Configuración de la recuperación ante desastres para SQL Server
En este artículo se describe cómo ayudar a proteger el back-end de SQL Server de una aplicación. Para ello, use una combinación de las tecnologías de continuidad empresarial y recuperación ante desastres de SQL Server y Azure Site Recovery.
Antes de empezar, asegúrese de que comprende las funcionalidades de recuperación ante desastres de SQL Server. Estas son algunas de ellas:
- Clústeres de conmutación por error
- Grupos de disponibilidad AlwaysOn
- Creación de reflejo de la base de datos
- Trasvase de registros
- Replicación geográfica activa
- Grupos de conmutación por error automática
Combinación de tecnologías de BCDR con Site Recovery
La elección de una tecnología de BCDR para recuperar instancias de SQL Server debe basarse en los objetivos de tiempo de recuperación (RTO) y objetivos de punto de recuperación (RPO) que necesita, tal y como se describe en la tabla siguiente. Combine Site Recovery con la operación de conmutación por error de la tecnología elegida con el fin de coordinar la recuperación de toda la aplicación.
| Tipo de implementación | Tecnología de BCDR | RTO esperado para SQL Server | RPO esperado para SQL Server |
|---|---|---|---|
| SQL Server en una máquina virtual de infraestructura como servicio (IaaS) de Azure o en un entorno local. | Grupos de disponibilidad AlwaysOn | El tiempo necesario para convertir la réplica secundaria en principal. | Como la replicación a la réplica secundaria es asincrónica, se produce una pérdida de datos. |
| SQL Server en una máquina virtual IaaS de Azure o en un entorno local. | Clústeres de conmutación por error (FCI AlwaysOn) | El tiempo necesario para realizar la conmutación por error entre los nodos. | Como Always On FCI usa almacenamiento compartido, está disponible la misma vista de la instancia de almacenamiento en la conmutación por error. |
| SQL Server en una máquina virtual IaaS de Azure o en un entorno local. | Creación de reflejo (modo de alto rendimiento) | El tiempo necesario para forzar el servicio, que utiliza el servidor reflejado como servidor en espera semiactiva. | La replicación es asincrónica. La base de datos reflejada puede retrasarse un poco respecto a la base de datos principal. El retraso suele ser pequeño. Pero puede ser grande si el sistema de la entidad de seguridad o del servidor reflejado están sobrecargados. El trasvase de registros puede ser un complemento a la creación de reflejo de la base de datos. Es una alternativa favorable a la creación de reflejo de la base de datos asincrónica. |
| SQL como plataforma como servicio (PaaS) en Azure. Este tipo de implementación incluye las bases de datos únicas y los grupos elásticos. |
Replicación geográfica activa | 30 segundos después de que se desencadene la conmutación por error. Cuando se activa la conmutación por error a una de las bases de datos secundarias, las demás bases de datos secundarias se vinculan automáticamente a la nueva base de datos principal. |
RPO de cinco segundos. La replicación geográfica activa usa la tecnología Always On de SQL Server. Esta permite replicar de forma asincrónica las transacciones confirmadas en la base de datos principal a una base de datos secundaria mediante el aislamiento de instantánea. Se garantiza que los datos secundarios nunca tengan transacciones parciales. |
| SQL como PaaS configurado con replicación geográfica activa en Azure. Este tipo de implementación incluye instancias administradas, grupos elásticos y bases de datos únicas. |
Grupos de conmutación por error automática | RTO de una hora. | RPO de cinco segundos. Los grupos de conmutación por error automática proporcionan la semántica de grupo sobre la replicación geográfica activa. Pero se usa el mismo mecanismo de replicación asincrónico. |
| SQL Server en una máquina virtual IaaS de Azure o en un entorno local. | Replicación con Azure Site Recovery | El RTO es normalmente de menos de 15 minutos. Para más información, lea el contrato de nivel de servicio de RTO proporcionado por Site Recovery. | Una hora para la coherencia de la aplicación y cinco minutos para la coherencia de bloqueo. Si busca un RPO más bajo, use otras tecnologías BCDR. |
Nota:
Estas son algunas consideraciones importantes al proteger las cargas de trabajo SQL con Site Recovery:
- Site Recovery es independiente de la aplicación. Site Recovery puede ayudar a proteger cualquier versión de SQL Server que se implemente en un sistema operativo compatible. Para más información, consulte la matriz de compatibilidad para la recuperación de máquinas replicadas.
- Puede usar Site Recovery para cualquier implementación en Azure, Hyper-V, VMware o infraestructura física. Siga la guía al final de este artículo sobre cómo proteger un clúster de SQL Server con Site Recovery.
