Concepts Kubernetes de base pour Azure Kubernetes Service
Le développement d’applications continue à évoluer vers une approche basée sur les conteneurs, ce qui augmente le besoin d’orchestrer et de gérer les ressources. En tant que plateforme de pointe, Kubernetes offre une planification fiable des charges de travail d’application tolérantes aux pannes. AKS (Azure Kubernetes Service) est une offre Kubernetes managés qui simplifie la gestion et le déploiement des applications basées sur les conteneurs.
Cet article présente les concepts de base suivants :
Composants de l’infrastructure Kubernetes :
- Plan de contrôle
- Nœuds
- Pools de nœuds
Ressources de la charge de travail :
- Pods
- deployments
- Jeux
Regroupement de ressources à l’aide d’espaces de noms.
Présentation de Kubernetes
Kubernetes est une plateforme évoluant rapidement qui gère les applications basées sur les conteneurs, ainsi que leurs composants de mise en réseau et de stockage. Kubernetes se concentre sur les charges de travail d’application, pas sur les composants de l’infrastructure sous-jacente. Kubernetes fournit une approche déclarative des déploiements, assortie d’un ensemble robuste d’API pour les opérations de gestion.
Vous pouvez générer et exécuter des applications modernes, portables et basées sur des microservices avec l’orchestration et la gestion par Kubernetes de la disponibilité des composants d’application. Kubernetes prend en charge les applications sans état et avec état à mesure que les équipes adoptent les applications basées sur des microservices.
En tant que plateforme ouverte, Kubernetes vous permet de créer des applications avec vos langages de programmation, système d’exploitation, bibliothèques ou bus de messagerie préférés. Les outils d’intégration et de livraison continues (CI/CD) existants peuvent s’intégrer à Kubernetes dans le cadre de la planification et du déploiement de versions.
AKS fournit un service Kubernetes géré qui réduit la complexité des tâches de déploiement et de gestion de base, comme la coordination de la mise à niveau. La plateforme Azure gère le plan de contrôle AKS et vous ne payez que pour les nœuds AKS qui exécutent vos applications.
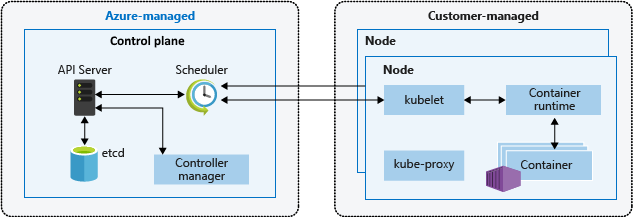
Architecture d’un cluster Kubernetes
Un cluster Kubernetes comprend deux composants :
- Plan de contrôle : fournit les services Kubernetes de base et l’orchestration des charges de travail d’applications.
- Nœuds : exécutent vos charges de travail d’application.
Plan de contrôle
Quand vous créez un cluster AKS, un plan de contrôle est automatiquement créé et configuré. Ce plan de contrôle est fourni gratuitement en tant que ressource Azure managée tirée de l’utilisateur. Vous payez uniquement pour les nœuds attachés au cluster AKS. Le plan de contrôle et ses ressources se trouvent uniquement sur la région dans laquelle le cluster a été créé.
Le plan de contrôle inclut les composants Kubernetes principaux suivants :
| Composant | Description |
|---|---|
| kube-apiserver | Le serveur d’API détermine comment les API Kubernetes sous-jacentes sont exposées. Ce composant fournit l’interaction des outils de gestion, tels que kubectl ou le tableau de bord Kubernetes. |
| etcd | Pour maintenir l’état de la configuration et du cluster Kubernetes, le composant etcd hautement disponible est un magasin de valeurs essentiel dans Kubernetes. |
| kube-scheduler | Quand vous créez ou mettez à l’échelle des applications, le planificateur détermine les nœuds pouvant exécuter la charge de travail et les démarre. |
| kube-controller-manager | Le gestionnaire de contrôleurs surveille une série de contrôleurs plus petits qui effectuent des actions comme la réplication des pods et la gestion des opérations sur les nœuds. |
AKS fournit un plan de contrôle monolocataire doté de dispositifs dédiés (serveur d’API, Scheduler, etc.). Vous définissez le nombre et la taille des nœuds, puis la plateforme Azure configure la communication sécurisée entre les nœuds et le plan de contrôle. L’interaction avec le plan de contrôle se produit par le biais d’API Kubernetes, telles que kubectl ou le tableau de bord Kubernetes.
