Tutorial: Creación de una canalización de datos de un extremo a otro para derivar información de ventas en Azure HDInsight
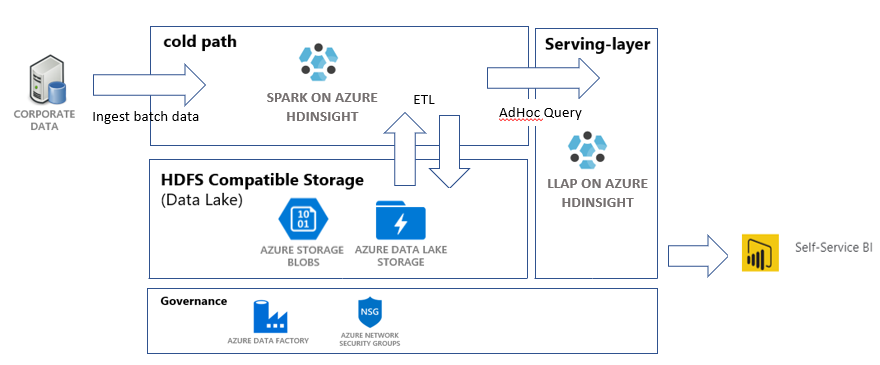
En este tutorial compilará una canalización de datos integral que realice operaciones de extracción, transformación y carga de datos (ETL). La canalización usará clústeres de Apache Spark y Apache Hive que se ejecutan en Azure HDInsight tanto para realizar consultas en los datos como para manipularlos. También usará tecnologías como Azure Data Lake Storage Gen2 para el almacenamiento de datos y Power BI para la visualización.
Esta canalización de datos combina los datos de varios almacenes, quita los datos no deseados, y anexa nuevos datos y los carga de nuevo en su almacenamiento para visualizar información empresarial. Consulte Extracción, transformación y carga de datos (ETL) a escala para más información sobre las canalizaciones ETL.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Prerrequisitos
CLI de Azure (2.2.0 como mínimo). Consulte Instalación de la CLI de Azure.
jq, un procesador JSON de línea de comandos. Vea https://stedolan.github.io/jq/.
Un miembro del rol integrado de Azure: propietario.
Si usa PowerShell para desencadenar la canalización de Data Factory, necesitará el módulo AZ.
Power BI Desktop para visualizar la información empresarial que aparece al final de este tutorial.
Crear recursos
Clonación del repositorio con scripts y datos
Inicie sesión en la suscripción de Azure. Si va a usar Azure Cloud Shell, seleccione Probar en la esquina superior derecha del bloque de código. En caso contrario, escriba el siguiente comando:
az login # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"Asegúrese de que es miembro del rol de Azure propietario. Reemplace
user@contoso.compor su cuenta y escriba el comando:az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"Si no se devuelve ningún registro, significa que no es miembro y, por consiguiente, no podrá realizar este tutorial.
Descargue los datos y scripts de este tutorial del repositorio de ETL de información de ventas de HDInsight. Escriba el comando siguiente:
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etlAsegúrese de que se han creado
salesdata scripts templates. Realice la comprobación con el comando siguiente:ls
Implementación de recursos de Azure necesarios para la canalización
Agregue permisos de ejecución para todos los scripts escribiendo:
chmod +x scripts/*.shEstablezca la variable para el grupo de recursos. Reemplace
RESOURCE_GROUP_NAMEpor el nombre de un grupo de recursos nuevo o existente y, a continuación, escriba el comando:RESOURCE_GROUP="RESOURCE_GROUP_NAME"Ejecute el script. Reemplace
LOCATIONpor el valor deseado y escriba el comando:./scripts/resources.sh $RESOURCE_GROUP LOCATIONSi no está seguro de qué región especificar, puede recuperar una lista de regiones admitidas para la suscripción con el comando az account list-locations.
El comando implementará los siguientes recursos:
- Una cuenta de Azure Blob Storage. Esta cuenta contendrá los datos de ventas de la empresa.
- Una cuenta de Azure Data Lake Storage Gen2. Esta cuenta servirá como cuenta de almacenamiento para ambos clústeres de HDInsight. Consulte Integración de Azure HDInsight con Data Lake Storage Gen2 para más información sobre HDInsight y Data Lake Storage Gen2.
- Una identidad administrada asignada por el usuario. Esta cuenta proporciona a los clústeres de HDInsight acceso a la cuenta de Data Lake Storage Gen2.
- Un clúster Apache Spark. Este clúster se usará para limpiar y transformar los datos sin procesar.
- Un clúster de Apache Hive Interactive Query. Este clúster permitirá consultar los datos de ventas y visualizarlos con Power BI.
- Una red virtual de Azure compatible con las reglas del grupo de seguridad de red (NSG). Esta red virtual permite a los clústeres comunicarse y proteger sus comunicaciones.
La creación del clúster puede tardar unos 20 minutos.
La contraseña predeterminada para el acceso SSH a los clústeres es Thisisapassword1. Si desea cambiar la contraseña, vaya al archivo ./templates/resourcesparameters_remainder.json y cámbiela para los parámetros sparksshPassword, sparkClusterLoginPassword, llapClusterLoginPassword y llapsshPassword.
Comprobación de la implementación y recopilación de información de recursos
Si desea comprobar el estado de la implementación, vaya al grupo de recursos en Azure Portal. En Configuración, seleccione Implementaciones y, a continuación, su implementación. Aquí puede ver los recursos que se han implementado correctamente y los que todavía están en curso.