- Asegúrese de que la frecuencia de cambio de datos observada en la máquina está dentro de los límites de Site Recovery. La tasa de cambio se mide en bytes de escritura por segundo. En el caso de las máquinas que ejecutan Windows, puede ver esta tasa de cambio seleccionando la pestaña Rendimiento del administrador de tareas. Observe la velocidad de escritura de cada disco.
- Site Recovery admite la replicación de las instancias de clúster de conmutación por error en Espacios de almacenamiento directo. Para más información, consulte cómo habilitar la replicación de Espacios de almacenamiento directo.
Si se migra una carga de trabajo de SQL a Azure, se recomienda aplicar las directrices de rendimiento de SQL Server en Azure Virtual Machines.
Recuperación ante desastres de una aplicación
Site Recovery organiza la prueba de conmutación por error y la conmutación por error de toda la aplicación con la ayuda de los planes de recuperación.
Hay algunos requisitos previos para garantizar que el plan de recuperación está completamente personalizado en función de sus necesidades. Normalmente, las implementaciones de SQL Server necesitan una implementación de Active Directory. También es necesaria la conectividad de la capa de aplicación.
Paso 1: Configuración de Active Directory
Configure Active Directory en el sitio de recuperación secundario para que SQL Server se ejecute correctamente.
- Pequeña empresa: tiene un pequeño número de aplicaciones y un solo controlador de dominio para el sitio local. Si desea conmutar por error todo el sitio, utilice la replicación de Site Recovery. Este servicio replica el controlador de dominio en el centro de datos secundario o en Azure.
- Empresas medianas y grandes: Es posible que tenga que configurar controladores de dominio adicionales.
- si tiene un gran número de aplicaciones, un bosque de Active Directory y desea que la conmutación por error se realice por aplicaciones o cargas de trabajo, configure un controlador de dominio adicional en el centro de datos secundario o en Azure.
- Si usa grupos de disponibilidad AlwaysOn para recuperar en un sitio remoto, configure otro controlador de dominio adicional en el sitio secundario o en Azure. Este controlador de dominio se utilizará para la instancia de SQL Server recuperada.
Las instrucciones de este artículo dan por supuesto que un controlador de dominio está disponible en la ubicación secundaria. Para más información, consulte los procedimientos para ayudar a proteger Active Directory con Site Recovery.
Paso 2: Garantizar la conectividad con otros niveles
Una vez que el nivel de base de datos está en marcha en la región de Azure de destino, asegúrese de que tiene conectividad con la aplicación y los niveles web. Siga los pasos necesarios de antemano con el fin de validar la conectividad con la conmutación por error de prueba.
Para comprender cómo puede diseñar aplicaciones para las consideraciones de conectividad, consulte estos ejemplos:
- Diseño de una aplicación para la recuperación ante desastres en la nube
- Estrategias de recuperación ante desastres de grupos elásticos
Paso 3: Interoperar con Always On, replicación geográfica activa y grupos de conmutación por error automática
Las tecnologías de BCDR de Always On, la replicación geográfica activa y los grupos de conmutación por error automática tienen réplicas secundarias de SQL Server que se ejecutan en la región de Azure de destino. El primer paso para la conmutación por error de la aplicación es especificar esta réplica como principal. En este paso se supone que ya tiene un controlador de dominio en el sitio secundario. Puede que este paso no sea necesario si elige realizar una conmutación por error automática. Solo una vez completada la conmutación por error de la base de datos, debe realizar la conmutación por error de las capas de aplicación o los niveles web.
Nota:
Si ha protegido las máquinas de SQL con Site Recovery, basta crear un grupo de recuperación de estas máquinas y agregar la conmutación por error en el plan de recuperación.
Cree un plan de recuperación con máquinas virtuales del nivel web y de aplicación. En los pasos siguientes se muestra cómo agregar la conmutación por error del nivel de base de datos:
Importe los scripts para conmutar por error grupos de disponibilidad de SQL en una máquina virtual de Resource Manager y una máquina virtual clásica. Importe los scripts en su cuenta de Azure Automation.

Agregue el script ASR-SQL-FailoverAG como acción previa del primer grupo del plan de recuperación.
Siga las instrucciones disponibles en el script para crear una variable de automatización. Esta variable proporciona el nombre de los grupos de disponibilidad.
Paso 4: realización de una prueba de conmutación por error.
Algunas tecnologías de BCDR, como SQL Always On, no admiten de forma nativa la conmutación por error de prueba. Se recomienda el siguiente enfoque solo al usar estas tecnologías.
Configure Azure Backup en la máquina virtual que hospeda la réplica del grupo de disponibilidad en Azure.
Antes de desencadenar la conmutación por error del plan de recuperación, recupere la máquina virtual a partir de la copia de seguridad realizada en el paso anterior.
