Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Microsoft is one of the largest companies in the world to use Agile methodologies. Over years of experience, Microsoft has developed a DevOps planning process that scales from the smallest projects up through massive efforts like Windows. This article describes many of the lessons learned and practices Microsoft implements when planning software projects across the company.
The following key changes help make development and shipping cycles healthier and more efficient:
- Promote cultural alignment and autonomy.
- Change focus from individuals to teams.
- Create new planning and learning strategies.
- Implement a multi-crew model.
- Improve code health practices.
- Foster transparency and accountability.
Peter Drucker said, "Culture eats strategy for breakfast." Autonomy, mastery, and purpose are key human motivations. Microsoft tries to provide these motivators to PMs, developers, and designers so they feel empowered to build successful products.
Two important contributors to this approach are alignment and autonomy.
- Alignment comes from the top down, to ensure that individuals and teams understand how their responsibilities align with broader business goals.
- Autonomy happens from the bottom up, to ensure that individuals and teams have an impact on day-to-day activities and decisions.
There is a delicate balance between alignment and autonomy. Too much alignment can create a negative culture where people perform only as they're told. Too much autonomy can cause a lack of structure or direction, inefficient decision-making, and poor planning.
Microsoft organizes people and teams into three groups: PM, design, and engineering.
- PM defines what Microsoft builds, and why.
- Design is responsible for designing what Microsoft builds.
- Engineering builds the products and ensures their quality.
Microsoft teams have the following key characteristics:
- Cross-disciplinary
- 10-12 people
- Self-managing
- Clear charter and goals for 12-18 months
- Physical team rooms
- Own feature deployment
- Own features in production
Microsoft teams used to be horizontal, covering all UI, all data, or all APIs. Now, Microsoft strives for vertical teams. Teams own their areas of the product end-to-end. Strict guidelines in certain tiers ensure uniformity among teams across the product.
The following diagram conceptualizes the difference between horizontal and vertical teams:
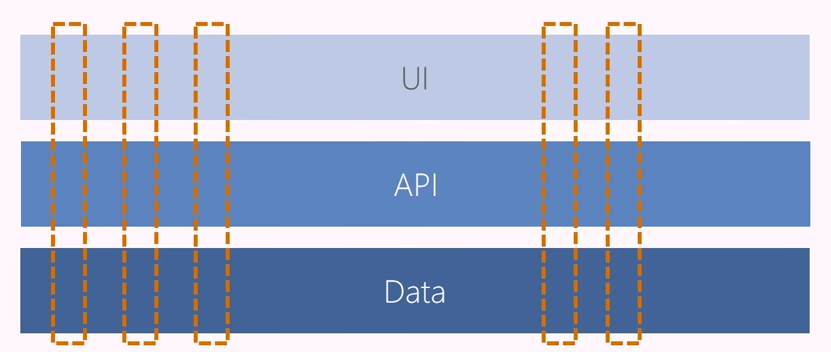
About every 18 months, Microsoft runs a "yellow sticky exercise," where developers can choose which areas of the product they want to work on for the next couple of planning periods. This exercise provides autonomy, as teams can choose what to work on, and organizational alignment, as it promotes balance among the teams. About 80% of the people in this exercise remain on their current teams, but they feel empowered because they had a choice.
Dwight Eisenhower said, "Plans are worthless, but planning is everything." Microsoft planning breaks down into the following structure:
- Sprints (3 weeks)
- Plans (3 sprints)
- Seasons (6 months)
- Strategies (12 months)
Engineers and teams are mostly responsible for sprints and plans. Leadership is primarily responsible for seasons and strategies.
The following diagram illustrates Microsoft planning strategy:

This planning structure also helps maximize learning while doing planning. Teams are able to get feedback, find out what customers want, and implement customer requests quickly and efficiently.
Previous methods fostered an "interrupt culture" of bugs and live site incidents. Microsoft teams came up with their own way to provide focus and avoid distractions. Teams self-organize for each sprint into two distinct crews: Features (F-crew) and Customer (C-crew).
