Kifejezések létrehozása a leképezési adatfolyamban
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
A leképezési adatfolyamban a rendszer számos átalakítási tulajdonságot kifejezésként ad meg. Ezek a kifejezések oszlopértékekből, paraméterekből, függvényekből, operátorokból és literálokból állnak, amelyek futtatáskor Spark-adattípusra értékelnek. Az adatfolyamok leképezése dedikált felülettel rendelkezik, amelynek célja, hogy segítséget nyújtsunk ezeknek a kifejezéseknek a Kifejezésszerkesztőnek a létrehozásában. Az IntelliSense kódkiegészítését a kiemeléshez, a szintaxis-ellenőrzéshez és az automatikus kiegészítéshez használva a kifejezésszerkesztő úgy lett kialakítva, hogy megkönnyítse az adatfolyamok létrehozását. Ez a cikk bemutatja, hogyan hozhatja létre hatékonyan üzleti logikáját a kifejezésszerkesztő használatával.
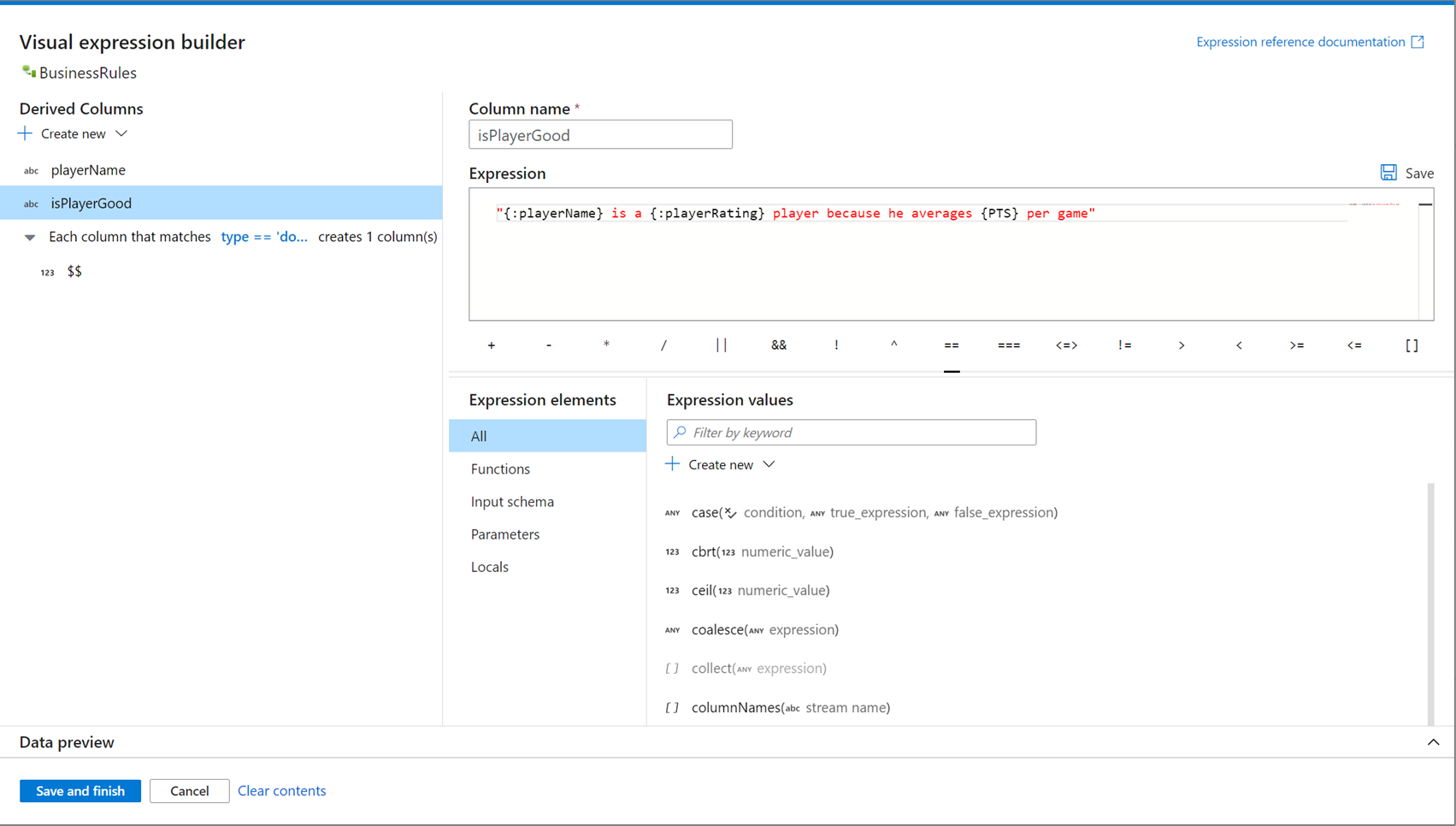
A Kifejezésszerkesztő megnyitása
A kifejezésszerkesztő megnyitásához több belépési pont is rendelkezésre áll. Ezek mind az adatfolyam-átalakítás adott környezetétől függenek. A leggyakoribb használati eset az olyan átalakítások, mint a származtatott oszlop és az összesítés , ahol a felhasználók az adatfolyam-kifejezés nyelvével hoznak létre vagy frissítenek oszlopokat. A kifejezésszerkesztő az oszlopok listája fölötti Kifejezésszerkesztő megnyitása lehetőséget választva nyitható meg. Kijelölhet egy oszlopkörnyezetet is, és közvetlenül az adott kifejezéshez nyithatja meg a kifejezésszerkesztőt.