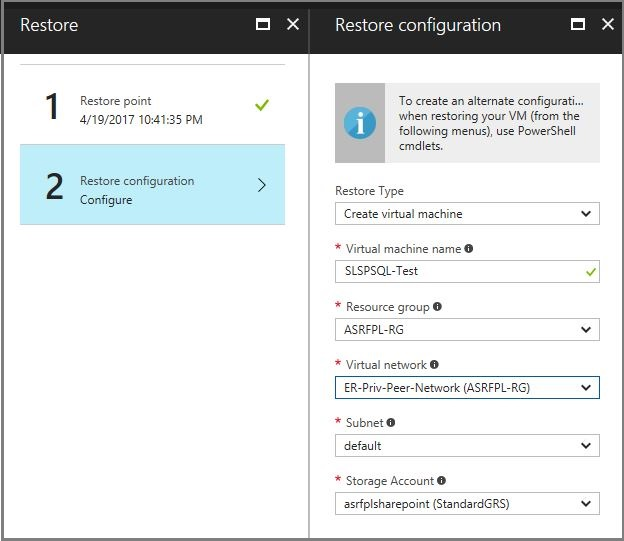
Fuerce un quórum en la máquina virtual que se restauró desde la copia de seguridad.
Actualice la dirección IP del cliente de escucha para que sea una dirección IP disponible en la red de conmutación por error de prueba.

Ponga el agente de escucha en línea.
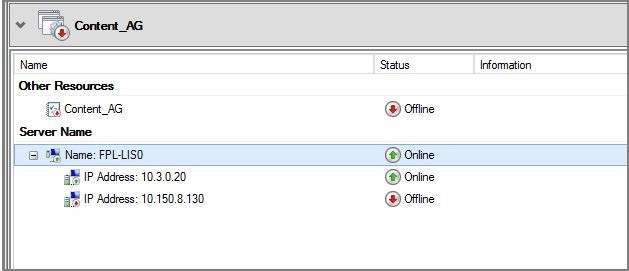
Asegúrese de que el equilibrador de carga de la red de conmutación por error tiene una dirección IP del grupo de direcciones IP de front-end que corresponde a cada agente de escucha del grupo de disponibilidad y con la máquina virtual de SQL Server en el grupo de back-end.
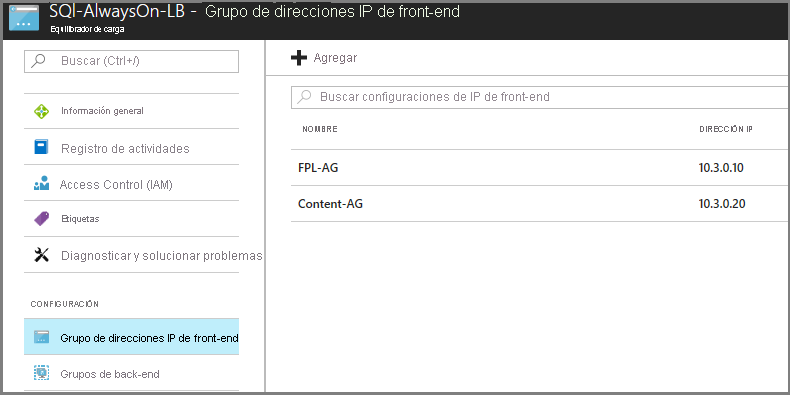
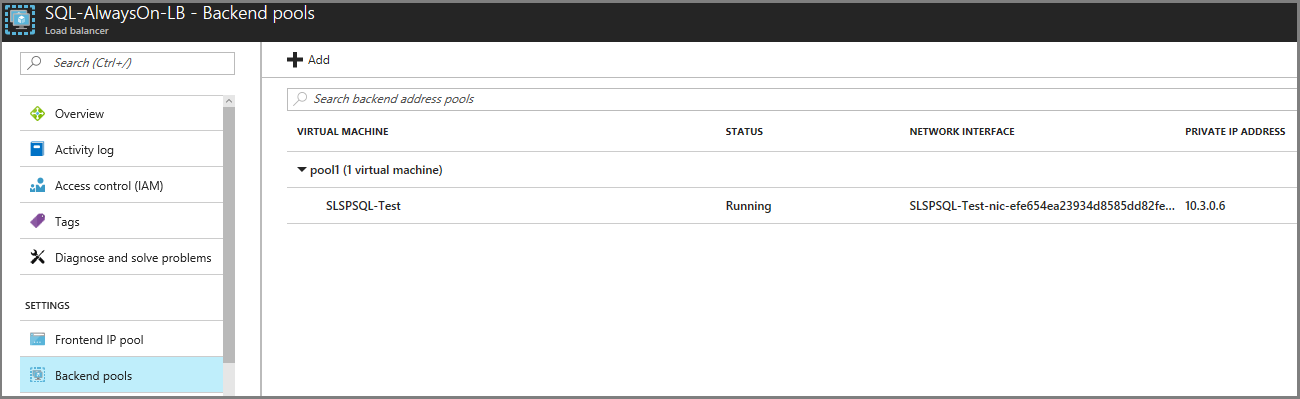
En grupos de recuperación posteriores, agregue conmutación por error de la capa de aplicación, seguida del nivel web de este plan de recuperación.