Vous n’avez pas besoin de configurer des composants tels qu’un magasin etcd hautement disponible avec ce plan de contrôle managé, mais ce plan n’est pas accessible directement. Le plan de contrôle Kubernetes et les mises à niveau des nœuds sont orchestrés via Azure CLI ou le portail Azure. Pour résoudre les problèmes éventuels, vous pouvez consulter les journaux d’activité du plan de contrôle par le biais des journaux d’activité Azure Monitor.
Pour configurer un plan de contrôle ou y accéder directement, déployez un cluster Kubernetes auto-géré à l’aide du Fournisseur d’API de cluster Azure.
Pour connaître les meilleures pratiques associées, consultez Meilleures pratiques relatives aux mises à jour et à la sécurité du cluster dans AKS.
Pour plus d’informations sur la gestion des coûts AKS, consultez Concepts de base des coûts AKS et Tarification pour AKS.
Nœuds et pools de nœuds
Pour exécuter vos applications et les services de prise en charge, vous avez besoin d’un nœud Kubernetes. Un cluster AKS comporte au moins un nœud, une machine virtuelle exécutant les composants des nœuds Kubernetes et le runtime de conteneur.
| Composant | Description |
|---|---|
kubelet |
Cet agent Kubernetes traite les requêtes d’orchestration du plan de contrôle, et gère la planification et l’exécution des conteneurs demandés. |
| kube-proxy | Gère la mise en réseau virtuelle sur chaque nœud. Le proxy route le trafic réseau et gère l’adressage IP pour les services et les pods. |
| Runtime de conteneur | Permet aux applications conteneurisées de s’exécuter et d’interagir avec d’autres ressources telles que le réseau virtuel ou le stockage. Les clusters AKS utilisant des pools de nœuds Kubernetes version 1.19+ pour Linux utilisent containerd comme runtime de conteneur. Depuis les pools de nœuds Kubernetes version 1.20 pour Windows, containerd peut être utilisé en préversion pour le runtime du conteneur, mais Docker est toujours le runtime de conteneur par défaut. Les clusters AKS qui utilisent des versions antérieures de Kubernetes pour les pools de nœuds utilisent Docker comme runtime de conteneur. |
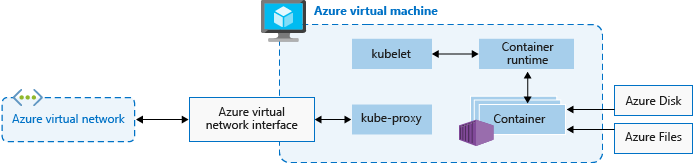
La taille VM Azure pour vos nœuds détermine les processeurs, la mémoire, la taille et le type de stockage disponibles (par exemple, SSD hautes performances ou HDD classique). Planifiez la taille du nœud pour déterminer si vos applications peuvent nécessiter une grande quantité d’UC et de mémoire ou un stockage hautes performances. Augmentez le nombre de nœuds dans votre cluster AKS afin de répondre à la demande. Pour plus d’informations sur la mise à l’échelle, consultez Options de mise à l’échelle pour les applications dans AKS.
Dans AKS, l’image de machine virtuelle pour les nœuds de votre cluster est basée sur Ubuntu Linux, Azure Linux ou Windows Server 2019. Quand vous créez un cluster AKS ou augmentez le nombre de nœuds, la plateforme Azure crée et configure automatiquement le nombre demandé de machines virtuelles. Les nœuds agent étant facturés en tant que machines virtuelles standard, les remises dont vous bénéficiez sur la taille de machine virtuelle que vous utilisez (y compris les réservations Azure) sont automatiquement appliquées.
