Créer et utiliser des flux de données dans Power Apps
La préparation des données avancée est désormais disponible dans Power Apps, vous pouvez donc créer une collection de données appelée flux de données, que vous pouvez ensuite utiliser pour vous connecter avec des données commerciales de sources diverses, vous pouvez nettoyer des données, les transformer, puis les charger dans Microsoft Dataverse ou le compte du stockage Azure Data Lake Gen2 de votre organisation.
Un flux de données est une collection d’entités créée et gérée dans les environnements du service Power Apps. Vous pouvez ajouter et modifier des tables dans votre dataflow, ainsi que gérer les plans d’actualisation des données directement dans l’environnement dans lequel le dataflow a été créé.
Après avoir créé un dataflow dans le portail Power Apps, vous pouvez obtenir des données de celui-ci à l’aide du connecteur Common Data Service ou Power BI Desktop Dataflow, selon la destination que vous avez choisie lors de la création du dataflow.
L’utilisation d’un dataflow comporte trois étapes principales :
Créer le dataflow dans le portail Power Apps. Vous sélectionnez la destination vers laquelle charger les données de sortie, la source à partir de laquelle obtenir les données et les étapes Power Query permettant de transformer les données à l’aide d’outils Microsoft conçus pour faciliter cette opération.
Planifier des exécutions de dataflow. Il s’agit de la fréquence à laquelle Power Platform Dataflow doit actualiser les données que votre dataflow va charger et transformer.
Utiliser les données que vous avez chargées dans le stockage de destination. Vous pouvez générer des applications, des flux, des rapports Power BI et des tableaux de bord ou vous connecter directement au dossier Common Data Model du flux de données du lac de votre organisation à l’aide de services de données Azure tels que Azure Data Factory, Azure Databricks ou tout autre service qui prend en charge le dossier Common Data Model standard.
Les sections suivantes présentent chacune de ces étapes, vous pouvez donc vous familiariser avec les outils fournis pour effectuer chaque étape.
Créer un flux de données
Les flux de données sont créés dans un environnement. Par conséquent, vous pourrez uniquement les afficher et les gérer à partir de cet environnement. En outre, les personnes qui souhaitent obtenir des données de votre flux de données doivent avoir accès à l’environnement dans lequel vous l’avez créé.
Notes
La création de Dataflows n’est actuellement pas disponible avec les Licences de plan de développeur Power Apps.
Connectez-vous à Power Apps et vérifiez dans quel environnement vous vous trouvez, recherchez le commutateur d’environnement sur la droite de la barre de commandes.

Dans le volet de navigation de gauche, sélectionnez Dataflows. Si l’élément ne se trouve pas dans le volet latéral, sélectionnez …Plus, puis sélectionnez l’élément souhaité.
Sélectionnez Nouveau dataflow, puis Démarrer à partir de zéro.
Sur la page Nouveau dataflow, entrez un Nom pour le dataflow. Par défaut, les dataflows stockent les tables dans Dataverse. Sélectionnez Entités analytiques uniquement si vous souhaitez que les tables soient stockées dans le compte de stockage Azure Data Lake de votre organisation. Sélectionnez Créer.
Important
Un flux de données n’a qu’un seul propriétaire : la personne qui l’a créé. Seul le propriétaire peut modifier le flux de données. L’autorisation et l’accès aux données créées par le flux de données dépendent de la destination où vous avez chargé les données. Les données chargées dans Dataverse seront disponibles via le connecteur Dataverse et requièrent que les personnes accédant aux données soient autorisées à accéder à Dataverse. Les données chargées dans le compte de stockage Azure Data Lake Gen2 de votre organisation sont accessibles via le connecteur de flux de données Power Platform et l’accès à ce dernier nécessite d’appartenir à l’environnement dans lequel il a été créé.
Dans la page Choisir une source de données, sélectionnez la source de données où sont stockées les tables. La sélection des sources de données affichées vous permet de créer des tables des dataflow.

Après avoir sélectionné une source de données, vous êtes invité à fournir les paramètres de connexion, notamment le compte à utiliser lors de la connexion à la source de données. Cliquez sur Suivant.