Realice una prueba de conmutación por error del plan de recuperación para probar la conmutación por error de un extremo a otro de la aplicación.
Pasos para realizar una conmutación por error
Después de agregar el script al paso 3 y validarlo en el paso 4, puede realizar una conmutación por error del plan de recuperación creado en el paso 3.
Los pasos de la conmutación por error para las capas de aplicación y los niveles de web deben ser los mismos en la conmutación por error de prueba y los planes de recuperación de conmutación por error.
Protección de un clúster de SQL Server
Para un clúster que ejecuta SQL Server Standard Edition o SQL Server 2008 R2, se recomienda utilizar la replicación de Site Recovery para ayudar a proteger SQL Server.
Azure en Azure y local en Azure
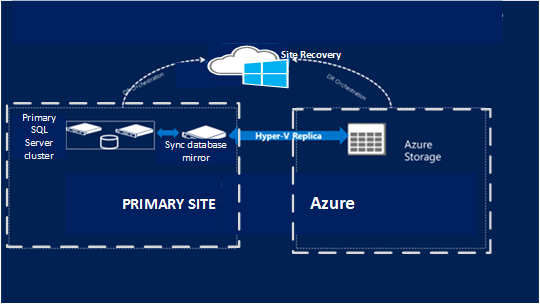
Site Recovery no proporciona la compatibilidad con clústeres invitados al replicar en una región de Azure. La edición SQL Server Standard tampoco proporciona una solución de recuperación ante desastres de bajo costo. En este escenario, se recomienda proteger el clúster de SQL Server en una instancia de SQL Server independiente en una ubicación principal y recuperarlo en la ubicación secundaria.
Configure otra instancia de SQL Server independiente en la región de Azure principal o en el sitio local.
Configure esta instancia para actuar como un reflejo para las bases de datos que desea proteger. Configure el reflejo en modo de alta seguridad.
Configure Site Recovery en el sitio principal para Azure, Hyper-V o máquinas virtuales y servidores físicos de VMware.
Utilice la replicación de Site Recovery para replicar la nueva instancia de SQL Server en el sitio secundario. Como es una copia de alta seguridad de reflejo, se sincroniza con el clúster principal, pero se replicará con la replicación de Site Recovery.
Consideraciones de la conmutación por recuperación
Para los clústeres de SQL Server Standard, la conmutación por recuperación después de una conmutación por error no planeada requiere una copia de seguridad y restauración de SQL Server. Esta operación se realiza desde la instancia reflejada en el clúster original con el restablecimiento del reflejo.
Preguntas más frecuentes
¿Cómo se obtiene una licencia de SQL Server cuando se usa con Site Recovery?
La replicación de Site Recovery para SQL Server está incluida en el beneficio de recuperación ante desastres de Software Assurance. Esta cobertura se aplica a todos los escenarios de Site Recovery: desde instalaciones locales a recuperación ante desastres de Azure y recuperación ante desastres de IaaS de Azure entre regiones. Consulte Precios de Azure Site Recovery para más información.
¿Admitirá Site Recovery mi nueva versión de SQL Server?
Site Recovery es independiente de la aplicación. Site Recovery puede ayudar a proteger cualquier versión de SQL Server que se implemente en un sistema operativo compatible. Para más información, consulte la matriz de compatibilidad para la recuperación de máquinas replicadas.
¿Funciona ASR con la replicación transaccional de SQL?
Debido a que ASR utiliza la copia a nivel de archivo, SQL no puede garantizar que los servidores de una topología de replicación SQL asociada estén sincronizados en el momento de la conmutación por error de ASR. Esto puede hacer que el lector de registros o los agentes de distribución produzcan un error debido a un error de coincidencia de LSN, lo que puede interrumpir la replicación. Si produce una conmutación por error del publicador, distribuidor o suscriptor en una topología de replicación, es necesario volver a generar la replicación. Se recomienda reinicializar la suscripción a SQL Server.
Pasos siguientes
- Más información acerca de la arquitectura de Site Recovery.
- Para SQL Server en Azure, obtenga más información sobre las soluciones de alta disponibilidad para la recuperación en una región secundaria de Azure.
- Para SQL Database, obtenga más información sobre las opciones de continuidad del negocio y alta disponibilidad para la recuperación en una región secundaria de Azure.
- Para máquinas SQL Server en el entorno local, obtenga más información acerca de las opciones de alta disponibilidad para la recuperación en Azure Virtual Machines.