Pour les disques managés, la taille et les performances du disque par défaut sont attribuées en fonction de la référence SKU de la machine virtuelle et du nombre de processeurs virtuels sélectionnés. Pour plus d’informations, consultez Dimensionnement du disque du système d’exploitation par défaut.
Si vous avez besoin d’une configuration et d’un contrôle avancés sur le runtime et le système d’exploitation de votre conteneur de nœuds Kubernetes, vous pouvez déployer un cluster autogéré à l’aide du Fournisseur d’API de cluster Azure.
Réservations de ressources
AKS utilise des ressources de nœud pour aider la fonction de nœud dans le cadre de votre cluster. Cette utilisation peut créer un écart entre les ressources totales du nœud et les ressources allouables dans AKS. Souvenez-vous de cette information au moment de définir les demandes et les limites des pods déployés par l’utilisateur.
Pour rechercher les ressources allouables d’un nœud, exécutez :
kubectl describe node [NODE_NAME]
Pour conserver les fonctionnalités et les performances des nœuds, AKS réserve des ressources sur chaque nœud. Lorsque le nœud gagne en taille dans les ressources, la réservation de ressources augmente en raison d’une plus grande quantité de pods déployés par l’utilisateur et nécessitant une gestion.
Notes
L’utilisation de modules complémentaires AKS tels que Container Insights (OMS) nécessite des ressources de nœud supplémentaires.
Deux types de ressources sont réservés :
UC
L’UC réservé dépend du type de nœud et de la configuration du cluster, ce qui peut le rendre moins allouable en raison de l’exécution de fonctionnalités supplémentaires.
| Cœurs de processeur sur l’hôte | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| Réservés par Kube (millicores) | 60 | 100 | 140 | 180 | 260 | 420 | 740 |
Mémoire
La mémoire utilisée par AKS comprend la somme de deux valeurs.
Important
La préversion d’AKS 1.29 va être disponible en janvier 2024 et comprend certains changements concernant les réservations de mémoire. Ces changements sont détaillés dans la section suivante.
AKS 1.29 et les versions ultérieures
Le démon
kubeleta la règle d’éviction memory.available<100 Mi par défaut. Cela garantit qu’un nœud a toujours au moins 100 Mi allouables à tout moment. Quand un hôte se trouve en dessous du seuil de mémoire disponible,kubeletdéclenche l’arrêt d’un des pods en cours d’exécution et libère de la mémoire sur la machine hôte.Un taux de réservations de mémoire est défini en fonction de la valeur la plus petite entre : 20 Mo * nombre maximal de pods pris en charge sur le nœud + 50 Mo ou 25 % des ressources de mémoire système totales.
Exemples :
- Si la machine virtuelle fournit 8 Go de mémoire et que le nœud prend en charge jusqu’à 30 pods, AKS réserve 20 Mo * 30 pods max. + 50 Mo = 650 Mo pour kube-reserved.
Allocatable space = 8GB - 0.65GB (kube-reserved) - 0.1GB (eviction threshold) = 7.25GB or 90.625% allocatable. - Si la machine virtuelle fournit 4 Go de mémoire et que le nœud prend en charge jusqu’à 70 pods, AKS réserve 25 % * 4 Go = 1 000 Mo pour kube-reserved, car la valeur est inférieure à 20 Mo * 70 pods max. + 50 Mo = 1 450 Mo.
Pour plus d’informations, consultez Configurer le nombre maximal de pods pour un cluster AKS.
- Si la machine virtuelle fournit 8 Go de mémoire et que le nœud prend en charge jusqu’à 30 pods, AKS réserve 20 Mo * 30 pods max. + 50 Mo = 650 Mo pour kube-reserved.
Versions AKS antérieures à 1.29
Le démon
kubeletest installé sur tous les nœuds d’agent Kubernetes pour gérer la création et l’arrêt du conteneur. Par défaut, sur AKS, le démonkubeletutilise la règle d’éviction memory.available<750Mi, ce qui garantit qu’un nœud doit toujours avoir au moins 750 Mi allouable à tout moment. Quand un ordinateur hôte se trouve au-dessous du seuil de mémoire disponible,kubeletdéclenche l’arrêt d’un des modules en cours d’exécution et libère de la mémoire sur l’ordinateur hôte.Une vitesse régressive des réservations de la mémoire pour que le démon kubelet fonctionne correctement (kube-reserved).