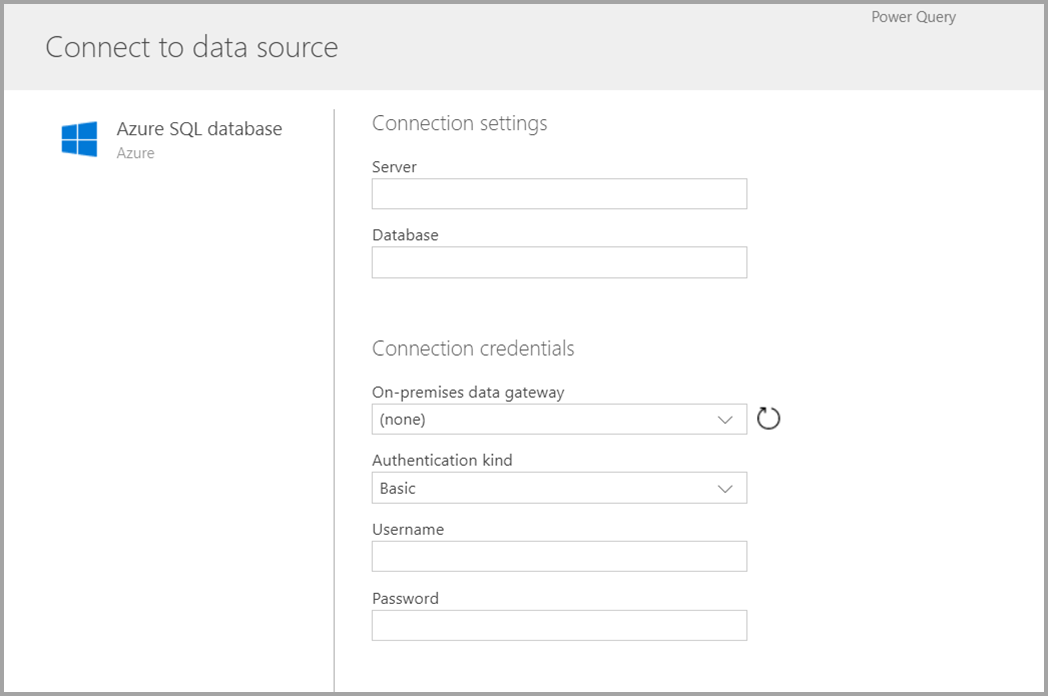
Une fois connecté, vous devez sélectionner les données à utiliser pour votre table. Lorsque vous choisissez les données et une source, le service de flux de données Power Platform se reconnecte ensuite à la source de données afin de conserver les données de votre flux de données actualisées selon la fréquence que vous sélectionnez ultérieurement dans le processus d’installation.
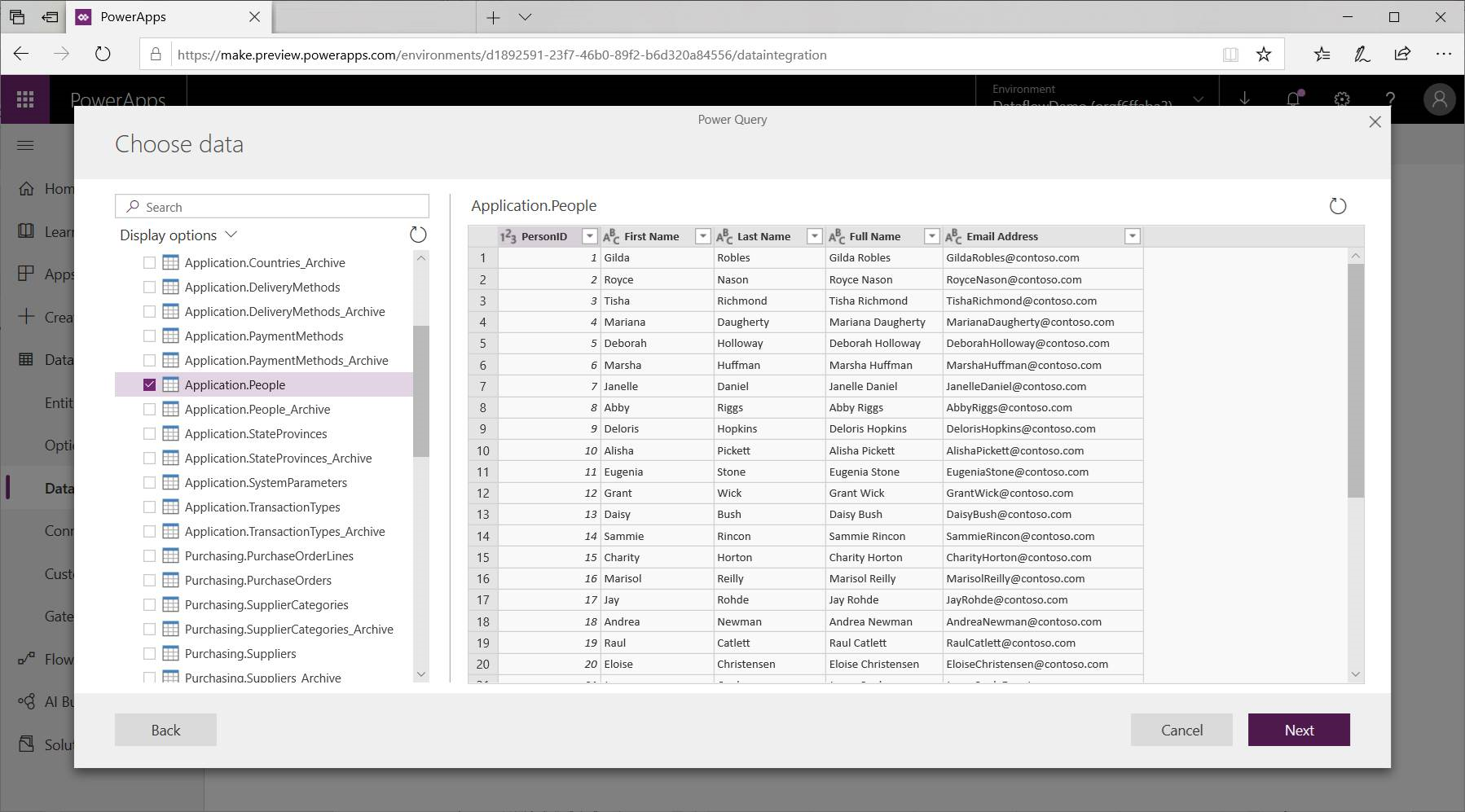

Maintenant que vous avez sélectionné les données à utiliser pour la table, vous pouvez utiliser l’éditeur de dataflow pour mettre en forme ou transformer ces données dans le format nécessaire pour une utilisation dans votre dataflow.
Utilisez l’éditeur de flux de données pour mettre en forme ou transformer des données
Vous pouvez mettre en forme votre sélection de données dans un formulaire le mieux adapté à votre table à l’aide d’une expérience d’édition Power Query similaire à l’éditeur Power Query dans Power BI Desktop. Pour plus d’informations sur Power Query, consultez Présentation des requêtes dans Power BI Desktop.
Si vous souhaitez visualiser le code que l’éditeur de requête crée à chaque étape, ou si vous souhaitez créer votre propre code, vous pouvez utiliser l’éditeur avancé.
