Fogadóátalakítás a leképezési adatfolyamban
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Az adatfolyamok az Azure Data Factoryben és az Azure Synapse Pipelinesban is elérhetők. Ez a cikk az adatfolyamok leképezésére vonatkozik. Ha még nem használta az átalakításokat, tekintse meg az adatok leképezési adatfolyam használatával történő átalakításáról szóló bevezető cikket.
Miután befejezte az adatok átalakítását, írja be egy céltárolóba a fogadó átalakításával. Minden adatfolyamhoz legalább egy fogadóátalakítás szükséges, de annyi fogadóba írhat, amennyi szükséges az átalakítási folyamat befejezéséhez. Ha további fogadókba szeretne írni, hozzon létre új streameket új ágakon és feltételes felosztásokon keresztül.
Minden fogadóátalakítás pontosan egy adathalmaz-objektumhoz vagy társított szolgáltatáshoz van társítva. A fogadó transzformációja határozza meg azoknak az adatoknak az alakját és helyét, amelyeket írni szeretne.
Beágyazott adatkészletek
Fogadóátalakítás létrehozásakor adja meg, hogy a fogadó adatai egy adathalmaz-objektumon belül vagy a fogadó átalakításán belül vannak-e definiálva. A legtöbb formátum csak az egyikben vagy a másikban érhető el. Ha tudni szeretné, hogyan használhat egy adott összekötőt, tekintse meg a megfelelő összekötő dokumentumot.
Ha a formátumok beágyazott és adathalmaz-objektumokban is támogatottak, mindkettőnek vannak előnyei. Az adathalmaz-objektumok olyan újrafelhasználható entitások, amelyek más adatfolyamokban és tevékenységekben, például a Másolásban is használhatók. Ezek az újrahasználható entitások különösen hasznosak, ha megerősített sémát használ. Az adathalmazok nem a Sparkban alapulnak. Időnként előfordulhat, hogy felül kell bírálnia bizonyos beállításokat vagy sémavetítést a fogadóátalakítás során.
A beágyazott adatkészletek rugalmas sémák, egyszeri fogadópéldányok vagy paraméteres fogadók használata esetén ajánlottak. Ha a fogadó erősen paraméterezett, a beágyazott adatkészletek lehetővé teszik, hogy ne hozzon létre "dummy" objektumot. A beágyazott adathalmazok a Sparkban alapulnak, és tulajdonságaik natívak az adatfolyamban.
Beágyazott adatkészlet használatához válassza ki a kívánt formátumot a Fogadó típusa választóban. Fogadóadatkészlet kiválasztása helyett válassza ki azt a társított szolgáltatást, amelyhez csatlakozni szeretne.
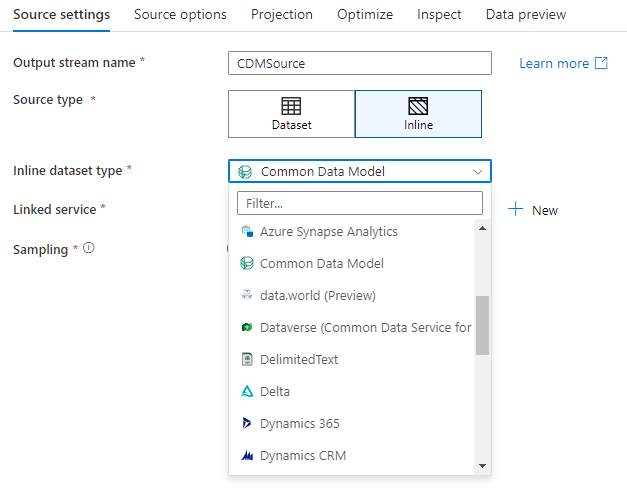
Munkaterület adatbázisa (csak Synapse-munkaterületek)
Ha adatfolyamokat használ az Azure Synapse-munkaterületeken, lehetősége lesz arra, hogy közvetlenül a Synapse-munkaterületen belüli adatbázistípusba süllyesztse az adatokat. Ez enyhíti a csatolt szolgáltatások vagy adathalmazok hozzáadásának szükségességét ezekhez az adatbázisokhoz. Az Azure Synapse-adatbázissablonokkal létrehozott adatbázisok a Workspace DB kiválasztásakor is elérhetők.
Feljegyzés
Az Azure Synapse Workspace DB-összekötő jelenleg nyilvános előzetes verzióban érhető el, és jelenleg csak Spark Lake-adatbázisokkal használható
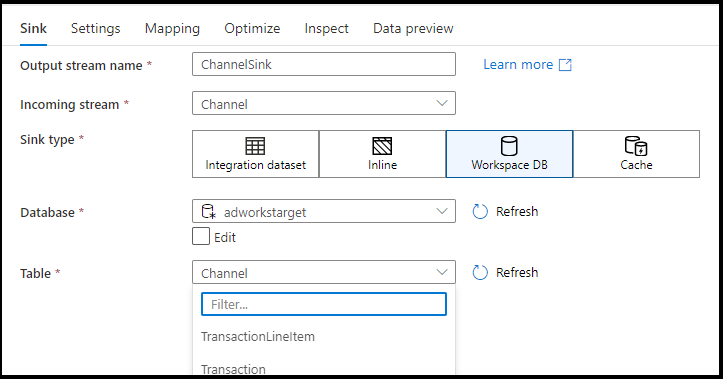
Támogatott fogadótípusok
A leképezési adatfolyam kinyerési, betöltési és átalakítási (ELT) megközelítést követ, és az Azure-ban található átmeneti adathalmazokkal működik. Jelenleg a következő adathalmazok használhatók fogadóátalakításban.
| Összekötő | Formátum | Adatkészlet/beágyazott |
|---|---|---|
| Azure Blob Storage | Avro Tagolt szöveg Delta JSON ORK Parketta |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| 1. generációs Azure Data Lake Storage | Avro Tagolt szöveg JSON ORK Parketta |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 | Avro Common Data Model Tagolt szöveg Delta JSON ORK Parketta |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Felügyelt Azure SQL-példány | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric Lakehouse | ✓/✓ | |
| SFTP | Avro Tagolt szöveg JSON ORK Parketta |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ |
Gépház ezekre az összekötőkre vonatkozó információk a Gépház lapon találhatók. A beállításokra vonatkozó információk és adatfolyam-szkriptek az összekötő dokumentációjában találhatók.
A szolgáltatás több mint 90 natív összekötőhöz rendelkezik hozzáféréssel. Ha az adatfolyamból más forrásokba szeretne adatokat írni, a Másolási tevékenység használatával töltse be az adatokat egy támogatott fogadóból.
Fogadó beállításai
Miután hozzáadott egy fogadót, konfiguráljon a Fogadó lapon. Itt kiválaszthatja vagy létrehozhatja azt az adathalmazt, amelybe a fogadó ír. Az adathalmaz-paraméterek fejlesztési értékei a hibakeresési beállításokban konfigurálhatók. (A hibakeresési módot be kell kapcsolni.)
Az alábbi videó számos különböző fogadóbeállítást ismertet a szöveggel tagolt fájltípusokhoz.
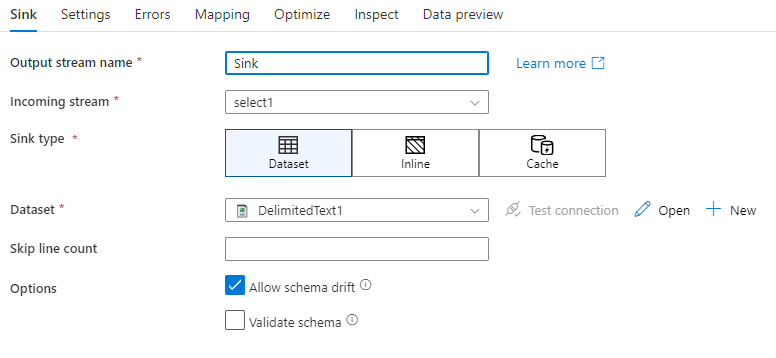
Sémaeltolódás: A sémaeltolódás az a képesség, hogy a szolgáltatás natív módon kezelje az adatfolyamok rugalmas sémáit anélkül, hogy explicit módon kellene meghatároznia az oszlopmódosításokat. Engedélyezze a sémaeltolódás engedélyezését, hogy további oszlopokat írjon a fogadó adatsémában meghatározottak fölé.
Séma érvényesítése: Ha a séma ellenőrzése ki van jelölve, az adatfolyam meghiúsul, ha a fogadó-vetítés egyik oszlopa sem található a fogadótárban, vagy ha az adattípusok nem egyeznek. Ezzel a beállítással kényszerítheti, hogy a fogadóséma megfeleljen a meghatározott vetület szerződésének. Adatbázis-fogadó forgatókönyvekben hasznos, ha jelzi, hogy az oszlopnevek vagy -típusok megváltoztak.
Gyorsítótár-fogadó
A gyorsítótár-fogadó az, amikor egy adatfolyam adattár helyett adatokat ír a Spark-gyorsítótárba. Az adatfolyamok leképezése során a gyorsítótár-kereséssel sokszor hivatkozhat ezekre az adatokra ugyanazon a folyamaton belül. Ez akkor hasznos, ha egy kifejezés részeként szeretne adatokra hivatkozni, de nem szeretné explicit módon összekapcsolni az oszlopokat. Gyakori példák, amelyekben a gyorsítótár-fogadó segíthet egy adattár maximális értékének keresésében, valamint a hibakódok egy hibaüzenet-adatbázishoz való egyeztetésében.
Ha egy gyorsítótár-fogadóba szeretne írni, vegyen fel egy fogadóátalakítást, és válassza a Gyorsítótárat fogadótípusként. Más fogadótípusoktól eltérően nem kell adathalmazt vagy társított szolgáltatást választania, mert nem külső tárolóba ír.
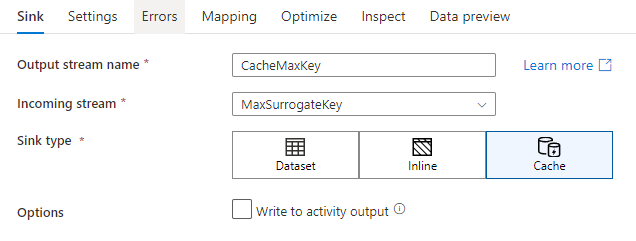
A fogadó beállításaiban opcionálisan megadhatja a gyorsítótár-fogadó kulcsoszlopait. Ezek egyező feltételekként használatosak a lookup() függvény gyorsítótár-keresésben való használatakor. Ha kulcsoszlopokat ad meg, nem használhatja a függvényt a outputs() gyorsítótár-keresésben. A gyorsítótár keresési szintaxisával kapcsolatos további információkért lásd a gyorsítótárazott kereséseket.
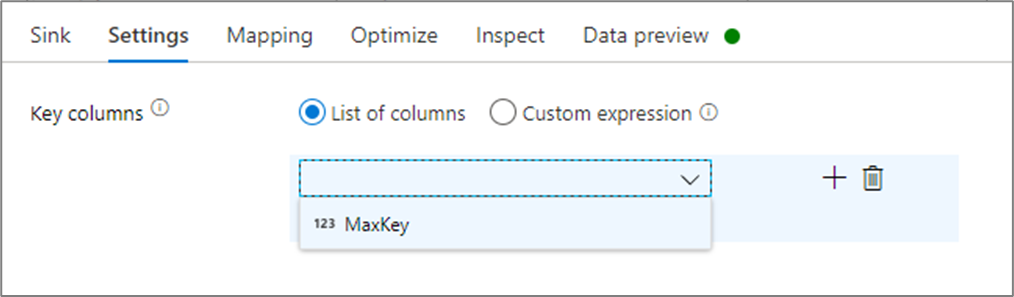
Ha például egyetlen kulcsoszlopot column1 adnék meg egy gyorsítótár-fogadóban, a cacheExamplehíváshoz cacheExample#lookup() egy paraméter adja meg, hogy a gyorsítótár-fogadó melyik sora feleljen meg. A függvény egyetlen összetett oszlopot ad ki az egyes leképezett oszlopokhoz tartozó aloszlopokkal.
Feljegyzés
A gyorsítótár-fogadónak teljesen független adatfolyamban kell lennie minden olyan átalakítástól, amely a gyorsítótár-keresésen keresztül hivatkozik rá. A gyorsítótár-fogadónak is az első megírt fogadónak kell lennie.
Írás tevékenységkimenetbe : A gyorsítótárazott fogadó opcionálisan a következő folyamattevékenység bemenetére is megírhatja a kimeneti adatokat. Ez lehetővé teszi az adatok gyors és egyszerű átadását az adatfolyam-tevékenységből anélkül, hogy az adatokat egy adattárban kellene tárolnia.
Frissítési módszer
Adatbázis-fogadótípusok esetén a Gépház lap egy "Frissítési módszer" tulajdonságot tartalmaz. Az alapértelmezett beállítás a beszúrás, de a frissítés, az upsert és a törlés jelölőnégyzetét is tartalmazza. A további lehetőségek kihasználásához hozzá kell adnia egy Alter Row-átalakítást a fogadó előtt. Az Alter Row segítségével meghatározhatja az egyes adatbázisműveletek feltételeit. Ha a forrás natív CDC-kompatibilis forrás, akkor a frissítési módszereket alter Row nélkül is beállíthatja, mivel az ADF már ismeri a beszúrás, frissítés, frissítés és törlés sorjelölőit.
Mezőleképezés
A kiválasztási átalakításhoz hasonlóan a fogadó Leképezés lapján eldöntheti, hogy mely bejövő oszlopok lesznek megírva. Alapértelmezés szerint az összes bemeneti oszlop, beleértve az elsodródott oszlopokat is, megfeleltetve van. Ezt a viselkedést automappingnak nevezzük.
Ha kikapcsolja az automatikus leképezést, rögzített oszlopalapú leképezéseket vagy szabályalapú leképezéseket is hozzáadhat. Szabályalapú leképezésekkel mintaegyeztetésű kifejezéseket írhat. Rögzített leképezési leképezések logikai és fizikai oszlopneveket képeznek le. További információ a szabályalapú leképezésről: Oszlopminták a leképezési adatfolyamban.
Fogadók egyéni sorrendbe rendezése
Alapértelmezés szerint az adatok nem meghatározott sorrendben több fogadóba lesznek írva. A végrehajtási motor párhuzamosan írja az adatokat az átalakítási logika befejezésekor, és a fogadó sorrendje minden futtatásban eltérő lehet. Ha pontos fogadórendelést szeretne megadni, engedélyezze az egyéni fogadórendezést az adatfolyam Általános lapján. Ha engedélyezve van, a fogadók egymás után, növekvő sorrendben vannak megírva.

Feljegyzés
A gyorsítótárazott keresések használatakor győződjön meg arról, hogy a fogadó rendelésében a gyorsítótárazott fogadók értéke 1, a legalacsonyabb (vagy az első) a sorrendben.
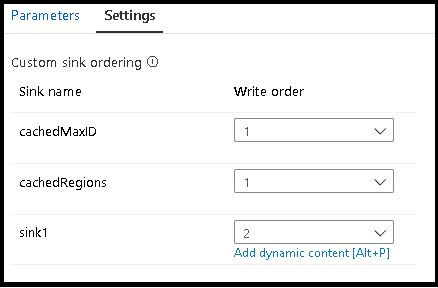
Fogadócsoportok
A fogadókat csoportosíthatja úgy, hogy ugyanazt a rendelésszámot alkalmazza a fogadók sorozatára. A szolgáltatás ezeket a fogadókat olyan csoportokként kezeli, amelyek párhuzamosan végrehajthatók. A párhuzamos végrehajtás lehetőségei megjelennek a folyamat adatfolyam-tevékenységében.
Hibák
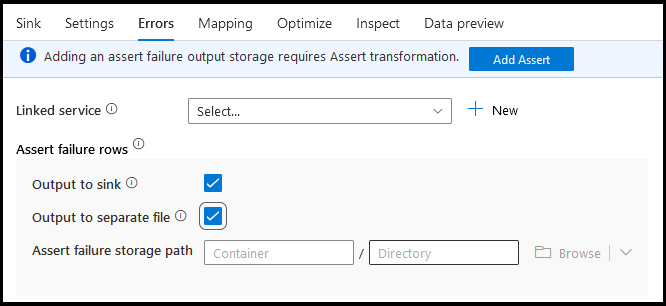
A fogadó hibák lapján konfigurálhatja a hibasorkezelést az adatbázis-illesztőprogramok hibáinak és a hibás állításoknak a rögzítéséhez és átirányításához.
Adatbázisokba való íráskor bizonyos adatsorok meghiúsulhatnak a cél által beállított korlátozások miatt. Alapértelmezés szerint az adatfolyam-futtatás az első hibánál meghiúsul. Bizonyos összekötőkben választhatja a Folytatás hibalehetőséget , amely lehetővé teszi, hogy az adatfolyam akkor is befejeződjön, ha az egyes sorok hibásak. Ez a funkció jelenleg csak az Azure SQL Database-ben és az Azure Synapse-ban érhető el. További információ: hibasorkezelés az Azure SQL DB-ben.
Az alábbiakban egy oktatóvideó ismerteti, hogyan használhatja automatikusan az adatbázis hibasorkezelését a fogadóátalakítás során.
Az érvényesítési hibák soraihoz használhatja az Igény transzformációt az adatfolyamban, majd átirányíthatja a hibás állításokat egy kimeneti fájlba a fogadó hibáinak lapján. Itt arra is lehetősége van, hogy figyelmen kívül hagyja a helyességi hibákkal rendelkező sorokat, és egyáltalán ne adja ki ezeket a sorokat a fogadó céladattárában.
Adatelőnézet a fogadóban
Ha hibakeresési módban lekéri az adatok előnézetét, a rendszer nem ír adatokat a fogadóba. A rendszer visszaad egy pillanatképet az adatok megjelenéséről, de a rendszer semmit sem ír a célhelyre. Az adatok fogadóba való írásának teszteléséhez futtasson egy folyamatkeresést a folyamatvászonról.
Adatfolyamszkript
Példa
Az alábbiakban egy példa látható a fogadó átalakítására és az adatfolyam-szkriptre:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Kapcsolódó tartalom
Most, hogy létrehozta az adatfolyamot, vegyen fel egy adatfolyam-tevékenységet a folyamatba.