- 25 % des 4 premiers Go de mémoire
- 20 % des 4 Go suivants de mémoire (jusqu’à 8 Go)
- 10 % des 8 Go suivants de mémoire (jusqu’à 16 Go)
- 6 % des 112 Go suivants de mémoire (jusqu’à 128 Go)
- 2 % de la mémoire au-dessus de 128 Go
Remarque
AKS réserve un processus système supplémentaire de 2 Go dans les nœuds Windows qui ne font pas partie de la mémoire calculée.
Les règles d’allocation de mémoire et de processeur sont conçues pour :
- Maintenez l’intégrité des nœuds d’agent, avec quelques blocs de système d’hébergement critiques pour l’intégrité du cluster.
- Faire en sorte que le nœud indique moins de mémoire et de processeur allouable qu’il ne le ferait s’il ne faisait pas partie d’un cluster Kubernetes.
Vous ne pouvez pas changer les réservations de ressources ci-dessus.
Par exemple, si un nœud offre 7 Go, il signalera 34 % de la mémoire non-allouable incluant le seuil d’éviction dur de 750Mi.
0.75 + (0.25*4) + (0.20*3) = 0.75GB + 1GB + 0.6GB = 2.35GB / 7GB = 33.57% reserved
En plus des réservations pour Kubernetes lui-même, le système d’exploitation du nœud sous-jacent réserve également une quantité de ressources de processeur et de mémoire pour gérer les fonctions du système d’exploitation.
Pour connaître les meilleures pratiques associées, consultez la section Meilleures pratiques relatives aux fonctionnalités de base du planificateur dans AKS.
Pools de nœuds
Remarque
Le pool de nœuds Linux Azure est désormais en disponibilité générale (GA). Pour en savoir plus sur les avantages et les étapes de déploiement, consultez la Présentation de l’hôte de conteneur Linux Azure pour AKS.
Les nœuds d’une même configuration sont regroupés dans des pools de nœuds. Un cluster Kubernetes contient au moins un pool de nœuds. Le nombre et la taille initiaux des nœuds sont définis quand vous créez un cluster AKS, opération qui engendre la création d’un nœud de pools par défaut. Ce pool de nœuds par défaut dans AKS contient les machines virtuelles sous-jacentes qui exécutent vos nœuds d’agent.
Notes
Pour garantir un fonctionnement fiable de votre cluster, vous devez exécuter au moins 2 (deux) nœuds dans le pool de nœuds par défaut.
Vous mettez à l’échelle ou à niveau un cluster AKS sur le pool de nœuds par défaut. Vous pouvez choisir de mettre à l’échelle ou de mettre à niveau un pool de nœuds spécifique. Pour les opérations de mise à niveau, les conteneurs en cours d’exécution sont planifiés sur d’autres nœuds du pool de nœuds jusqu’à ce que tous les nœuds soient mis à niveau.
Pour plus d'informations sur l'utilisation de plusieurs pools de nœuds dans AKS, consultez Créer plusieurs pools de nœuds pour un cluster dans AKS.
Sélecteurs de nœud
Dans un cluster AKS avec plusieurs pools de nœuds, vous devrez peut-être indiquer au planificateur Kubernetes Scheduler le pool de nœuds qui devra être utilisé pour une ressource donnée. Par exemple, les contrôleurs d’entrée ne doivent pas s’exécuter sur des nœuds Windows Server.
Les sélecteurs de nœud vous permettent de définir différents paramètres, comme le système d’exploitation des nœuds, pour contrôler à quel endroit un pod doit être planifié.
L’exemple de base suivant planifie une instance NGINX sur un nœud Linux en utilisant le sélecteur de nœud "kubernetes.io/os": linux :
kind: Pod
apiVersion: v1
metadata:
name: nginx
spec:
containers:
- name: myfrontend
image: mcr.microsoft.com/oss/nginx/nginx:1.15.12-alpine
nodeSelector:
"kubernetes.io/os": linux
Pour plus d’informations sur la façon de contrôler l’endroit où sont planifiés les pods, consultez la section Meilleures pratiques relatives aux fonctionnalités avancées du planificateur dans AKS.