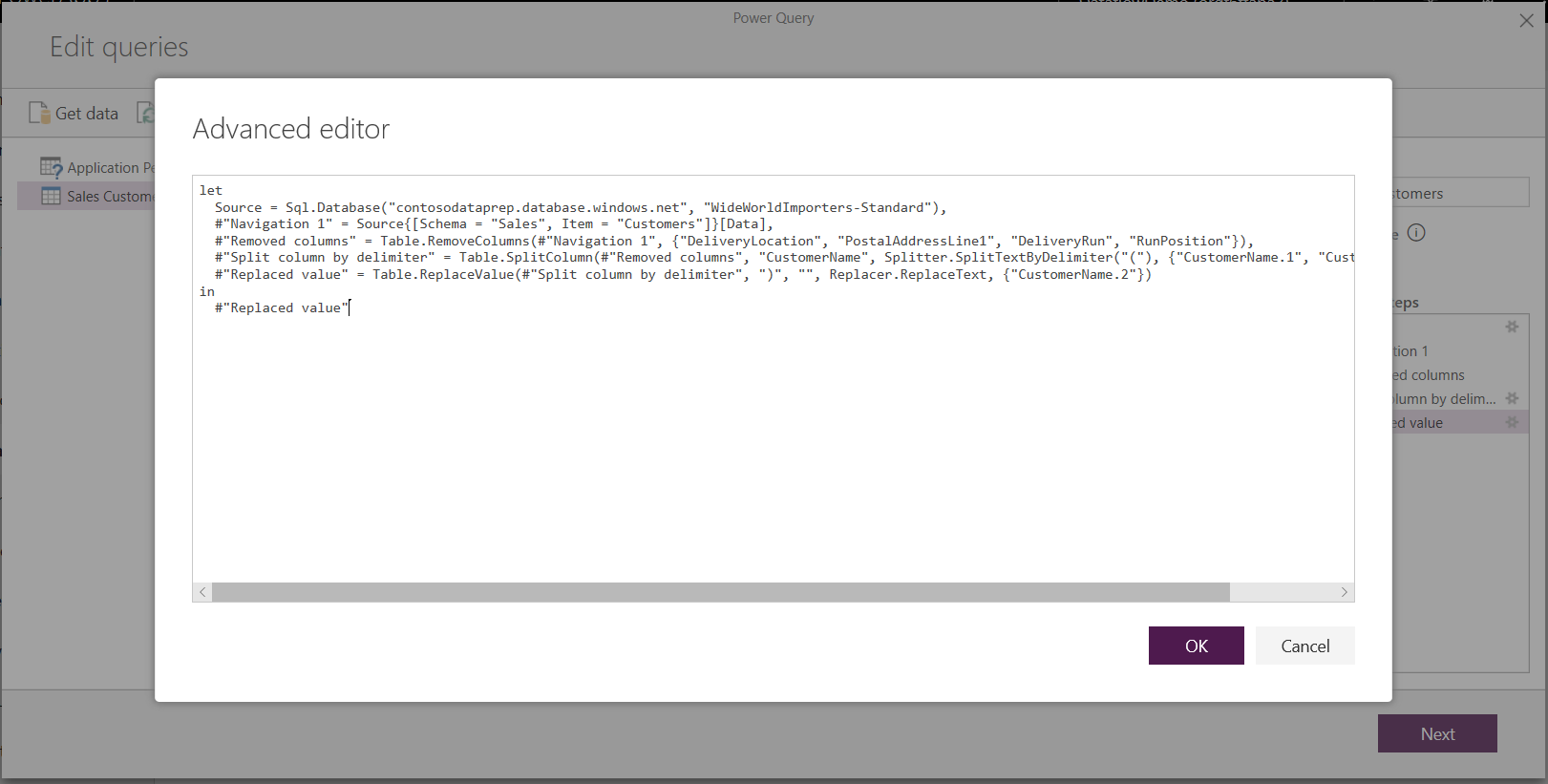
Flux de données et Common Data Model
Les tables de dataflows incluent de nouveaux outils pour mapper facilement vos données commerciales au Common Data Model, pour les enrichir avec des données de Microsoft et de tiers, et pour obtenir l’accès simplifié au Machine Learning. Ces nouvelles capacités peuvent être exploitées pour fournir des informations utiles et exploitables à vos données commerciales. Une fois que vous avez effectué toutes les transformations dans l’étape de modification de requêtes décrite ci-dessous, vous pouvez mapper les colonnes de vos tables de source de données dans des colonnes de table standard conformément à ce qui est défini par Common Data Model. Les tables standard ont un schéma connu défini par Common Data Model.
Pour plus d’informations sur cette méthode, et sur Common Data Model, voir Common Data Model.
Pour tirer parti de Common Data Model avec votre flux de données, sélectionnez la transformation Mapper au format standard dans la boîte de dialogue Modifier les requêtes. Dans l’écran Mapper des tables qui s’affiche, sélectionnez la table standard que vous souhaitez mapper.
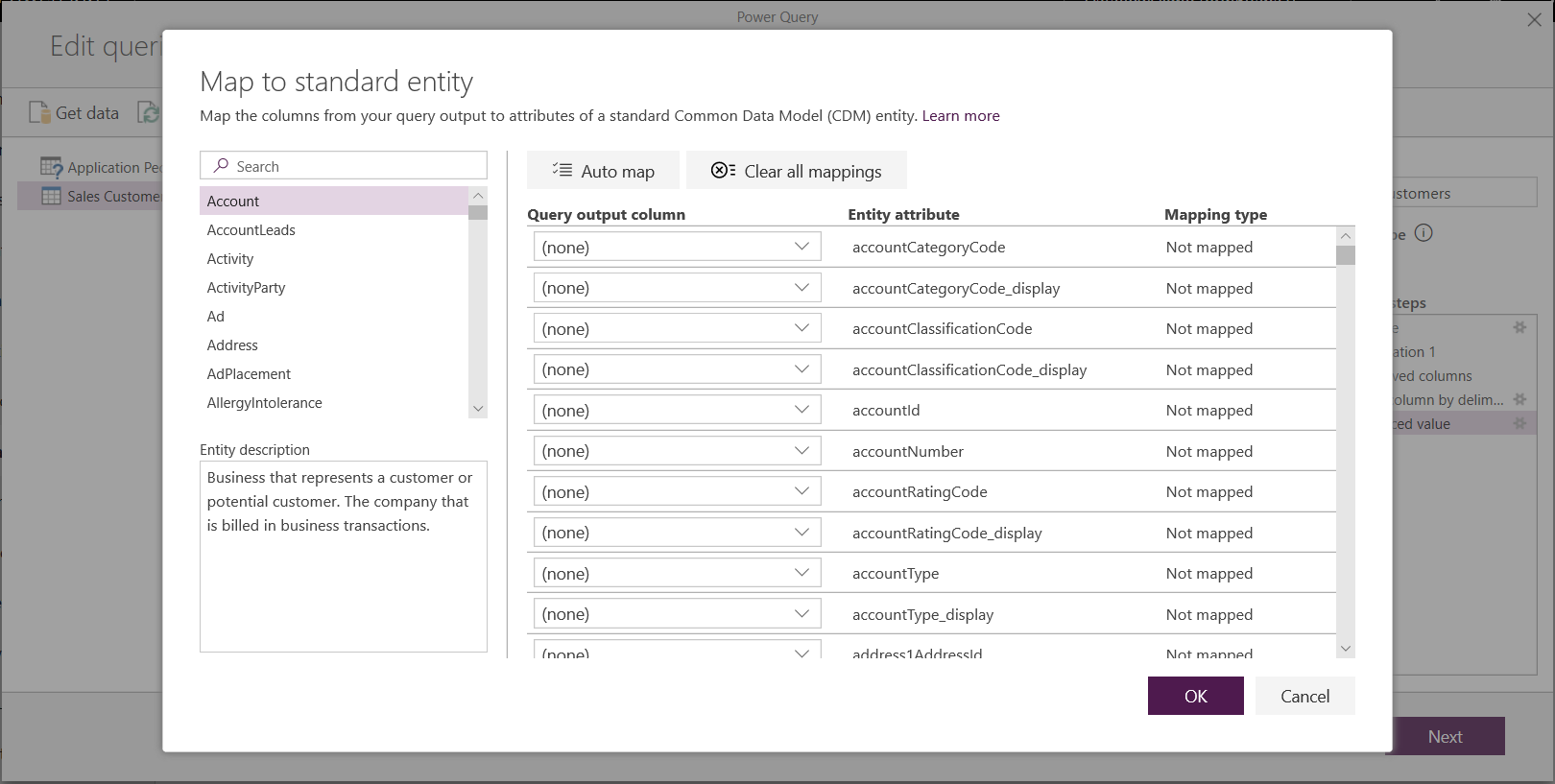
Lorsque vous mappez une colonne source à une colonne standard, les événements suivants se produisent :
La colonne source porte le nom de la colonne standard (la colonne est renommée si les noms sont différents).
La colonne source obtient le type de données de la colonne standard.
Pour préserver la table standard Common Data Model, toutes les colonnes standard qui ne sont pas mappées obtiennent des valeurs Null.
Toutes les colonnes sources qui ne sont pas mappées ne changent pas pour garantir que le résultat du mappage est une table standard avec des colonnes personnalisées.
Une fois que vous avez terminé vos sélections et que votre table et ses paramètres de données sont complets, vous êtes prêt pour la prochaine étape, qui consiste à sélectionner la fréquence d’actualisation de votre dataflow.
Définir la fréquence d’actualisation
Une fois que vos tables ont été définies, vous devez planifier la fréquence d’actualisation pour chacune de vos sources de données connectées.
Les flux de données utilisent un processus d’actualisation des données pour maintenir les données à jour. Dans l’outil de création de flux de données Power Platform, vous pouvez choisir d’actualiser votre flux de données manuellement ou automatiquement à un intervalle de votre choix. Pour planifier une actualisation automatiquement, sélectionnez Actualiser automatiquement.
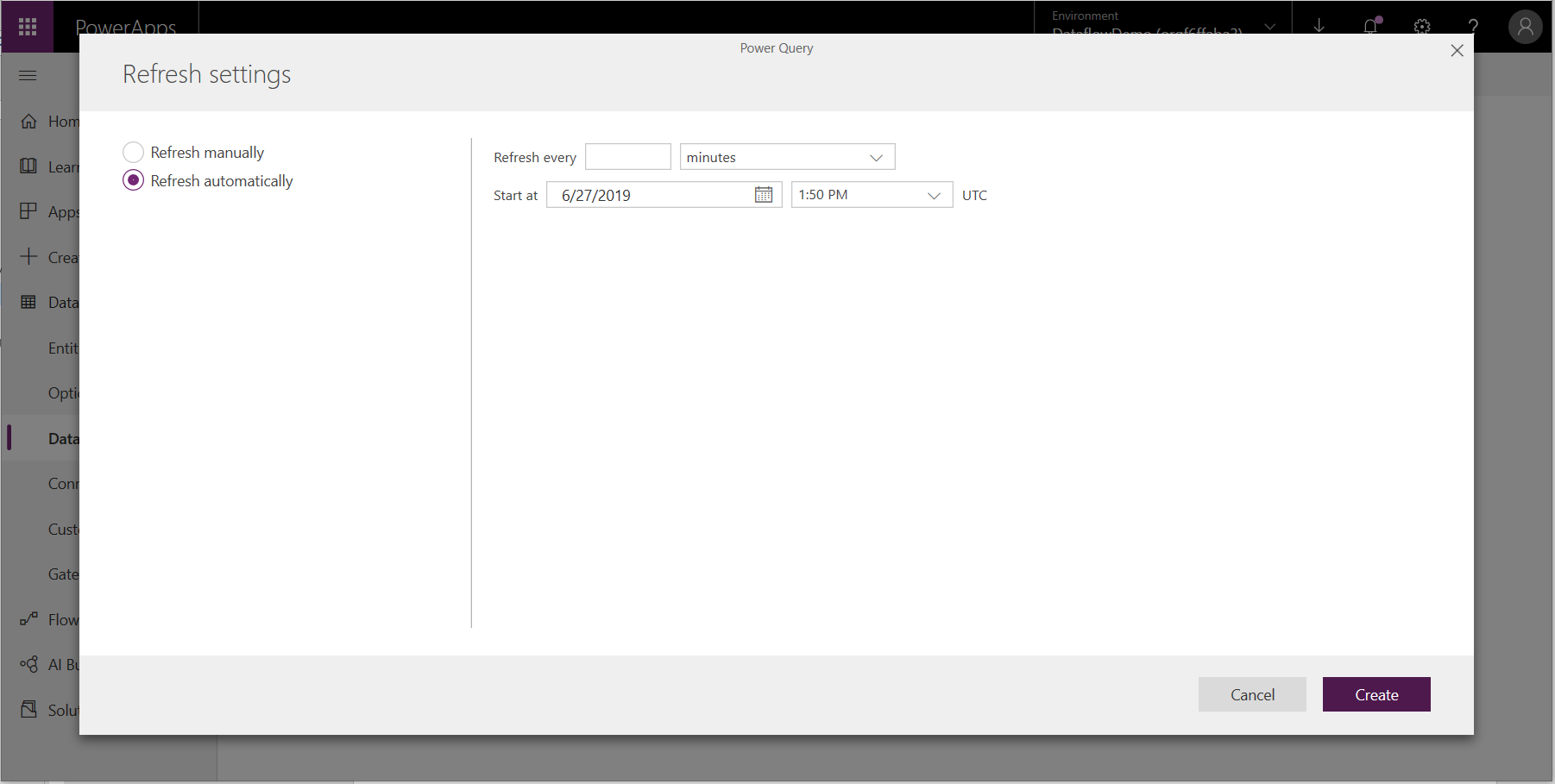
Entrez la fréquence d’actualisation du flux de données, la date et l’heure de début dans UTC.
Sélectionnez Créer.
Utilisation des flux de données stockés dans Azure Data Lake Storage Gen2
Certaines organisations peuvent utiliser leur propre stockage pour la création et la gestion des flux de données. Vous pouvez intégrer des flux de données avec Azure Data Lake Storage Gen2 si vous respectez les exigences d’installation du compte de stockage. Pour plus d’informations, voir : Connecter Azure Data Lake Storage Gen2 pour le stockage du flux de données
Résolution des problèmes liés aux connexions de données
Il peut arriver qu’il y ait des problèmes lors de la connexion aux sources de données pour les exécutions de flux de données. Cette section fournit des conseils de dépannage pour les problèmes rencontrés.