The F-crew works on committed features, and the C-crew deals with live site issues and interruptions. The team establishes a rotating cadence that lets members plan activities more easily. For more information about the multi-crew model, see Build productive, customer focused teams.
Before switching to Agile methodologies, teams used to let code bugs build up until code was complete at the end of the development phase. Teams then discovered bugs and worked on fixing them. This practice created a roller coaster of bugs, which affected team morale and productivity when teams had to work on bug fixes instead of implementing new features.
Teams now implement a bug cap, calculated by the formula # of engineers x 5 = bug cap. If a team's bug count exceeds the bug cap at the end of a sprint, they must stop working on new features and fix bugs until they are under their cap. Teams now pay down bug debt as they go.
At the end of each sprint, every team sends a mail reporting what they've accomplished in the previous sprint, and what they plan to do in the next sprint.
Teams are most effective when they're clear on the goals the organization is trying to achieve. Microsoft provides clarity for teams through objectives and key results (OKRs).
- Objectives define the goals to achieve. Objectives are significant, concrete, action oriented, and ideally inspirational statements of intent. Objectives represent big ideas, not actual numbers.
- Key results define steps to achieve the objectives. Key results are quantifiable outcomes that evaluate progress and indicate success against objectives in a specific time period.
OKRs reflect the best possible results, not just the most probable results. Leaders try to be ambitious and not cautious. Pushing teams to pursue challenging key results drives acceleration against objectives and prioritizes work that moves towards larger goals.
Adopting an OKR framework can help teams perform better for the following reasons:
- Every team is aligned on the plan.
- Teams focus on achieving outcomes rather than completing activities.
- Every team is accountable for efforts on a regular basis.
OKRs might exist at different levels of a product. For example, there can be top-level product OKRs, component-level OKRs, and team-level OKRs. Keeping OKRs aligned is relatively easy, especially if objectives are set top-down. Any conflicts that arise are valuable early indicators of organizational misalignment.
Objective: Grow a strong and happy customer base.
Key results:
- Increase external net promoter score (NPS) from 21 to 35.
- Increase docs satisfaction from 55 to 65.
- New pipeline flow has an Apdex score of 0.9.
- Queue time for jobs is 5 seconds or less.
For more information about OKRs, see Measure business outcomes using objectives and key results.
Key results are only as useful as the metrics they're based on. Microsoft uses leading indicators that focus on change. Over time, these metrics build a working picture of product acceleration or deceleration. Microsoft often uses the following metrics:
- Change in monthly growth rate of adoption
- Change in performance
- Change in time to learn
- Change in frequency of incidents
Teams avoid metrics that don't accrue value toward objectives. While they may have certain uses, the following metrics aren't helpful for tracking progress toward objectives:
- Accuracy of original estimates
- Completed hours
- Lines of code
- Team capacity
- Team burndown
- Team velocity
- Number of bugs found
- Code coverage
The following table summarizes the changes Microsoft development teams made as they adopted Agile practices.
| Before | After |
|---|---|
| 4-6 month milestones | 3-week sprints |
| Horizontal teams | Vertical teams |
| Personal offices | Team rooms and remote work |
| Long planning cycles | Continual planning and learning |
| PM, Dev, and Test | PM, Design, and Engineering |
| Yearly customer engagement | Continual customer engagement |
| Feature branches | Everyone works in the main branch |
| 20+ person teams | 8-12 person teams |
| Secret roadmap | Publicly shared roadmap |
| Bug debt | Zero debt |
| 100-page spec documents | PowerPoint specs |
| Private repositories | Open source or InnerSource |
| Deep organization hierarchy | Flattened organization hierarchy |
| Install numbers define success | User satisfaction defines success |
| Features ship once a year | Features ship every sprint |
- Take Agile science seriously, but don't be overly prescriptive. Agile can become too strict. Let the Agile mindset and culture grow.
- Celebrate results, not activity. Deploying functionality outweighs lines of code.
- Ship at every sprint to establish a rhythm and cadence and find all the work that needs to be done.
- Build the culture you want to get the behavior you're looking for.