Para ver los nombres de los clústeres, escriba el siguiente comando:
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAMEPara ver la cuenta de almacenamiento y la clave de acceso de Azure, escriba el siguiente comando:
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEYPara ver la cuenta de almacenamiento y la clave de acceso de Data Lake Storage Gen2, escriba el siguiente comando:
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
Crear una factoría de datos
Azure Data Factory es una herramienta que ayuda a automatizar Azure Pipelines. No es la única forma de realizar estas tareas, pero es una excelente manera de automatizar los procesos. Consulte la documentación de Azure Data Factory para más información sobre Azure Data Factory.
Esta factoría de datos tendrá una canalización con dos actividades:
- La primera actividad copiará los datos de Azure Blob Storage en la cuenta de almacenamiento de Data Lake Storage Gen 2 para simular la ingesta de datos.
- La segunda actividad transformará los datos en el clúster de Spark. El script transforma los datos al quitar las columnas no deseadas. También anexa una nueva columna que calcula los ingresos que genera una transacción.
Para configurar una canalización de Azure Data Factory, ejecute el siguiente comando. Todavía debería estar en el directorio hdinsight-sales-insights-etl.
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
El script hace lo siguiente:
- Crea una entidad de servicio con permisos de
Storage Blob Data Contributoren la cuenta de almacenamiento de Data Lake Storage Gen2. - Obtiene un token de autenticación para autorizar solicitudes POST a la API REST del sistema de archivos de Data Lake Storage Gen2.
- Rellena el nombre de la cuenta de almacenamiento de Data Lake Storage Gen2 en los archivos
sparktransform.pyyquery.hql. - Obtiene las claves de almacenamiento para las cuentas de Data Lake Storage Gen2 y Blob Storage.
- Crea otra implementación de recursos para crear una canalización de Azure Data Factory, con sus actividades y servicios vinculados asociados. Pasa las claves de almacenamiento como parámetros al archivo de plantilla para que los servicios vinculados puedan acceder a las cuentas de almacenamiento correctamente.
Ejecución de la canalización de datos
Desencadenador de las actividades de Data Factory
La primera actividad de la canalización de Data Factory que ha creado mueve los datos de Blob Storage a Data Lake Storage Gen2. La segunda actividad aplica las transformaciones de Spark a los datos y guarda los archivos CSV transformados en una nueva ubicación. La canalización puede tardar unos minutos en completarse.
Para recuperar el nombre de Data Factory, escriba el siguiente comando:
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
Para desencadenar la canalización, puede:
Desencadene la canalización de Data Factory en PowerShell. Reemplace
RESOURCEGROUPyDataFactoryNamepor los valores adecuados y, a continuación, ejecute los siguientes comandos:# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipelineVuelva a ejecutar
Get-AzDataFactoryV2PipelineRunsegún sea necesario para supervisar el progreso.Or
Abra la factoría de datos y seleccione Author & Monitor (Creación y supervisión). Desencadene la canalización
IngestAndTransformdesde el portal. Consulte Creación de clústeres de Apache Hadoop a petición en HDInsight mediante Azure Data Factory para más información sobre cómo desencadenar canalizaciones mediante el portal.
Para comprobar que se ha ejecutado la canalización, puede realizar uno de los pasos siguientes:
- Vaya a la sección Monitor (Supervisar) de la factoría de datos mediante el portal.
- En Explorador de Azure Storage, vaya a la cuenta de almacenamiento de Data Lake Storage Gen 2. Vaya al sistema de archivos
filesy a la carpetatransformed, y compruebe su contenido para ver si la canalización se ha realizado correctamente.
Consulte este artículo sobre el uso de Jupyter Notebook para otras maneras de transformar datos con HDInsight.
Creación de una tabla en el clúster de Interactive Query para ver datos en Power BI
Copie el archivo
query.hqlen el clúster de LLAP mediante SCP. Escriba el comando:LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net:/home/sshuser/Recordatorio: La contraseña predeterminada es
Thisisapassword1.Use SSH para acceder al clúster de LLAP. Escriba el comando:
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.netUse el siguiente comando para ejecutar el script:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hqlEste script creará una tabla administrada en el clúster de Interactive Query a la que puede acceder desde Power BI.
Creación de un panel de Power BI a partir de datos de ventas
Abra Power BI Desktop.
En el menú, vaya a Obtenga datos>Más...>Azure>HDInsight Interactive Query.
Seleccione Conectar.
En el cuadro de diálogo HDInsight Interactive Query:
- En el cuadro de texto Servidor, escriba el nombre del clúster de LLAP en el formato de
https://LLAPCLUSTERNAME.azurehdinsight.net. - En el cuadro de texto base de datos, escriba
default. - Seleccione Aceptar.
- En el cuadro de texto Servidor, escriba el nombre del clúster de LLAP en el formato de
En el cuadro de diálogo AzureHive:
- En el cuadro de texto Nombre de usuario, escriba
admin. - En el cuadro de texto Contraseña, escriba
Thisisapassword1. - Seleccione Conectar.
- En el cuadro de texto Nombre de usuario, escriba
En Navegador, seleccione
salesosales_rawpara obtener una vista previa de los datos. Una vez cargados los datos, puede experimentar con el panel que desee crear. Consulte los siguientes vínculos para ver una introducción a los paneles de Power BI:
Limpieza de recursos
Si no va a seguir usando esta aplicación, elimine todos los recursos asociados mediante el comando siguiente para que no se le facturen.
Para eliminar el grupo de recursos, escriba el comando:
az group delete -n $RESOURCE_GROUPPara eliminar la entidad de servicio, escriba los comandos:
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL