Összesítő átalakítás a leképezési adatfolyamban
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Az adatfolyamok az Azure Data Factoryben és az Azure Synapse Pipelinesban is elérhetők. Ez a cikk az adatfolyamok leképezésére vonatkozik. Ha még nem használta az átalakításokat, tekintse meg az adatok leképezési adatfolyam használatával történő átalakításáról szóló bevezető cikket.
Az összesített átalakítás az adatfolyamok oszlopainak összesítését határozza meg. A Kifejezésszerkesztővel különböző típusú összesítéseket definiálhat, például a SUM, a MIN, a MAX és a COUNT függvényt meglévő vagy számított oszlopok szerint csoportosítva.
Csoportosítás szempontja:
Jelöljön ki egy meglévő oszlopot, vagy hozzon létre egy új számított oszlopot, amelyet az összesítéshez használ csoportonkénti záradékként. Meglévő oszlop használatához válassza ki a legördülő listából. Új számított oszlop létrehozásához vigye az egérmutatót a záradék fölé, és kattintson a Számított oszlop elemre. Ekkor megnyílik az adatfolyam-kifejezésszerkesztő. Miután létrehozta a számított oszlopot, adja meg a kimeneti oszlop nevét a Név mező alatt . Ha további csoportot szeretne hozzáadni záradék szerint, mutasson egy meglévő záradékra, és kattintson a plusz ikonra.
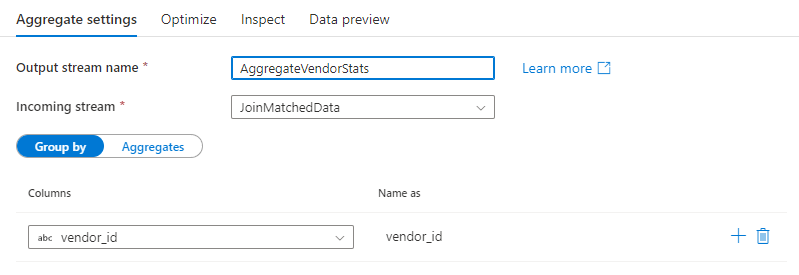
A csoportosítási záradék nem kötelező összesített átalakítás esetén.
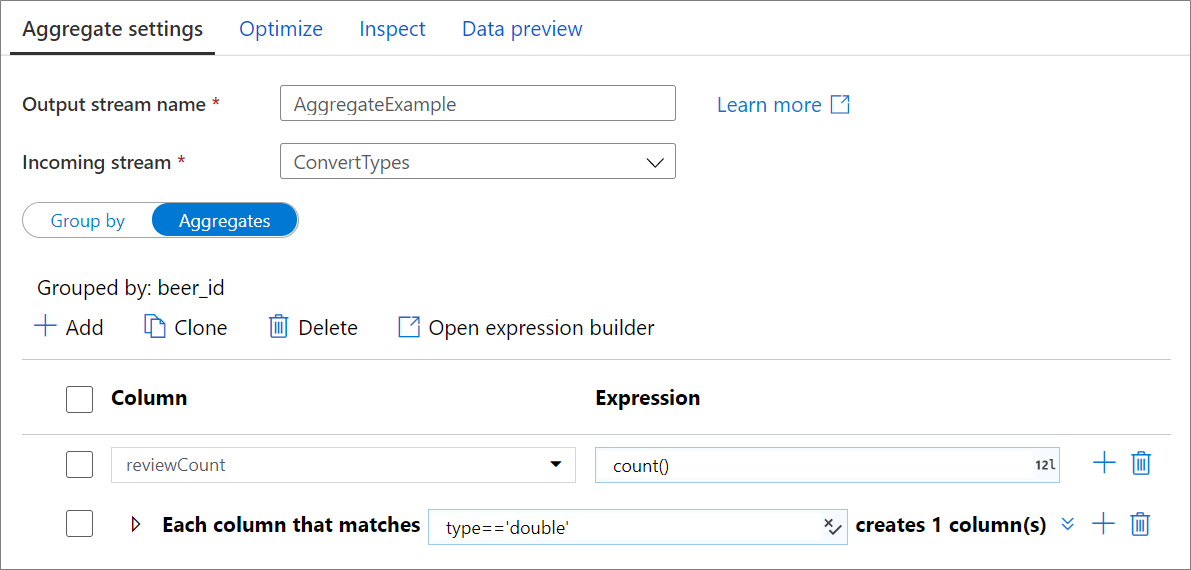
Oszlopok összesítése
Az összesítési kifejezések létrehozásához lépjen az Összesítések lapra. Felülírhat egy meglévő oszlopot összesítéssel, vagy létrehozhat egy új mezőt új névvel. Az aggregációs kifejezés a jobb oldali mezőbe kerül az oszlopnév-választó mellett. A kifejezés szerkesztéséhez kattintson a szövegdobozra, és nyissa meg a kifejezésszerkesztőt. További összesítő oszlopok hozzáadásához kattintson a Hozzáadás gombra az oszloplista fölött vagy a meglévő összesítő oszlop melletti plusz ikonra. Válassza az Oszlop hozzáadása vagy az Oszlopminta hozzáadása lehetőséget. Minden összesítési kifejezésnek legalább egy összesítő függvényt kell tartalmaznia.
Megjegyzés:
Hibakeresési módban a kifejezésszerkesztő nem tud összesítő függvényekkel rendelkező adatelőnézeteket létrehozni. Az összesítő átalakítások adatelőnézeteinek megtekintéséhez zárja be a kifejezésszerkesztőt, és tekintse meg az adatokat az "Adatok előnézete" lapon.
Oszlopminták
Az oszlopminták használatával ugyanazt az összesítést alkalmazhatja egy oszlopkészletre. Ez akkor hasznos, ha a bemeneti sémából több oszlopot is meg szeretne őrizni, mivel alapértelmezés szerint elveti őket. Használjon heurisztikus megoldást, például first() a bemeneti oszlopok aggregáción keresztüli megőrzéséhez.
Sorok és oszlopok újracsatlakoztatása
Az összesítési átalakítások hasonlóak az SQL-összesítő választó lekérdezésekhez. Azok az oszlopok, amelyek nem szerepelnek a csoport záradék vagy összesítő függvények szerint, nem haladnak át az összesített átalakítás kimenetén. Ha más oszlopokat is fel szeretne venni az összesített kimenetbe, hajtsa végre az alábbi módszerek egyikét:
- Használjon aggregátumfüggvényt, például
last()first()a további oszlopot. - Csatlakozzon újra az oszlopokhoz a kimeneti adatfolyamhoz az önillesztési mintával.
Ismétlődő sorok eltávolítása
Az összesítési átalakítás gyakori használata a forrásadatok ismétlődő bejegyzéseinek eltávolítása vagy azonosítása. Ezt a folyamatot deduplikációnak nevezzük. A kulcsok szerinti csoport alapján válasszon egy heurisztikus megoldást, amellyel meghatározhatja, hogy melyik ismétlődő sort tartsa meg. A gyakori heurisztika a first(), last()és max()min(). Oszlopminták használatával a szabályt minden oszlopra alkalmazhatja, kivéve a csoportonkénti oszlopokat.
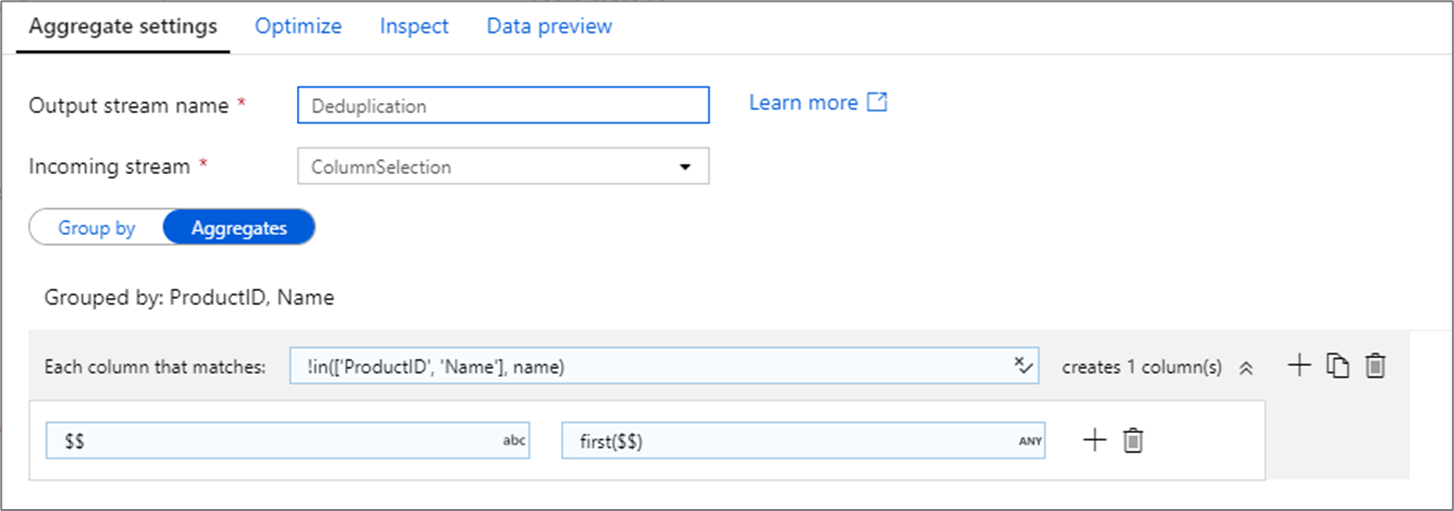
A fenti példában oszlopok ProductID vannak, és Name csoportosításhoz vannak használva. Ha két sor ugyanazokkal az értékekkel rendelkezik a két oszlophoz, azok duplikáltnak minősülnek. Ebben az összesített átalakításban a rendszer megtartja az első egyező sor értékeit, és az összes többit elveti. Az oszlopminta szintaxisával minden olyan oszlop, amelynek a neve nem ProductID szerepel, és Name a meglévő oszlopnévhez van megfeleltetve, és az első egyező sorok értékét adja meg. A kimeneti séma megegyezik a bemeneti sémával.
Adatérvényesítési forgatókönyvek esetén a függvény használható a count() duplikált példányok számának megszámlálására.
Adatfolyamszkript
Syntax
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Példa
Az alábbi példa egy bejövő streamet MoviesYear vesz fel, és oszloponként yearcsoportosítja a sorokat. Az átalakítás létrehoz egy összesített oszlopot avgrating , amely az oszlop Ratingátlagát értékeli ki. Ez az összesített átalakítás neve AvgComedyRatingsByYear.
A felhasználói felületen ez az átalakítás az alábbi képhez hasonlóan néz ki:
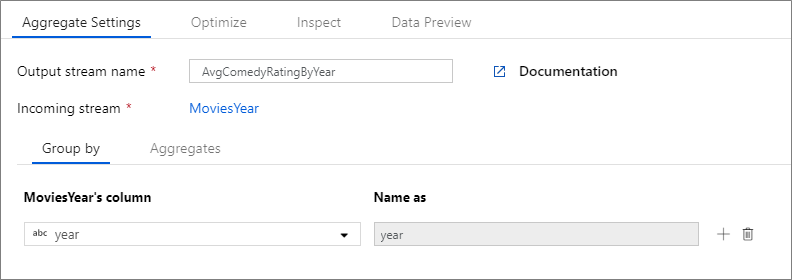
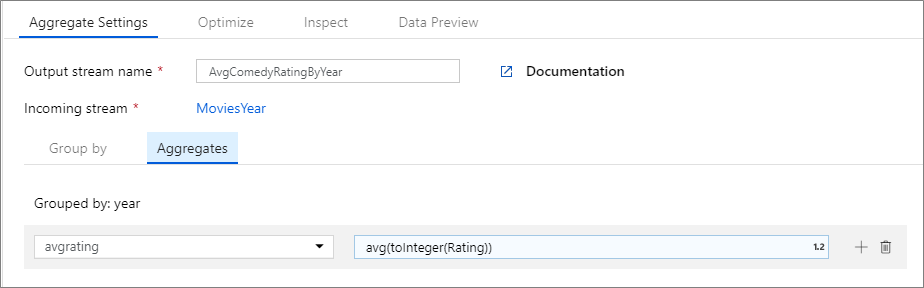
Az átalakítás adatfolyam-szkriptje az alábbi kódrészletben található.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
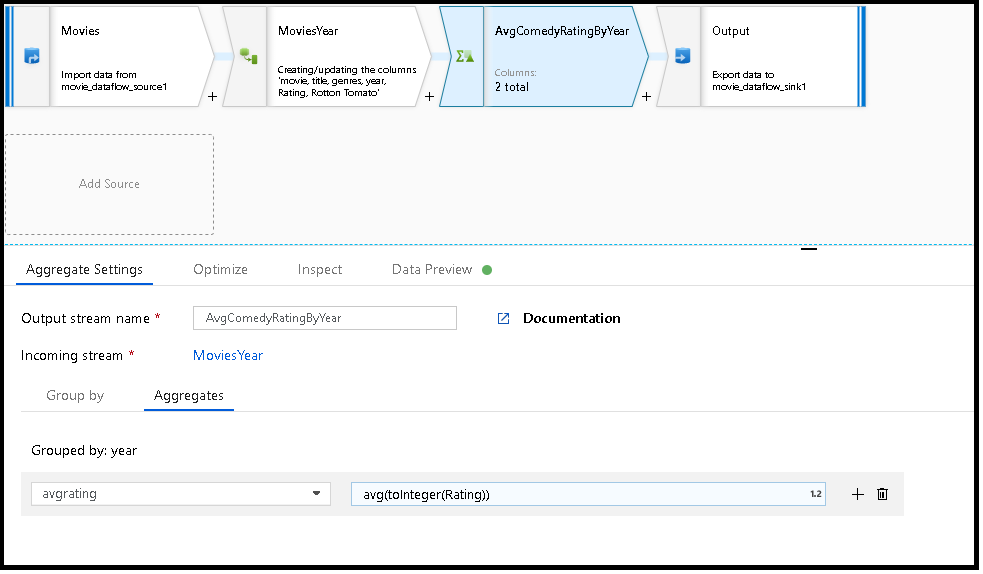
MoviesYear: Év- és címoszlopokat AvgComedyRatingByYearmeghatározó származtatott oszlop: A komikák átlagos minősítésének összesített átalakítása év avgratingszerint csoportosítva: Az összesített érték tárolásához létrehozandó új oszlop neve
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Kapcsolódó tartalom
- Ablakalapú összesítés definiálása az Ablak átalakítással