher handelt. Zulässige Werte sind: - PreserveHierarchy (Standard): Behält die Dateihierarchie im Zielordner bei. Der relative Pfad der Quelldatei zum Quellordner entspricht dem relativen Pfad der Zieldatei zum Zielordner. - FlattenHierarchy: Alle Dateien aus dem Quellordner befinden sich auf der ersten Ebene des Zielordners. Die Namen für die Zieldateien werden automatisch generiert. - MergeFiles: Alle Dateien aus dem Quellordner werden in einer Datei zusammengeführt. Wenn der Datei- oder Blobname angegeben wurde, entspricht der Name der Zusammenführungsdatei dem angegebenen Namen. Andernfalls wird der Dateiname automatisch generiert. |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
Beispiel:
"activities":[
{
"name": "CopyToBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Blob output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "BlobSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Erfassung geänderter Daten
Azure Data Factory kann neue oder geänderte Dateien aus Azure Blob Storage nur abrufen, indem Sie in der Transformation für Zuordnungsdatenflussquellen **Change Data Capture aktivieren** aktivieren. Mit dieser Connectoroption können Sie nur neue oder aktualisierte Dateien lesen und Transformationen anwenden, bevor Sie transformierte Daten in Zieldatensets Ihrer Wahl laden. Details dazu finden Sie unter Change Data Capture.
.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die diese Kopieraktivität als Quellen und Senken unterstützt, finden Sie unter Unterstützte Datenspeicher.