Connecteur Salesforce. L’utilisation d’un compte d’évaluation pour Salesforce avec des flux de données aboutit à un échec de connexion sans aucune explication. Pour résoudre ce problème, utilisez un compte de production Salesforce ou un compte de développeur à des fins de test.
Connecteur SharePoint. Vérifiez que vous ne fournissez bien l’adresse racine du site SharePoint, sans les sous-dossiers ou les documents. Par exemple, utilisez un lien similaire à
https://microsoft.sharepoint.com/teams/ObjectModel.Connecteur de fichier JSON. Actuellement, vous pouvez vous connecter à un fichier JSON à l’aide de l’authentification de base uniquement. Par exemple, une URL similaire à
https://XXXXX.blob.core.windows.net/path/file.json?sv=2019-01-01&si=something&sr=c&sig=123456abcdefgn’est pas actuellement prise en charge.Azure Synapse Analytics. Les flux de données ne sont pour l’instant pas compatibles avec l’authentification Azure Active Directory pour Azure Synapse Analytics. Utilisez l’authentification de base pour ce scénario.
Notes
Si vous utilisez des stratégies de protection contre la perte de données (DLP) pour bloquer le connecteur HTTP avec Microsoft Entra (préautorisé), alors les connecteurs SharePoint et OData échoueront. Le connecteur HTTP avec Microsoft Entra (préautorisé) doit être autorisé dans les stratégies DLP pour le bon fonctionnement des connecteurs SharePoint et OData.
Étapes suivantes
Les articles suivants sont utiles pour obtenir plus d’informations et de scénarios sur l’utilisation des flux de données :
Utilisation d’une passerelle de données locale dans les flux de données Power Platform
Connecter Azure Data Lake Storage Gen2 pour le stockage du flux de données
Pour plus d’informations sur Common Data Model :
Notes
Pouvez-vous nous indiquer vos préférences de langue pour la documentation ? Répondez à un court questionnaire. (veuillez noter que ce questionnaire est en anglais)
Le questionnaire vous prendra environ sept minutes. Aucune donnée personnelle n’est collectée (déclaration de confidentialité).
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour