Utilisation de données dans les applications ASP.NET Core
Conseil
Ce contenu est un extrait du livre électronique, Architect Modern Web Applications with ASP.NET Core and Azure (Architecturer des applications web modernes avec ASP.NET Core et Azure), disponible dans la documentation .NET ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

« Les données sont une chose précieuse et durent plus longtemps que les systèmes eux-mêmes. »
Tim Berners-Lee
L’accès aux données est une partie importante de la plupart des applications logicielles. ASP.NET Core prend en charge diverses options d’accès aux données, notamment Entity Framework Core (et Entity Framework 6), et peut fonctionner avec tout framework d’accès aux données .NET. Le choix du framework d’accès aux données à utiliser dépend des besoins de l’application. L’abstraction de ces choix par rapport aux projets d’interface utilisateur et ApplicationCore, ainsi que l’encapsulation des détails d’implémentation dans l’infrastructure, permettent de produire des logiciels faiblement couplés et testables.
Entity Framework Core (pour les bases de données relationnelles)
Si vous écrivez une application ASP.NET Core qui doit fonctionner avec des données relationnelles, Entity Framework Core (EF Core) est la méthode recommandée pour l’accès de l’application à ses données. EF Core est un mappeur objet-relationnel (ORM) qui permet aux développeurs .NET de conserver des objets vers et à partir d’une source de données. Du coup, ils n’ont plus à écrire une grande partie du code d’accès aux données qu’ils devraient généralement écrire. Comme ASP.NET Core, EF Core a été entièrement réécrit afin de prendre en charge les applications multiplateformes modulaires. Vous l’ajoutez à votre application en tant que package NuGet, vous le configurez lors du démarrage de l’application et vous le demandez par l’intermédiaire de l’injection de dépendances quand vous en avez besoin.
Pour utiliser EF Core avec une base de données SQL Server, exécutez la commande d’interface CLI dotnet suivante :
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
Pour ajouter la prise en charge d’une source de données InMemory, à des fins de test :
dotnet add package Microsoft.EntityFrameworkCore.InMemory
Le DbContext
Pour utiliser EF Core, vous avez besoin d’une sous-classe de DbContext. Cette classe contient des propriétés représentant des collections d’entités que votre application utilisera. L’exemple eShopOnWeb comprend un CatalogContext avec des collections d’éléments, de marques et de types :
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
Votre DbContext doit avoir un constructeur qui accepte des DbContextOptions et passer cet argument au constructeur DbContext de base. Si vous n’avez qu’un seul DbContext dans votre application, vous pouvez passer une instance de DbContextOptions, mais si vous en avez plusieurs vous devez utiliser le type DbContextOptions<T> générique et passer votre type DbContext comme paramètre générique.
Configuration d’EF Core
Dans votre application ASP.NET Core, vous configurez généralement EF Core dans Program.cs avec les autres dépendances de votre application. EF Core utilise un DbContextOptionsBuilder, qui prend en charge plusieurs méthodes d’extension utiles pour simplifier sa configuration. Pour configurer CatalogContext de façon à utiliser une base de données SQL Server avec une chaîne de connexion définie dans Configuration, vous devez ajouter le code suivant :
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
Pour utiliser la base de données en mémoire :
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
Une fois que vous avez installé Core EF, créé un type enfant DbContext et ajouté le type aux services de l’application, vous êtes prêt à utiliser EF Core. Vous pouvez demander une instance de votre type DbContext dans n’importe quel service qui en a besoin, et commencer à travailler avec vos entités persistantes à l’aide de LINQ comme si elles se trouvaient simplement dans une collection. EF Core effectue la traduction de vos expressions LINQ en requêtes SQL pour stocker et récupérer vos données.
Vous pouvez voir les requêtes qu’EF Core exécute en configurant un enregistreur d’événements et en réglant son niveau au moins sur Informations, comme indiqué dans la Figure 8-1.

Figure 8-1 : Journalisation des requêtes EF Core dans la console
Extraction et stockage des données
Pour récupérer des données à partir d’EF Core, vous devez accéder à la propriété appropriée et utiliser LINQ afin de filtrer le résultat. Vous pouvez également utiliser LINQ pour effectuer une projection et transformer le résultat d’un type en un autre. L’exemple suivant permet de récupérer des CatalogBrands, classés par nom, filtrés d’après leur propriété Enabled et projetés sur un type SelectListItem :
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
Il est important dans l’exemple ci-dessus d’ajouter l’appel à ToListAsync afin d’exécuter la requête immédiatement. Sinon, l’instruction affecte un IQueryable<SelectListItem> à brandItems, qui ne sera pas exécutée avant son énumération. Le fait de retourner des résultats IQueryable à partir de méthodes présente des avantages et des inconvénients. Cela permet de modifier davantage la requête qu’EF Core construira, mais peut également provoquer des erreurs qui se produiront uniquement au moment de l’exécution, si des opérations sont ajoutées à la requête qu’EF Core ne peut pas traduire. Il est généralement plus sûr de passer les filtres à la méthode qui effectue l’accès aux données, et de retourner une collection en mémoire (par exemple, List<T>) comme résultat.