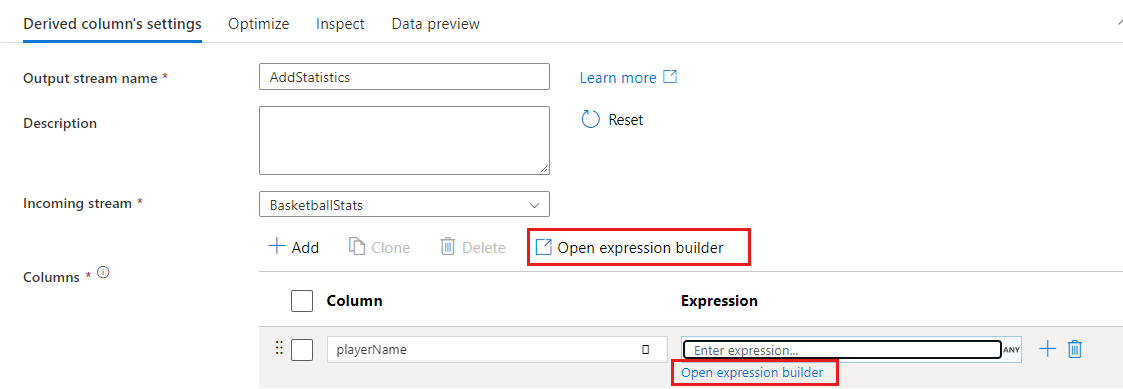
Bizonyos átalakításokban, például a szűrőben a kék kifejezés szövegmezőre kattintva megnyílik a kifejezésszerkesztő.
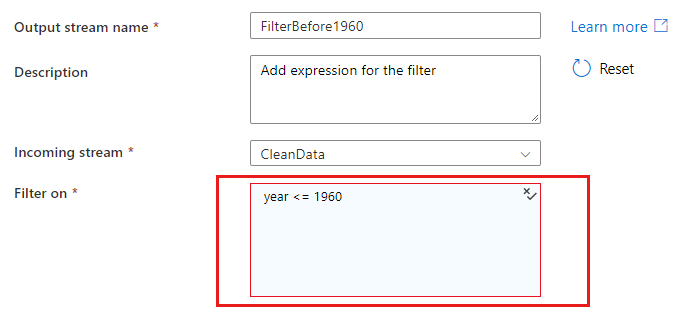
Ha egy egyező vagy csoportosítási feltételben lévő oszlopokra hivatkozik, egy kifejezés kinyerheti az oszlopokból az értékeket. Kifejezés létrehozásához válassza a Számított oszlop lehetőséget.

Ha egy kifejezés vagy egy literális érték érvényes bemenet, válassza a Dinamikus tartalom hozzáadása lehetőséget egy olyan kifejezés létrehozásához, amely literális értékre értékel.

Kifejezéselemek
Az adatfolyamok leképezése során a kifejezések oszlopértékekből, paraméterekből, függvényekből, helyi változókból, operátorokból és literálokból állhatnak. Ezeknek a kifejezéseknek Spark-adattípusra, például sztringre, logikai értékre vagy egész számra kell kiértékelniük.
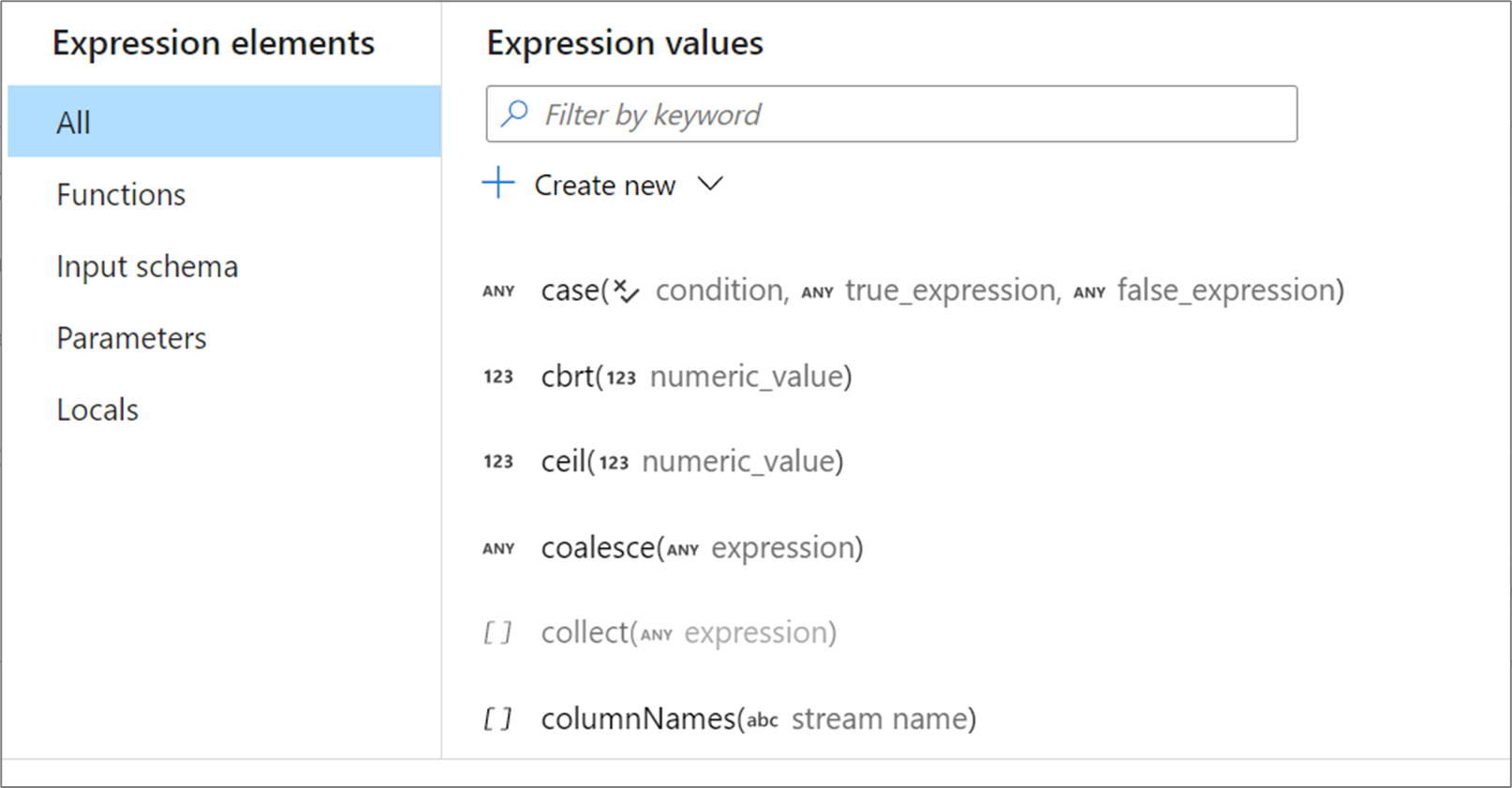
Funkciók
Az adatfolyamok leképezése beépített függvényekkel és operátorokkal rendelkezik, amelyek a kifejezésekben használhatók. Az elérhető függvények listáját a leképezési adatfolyam nyelvi referenciája tartalmazza.
Felhasználó által definiált függvények (előzetes verzió)
Az adatfolyamok leképezése támogatja a felhasználó által definiált függvények létrehozását és használatát. A felhasználó által definiált függvények létrehozásáról és használatáról a felhasználó által definiált függvények című témakörben olvashat.
Címtömbindexek
Ha tömbtípusokat visszaadó oszlopokkal vagy függvényekkel foglalkozik, szögletes zárójelek ([]) használatával érhet el egy adott elemet. Ha az index nem létezik, a kifejezés null értékű lesz.
Fontos
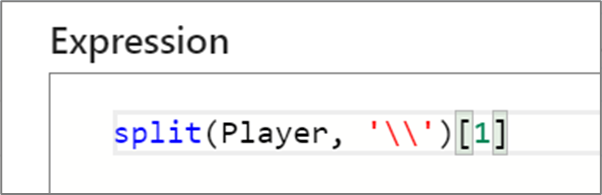
Az adatfolyamok leképezése során a tömbök egy-alapúak, ami azt jelenti, hogy az első elemre az index 1 hivatkozik. A myArray[1] például a "myArray" nevű tömb első eleméhez fog hozzáférni.
Bemeneti séma
Ha az adatfolyam egy meghatározott sémát használ bármelyik forrásában, számos kifejezésben hivatkozhat név szerint egy oszlopra. Ha sémaeltolódást használ, az oszlopokra kifejezetten hivatkozhat a függvények vagy byNames() függvények byName() használatával, vagy oszlopminták használatával egyezhet.
Speciális karaktereket tartalmazó oszlopnevek
Ha speciális karaktereket vagy szóközöket tartalmazó oszlopneveket használ, a nevet kapcsos zárójelekkel körülvéve hivatkozzon rájuk egy kifejezésben.
{[dbo].this_is my complex name$$$}
Parameters
A paraméterek olyan értékek, amelyek egy folyamat futásidejű adatfolyamába kerülnek. Ha egy paraméterre szeretne hivatkozni, válassza ki a paramétert a Kifejezéselemek nézetből, vagy hivatkozzon rá egy dollárjellel a neve előtt. Például egy paraméter1 nevű paraméterre hivatkozik a $parameter1függvény. További információkért tekintse meg a leképezési adatfolyamok paraméterezését.
Gyorsítótárazott keresés
A gyorsítótárazott keresések lehetővé teszik a gyorsítótárazott fogadó kimenetének beágyazott keresését. Az egyes fogadókhoz két függvény használható, lookup() és outputs()a . A függvények hivatkozásának szintaxisa: cacheSinkName#functionName(). További információ: gyorsítótár-fogadók.
lookup() az aktuális átalakítás megfelelő oszlopait veszi fel paraméterekként, és a gyorsítótár-fogadó kulcsoszlopainak megfelelő sornak megfelelő komplex oszlopot ad vissza. A visszaadott összetett oszlop a gyorsítótár-fogadóban leképezett összes oszlophoz tartalmaz egy aloszlopot. Ha például hibakód-gyorsítótár-fogadója errorCodeCache volt, amelynek kulcsoszlopa megfelelt a kódnak és egy úgynevezett oszlopnak Message. A hívás errorCodeCache#lookup(errorCode).Message a megadott kódnak megfelelő üzenetet adja vissza.
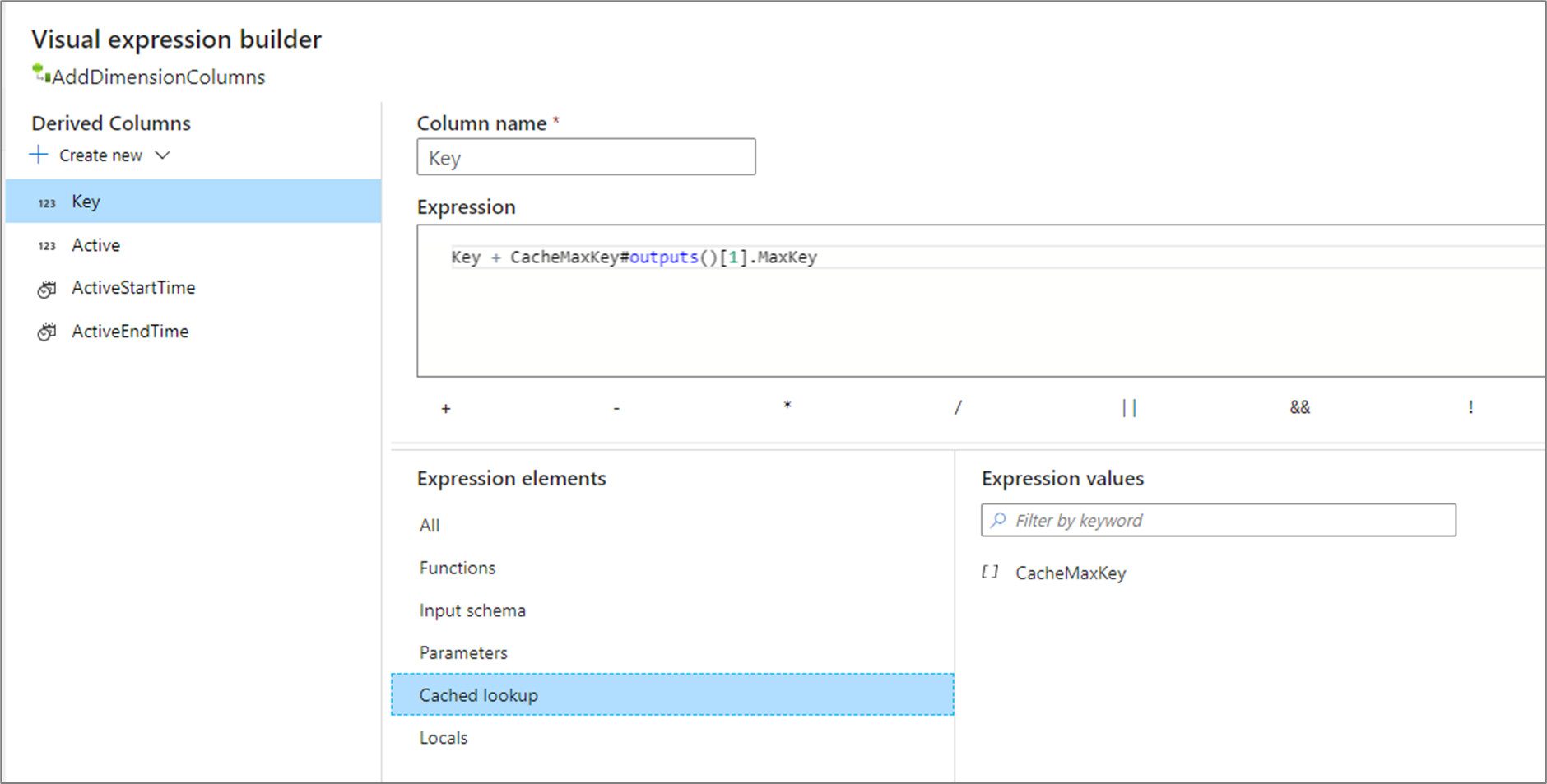
outputs() nem használ paramétereket, és a teljes gyorsítótár-fogadót komplex oszlopok tömbjeként adja vissza. Ez nem hívható meg, ha a fogadóban kulcsoszlopok vannak megadva, és csak akkor használható, ha a gyorsítótár-fogadóban van néhány sor. Gyakori használati eset egy növekményes kulcs maximális értékének hozzáfűzése. Ha egy gyorsítótárazott egyetlen összesített sor CacheMaxKey tartalmaz egy oszlopot MaxKey, az első értékre hivatkozhat a hívással CacheMaxKey#outputs()[1].MaxKey.
Locals
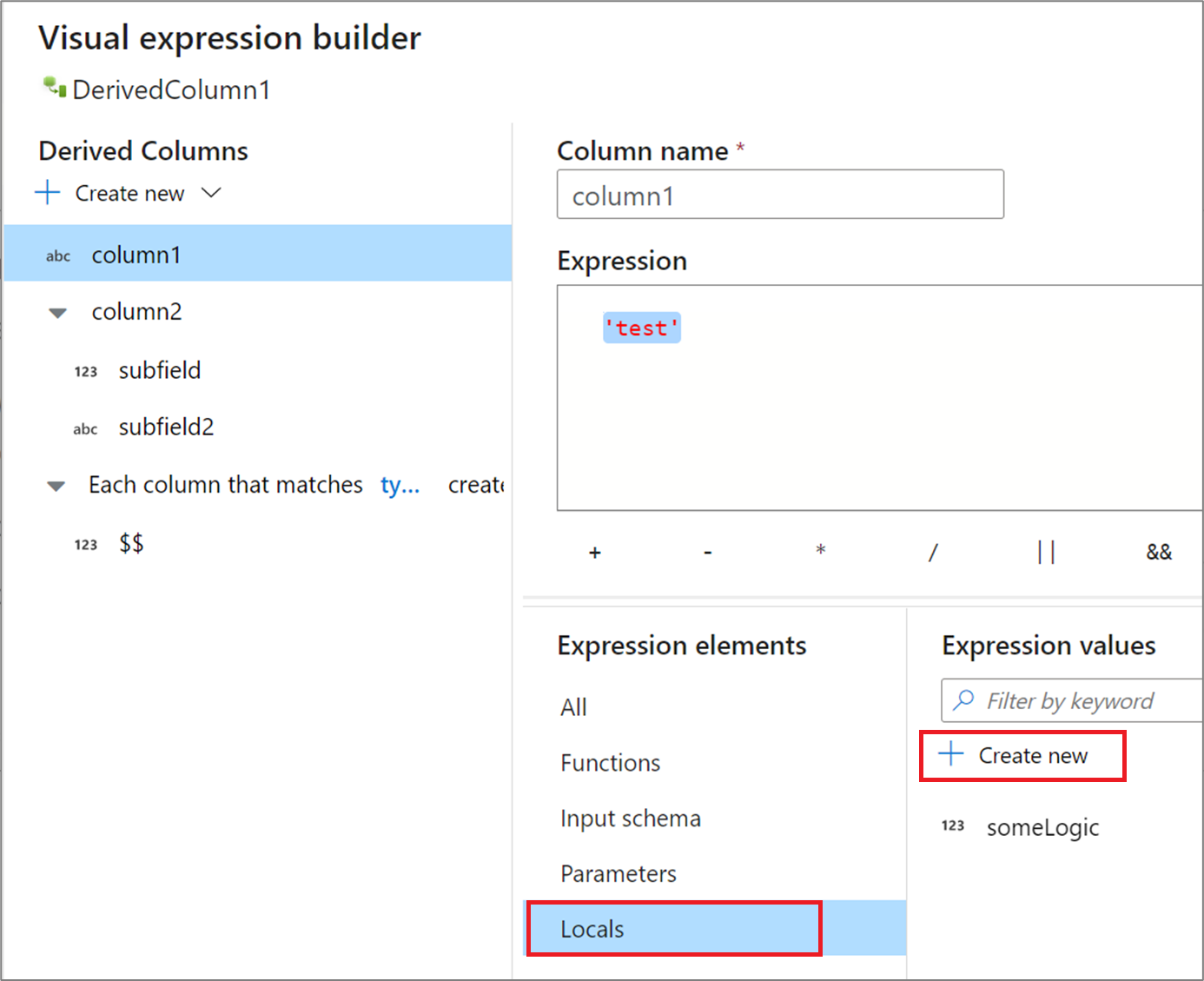
Ha több oszlopban osztja meg a logikát, vagy el szeretné osztani a logikát, létrehozhat egy helyi változót. A helyi egy logikai készlet, amely nem lesz propagálás alatt a következő átalakításhoz. A helyiek a kifejezésszerkesztőben hozhatók létre a Kifejezéselemek és a Helyiek lehetőség kiválasztásával. Hozzon létre egy újat az Új létrehozása gombra kattintva.
A helyiek bármilyen kifejezéselemre hivatkozhatnak, beleértve a függvényeket, a bemeneti sémát, a paramétereket és más helyi elemeket. Más helyiekre való hivatkozáskor a sorrend nem számít, mivel a hivatkozott helyinek a jelenleginél "feljebb" kell lennie.
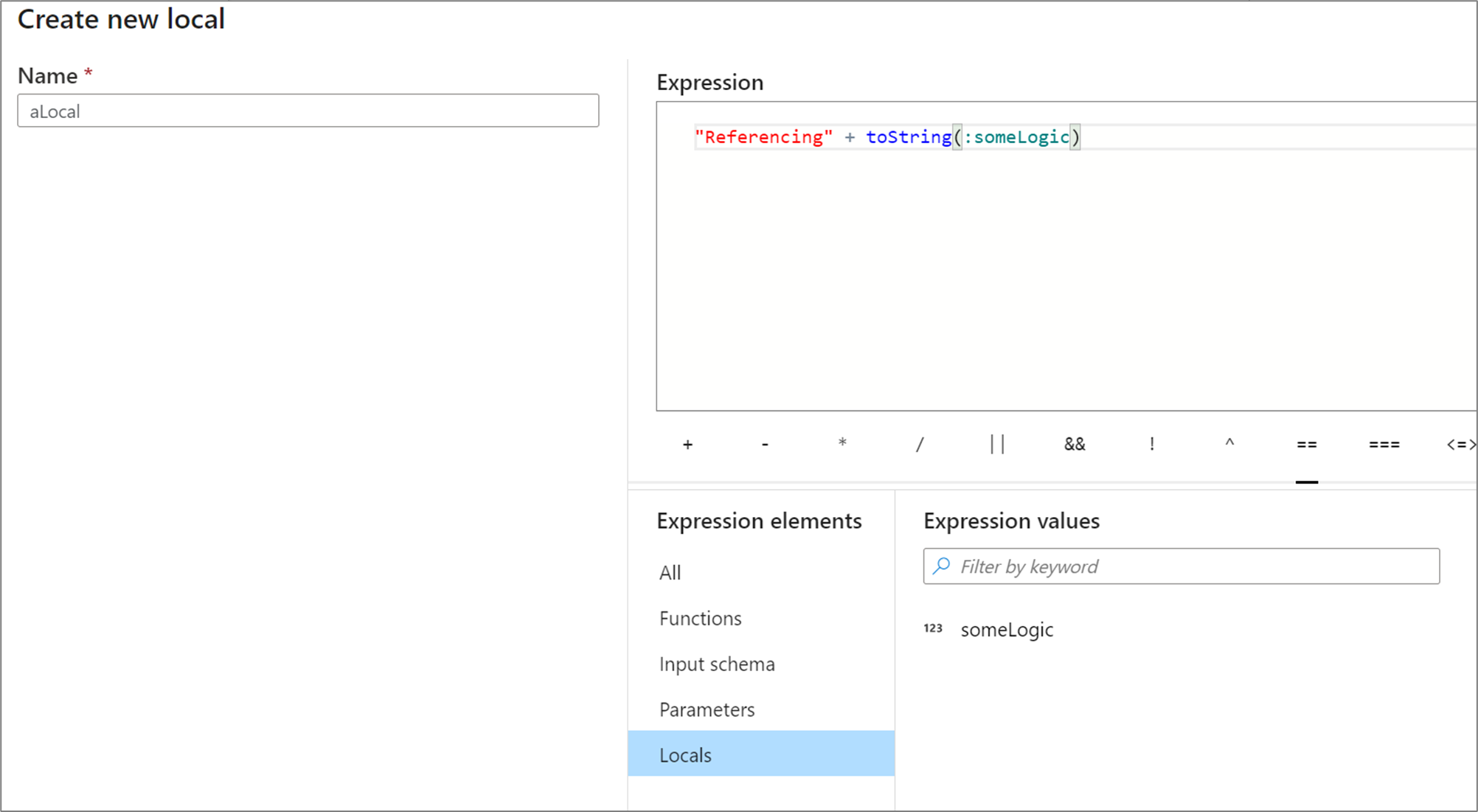
Ha helyire szeretne hivatkozni egy átalakításban, válassza ki a helyit a Kifejezéselemek nézetből, vagy hivatkozzon rá kettősponttal a neve előtt. Például egy helyi1 nevű helyire hivatkozik :local1a rendszer. Helyi definíció szerkesztéséhez mutasson rá a kifejezéselemek nézetben, és válassza a ceruza ikont.
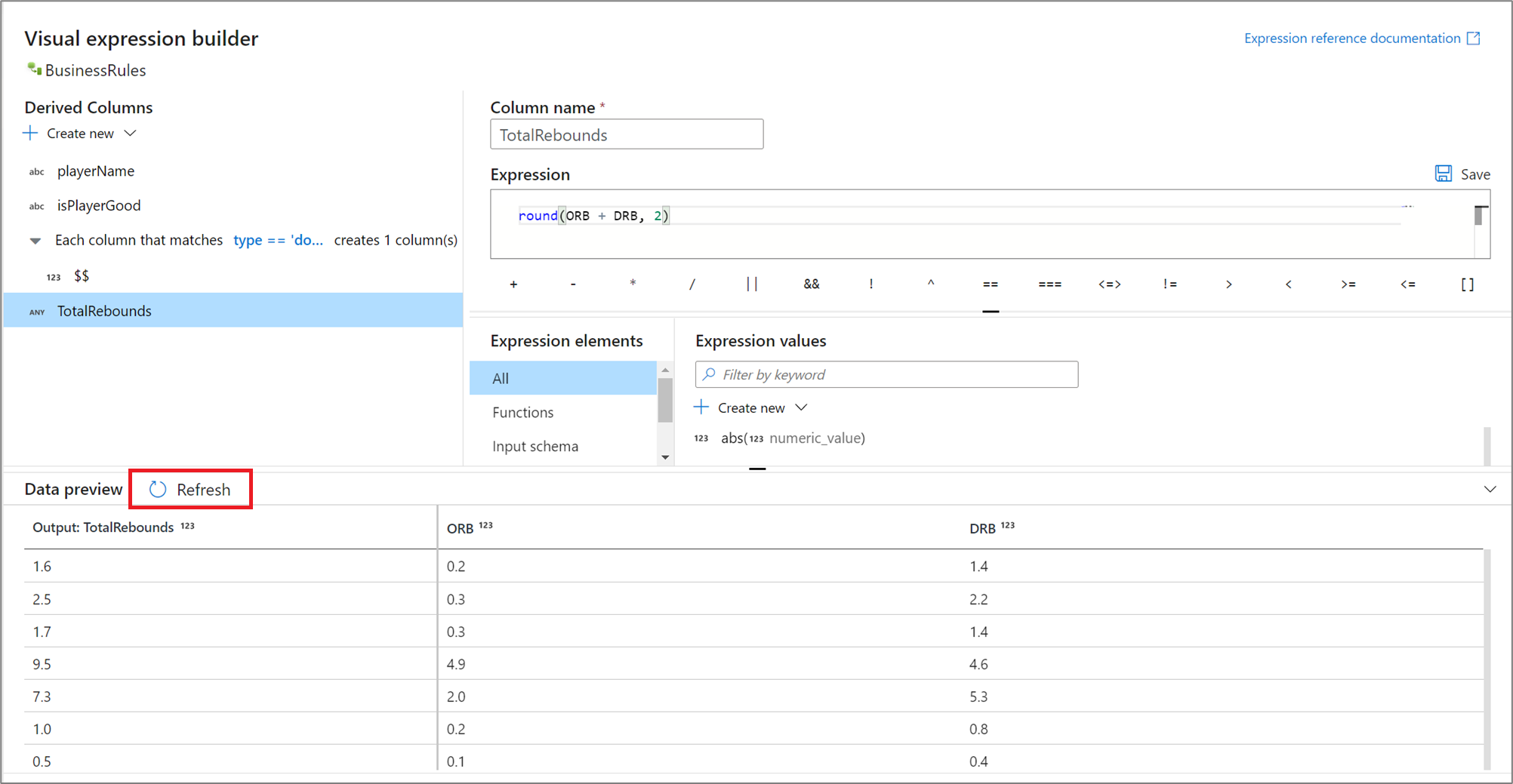
Előnézeti kifejezés eredményei
Ha a hibakeresési mód be van kapcsolva, interaktív módon használhatja a hibakeresési fürtöt a kifejezés kiértékelésének előnézetéhez. Az adatok előnézete mellett válassza a Frissítés lehetőséget az adatelőnézet eredményeinek frissítéséhez. Az egyes sorok kimenetét a bemeneti oszlopok alapján tekintheti meg.
Sztring interpolációja
Kifejezéselemeket használó hosszú sztringek létrehozásakor sztringinterpolációval egyszerűen hozhat létre összetett sztringlogikát. A sztringek interpolációja elkerüli a sztringösszefűzés széles körű használatát, ha a paramétereket a lekérdezési sztringek tartalmazzák. Kettős idézőjelek használatával konstans sztringszöveget csatolhat kifejezésekhez. Kifejezésfüggvényeket, oszlopokat és paramétereket is tartalmazhat. A kifejezés szintaxisának használatához kapcsos zárójelekbe kell tenni,
Néhány példa a sztring interpolációjára:
"My favorite movie is {iif(instr(title,', The')>0,"The {split(title,', The')[1]}",title)}""select * from {$tablename} where orderyear > {$year}""Total cost with sales tax is {round(totalcost * 1.08,2)}""{:playerName} is a {:playerRating} player"
Megjegyzés:
Ha sztringinterpolációs szintaxist használ az SQL-forrás lekérdezésekben, a lekérdezési sztringnek egyetlen sorban kell lennie, "/n" nélkül.
Megjegyzés-kifejezések
Megjegyzések hozzáadása a kifejezésekhez egysoros és többsoros megjegyzésszintaxis használatával.
Az alábbi példák érvényes megjegyzések:
/* This is my comment *//* This is amulti-line comment */
Ha megjegyzést fűz a kifejezés elejéhez, az az átalakítási szövegmezőben jelenik meg az átalakítási kifejezések dokumentálásához.

Reguláris kifejezések
Számos kifejezésnyelvi függvény használ reguláris kifejezésszintaxist. Reguláris kifejezésfüggvények használata esetén a Expression Builder egy fordított perjelet (\) próbál feloldó karaktersorozatként értelmezni. Ha fordított perjeleket használ a reguláris kifejezésben, akkor vagy a teljes regexet mellékelje a backticks (') alá, vagy használjon dupla fordított perjelet.
Példa a backticks használatára:
regex_replace('100 and 200', `(\d+)`, 'digits')
Példa kettős perjelekre:
regex_replace('100 and 200', '(\\d+)', 'digits')
Billentyűparancsok
Az alábbiakban a kifejezésszerkesztőben elérhető billentyűparancsok listája látható. A kifejezések létrehozásakor a legtöbb intellisense-parancsikon elérhető.
- Ctrl+K Ctrl+C: Teljes sor megjegyzése.
- Ctrl+K Ctrl+U: Megjegyzés feloldása.
- F1: Adjon meg szerkesztői súgóparancsokat.
- Alt+Le nyílbillentyű: Lépés lefelé az aktuális vonalon.
- Alt+Fel nyílbillentyű: Feljebb az aktuális vonalon.
- Ctrl+Szóköz: A környezet súgójának megjelenítése.
Gyakran használt kifejezések
Konvertálás dátumokra vagy időbélyegekké
Ha sztringkonstansokat szeretne belefoglalni az időbélyeg kimenetbe, csomagolja be a konvertálást.toString()
toString(toTimestamp('12/31/2016T00:12:00', 'MM/dd/yyyy\'T\'HH:mm:ss'), 'MM/dd /yyyy\'T\'HH:mm:ss')
Az ezredmásodperceket a korszakból dátummá vagy időbélyeggé alakíthatja, használja a következőt toTimestamp(<number of milliseconds>): . Ha az idő másodpercben jön, szorozza meg az 1000-et.
toTimestamp(1574127407*1000l)
Az előző kifejezés végén található záró "l" azt jelzi, hogy az átalakítás hosszú típusra, mint beágyazott szintaxis.
Idő keresése a korszakból vagy unix időpontból
toLong( currentTimestamp() - toTimestamp('1970-01-01 00:00:00.000', 'yyyy-MM-dd HH:mm:ss. SSS') ) * 1000l
Adatfolyam-idő kiértékelése
Az adatfolyamok ezredmásodpercig feldolgozhatók. A 2018-07-31T20:00:00.2170000 esetében a 2018-07-31T20:00:00.217 kimenet jelenik meg. A szolgáltatás portálján az időbélyeg az aktuális böngészőbeállításban jelenik meg, amely kiküszöbölheti a 217-et, de ha az adatfolyamot a végéig futtatja, 217 (ezredmásodpercben is feldolgozva). A toString(myDateTimeColumn) kifejezésként használható, és megtekintheti a teljes pontosságú adatokat előzetes verzióban. A datetime-t sztring helyett dátumidőként dolgozza fel minden gyakorlati célra.