Groupe de ressources de nœud
Lorsque vous créez un cluster AKS, vous devez spécifier un groupe de ressources dans lequel créer la ressource de cluster. En plus de ce groupe de ressources, le fournisseur de ressources AKS crée et gère également un groupe de ressources distinct appelé groupe de ressources de nœud. Le groupe de ressources contient les ressources d’infrastructure suivantes :
- Groupes de machines virtuelles identiques et machines virtuelles pour chaque nœud dans les pools de nœuds
- Réseau virtuel pour le cluster
- Stockage pour le cluster
Un nom est attribué au groupe de ressources de nœud par défaut, par exemple MC_myResourceGroup_myAKSCluster_eastus. Lors de la création du cluster, vous avez également la possibilité de spécifier le nom attribué à votre groupe de ressources de nœud. Lorsque vous supprimez votre cluster AKS, le fournisseur de ressources AKS supprime automatiquement le groupe de ressources de nœud.
Le groupe de ressources de nœud présente les limitations suivantes :
- Vous ne pouvez pas spécifier un groupe de ressources existant pour le groupe de ressources de nœud.
- Vous ne pouvez pas spécifier un autre abonnement pour le groupe de ressources de nœud.
- Vous ne pouvez pas modifier le nom du groupe de ressources de nœud une fois que le cluster a été créé.
- Vous ne pouvez pas spécifier des noms pour les ressources managées au sein du groupe de ressources de nœud.
- Vous ne pouvez pas modifier ni supprimer les étiquettes des ressources managées créées par Azure au sein du groupe de ressources de nœud.
Si vous modifiez ou supprimez des étiquettes créées par Azure et d’autres propriétés de ressources dans le groupe de ressources de nœud, vous pouvez obtenir des résultats inattendus tels que des erreurs de mise à l’échelle et de mise à niveau. À mesure qu’AKS gère le cycle de vie de l’infrastructure dans le groupe de ressources de nœud, toutes les modifications déplacent votre cluster dans un état non pris en charge.
Un scénario courant dans lequel les clients souhaitent modifier des ressources consiste à utiliser des étiquettes. AKS vous permet de créer et de modifier des étiquettes qui sont propagées aux ressources du groupe de ressources du nœud, et vous pouvez ajouter ces étiquettes lors de la création ou de la mise à jour du cluster. Vous souhaiterez peut-être créer ou modifier des balises personnalisées, par exemple, pour affecter une unité commerciale ou un centre de coûts. Vous pouvez également des stratégies Azure avec une étendue sur le groupe de ressources managé.
La modification de balises créées par Azure sur des ressources dépendant du groupe de ressources du nœud dans le cluster AKS est une action non prise en charge, qui rompt l’objectif de niveau de service (SLO). Pour plus d'informations, consultez AKS offre-t-il un contrat de niveau de service ?
Pour réduire le risque que des modifications dans le groupe de ressources de nœud affectent vos clusters, vous pouvez activer le verrouillage du groupe de ressources de nœud pour appliquer une affectation de refus à vos ressources AKS. Pour plus d’informations, consultez Configuration du cluster dans AKS.
Avertissement
Si vous n’avez pas activé le verrouillage du groupe de ressources de nœud, vous pouvez modifier directement n’importe quelle ressource du groupe de ressources de nœud. La modification directe des ressources dans le groupe de ressources de nœud peut entraîner l’instabilité ou la réponse de votre cluster.
Pods
Kubernetes Utilise des pods pour exécuter une instance de votre application. Un pod représente une instance unique de votre application.
Les pods utilisent généralement un mappage individuel avec un conteneur. Dans les scénarios avancés, un pod peut contenir plusieurs conteneurs. Ces pods multiconteneurs sont planifiés ensemble sur le même nœud et permettent aux conteneurs de partager des ressources connexes.
Quand vous créez un pod, vous pouvez définir des demandes de ressources afin de demander une certaine quantité de ressources de processeur ou de mémoire. Le planificateur de Kubernetes essaie de répondre à cette demande en planifiant les pods afin qu’ils s’exécutent sur un nœud avec des ressources disponibles. Vous pouvez également spécifier des limites de ressources maximales qui empêchent un pod de consommer trop de ressources de calcul à partir du nœud sous-jacent. La meilleure pratique consiste à inclure des limites de ressources pour tous les pods afin d’aider le planificateur de Kubernetes à identifier les ressources nécessaires et autorisées.
Pour plus d’informations, consultez Kubernetes pods (Pods Kubernetes) et Kubernetes pod lifecycle (cycle de vie des pods Kubernetes).
Un pod est une ressource logique, mais les charges de travail s’exécutent sur les conteneurs. Les pods sont généralement des ressources éphémères et jetables. Il manque aux pods planifiés individuellement une partie des caractéristiques de haute disponibilité et de redondance de Kubernetes. En effet, les pods sont déployés et gérés par des contrôleurs Kubernetes, comme le contrôleur de déploiement.
Déploiements et manifestes YAML
Un déploiement représente des pods identiques, gérés par le contrôleur de déploiement Kubernetes. Un déploiement définit le nombre de réplicas de pods à créer. Le planificateur Kubernetes veille à ce que des pods supplémentaires soient planifiés sur des nœuds sains si des pods ou des nœuds rencontrent des problèmes.
Vous pouvez mettre à jour les déploiements pour changer la configuration des pods, l’image de conteneur utilisée ou le stockage attaché. Le contrôleur de déploiement :
- Purge et termine un nombre donné de réplicas.
- Crée des réplicas à partir de la nouvelle définition de déploiement.
- Poursuit le processus jusqu’à ce que tous les réplicas du déploiement soient mis à jour.
La plupart des applications sans état dans AKS doivent utiliser le modèle de déploiement plutôt que la planification de pods individuels. Kubernetes peut superviser l’intégrité et l’état du déploiement pour s’assurer que le nombre requis de réplicas s’exécutent dans le cluster. Quand vous planifiez des pods individuels, ces derniers ne sont pas redémarrés s’ils rencontrent un problème et ne sont pas replanifiés sur des nœuds sains si leur nœud actuel rencontre un problème.
Vous ne souhaitez pas interrompre les décisions de gestion avec un processus de mise à jour si votre application nécessite un nombre minimal d’instances disponibles. Les budgets d’interruption de pods permettent de définir le nombre de réplicas dans un déploiement pouvant être retirés pendant une mise à niveau d’un nœud ou une mise à jour. Par exemple, si votre déploiement comprend cinq (5) réplicas, vous pouvez définir une interruption de pods de 4 (quatre) pour limiter la suppression ou la replanification autorisée à un seul réplica à la fois. Comme dans le cas des limites de ressources des pods, une bonne pratique consiste à définir des budgets d’interruption de pods sur les applications qui nécessitent la présence systématique d’un nombre minimal de réplicas.
Les déploiements sont généralement créés et gérés avec kubectl create ou kubectl apply. Créez un déploiement en définissant un fichier manifeste au format YAML.
L’exemple suivant crée un déploiement de base du serveur web NGINX. Le déploiement spécifie la création de trois (3) réplicas ; le port 80 doit être ouvert sur le conteneur. Des demandes et limites de ressources sont également définies pour l’UC et la mémoire.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: mcr.microsoft.com/oss/nginx/nginx:1.15.2-alpine
ports:
- containerPort: 80
resources:
requests:
cpu: 250m
memory: 64Mi
limits:
cpu: 500m
memory: 256Mi
Voici la répartition des spécifications de déploiement dans le fichier manifeste YAML :
| Caractéristique | Description |
|---|---|
.apiVersion |
Spécifie le groupe d’API et la ressource d’API que vous souhaitez utiliser lors de la création de la ressource. |
.kind |
Spécifie le type de ressource que vous voulez créer. |
.metadata.name |
Spécifie le nom du déploiement. Ce fichier exécute l’image nginx à partir de Docker Hub. |
.spec.replicas |
Spécifie le nombre de pods à créer. Ce fichier va créer trois pods dupliqués. |
.spec.selector |
Spécifie les pods qui seront affectés par ce déploiement. |
.spec.selector.matchLabels |
Contient une carte de paires {clé, valeur} qui permet au déploiement de rechercher et de gérer les pods créés. |
.spec.selector.matchLabels.app |
Doit correspondre à .spec.template.metadata.labels. |
.spec.template.labels |
Spécifie les paires {key, value} attachées à l’objet. |
.spec.template.app |
Doit correspondre à .spec.selector.matchLabels. |
.spec.spec.containers |
Spécifie la liste des conteneurs appartenant au pod. |
.spec.spec.containers.name |
Spécifie le nom du conteneur spécifié sous forme d’étiquette DNS. |
.spec.spec.containers.image |
Spécifie le nom de l’image conteneur. |
.spec.spec.containers.ports |
Spécifie la liste des ports à exposer à partir du conteneur. |
.spec.spec.containers.ports.containerPort |
Spécifie le nombre de ports à exposer sur l’adresse IP du pod. |
.spec.spec.resources |
Spécifie les ressources de calcul requises par le conteneur. |
.spec.spec.resources.requests |
Spécifie la quantité minimale de ressources de calcul requises. |
.spec.spec.resources.requests.cpu |
Spécifie la quantité minimale d’UC requise. |
.spec.spec.resources.requests.memory |
Spécifie la quantité minimale de mémoire requise. |
.spec.spec.resources.limits |
Spécifie la quantité minimale de ressources de calcul requises. Cette limite est appliquée par le kubelet. |
.spec.spec.resources.limits.cpu |
Spécifie la quantité maximale d’UC autorisée. Cette limite est appliquée par le kubelet. |
.spec.spec.resources.limits.memory |
Spécifie la quantité maximale de mémoire autorisée. Cette limite est appliquée par le kubelet. |
Vous pouvez également créer des applications plus complexes en incluant des services tels que des équilibreurs de charge dans le manifeste YAML.
Pour plus d’informations, consultez la section Déploiements Kubernetes.
Gestion des packages avec Helm
Helm est couramment utilisé pour gérer les applications dans Kubernetes. Vous pouvez déployer des ressources en créant et en utilisant des graphiques Helm publics existants qui contiennent une version empaquetée d’un code d’application et de manifestes YAML Kubernetes. Ces graphiques Helm peuvent être stockés localement ou dans un référentiel distant comme un référentiel de graphiques Helm Azure Container Registry.
Pour utiliser Helm, installez le client Helm sur votre ordinateur, ou utilisez le client Helm dans Azure Cloud Shell. Recherchez ou créez des graphiques Helm, puis installez-les sur votre cluster Kubernetes. Pour plus d’informations, consultez la section Installer des applications existantes avec Helm dans AKS.
Ressources StatefulSet et ressources DaemonSet
À l’aide du planificateur de Kubernetes, le contrôleur de déploiement exécute des réplicas sur n’importe quel nœud disponible ayant des ressources. Bien que cette approche soit suffisante pour les applications sans état, le contrôleur de déploiement n’est pas idéal pour les applications qui nécessitent :
- Une convention d’affectation de noms ou un stockage persistant.
- Un réplica sur certains nœuds au sein d’un cluster.
Cependant, il existe deux ressources Kubernetes qui vous permettent de gérer ces types d’applications :
- Les StatefulSets maintiennent l’état des applications au-delà du cycle de vie d’un pod individuel.
- DaemonSet garantit une instance en cours d’exécution sur chaque nœud, tôt dans le processus de démarrage de Kubernetes.
Ressources StatefulSet
Le développement d’applications modernes est souvent destiné à des applications sans état. Pour les applications avec état, comme celles qui incluent des composants de base de données, vous pouvez utiliser StatefulSets. Comme pour les déploiements, StatefulSet crée et gère au moins un pod identique. Les réplicas d’une ressource StatefulSet suivent une approche séquentielle et sans perte de données du déploiement, de la mise à l’échelle, de la mises à niveau et de l’arrêt. Avec une ressource StatefulSet, la convention de nommage, les noms de réseau et le stockage persistent quand les réplicas sont replanifiés.
Définissez l’application au format YAML à l’aide de kind: StatefulSet. À partir de là, le contrôleur StatefulSet gère le déploiement et la gestion des réplicas requis. Les données sont écrites dans un stockage persistant, fourni par Azure Disques managés ou Azure Files. Avec une ressource StatefulSet, le stockage permanent sous-jacent demeure, même quand la ressource est supprimée.
Pour plus d’informations, consultez la section Kubernetes StatefulSets.
Les réplicas dans une ressource StatefulSet sont planifiés et exécutés sur n’importe quel nœud disponible dans un cluster AKS. Pour garantir qu’au moins un pod dans votre jeu s’exécute sur un nœud, vous utilisez un DaemonSet à la place.
Ressources DaemonSet
Dans le cadre d’une supervision ou d’une collecte de journaux spécifique, vous pouvez être amené à exécuter un pod sur la totalité ou un ensemble des nœuds. Vous pouvez utiliser DaemonSets pour un déploiement sur un ou plusieurs pods identiques. Le contrôleur DaemonSet garantit que chaque nœud spécifié exécute une instance du pod.
Le contrôleur DaemonSet peut planifier des pods sur des nœuds tôt dans le processus de démarrage du cluster, avant que ne démarre le planificateur Kubernetes par défaut. Ainsi, les pods dans une ressource DaemonSet sont démarrés avant que ne soient planifiés les pods traditionnels dans un déploiement ou une ressource StatefulSet.
À l’image des ressources StatefulSet, une ressource DaemonSet est définie dans le cadre d’une définition YAML à l’aide de kind: DaemonSet.
Pour plus d’informations, consultez la section Kubernetes DaemonSets.
Notes
Si vous utilisez le complément add-on Virtual Nodes, les DaemonSets ne créeront pas de pods sur le nœud virtuel.
Espaces de noms
Les ressources Kubernetes, comme les pods et les déploiements, sont regroupées logiquement dans un espace de noms pour diviser un cluster AKS, et créer, visualiser ou gérer l’accès à des ressources. Par exemple, vous pouvez créer des espaces de noms pour séparer les groupes métier. Les utilisateurs ne peuvent interagir qu’avec les ressources appartenant aux espaces de noms qui leur sont attribués.
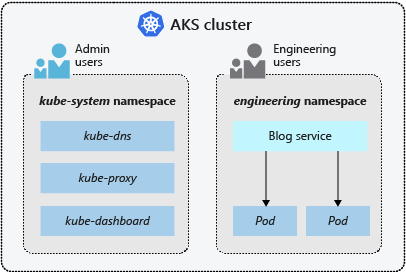
Quand vous créez un cluster AKS, les espaces de noms suivants sont disponibles :
| Espace de noms | Description |
|---|---|
| default | Espace de noms dans lequel sont créés par défaut les pods et les déploiements quand aucun espace de noms n’est fourni. Dans les environnements plus petits, vous pouvez déployer les applications directement dans l’espace de noms par défaut sans provoquer la création de séparations logiques supplémentaires. Quand vous interagissez avec l’API Kubernetes, comme avec kubectl get pods, l’espace de noms par défaut est utilisé si aucun n’est spécifié. |
| kube-system | Espace de noms où se trouvent les ressources principaless, telles que les fonctionnalités réseau, comme le DNS et le proxy, ou bien le tableau de bord Kubernetes. En règle générale, vous ne déployez pas vos propres applications dans cet espace de noms. |
| kube-public | Cet espace de noms n’est généralement pas utilisé, mais vous pouvez y recourir pour rendre les ressources visibles dans l’ensemble du cluster et consultables par tous les utilisateurs. |
Pour plus d’informations, consultez la section Espace de noms Kubernetes.
Étapes suivantes
Cet article décrit certains des principaux composants Kubernetes et leur application aux clusters AKS. Pour plus d’informations sur les concepts fondamentaux de Kubernetes et d’AKS, consultez les articles suivants :