Cet article décrit comment créer un service de recherche qui permet aux utilisateurs d’effectuer des recherches de documents à partir de leur contenu et de toutes les métadonnées associées aux fichiers.
Vous pouvez implémenter ce service en utilisant plusieurs indexeurs dans le service Recherche Azure AI.
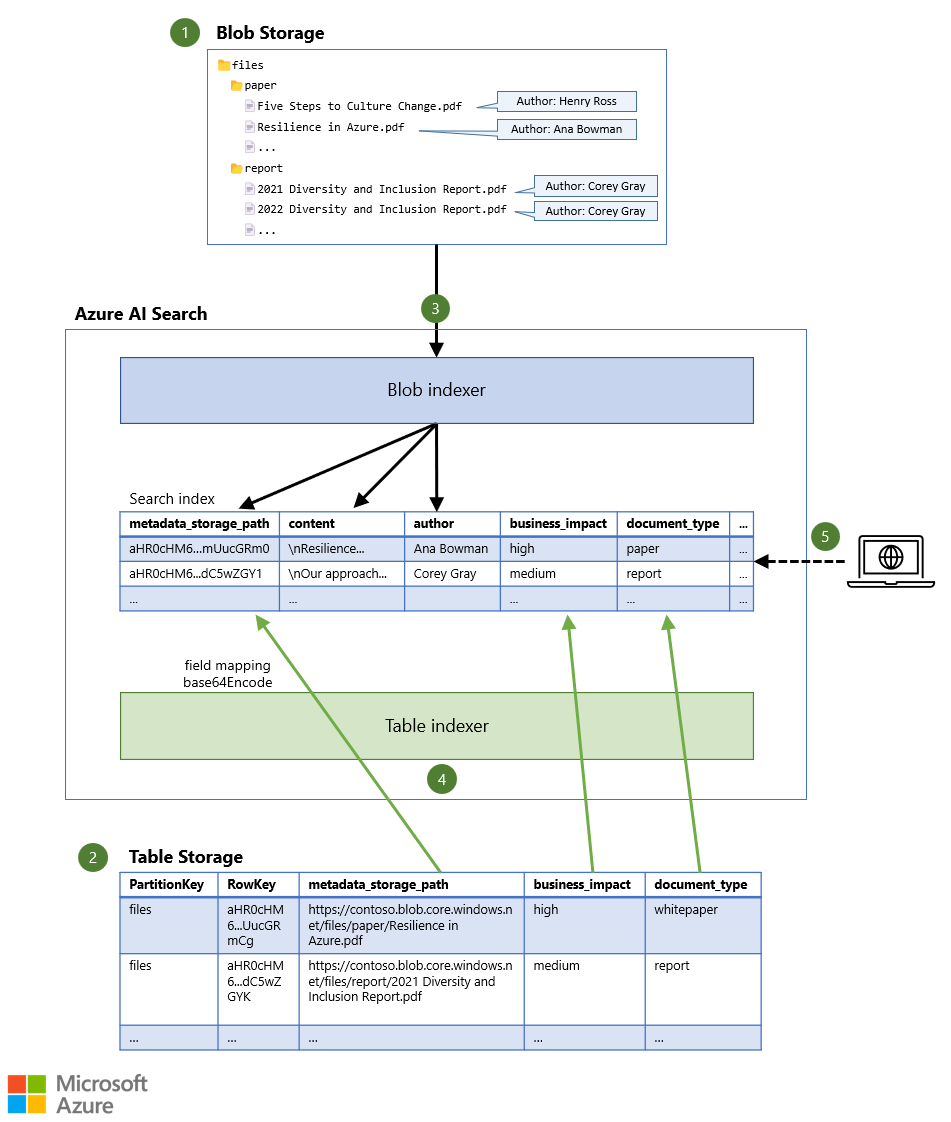
Cet article utilise un exemple de charge de travail pour indiquer comment créer index de recherche unique basé sur des fichiers dans le service Stockage Blob Azure. Les métadonnées du fichier sont stockées dans Stockage Table Azure.
Architecture
Téléchargez un fichier PowerPoint de cette architecture.
Dataflow
- Les fichiers sont stockés dans le stockage Blob, éventuellement accompagnés d’un nombre limité de métadonnées (par exemple, l’auteur du document).
- Des métadonnées supplémentaires sont stockées dans le Stockage Table, qui peut contenir beaucoup plus d’informations pour chaque document.
- Un indexeur lit le contenu de chaque fichier, ainsi que les métadonnées d’objet blob, et stocke les données dans l’index de recherche.
- Un autre indexeur lit les métadonnées supplémentaires de la table et les stocke dans le même index de recherche.
- Une requête de recherche est envoyée au service de recherche. La requête renvoie les documents correspondants, en fonction du contenu et des métadonnées du document.
Composants
- Le stockage Blob fournit un stockage cloud économique pour les données de fichiers, y compris les données dans des formats tels que PDF, HTML et CSV, et dans les fichiers Microsoft 365.
- Le Stockage Table fournit un stockage pour les données structurées non relationnelles. Dans ce scénario, il est utilisé pour stocker les métadonnées de chaque document.
- Recherche Azure AI est un service de recherche entièrement géré qui fournit une infrastructure, des API et des outils pour créer une expérience de recherche enrichie.
Autres solutions
Ce scénario utilise des indexeurs dans le service Recherche Azure AI pour découvrir automatiquement le nouveau contenu dans les sources de données prises en charge, comme le stockage d’objets blob et de table, puis l’ajouter à l’index de recherche. Vous pouvez également utiliser les API fournies par Recherche Azure AI pour envoyer des données à l’index de recherche. Toutefois, si vous le faites, vous devez écrire du code pour envoyer (push) les données dans l’index de recherche, ainsi que pour analyser et extraire du texte des documents binaires que vous souhaitez rechercher. L’indexeur de stockage d’objets blob prend en charge de nombreux formats de documents, ce qui simplifie considérablement le processus d’extraction et d’indexation du texte.
En outre, si vous utilisez des indexeurs, vous pouvez éventuellement enrichir les données dans le cadre d’un pipeline d’indexation. Par exemple, vous pouvez utiliser Azure AI Services pour effectuer la reconnaissance optique de caractères (OCR) ou l’analyse visuelle des images dans les documents, détecter la langue des documents ou traduire des documents. Vous pouvez également définir vos propres compétences personnalisées pour enrichir les données de manière pertinente pour votre scénario d’entreprise.
Cette architecture utilise le stockage d’objets blob et de table parce qu’ils sont rentables et efficaces. Cette conception permet également de combiner le stockage des documents et des métadonnées dans un seul compte de stockage. Les autres sources de données prises en charge pour les documents eux-mêmes comprennent Azure Data Lake Storage et Azure Files. Les métadonnées des documents peuvent être stockées dans toute autre source de données prise en charge qui contient des données structurées, comme Azure SQL Database et Azure Cosmos DB.
Détails du scénario
Recherche dans le contenu des fichiers
Cette solution permet aux utilisateurs de rechercher des documents en se basant à la fois sur le contenu du fichier et sur des métadonnées supplémentaires stockées séparément pour chaque document. En plus de rechercher le contenu textuel d’un document, un utilisateur peut souhaiter rechercher l’auteur du document, le type de document (commeun article ou un rapport) ou son impact sur l’entreprise (élevé, moyen ou faible).
Recherche Azure AI est un service de recherche complètement managé qui peut créer des index de recherche contenant les informations que souhaitez permettre aux utilisateurs de rechercher.
Étant donné que les fichiers recherchés dans ce scénario sont des documents binaires, vous pouvez les stocker dans le stockage Blob. Dans ce cas, vous pouvez utiliser l’indexeur de stockage d’objets blob intégré au service Recherche Azure AI pour extraire automatiquement le texte des fichiers et ajouter leur contenu à l’index de recherche.
Recherche dans les métadonnées de fichiers
Si vous souhaitez inclure des informations supplémentaires sur les fichiers, vous pouvez associer directement des métadonnées aux objets blob, sans utiliser de magasin distinct. L’indexeur de recherche de stockage Blob intégré peut même lire ces métadonnées et les placer dans l’index de recherche. Cela permet aux utilisateurs de rechercher des métadonnées en même temps que le contenu du fichier. Toutefois, la quantité de métadonnées étant limitée à 8 Ko par objet blob, la quantité d’informations que vous pouvez placer sur chaque objet blob est relativement faible. Vous pouvez choisir de stocker uniquement les informations les plus critiques directement sur les objets blob. Dans ce scénario, seul l’auteur du document est stocké dans l’objet blob.
Pour surmonter cette limitation de stockage, vous pouvez placer des métadonnées supplémentaires dans une autre source de données qui dispose d’un indexeur pris en charge, comme le Stockage Table. Vous pouvez ajouter le type de document, l’impact sur l’entreprise et d’autres valeurs de métadonnées en tant que colonnes distinctes dans la table. Si vous configurez l’indexeur de Stockage Table intégré pour cibler le même index de recherche que l’indexeur d’objets blob, les métadonnées de stockage d’objets blob et de table sont combinées pour chaque document dans l’index de recherche.
Utilisation de plusieurs sources de données pour un seul index de recherche
Pour vous assurer que les deux indexeurs pointent vers le même document dans l’index de recherche, la clé du document dans l’index de recherche est définie comme un identificateur unique du fichier. Cet identificateur unique est ensuite utilisé pour faire référence au fichier dans les deux sources de données. Par défaut, l’indexeur d’objets blob utilise le metadata_storage_path comme clé du document. La propriété metadata_storage_path stocke l’URL complète du fichier dans le stockage Blob, par exemple. https://contoso.blob.core.windows.net/files/paper/Resilience in Azure.pdf L’indexeur effectue un encodage Base64 sur la valeur pour s’assurer qu’il n’y a pas de caractères invalides dans la clé du document. Le résultat est une clé de document unique, comme aHR0cHM6...mUucGRm0.
Si vous ajoutez le metadata_storage_path en tant que colonne dans le Stockage Table, vous savez exactement à quel objet blob appartiennent les métadonnées des autres colonnes. Vous pouvez donc utiliser n’importe quelle valeur PartitionKey et RowKey dans la table. Par exemple, vous pouvez utiliser le nom du conteneur d’objets blob comme PartitionKey et l’URL complète encodée en Base64 de l’objet blob en tant que RowKey, tout en veillant à ce qu’il n’y ait aucun caractère non valide dans ces clés.
Vous pouvez ensuite utiliser un mappage de champs dans l’indexeur de table pour mapper la colonne metadata_storage_path (ou une autre colonne) dans le Stockage Table avec le champ clé du document metadata_storage_path dans l’index de recherche. Si vous appliquez la fonction base64Encode sur le mappage de champs, vous obtenez la même clé de document (aHR0cHM6...mUucGRm0 dans l’exemple précédent) et les métadonnées du Stockage Table sont ajoutées au même document qui a été extrait du stockage Blob.
Notes
La documentation de l’indexeur de table indique que vous ne devez pas définir un mappage de champ vers un champ de chaîne unique alternatif dans votre table. Cela est dû au fait que l’indexeur concatène par défaut le PartitionKey et le RowKey en tant que clé du document. Étant donné que vous vous appuyez déjà sur la clé de document telle que configurée par l’indexeur d’objets blob (qui est l’URL complète encodée en Base64 de l’objet blob), la création d’un mappage de champs pour vous assurer que les deux indexeurs font référence au même document dans l’index de recherche est appropriée et prise en charge pour ce scénario.
Vous pouvez également mapper directement le RowKey (qui est défini sur l’URL complète encodée en Base64 de l’objet blob) à la clé de document metadata_storage_path, sans la stocker séparément et l’encoder en Base64 dans le cadre du mappage de champs. Toutefois, le fait de conserver l’URL non codée dans une colonne distincte permet de clarifier l’objet blob auquel elle fait référence et de choisir librement les clés de partition et de ligne sans affecter l’indexeur de recherche.
Cas d’usage potentiels
Ce scénario s’applique aux applications qui nécessitent la possibilité de rechercher des documents en fonction de leur contenu et de métadonnées supplémentaires.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework, un ensemble de principes directeurs que vous pouvez utiliser pour améliorer la qualité d’une charge de travail. Pour plus d'informations, consultez Microsoft Azure Well-Architected Framework.
Fiabilité
La fiabilité permet de s’assurer que votre application tient vos engagements auprès de vos clients. Pour plus d’informations, consultez la page Vue d’ensemble du pilier de fiabilité.
Recherche Azure AI fournit un contrat de niveau de service (SLA) élevé pour les lectures (requêtes) si vous avez au moins deux réplicas. Il fournit un contrat SLA élevé pour les mises à jour (mise à jour des index de recherche) si vous avez au moins trois réplicas. Vous devez donc approvisionner au moins deux réplicas si vous voulez que vos utilisateurs puissent effectuer des recherches fiables, et trois si les modifications apportées à l’index doivent également faire l’objet d’opérations à haute disponibilité.
Le stockage Azure stocke toujours plusieurs copies de vos données afin de les protéger contre les événements planifiés et non planifiés. Le stockage Azure offre des options de redondance supplémentaires pour la réplication des données entre les régions. Ces mesures de protection s’appliquent aux données dans le stockage d’objets blob et de table.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour plus d’informations, consultez Vue d’ensemble du pilier Sécurité.
Recherche Azure AI fournit des contrôles de sécurité robustes qui vous aident à implémenter la sécurité réseau, l’authentification et l’autorisation, la résidence et la protection des données, ainsi que des contrôles administratifs qui vous aident à maintenir la sécurité, la confidentialité et la conformité.
Dans la mesure du possible, utilisez l'authentification Microsoft Entra pour fournir l'accès au service de recherche lui-même et connectez votre service de recherche à d'autres ressources Azure (comme le stockage d'objets blob et de table dans ce scénario) à l'aide d'une identité managée.
Vous pouvez vous connecter au compte de stockage à partir du service de recherche à l’aide d’un point de terminaison privé. Lorsque vous utilisez un point de terminaison privé, les indexeurs peuvent utiliser une connexion privée sans exiger que le stockage d’objets blob et de table soit accessible publiquement.
Optimisation des coûts
L’optimisation des coûts consiste à réduire les dépenses inutiles et à améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Pour plus d’informations sur les coûts d’exécution de ce scénario, consultez cette estimation préconfigurée dans la calculatrice de prix Azure. Tous les services décrits ici sont configurés dans cette estimation. L’estimation concerne une charge de travail dont la taille totale du document est de 20 Go dans le stockage Blob et de 1 Go de métadonnées dans le Stockage Table. Deux unités de recherche sont utilisées pour satisfaire le contrat SLA à des fins de lecture, comme décrit dans la section Fiabilité de cet article. Pour pouvoir observer l’évolution de la tarification pour votre cas d’usage particulier, modifiez les variables appropriées pour qu’elles correspondent à l’utilisation que vous prévoyez.
Si vous passez en revue l’estimation, vous pouvez constater que le coût du stockage d’objets blob et de table est relativement faible. La majeure partie du coût est liée à Recherche Azure AI, qui effectue l’indexation et le calcul nécessaires à l’exécution des requêtes de recherche.
Déployer ce scénario
Pour déployer cet exemple de charge de travail, consultez Indexation du contenu et des métadonnées des fichiers dans Recherche Azure AI. Vous pouvez utiliser cet échantillon pour :
- Créer les services Azure nécessaires.
- Charger quelques exemples de documents vers le stockage Blob.
- Renseigner la valeur des métadonnées de l’auteur sur l’objet blob.
- Stocker le type de document et les valeurs de métadonnées qui ont un impact sur l’entreprise dans Stockage Table.
- Créer les indexeurs qui gèrent l’index de recherche.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Jelle Druyts | Ingénieur principal de l’expérience client
Autre contributeur :
- Mick Alberts | Rédacteur technique
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Prise en main de Recherche Azure AI
- Améliorer la pertinence grâce à la recherche sémantique dans Recherche Azure AI
- Filtres de sécurité pour le filtrage des résultats dans Recherche Azure AI
- Tutoriel : Indexer à partir de plusieurs sources de données à l’aide du SDK .NET