Forrásátalakítás az adatfolyamok leképezésében
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Az adatfolyamok az Azure Data Factoryben és az Azure Synapse Pipelinesban is elérhetők. Ez a cikk az adatfolyamok leképezésére vonatkozik. Ha még nem használta az átalakításokat, tekintse meg az adatok leképezési adatfolyam használatával történő átalakításáról szóló bevezető cikket.
A forrásátalakítás konfigurálja az adatforrást az adatfolyamhoz. Adatfolyamok tervezésekor az első lépés mindig egy forrásátalakítás konfigurálása. Forrás hozzáadásához válassza a Forrás hozzáadása mezőt az adatfolyam-vásznon.
Minden adatfolyamhoz legalább egy forrásátalakítás szükséges, de annyi forrást adhat hozzá, amennyi szükséges az adatátalakítások elvégzéséhez. Ezeket a forrásokat összekapcsolhatja egy illesztéssel, kereséssel vagy egyesülési átalakítással.
Minden forrásátalakítás pontosan egy adatkészlethez vagy társított szolgáltatáshoz van társítva. Az adatkészlet határozza meg azoknak az adatoknak az alakját és helyét, amelyeket írni vagy olvasni szeretne. Ha fájlalapú adatkészletet használ, a forrásban helyettesítő karakterek és fájllisták használatával egyszerre több fájllal is dolgozhat.
Beágyazott adatkészletek
A forrásátalakítás létrehozásakor elsőként azt kell eldöntenie, hogy a forrásadatok egy adathalmaz-objektumon belül vagy a forrásátalakításon belül vannak-e definiálva. A legtöbb formátum csak az egyikben vagy a másikban érhető el. Ha tudni szeretné, hogyan használhat egy adott összekötőt, tekintse meg a megfelelő összekötő dokumentumot.
Ha a formátumok beágyazott és adathalmaz-objektumokban is támogatottak, mindkettőnek vannak előnyei. Az adathalmaz-objektumok olyan újrafelhasználható entitások, amelyek más adatfolyamokban és tevékenységekben, például a Másolásban is használhatók. Ezek az újrahasználható entitások különösen hasznosak, ha megerősített sémát használ. Az adathalmazok nem a Sparkban alapulnak. Időnként előfordulhat, hogy felül kell bírálnia bizonyos beállításokat vagy sémavetítést a forrásátalakítás során.
A beágyazott adatkészletek rugalmas sémák, egyszeri forráspéldányok vagy paraméteres források használata esetén ajánlottak. Ha a forrás erősen paraméterezett, a beágyazott adatkészletek lehetővé teszik, hogy ne hozzon létre "dummy" objektumot. A beágyazott adathalmazok a Sparkban alapulnak, és tulajdonságaik natívak az adatfolyamban.
Beágyazott adatkészlet használatához válassza ki a kívánt formátumot a Forrástípus-választóban . Forrásadatkészlet kiválasztása helyett válassza ki azt a társított szolgáltatást, amelyhez csatlakozni szeretne.
Sémabeállítások
Mivel egy beágyazott adatkészlet az adatfolyamon belül van definiálva, nincs definiált séma a beágyazott adatkészlethez társítva. A Vetítés lapon importálhatja a forrásadatsémát, és a sémát forrásvetítésként tárolhatja. Ezen a lapon talál egy "Sémabeállítások" gombot, amely lehetővé teszi az ADF sémafelderítési szolgáltatásának viselkedésének meghatározását.
- Tervezett séma használata: Ez a beállítás akkor hasznos, ha nagy számú forrásfájllal rendelkezik, amelyeket az ADF vizsgál forrásként. Az ADF alapértelmezett viselkedése az összes forrásfájl sémájának felderítése. Ha azonban már van előre definiált vetülete a forrásátalakításban, ezt igaz értékre állíthatja, és az ADF kihagyja az összes séma automatikus felderítését. Ha ez a beállítás be van kapcsolva, a forrásátalakítás sokkal gyorsabban tudja beolvasni az összes fájlt, és minden fájlra alkalmazza az előre definiált sémát.
- Sémaeltolódás engedélyezése: Kapcsolja be a sémaeltolódást, hogy az adatfolyam lehetővé tegye a forrássémában még nem definiált új oszlopokat.
- Séma érvényesítése: Ha ezt a beállítást választja, az adatfolyam meghiúsul, ha a kivetítésben definiált bármely oszlop és típus nem felel meg a forrásadatok felderített sémájának.
- Sodródott oszloptípusokból következtethet: Ha az ADF új sodródott oszlopokat azonosít, az új oszlopok az ADF automatikus típuskövetkeztetésével a megfelelő adattípusba kerülnek.
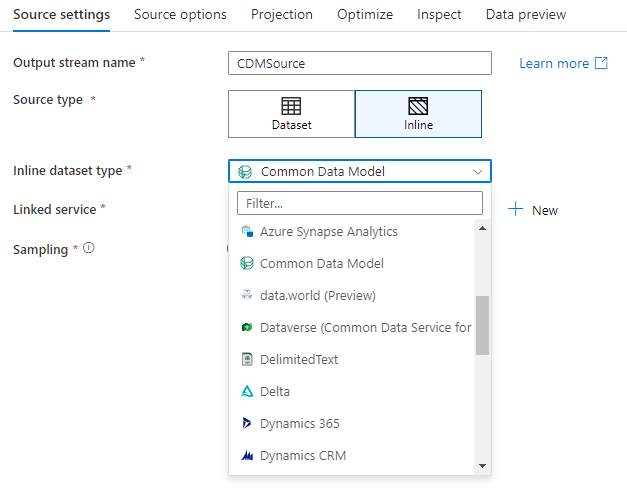
Munkaterület adatbázisa (csak Synapse-munkaterületek)
Az Azure Synapse-munkaterületeken egy további lehetőség is elérhető az adatfolyam-forrásátalakításokban Workspace DB. Ez lehetővé teszi, hogy közvetlenül válasszon egy tetszőleges típusú munkaterület-adatbázist forrásadatként anélkül, hogy további társított szolgáltatásokat vagy adatkészleteket kellene megkövetelnie. Az Azure Synapse-adatbázissablonokkal létrehozott adatbázisok a Workspace DB kiválasztásakor is elérhetők.
Támogatott forrástípusok
A leképezési adatfolyam kinyerési, betöltési és átalakítási (ELT) megközelítést követ, és az Azure-ban található átmeneti adathalmazokkal működik. Jelenleg a következő adathalmazok használhatók forrásátalakításkor.
Gépház ezekre az összekötőkre jellemzőForrásbeállítások lap. Ezekre a beállításokra vonatkozó információk és adatfolyam-szkriptek az összekötő dokumentációjában találhatók.
Az Azure Data Factory és a Synapse-folyamatok több mint 90 natív összekötőhöz férhetnek hozzá. Ha más forrásokból származó adatokat szeretne belefoglalni az adatfolyamba, a Másolási tevékenység használatával töltse be az adatokat az egyik támogatott átmeneti területre.
Forrásbeállítások
Miután hozzáadott egy forrást, konfiguráljon a Forrásbeállítások lapon. Itt választhatja ki vagy hozhatja létre a forráspontokat. Az adatok sémáját és mintavételezési beállításait is kiválaszthatja.
Az adathalmaz paramétereinek fejlesztési értékei a hibakeresési beállításokban konfigurálhatók. (A hibakeresési módot be kell kapcsolni.)
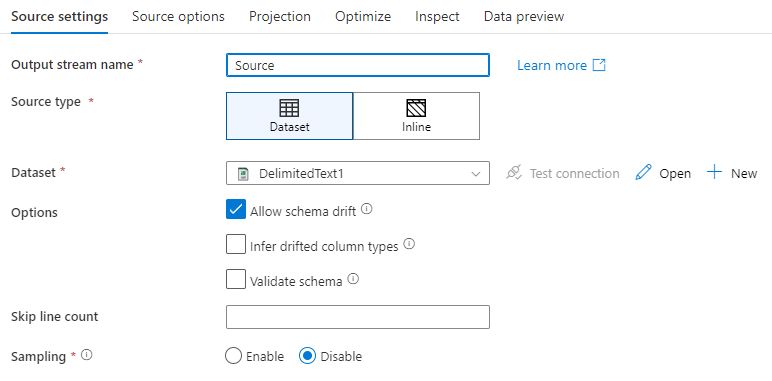
Kimeneti stream neve: A forrásátalakítás neve.
Forrás típusa: Adja meg, hogy beágyazott adathalmazt vagy meglévő adathalmaz-objektumot szeretne-e használni.
Kapcsolat tesztelése: Annak tesztelése, hogy az adatfolyam Spark-szolgáltatása sikeresen tud-e csatlakozni a forrásadatkészletben használt társított szolgáltatáshoz. A hibakeresési módnak be kell kapcsolnia ezt a funkciót ahhoz, hogy engedélyezve legyen.
Sémaeltolódás: A sémaeltolódás az a képesség, hogy a szolgáltatás natív módon kezelje az adatfolyamok rugalmas sémáit anélkül, hogy explicit módon kellene meghatároznia az oszlopmódosításokat.
Jelölje be a Sémaeltolódás engedélyezése jelölőnégyzetet, ha a forrásoszlopok gyakran változnak. Ez a beállítás lehetővé teszi, hogy az összes bejövő forrásmező átfolyjon a fogadóba irányuló átalakításokon.
Az eltolódott oszloptípusok kijelölése arra utasítja a szolgáltatást, hogy észlelje és definiálja az egyes felderített új oszlopok adattípusait. Ha ez a funkció ki van kapcsolva, az összes sodródott oszlop típussztring.
Séma érvényesítése: Ha a séma ellenőrzése ki van jelölve, az adatfolyam nem fut, ha a bejövő forrásadatok nem felelnek meg az adathalmaz megadott sémájának.
Sorok számának kihagyása: A Sorszám kihagyása mező azt határozza meg, hogy hány sort kell figyelmen kívül hagyni az adathalmaz elején.
Mintavételezés: A mintavételezés engedélyezése a forrásból származó sorok számának korlátozásához. Ezt a beállítást akkor használja, ha hibakeresési célokból teszteli vagy mintaadatokat használ a forrásból. Ez nagyon hasznos, ha az adatfolyamokat hibakeresési módban hajtja végre egy folyamatból.
A forrás helyes konfigurálásának ellenőrzéséhez kapcsolja be a hibakeresési módot, és kérje le az adat előnézetét. További információ: Hibakeresési mód.
Feljegyzés
Ha a hibakeresési mód be van kapcsolva, a hibakeresési beállítások sorkorlát-konfigurációja felülírja a mintavételezési beállítást a forrásban az adatelőnézet során.
Forrásbeállítások
A Forrásbeállítások lap az összekötőre és a választott formátumra vonatkozó beállításokat tartalmazza. További információkért és példákért tekintse meg a vonatkozó összekötő dokumentációját. Ide tartoznak például az azt támogató adatforrások elkülönítési szintje (például a helyszíni SQL Server, az Azure SQL Databases és a felügyelt Azure SQL-példányok) és más adatforrásspecifikus beállítások.
Vetület
Az adathalmazok sémáihoz hasonlóan a forrásban lévő kivetítés is meghatározza a forrásadatok adatoszlopait, típusait és formátumait. A legtöbb adathalmaztípushoz, például az SQL-hez és a Parquethez, a forrásban lévő kivetítés rögzített, hogy tükrözze az adathalmazban definiált sémát. Ha a forrásfájlok nincsenek erősen begépelve (például parquet-fájlok helyett egybesimított .csv fájlok), a forrásátalakítás egyes mezőihez megadhatja az adattípusokat.

Ha a szövegfájl nem rendelkezik definiált sémával, válassza az Adattípus észlelése lehetőséget, hogy a szolgáltatás mintákat használjon, és az adattípusokat következtethesse. Az alapértelmezett adatformátumok automatikus megadásához válassza az Alapértelmezett formátum megadása lehetőséget.
A séma alaphelyzetbe állítása visszaállítja a vetítést a hivatkozott adatkészletben definiáltra.
A séma felülírásával módosíthatja a forrásként megadott előrejelzett adattípusokat, felülírva a séma által definiált adattípusokat. Másik lehetőségként módosíthatja az oszlop adattípusát egy alsóbb rétegbeli származtatott oszlopátalakításban. Válasszon átalakítást az oszlopnevek módosításához.
Séma importálása
Kattintson a Séma importálása gombra a Vetítés lapon, ha aktív hibakeresési fürtöt szeretne használni sémavetítés létrehozásához. Minden forrástípusban elérhető. A séma importálása felülírja az adathalmazban definiált vetületet. Az adathalmaz-objektum nem változik.
A séma importálása olyan adathalmazokban hasznos, mint az Avro és az Azure Cosmos DB, amelyek olyan összetett adatstruktúrákat támogatnak, amelyek nem igényelnek sémadefiníciókat az adathalmazban. Beágyazott adathalmazok esetén a séma importálása az egyetlen módja annak, hogy sémaeltolódás nélkül hivatkozzon az oszlop metaadataira.
A forrásátalakítás optimalizálása
Az Optimalizálás lap lehetővé teszi a partícióadatok szerkesztését minden átalakítási lépésnél. A legtöbb esetben a jelenlegi particionálás optimalizálja a forrás ideális particionálási struktúráját.
Ha Azure SQL Database-forrásból olvas, az egyéni forrásparticionálás valószínűleg az adatokat olvassa a leggyorsabban. A szolgáltatás nagy lekérdezéseket olvas be úgy, hogy párhuzamosan létesít kapcsolatot az adatbázissal. Ez a forrásparticionálás elvégezhető egy oszlopon vagy egy lekérdezés használatával.

A leképezési adatfolyamon belüli optimalizálásról további információt az Optimalizálás lapon talál.
Kapcsolódó tartalom
Kezdje el létrehozni az adatfolyamot egy származtatott oszlopos átalakítással és egy kiválasztási átalakítással.