EF Core effectue le suivi des modifications apportées aux entités qu’il extrait de la persistance. Pour enregistrer les modifications apportées à une entité suivie, il vous suffit d’appeler la méthode SaveChangesAsync sur le DbContext, en vérifiant qu’il s’agit de la même instance de DbContext que celle utilisée pour extraire l’entité. L’ajout et la suppression d’entités s’effectuent directement sur la propriété DbSet appropriée, là aussi avec un appel à SaveChangesAsync pour exécuter les commandes de base de données. L’exemple suivant illustre l’ajout, la mise à jour et la suppression d’entités de la persistance.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core prend en charge les méthodes synchrones et asynchrones pour l’extraction et l’enregistrement. Dans les applications web, nous vous recommandons d’utiliser le modèle async/await avec les méthodes asynchrones, afin que les threads du serveur web ne soient pas bloqués pendant qu’ils attendent la fin des opérations d’accès aux données.
Pour plus d’informations, consultez Mise en mémoire tampon et streaming.
Extraction des données associées
Quand EF Core récupère des entités, il remplit toutes les propriétés qui sont stockées directement avec cette entité dans la base de données. Les propriétés de navigation (telles que les listes d’entités associées) ne sont pas remplies, et leur valeur peut être définie sur null. Ce processus garantit qu’EF Core n’extrait pas plus de données que nécessaire, ce qui est particulièrement important pour les applications web, qui doivent rapidement traiter les requêtes et retourner des réponses de manière efficace. Pour inclure des relations avec une entité en utilisant le chargement hâtif, vous spécifiez la propriété à l’aide de la méthode d’extension Include sur la requête, comme indiqué ci-dessous :
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
Vous pouvez inclure plusieurs relations, et également inclure des sous-relations à l’aide de ThenInclude. EF Core exécutera une seule requête pour récupérer le jeu d’entités résultant. Vous pouvez également inclure des propriétés de navigation de propriétés de navigation en passant une chaîne séparée par « . » à la méthode d’extension .Include(), comme suit :
.Include("Items.Products")
En plus de l’encapsulation de la logique de filtrage, une spécification peut spécifier la forme des données à retourner, dont les propriétés à remplir. L’exemple eShopOnWeb présente plusieurs spécifications qui illustrent l’encapsulation des informations de chargement hâtif dans la spécification. Vous pouvez voir comment la spécification est utilisée dans le cadre d’une requête ici :
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Une autre option de chargement des données associées consiste à utiliser le chargement explicite. Le chargement explicite vous permet de charger des données supplémentaires dans une entité qui a déjà été récupérée. Comme cette approche implique une requête distincte à la base de données, ce n’est pas recommandé pour les applications web, qui doivent réduire le nombre d’allers-retours vers la base de données effectués par requête.
Le chargement différé est une fonctionnalité qui charge automatiquement les données associées telles qu’elles sont référencées par l’application. La prise en charge du chargement différé a été ajoutée à la version 2.1 d’EF Core. Le chargement différé n’est pas activé par défaut et nécessite l’installation de Microsoft.EntityFrameworkCore.Proxies. Comme pour le chargement explicite, le chargement différé doit le plus souvent être désactivé pour les applications web, car son utilisation génère un supplément de requêtes de base de données à chaque requête web exécutée. Seulement, la surcharge induite par le chargement différé passe souvent inaperçue en phase de développement en raison de la faible latence et de la taille souvent réduite des jeux de données utilisés pour les tests. Cependant, en production, compte tenu du plus grand nombre d’utilisateurs, des données plus volumineuses et de la latence supérieure, les requêtes de base de données additionnelles peuvent souvent se traduire par des performances médiocres pour les applications web qui font largement appel au chargement différé.
Éviter les entités de chargement différé dans les applications web
Il est judicieux de tester votre application tout en examinant les requêtes de base de données réelles qu’elle effectue. Dans certaines circonstances, EF Core peut effectuer beaucoup plus de requêtes ou une requête plus coûteuse que ce qui est optimal pour l’application. L’un de ces problèmes est connu sous le nom d’explosion cartésienne. L’équipe EF Core met à disposition la méthode AsSplitQuery comme l’une des nombreuses façons de régler le comportement au moment de l’exécution.
Encapsulation de données
EF Core prend en charge plusieurs fonctionnalités qui permettent à votre modèle d’encapsuler correctement son état. Un problème courant dans les modèles de domaine est qu’ils exposent des propriétés de navigation de collection en tant que types de listes accessibles publiquement. Ce problème permet à tout collaborateur de manipuler le contenu de ces types de collection, de contourner ainsi des règles métier importantes relatives à la collection et de laisser éventuellement l’objet dans un état non valide. La solution à ce problème consiste à exposer un accès en lecture seule aux collections associées et à fournir explicitement des méthodes qui définissent des moyens par lesquels les clients peuvent les manipuler, comme dans l’exemple suivant :
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
Ce type d’entité n’expose pas une propriété List ou ICollection publique, mais expose plutôt un type IReadOnlyCollection qui encapsule le type de liste sous-jacent. Lorsque vous utilisez ce modèle, vous pouvez indiquer à Entity Framework Core d’utiliser le champ de stockage comme suit :
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Une autre manière d’améliorer votre modèle de domaine consiste à utiliser des objets de valeur pour les types qui ne disposent pas d’identité et qui se distinguent uniquement par leurs propriétés. L’utilisation de ces types comme propriétés de vos entités peut aider à maintenir à sa place la logique spécifique à l’objet de valeur et peut éviter d’avoir une logique en double entre plusieurs entités qui utilisent le même concept. Dans Entity Framework Core, vous pouvez conserver les objets de valeur dans la même table que leur entité propriétaire en configurant le type comme une entité détenue, comme suit :
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
Dans cet exemple, la propriété ShipToAddress est de type Address. Address est un objet de valeur doté de plusieurs propriétés telles que Street et City. EF Core mappe l’objet Order à sa table avec une colonne par propriété Address, en faisant précéder chaque nom de colonne par le nom de la propriété. Dans cet exemple, la table Order doit inclure des colonnes telles que ShipToAddress_Street et ShipToAddress_City. Il est également possible de stocker les types détenus dans des tables distinctes, si vous le souhaitez.
Apprenez-en plus sur la prise en charge des entités détenues dans EF Core.
Connexions résilientes
Les ressources externes telles que les bases de données SQL peuvent parfois être indisponibles. En cas d’indisponibilité temporaire, les applications peuvent utiliser une logique de nouvelle tentative pour éviter de lever une exception. Cette technique est communément appelée résilience de la connexion. Vous pouvez implémenter votre propre technique de nouvelle tentative avec interruption exponentielle en retentant une opération après un temps d’attente qui augmente de manière exponentielle, jusqu’à ce que le nombre maximal de tentatives configuré ait été atteint. Cette technique prend en compte le fait que les ressources du cloud peuvent être indisponibles par intermittence pendant de brèves périodes, ce qui entraîne l’échec de certaines requêtes.
Pour Azure SQL DB, Entity Framework Core fournit déjà la logique de résilience et de nouvelle tentative de connexion de base de données interne. Par contre, vous devez autoriser la stratégie d’exécution d’Entity Framework pour chaque connexion DbContext si vous voulez avoir des connexions EF Core résilientes.
Par exemple, le code suivant au niveau des connexions EF Core autorise les connexions SQL résilientes qui sont retentées si elles échouent.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Stratégies d’exécution et transactions explicites utilisant BeginTransaction et plusieurs DbContexts
Quand les nouvelles tentatives sont activées dans les connexions EF Core, chaque opération que vous effectuez avec EF Core devient sa propre opération de nouvelle tentative. Chaque requête et chaque appel à SaveChangesAsync sont retentés ensemble si un échec passager se produit.
Toutefois, si votre code lance une transaction à l’aide de BeginTransaction, définissez votre propre groupe d’opérations à traiter ensemble. Ainsi, tout le contenu de la transaction doit être restauré si une défaillance se produit. Une exception semblable à la suivante s’affiche si vous tentez d’exécuter cette transaction quand vous utilisez une stratégie d’exécution EF (stratégie de nouvelle tentative) et que vous incluez dedans plusieurs SaveChangesAsync de plusieurs DbContexts.
System.InvalidOperationException : La stratégie d’exécution configurée SqlServerRetryingExecutionStrategy ne prend pas en charge les transactions lancées par l’utilisateur. Utilisez la stratégie d’exécution retournée par DbContext.Database.CreateExecutionStrategy() pour exécuter toutes les opérations de la transaction en tant qu’ensemble pouvant être retenté.
La solution consiste à appeler manuellement la stratégie d’exécution EF avec un délégué représentant tout ce qui doit être exécuté. En cas d’échec passager, la stratégie d’exécution appelle de nouveau le délégué. Le code suivant montre comment implémenter cette approche :
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
Le premier DbContext est le _catalogContext et le second DbContext se trouve dans l’objet _integrationEventLogService. Pour finir, l’action de validation serait effectuée avec plusieurs DbContexts et avec une stratégie d’exécution EF.
Références : Entity Framework Core
- Documentation EF Corehttps://learn.microsoft.com/ef/
- EF Core : Données associéeshttps://learn.microsoft.com/ef/core/querying/related-data
- Éviter le chargement différé des entités dans les applications ASPNEThttps://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
EF Core ou micro-ORM ?
Bien qu’EF Core soit un bon choix pour la gestion de la persistance, et que dans la plupart des cas il encapsule les détails de la base de données des développeurs d’applications, ce n’est pas le seul choix possible. Une alternative open source populaire est Dapper, qui est ce que l’on appelle un micro-ORM. Un micro-ORM est un outil allégé, avec moins de fonctionnalités, qui permet de mapper des objets à des structures de données. Dans le cas de Dapper, ses objectifs de conception sont axés sur les performances, plutôt que sur l’encapsulation entière des requêtes sous-jacentes qu’il utilise afin de récupérer et de mettre à jour des données. Comme il n’effectue pas d’abstraction de SQL par rapport au développeur, Dapper est « au plus proche du métal » et permet aux développeurs d’écrire les requêtes exactes qu’ils souhaitent utiliser pour une opération d’accès aux données spécifique.
EF Core offre deux fonctionnalités importantes qui le distinguent de Dapper, mais qui ajoutent également à sa surcharge de performances. La première est la conversion des expressions LINQ en SQL. Ces conversions sont mises en cache, mais leur exécution initiale implique tout de même une surcharge. La deuxième est le suivi des modifications sur les entités (afin que des instructions de mise à jour efficaces puissent être générées). Ce comportement peut être désactivé pour des requêtes spécifiques à l’aide de l’extension AsNoTracking. EF Core génère aussi des requêtes SQL qui sont en général très efficaces et dans tous les cas parfaitement acceptables du point de vue des performances, mais si vous avez besoin d’un contrôle affiné de la requête précise à exécuter, vous pouvez également passer du code SQL personnalisé (ou exécuter une procédure stockée) à l’aide d’EF Core. Dans ce cas, les performances de Dapper sont encore supérieures à celles d’EF Core, mais seulement très légèrement. Vous trouverez des données actuelles de point de référence de performances pour diverses méthodes d’accès aux données sur le site de Dapper.
Pour comparer les syntaxes de Dapper et d’EF, examinez ces deux versions de la même méthode servant à récupérer une liste d’éléments :
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Si vous avez besoin de générer des graphiques d’objets plus complexes avec Dapper, vous devez écrire vous-même les requêtes associées (alors que dans EF Core vous devez ajouter un Include). Cette fonctionnalité est prise en charge par diverses syntaxes, notamment une fonctionnalité appelée Mappage multiple, qui vous permet de mapper des lignes individuelles à plusieurs objets mappés. Par exemple, étant donné une classe Post avec une propriété Owner de type User, l’instruction SQL suivante retourne toutes les données nécessaires :
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Chaque ligne retournée inclut des données User et Post. Puisque les données User doivent être attachées aux données Post par le biais de leur propriété Owner, la fonction suivante est utilisée :
(post, user) => { post.Owner = user; return post; }
Voici le code complet permettant de retourner une collection de publications dont la propriété Owner est renseignée avec les données utilisateur associées :
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Comme il offre moins d’encapsulation, Dapper exige des développeurs une meilleure connaissance de la façon dont leurs données sont stockées et de la manière de les interroger efficacement. Ils doivent aussi écrire davantage de code pour les récupérer. Quand le modèle change, au lieu de simplement créer une nouvelle migration (une autre fonctionnalité d’EF Core) et/ou de mettre à jour les informations de mappage à un emplacement dans un DbContext, chaque requête affectée doit être mise à jour. Ces requêtes n’offrent pas de garantie au moment de la compilation. Elles peuvent donc échouer au moment de l’exécution en réponse à des changements du modèle ou de la base de données, ce qui rend les erreurs plus difficiles à détecter rapidement. En contrepartie, Dapper offre des performances extrêmement élevées en termes de rapidité.
Pour la plupart des applications, et pour la plupart des composants de presque toutes les applications, EF Core offre des performances acceptables. Ainsi, ses avantages en matière de productivité du développeur l’emporteront sans doute sur sa surcharge de performances. Pour les requêtes qui peuvent tirer parti de la mise en cache, il est possible que la requête réelle ne soit que rarement exécutée, ce qui atténue les différences pour les requêtes relativement petites.
SQL ou NoSQL
En règle générale, les bases de données relationnelles telles que SQL Server dominent la place de marché pour le stockage des données persistantes, mais elles ne constituent pas l’unique solution possible. Des bases de données NoSQL telles que MongoDB offrent une approche différente pour le stockage d’objets. Plutôt que de mapper des objets à des tables et des lignes, une autre option consiste à sérialiser le graphique d’objets entier et à stocker le résultat. Les avantages de cette approche, du moins initialement, sont la simplicité et les performances. Il est plus simple de stocker un objet sérialisé unique avec une clé, plutôt que de décomposer l’objet en nombreuses tables avec des relations et de mettre à jour les lignes qui peuvent avoir changé depuis la dernière fois où l’objet a été récupéré à partir de la base de données. De même, l’extraction et la désérialisation d’un objet unique à partir d’un magasin basé sur des clés sont généralement beaucoup plus rapides et plus faciles à effectuer que les jointures complexes ou les requêtes de base de données multiples requises pour composer entièrement le même objet à partir d’une base de données relationnelle. L’absence de verrous, de transactions ou de schéma fixe rend également les bases de données NoSQL adaptées à la mise à l’échelle entre plusieurs ordinateurs, ce qui permet de prendre en charge les jeux de données très volumineux.
En revanche, les bases de données NoSQL (comme elles sont généralement appelées) ont leurs inconvénients. Les bases de données relationnelles utilisent la normalisation afin d’appliquer la cohérence et éviter la duplication des données. Cette approche réduit la taille totale de la base de données et garantit que les mises à jour des données partagées sont disponibles immédiatement dans l’ensemble de la base de données. Dans une base de données relationnelle, une table Adresse peut référencer une table Pays par ID, de telle manière que si le nom d’un pays ou d’une région est modifié, les enregistrements d’adresses tireront parti de la mise à jour sans avoir à être eux-mêmes mis à jour. Toutefois, dans une base de données NoSQL, Adresse et son Pays associé peuvent être sérialisées dans le cadre de nombreux objets stockés. La mise à jour du nom d’un pays ou d’une région nécessiterait la mise à jour de tous ces objets, plutôt que celle d’une seule ligne. Les bases de données relationnelles peuvent également garantir l’intégrité relationnelle en appliquant des règles comme des clés étrangères. Les bases de données NoSQL n’offrent généralement pas ces contraintes sur leurs données.
Une autre complexité que les bases de données NoSQL doivent gérer est le contrôle de version. Quand les propriétés d’un objet changent, il se peut qu’il soit impossible de le désérialiser à partir des versions antérieures qui ont été stockées. Par conséquent, tous les objets existants qui ont une version sérialisée (précédente) de l’objet doivent être mis à jour pour être conformes à son nouveau schéma. Sur le plan conceptuel, cette approche ne diffère pas d’une base de données relationnelle, où les modifications de schéma nécessitent parfois des scripts de mise à jour ou des mises à jour du mappage. Toutefois, le nombre d’entrées qui doivent être modifiées est souvent beaucoup plus élevé avec l’approche NoSQL, car il y a plus de duplication de données.
Il est possible dans les bases de données NoSQL de stocker plusieurs versions d’objets, ce qui n’est en général pas pris en charge par les bases de données relationnelles à schéma fixe. Toutefois, dans ce cas votre code d’application devra prendre en compte l’existence de versions d’objets précédentes, ce qui augmentera la complexité.
Les bases de données NoSQL n’appliquent généralement pas ACID, ce qui signifie qu’elles présentent des avantages en termes de performances et de scalabilité par rapport aux bases de données relationnelles. Elles conviennent bien aux jeux de données très volumineux et aux objets qui ne sont pas adaptés au stockage dans des structures de tables normalisées. Rien n’empêche une application de tirer parti à la fois des bases de données relationnelles et NoSQL, en utilisant chacune là où c’est préférable.
Azure Cosmos DB
Azure Cosmos DB est un service de base de données NoSQL complètement managé qui propose un stockage des données dans le cloud sans schéma. Azure Cosmos DB est conçu pour offrir des performances rapides et prévisibles, une haute disponibilité, une mise à l’échelle élastique et une distribution globale. Même s’il s’agit d’une base de données NoSQL, les développeurs peuvent utiliser des fonctionnalités de requête SQL riches et familières sur des données JSON. Toutes les ressources Azure Cosmos DB sont stockées sous forme de documents JSON. Elles sont gérées en tant qu’éléments, qui sont des documents contenant des métadonnées, et en tant que flux, qui sont des collections d’éléments. La Figure 8-2 montre la relation entre différentes ressources Azure Cosmos DB.

Figure 8-2. Organisation des ressources Azure Cosmos DB.
Le langage de requête Azure Cosmos DB est une interface simple et puissante permettant d’interroger des documents JSON. Le langage prend en charge un sous-ensemble de syntaxe ANSI SQL et ajoute une intégration approfondie des objets JavaScript, des tableaux, de la construction d'objets et de l'appel de fonctions.
Références – Azure Cosmos DB
- Présentation d’Azure Cosmos DB https://learn.microsoft.com/azure/cosmos-db/introduction
Autres options de persistance
Outre les options de stockage NoSQL et relationnel, les applications ASP.NET Core peuvent utiliser Stockage Azure pour stocker différents formats de données et fichiers de façon scalable et basée sur le cloud. Stockage Azure étant extrêmement scalable, vous pouvez commencer par stocker de petites quantités de données, puis monter en charge et stocker jusqu’à des téraoctets de données si votre application l’exige. Stockage Azure prend en charge quatre genres de données :
Stockage Blob pour le stockage binaire ou de texte non structuré, également appelé stockage d’objets.
Stockage Table pour les jeux de données structurés, accessibles par le biais de clés de lignes.
Stockage File d’attente pour la messagerie fiable basée sur les files d’attente.
Stockage Fichier pour l’accès aux fichiers partagé entre les machines virtuelles Azure et les applications locales.
Références : Stockage Azure
- Introduction au Stockage Azure https://learn.microsoft.com/azure/storage/common/storage-introduction
Mise en cache
Dans les applications web, chaque requête web doit se terminer dans les plus brefs délais. L’une des manières de satisfaire à cette fonctionnalité consiste à limiter le nombre d’appels externes que le serveur doit effectuer pour terminer la requête. La mise en cache implique de stocker une copie des données sur le serveur (ou un autre magasin de données plus facilement interrogeable que la source de données). Les applications web, et en particulier les applications web traditionnelles non-monopages, doivent générer l’interface utilisateur entière lors de chaque requête. Cette approche implique souvent d’effectuer nombre des mêmes requêtes de base de données de manière répétée lors de chaque requête utilisateur. Dans la plupart des cas, ces données changent rarement ; il y a donc peu de raisons de les demander en permanence à la base de données. ASP.NET Core prend en charge la mise en cache des réponses, pour la mise en cache de pages entières, et la mise en cache des données, qui prend en charge un comportement de mise en cache plus granulaire.
Lors de l’implémentation de la mise en cache, il est important de garder à l’esprit la séparation des fonctions. Évitez d’implémenter la logique de mise en cache dans votre logique d’accès aux données ou dans votre interface utilisateur. Au lieu de cela, encapsulez la mise en cache dans ses propres classes, et utilisez la configuration pour gérer son comportement. Cette approche permet de respecter le principe de responsabilité unique et le principe ouvert/fermé, et il vous sera plus facile de gérer la façon dont vous utilisez la mise en cache dans votre application à mesure qu’elle évolue.
Mise en cache des réponses ASP.NET Core
ASP.NET Core prend en charge deux niveaux de mise en cache des réponses. Le premier niveau ne met rien en cache sur le serveur, mais ajoute des en-têtes HTTP qui demandent aux clients et aux serveurs proxy de mettre en cache les réponses. Cette fonctionnalité est implémentée en ajoutant l’attribut ResponseCache à des contrôleurs ou des actions spécifiques :
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
L’exemple précédent entraîne l’ajout de l’en-tête ci-dessous à la réponse, donnant instruction aux clients de mettre en cache le résultat pour une durée maximale de 60 secondes.
Cache-Control: public,max-age=60
Pour ajouter la mise en cache en mémoire côté serveur à l’application, vous devez référencer le package NuGet Microsoft.AspNetCore.ResponseCaching, puis ajouter l’intergiciel (middleware) de mise en cache des réponses. Cet intergiciel est configuré avec des services et des intergiciels lors du démarrage de l’application :
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
L’intergiciel (middleware) de mise en cache des réponses mettra automatiquement en cache les réponses conformément à un ensemble de conditions, que vous pouvez personnaliser. Par défaut, seules 200 réponses (OK) demandées par le biais des méthodes GET ou HEAD sont mises en cache. En outre, les requêtes doivent avoir une réponse avec un en-tête Cache-Control: public et ne peuvent pas inclure des en-têtes pour Authorization ou Set-Cookie. Consultez la liste complète des conditions de mise en cache utilisées par l’intergiciel (middleware) de mise en cache des réponses.
Mise en cache des données
Au lieu (ou en plus) de mettre en cache des réponses web complètes, vous pouvez mettre en cache les résultats de requêtes de données individuelles. Pour cette fonctionnalité, vous pouvez utiliser la mise en cache en mémoire sur le serveur web, ou utiliser un cache distribué. Cette section illustre comment implémenter la mise en cache en mémoire.
Ajoutez la prise en charge de la mise en cache de la mémoire (ou distribuée) avec le code suivant :
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Veillez également à ajouter le package NuGet Microsoft.Extensions.Caching.Memory.
Une fois que vous avez ajouté le service, vous demandez IMemoryCache par le biais de l’injection de dépendances partout où vous avez besoin d’accéder au cache. Dans cet exemple, le CachedCatalogService utilise le modèle de conception Proxy (ou Decorator), en fournissant une autre implémentation d’ICatalogServicequi contrôle l’accès à l’implémentation sous-jacente de CatalogService (ou y ajoute un comportement).
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
Pour configurer l’application afin qu’elle utilise la version mise en cache du service, tout en autorisant le service à obtenir l’instance de CatalogService dont il a besoin dans son constructeur, vous devez ajouter les lignes suivantes dans Program.cs :
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
Tout ce code étant en place, les appels de base de données afin d’extraire les données du catalogue ne seront effectués qu’une fois par minute, plutôt qu’à chaque requête. En fonction du trafic vers le site, cela peut avoir un impact considérable sur le nombre de requêtes effectuées sur la base de données et sur la durée moyenne de chargement de la page d’accueil, qui dépend actuellement des trois requêtes exposées par ce service.
Quand la mise en cache est implémentée, un problème apparaît : les données périmées. Il s’agit de données qui ont changé à la source, mais dont il reste une version obsolète dans le cache. Un moyen simple de résoudre ce problème consiste à utiliser de faibles durées de mise en cache, puisque pour une application occupée l’extension de la durée de mise en cache des données offre un avantage supplémentaire limité. Par exemple, prenez une page qui effectue une seule requête de base de données, et qui est demandée 10 fois par seconde. Si cette page est mise en cache pendant une minute, le nombre de requêtes de base de données effectuées par minute baissera de 600 à 1, une réduction de 99,8 %. Si la durée de mise en cache était d’une heure, la réduction globale serait de 99,997 %, mais la probabilité et l’âge potentiel des données périmées augmenteraient tous deux considérablement.
Une autre approche consiste à supprimer de manière proactive les entrées de cache quand les données qu’elles contiennent sont mises à jour. Vous pouvez supprimer une entrée si vous connaissez sa clé :
_cache.Remove(cacheKey);
Si votre application expose une fonctionnalité pour la mise à jour des entrées qu’elle met en cache, vous pouvez supprimer les entrées de cache correspondantes dans votre code qui effectue les mises à jour. Il peut parfois y avoir de nombreuses entrées différentes qui dépendent d’un jeu de données particulier. Dans ce cas, il peut être utile de créer des dépendances entre les entrées du cache, à l’aide d’un CancellationChangeToken. Avec un CancellationChangeToken, vous pouvez faire expirer plusieurs entrées de cache à la fois en annulant le jeton.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
La mise en cache peut améliorer considérablement les performances des pages web qui demandent à maintes reprises les mêmes valeurs à la base de données. Veillez à mesurer les performances des pages et de l’accès aux données avant d’appliquer la mise en cache, et appliquez uniquement la mise en cache là où vous constatez qu’il est nécessaire d’apporter une amélioration. La mise en cache consomme des ressources mémoire du serveur web et accroît la complexité de l’application. Il est donc important de ne pas procéder à une optimisation prématurée en employant cette technique.
Obtention de données dans des applications BlazorWebAssembly
Si vous créez des applications qui utilisent Blazor Server, vous pouvez utiliser Entity Framework et d’autres technologies d’accès aux données directes comme elles ont été abordées jusqu’à présent dans ce chapitre. Toutefois, lors de la création d’applications BlazorWebAssembly, comme d’autres infrastructures SPA, vous avez besoin d’une stratégie différente pour l’accès aux données. En règle générale, ces applications accèdent aux données et interagissent avec le serveur via des points de terminaison d’API web.
Si les données ou opérations effectuées sont sensibles, veillez à passer en revue la section relative à la sécurité dans le chapitre précédent et à protéger vos API contre un accès non autorisé.
Vous trouverez un exemple d’application BlazorWebAssembly dans l’application de référence eShopOnWeb, dans le Blazorprojet Administration. Ce projet est hébergé dans le projet web eShopOnWeb et permet aux utilisateurs du groupe Administrateurs de gérer les éléments du magasin. Vous pouvez voir une capture d’écran de l’application dans la figure 8-3.
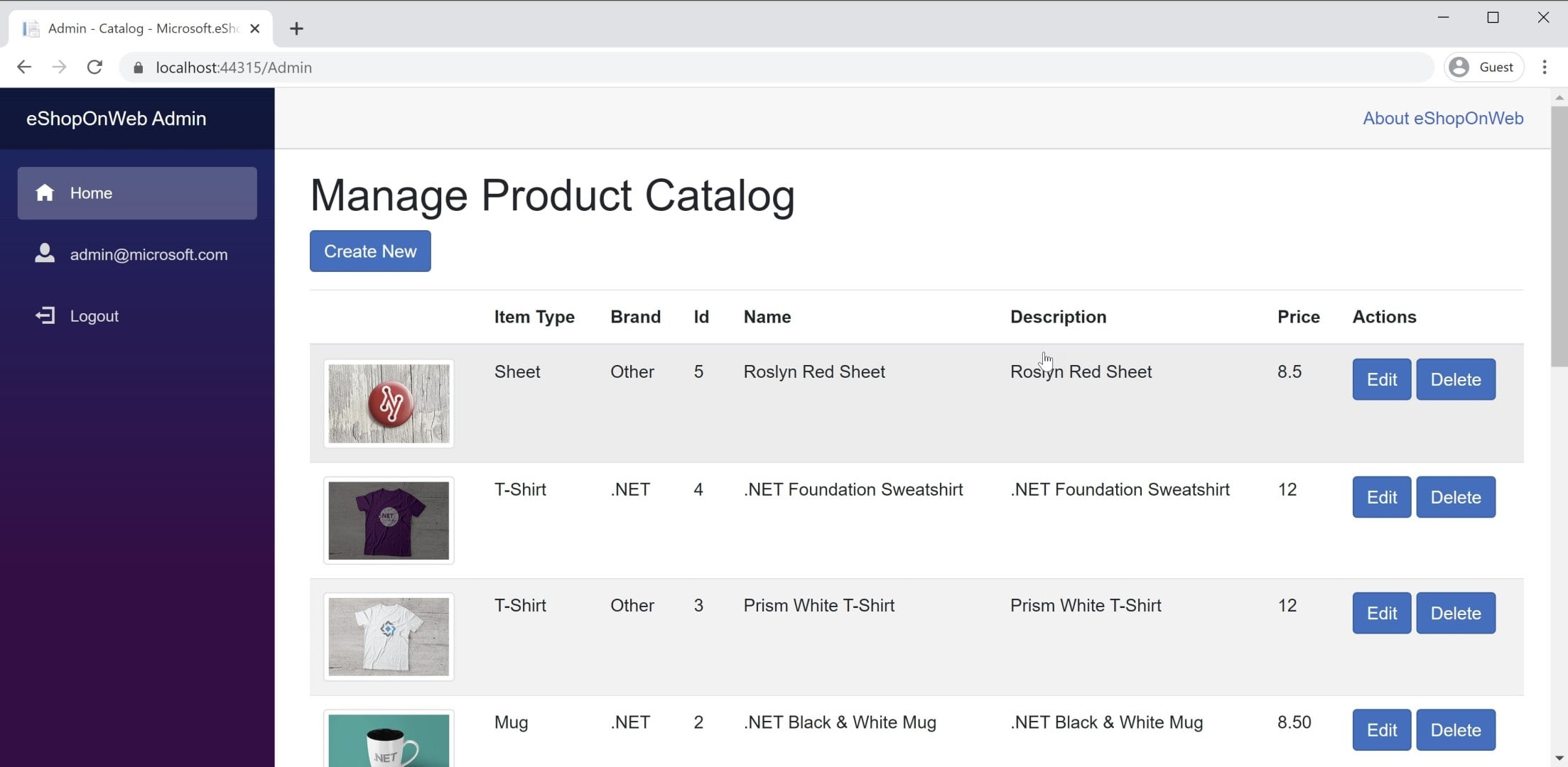
Figure 8-3. Capture d’écran du catalogue eShopOnWeb Administration.
Lors de l’extraction de données à partir d’API web au sein d’une application BlazorWebAssembly, vous utilisez simplement une instance de HttpClient comme vous le feriez dans n’importe quelle application .NET. Les étapes de base impliquées sont de créer la demande à envoyer (si nécessaire, généralement pour les demandes POST ou PUT), d’attendre la demande elle-même, de vérifier le code d’état et de désérialiser la réponse. Si vous allez effectuer de nombreuses demandes à un ensemble donné d’API, il est judicieux d’encapsuler vos API et de configurer l’adresse de base HttpClient de manière centralisée. De cette façon, si vous devez ajuster l’un de ces paramètres entre les différents environnements, vous pouvez apporter les modifications à un seul endroit. Vous devez ajouter la prise en charge de ce service dans votre fichier Program.Main :
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
Si vous devez accéder en toute sécurité aux services, vous devez accéder à un jeton sécurisé et configurer l’HttpClient pour transmettre ce jeton en tant qu’en-tête d’authentification avec chaque requête :
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
Cette activité peut être effectuée à partir de n’importe quel composant dans lequel HttpClient a été injecté, à condition que HttpClient n’ait pas été ajouté aux services de l’application avec une durée de vie Transient. Chaque référence à HttpClient dans l’application fait référence à la même instance, de sorte que les modifications apportées dans un seul flux de composant transitent dans l’ensemble de l’application. Un composant partagé comme la navigation principale du site est un endroit idéal pour effectuer cette vérification d’authentification (suivie de la spécification du jeton). Apprenez-en plus sur cette approche dans le projet BlazorAdmin dans l’application de référence eShopOnWeb.
L’un des avantages de BlazorWebAssembly par rapport aux applications monopages JavaScript traditionnelles est que vous n’avez pas besoin de synchroniser les copies de vos objets de transfert de données (DTOS). Votre projet BlazorWebAssembly et votre projet d’API web peuvent partager les mêmes objets de transfert de données dans un projet partagé commun. Cette approche élimine certaines des frictions impliquées dans le développement d’applications monopages.
Pour obtenir rapidement des données à partir d’un point de terminaison d’API, vous pouvez utiliser la méthode d’assistance intégrée GetFromJsonAsync. Il existe des méthodes similaires pour POST, PUT, etc. Ci-après, découvrez comment obtenir un CatalogItem à partir d’un point de terminaison d’API à l’aide d’un HttpClient configuré dans une application BlazorWebAssembly :
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
Une fois que vous avez les données requises, vous suivez généralement les modifications en local. Lorsque vous souhaitez apporter des mises à jour au magasin de données principal, appelez des API web supplémentaires à cet effet.
Références – Blazor Données
- Appeler une API web à partir d’ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour