Adatintegráció az Azure Data Factory és az Azure Data Share használatával
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Az ügyfelek modern adattárház- és elemzési projektjeik megkezdéséhez nemcsak több adatot, hanem nagyobb átláthatóságot is igényelnek az adataikban az adattulajdonban. Ez a workshop bemutatja, hogy az Azure Data Factory és az Azure Data Share fejlesztései hogyan egyszerűsítik az Azure-beli adatintegrációt és -felügyeletet.
A kód nélküli ETL/ELT engedélyezésétől az adatok átfogó áttekintésének kialakításáig az Azure Data Factory fejlesztései lehetővé teszik az adatmérnökök számára, hogy magabiztosan több adatot, ezáltal több értéket hozzanak létre a vállalat számára. Az Azure Data Share lehetővé teszi, hogy az üzleti megosztást szabályozott módon végezze el.
Ebben a workshopban az Azure Data Factory (ADF) használatával fog adatokat betöltésre az Azure SQL Database-ből az Azure Data Lake Storage Gen2-be (ADLS Gen2). Miután lerakta az adatokat a tóba, átalakítja azokat az adatfolyamok leképezésével, a Data Factory natív átalakítási szolgáltatásával, és az Azure Synapse Analyticsbe fogja őket átfogni. Ezután megosztja a táblát átalakított adatokkal, valamint néhány további adattal az Azure Data Share használatával.
A laborban használt adatok New York-i taxiadatok. Ha az SQL Database-ben szeretné importálni az adatbázisba, töltse le a taxi-data bacpac fájlt. Válassza a Nyers fájl letöltése lehetőséget a GitHubon.
Előfeltételek
Azure-előfizetés: Ha nem rendelkezik Azure-előfizetéssel, első lépésként mindössze néhány perc alatt létrehozhat egy ingyenes fiókot.
Azure SQL Database: Ha nem rendelkezik Azure SQL Database-adatbázissal, megtudhatja, hogyan hozhat létre SQL Database-adatbázist.
Azure Data Lake Storage Gen2-tárfiók: Ha nem rendelkezik ADLS Gen2-tárfiókkal, megtudhatja, hogyan hozhat létre ADLS Gen2-tárfiókot.
Azure Synapse Analytics: Ha nem rendelkezik Azure Synapse Analytics-munkaterülettel, megtudhatja, hogyan kezdheti el az Azure Synapse Analytics szolgáltatást.
Azure Data Factory: Ha még nem hozott létre adat-előállítót, tekintse meg, hogyan hozhat létre adat-előállítót.
Azure Data Share: Ha még nem hozott létre adatmegosztást, tekintse meg, hogyan hozhat létre adatmegosztást.
Az Azure Data Factory-környezet beállítása
Ebben a szakaszban megtudhatja, hogyan érheti el az Azure Data Factory felhasználói felületét (ADF UX) az Azure Portalon. Az ADF UX-ben három társított szolgáltatást fog konfigurálni minden használt adattárhoz: Azure SQL Database, ADLS Gen2 és Azure Synapse Analytics.
Az Azure Data Factory társított szolgáltatásaiban adja meg a külső erőforrások kapcsolati adatait. Az Azure Data Factory jelenleg több mint 85 összekötőt támogat.
Az Azure Data Factory UX megnyitása
Nyissa meg az Azure Portalt a Microsoft Edge-ben vagy a Google Chrome-ban.
A lap tetején található keresősáv használatával keresse meg az "Adat-előállítók" kifejezést.
Válassza ki a data factory-erőforrást az erőforrások megnyitásához a bal oldali panelen.
Válassza az Azure Data Factory Studio megnyitása lehetőséget. A Data Factory Studio közvetlenül a adf.azure.com is elérhető.
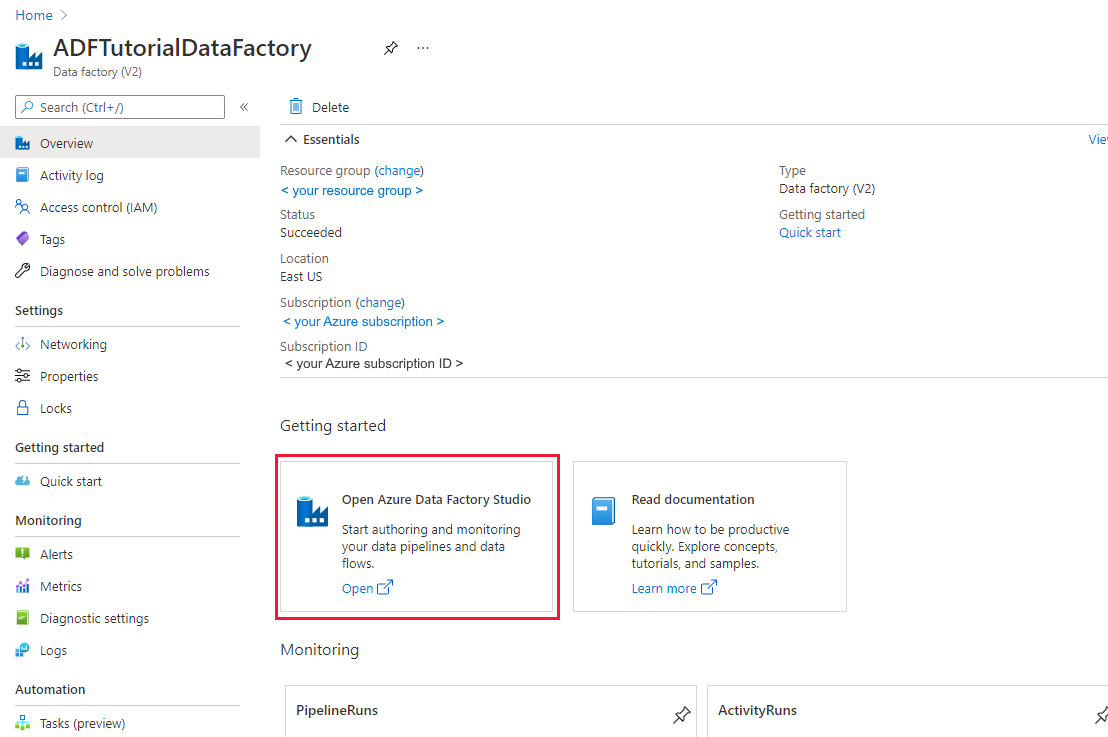
A rendszer átirányítja az ADF kezdőlapjára az Azure Portalon. Ez az oldal rövid útmutatókat, oktatóvideókat és oktatóanyagokra mutató hivatkozásokat tartalmaz a Data Factory alapfogalmainak megismeréséhez. A szerkesztés megkezdéséhez válassza a ceruza ikont a bal oldali sávon.



Azure SQL Database-beli társított szolgáltatás létrehozása
Csatolt szolgáltatás létrehozásához válassza a Bal oldali sávOn a Központ kezelése lehetőséget, a Csatlakozás ions panelen válassza a Csatolt szolgáltatások lehetőséget, majd az Új lehetőséget egy új társított szolgáltatás hozzáadásához.

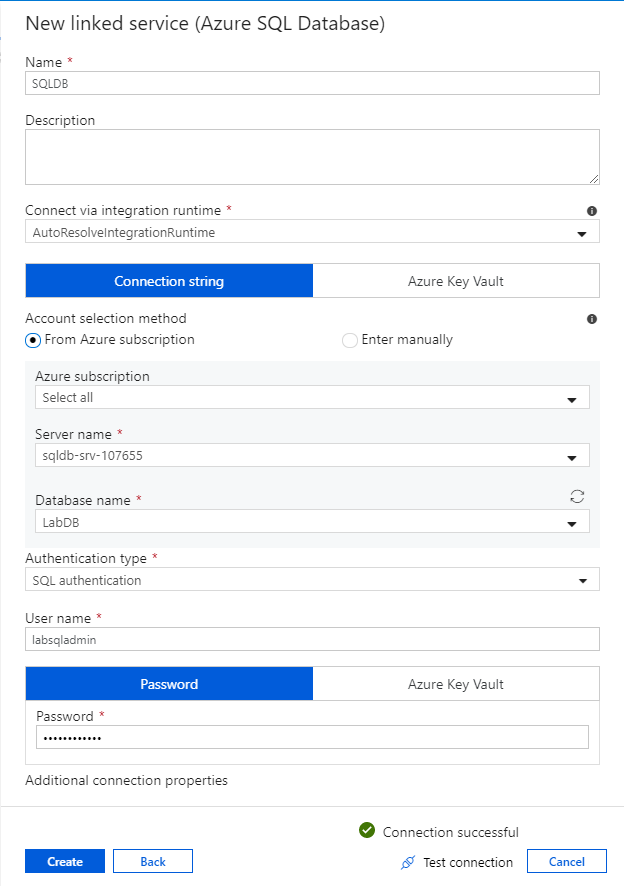
Az első konfigurált társított szolgáltatás egy Azure SQL Database. A keresősáv használatával szűrheti az adattárak listáját. Válassza az Azure SQL Database csempét, és válassza a Folytatás lehetőséget.

Az SQL Database konfigurációs paneljén adja meg az "SQLDB" nevet csatolt szolgáltatásnévként. Adja meg a hitelesítő adatait, hogy lehetővé tegye a Data Factory számára az adatbázishoz való csatlakozást. Ha SQL-hitelesítést használ, adja meg a kiszolgáló nevét, az adatbázist, a felhasználónevet és a jelszót. A Kapcsolat tesztelése lehetőség kiválasztásával ellenőrizheti, hogy a kapcsolat adatai helyesek-e. Miután végzett, válassza a Létrehozás lehetőséget.

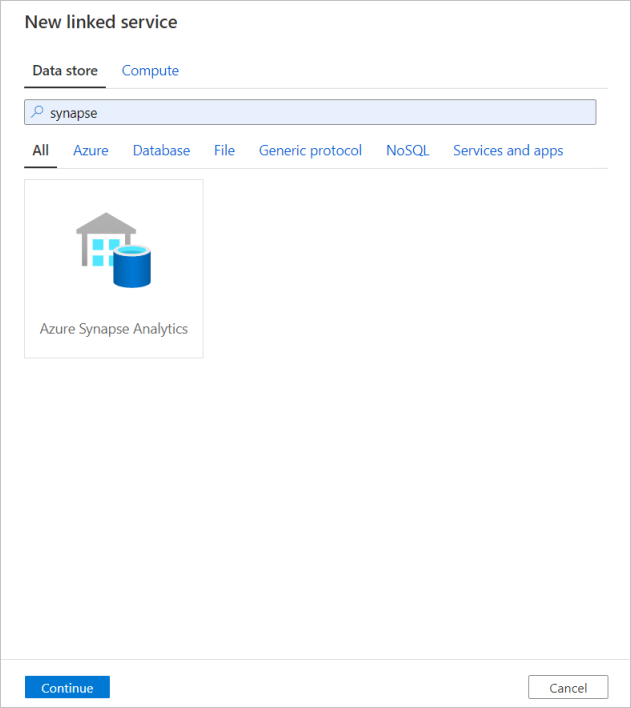
Azure Synapse Analytics társított szolgáltatás létrehozása
Ismételje meg ugyanezt a folyamatot egy Társított Azure Synapse Analytics-szolgáltatás hozzáadásához. A Kapcsolatok lapon válassza az Új lehetőséget. Válassza ki az Azure Synapse Analytics csempét, és válassza a Folytatás lehetőséget.
A társított szolgáltatás konfigurációs paneljén adja meg az "SQLDW" nevet a társított szolgáltatás neveként. Adja meg a hitelesítő adatait, hogy lehetővé tegye a Data Factory számára az adatbázishoz való csatlakozást. Ha SQL-hitelesítést használ, adja meg a kiszolgáló nevét, az adatbázist, a felhasználónevet és a jelszót. A Kapcsolat tesztelése lehetőség kiválasztásával ellenőrizheti, hogy a kapcsolat adatai helyesek-e. Miután végzett, válassza a Létrehozás lehetőséget.
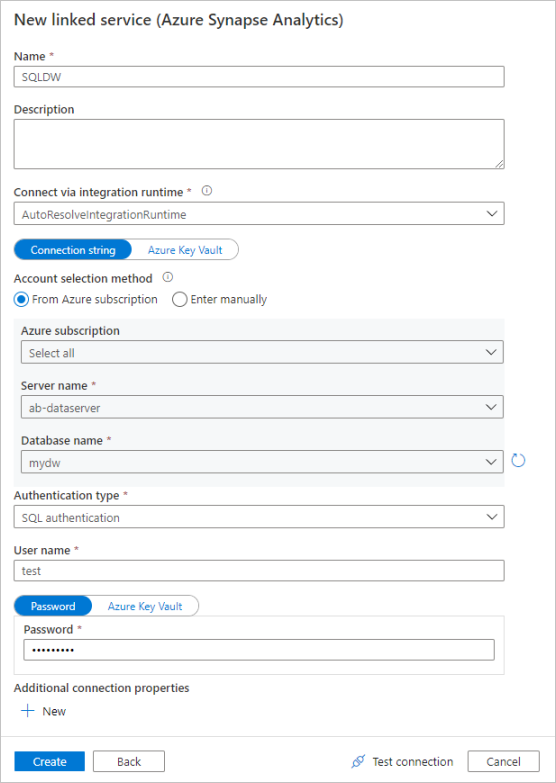
Azure Data Lake Storage Gen2 társított szolgáltatás létrehozása
A labor utolsó társított szolgáltatása egy Azure Data Lake Storage Gen2. A Kapcsolatok lapon válassza az Új lehetőséget. Válassza az Azure Data Lake Storage Gen2 csempét, és válassza a Folytatás lehetőséget.
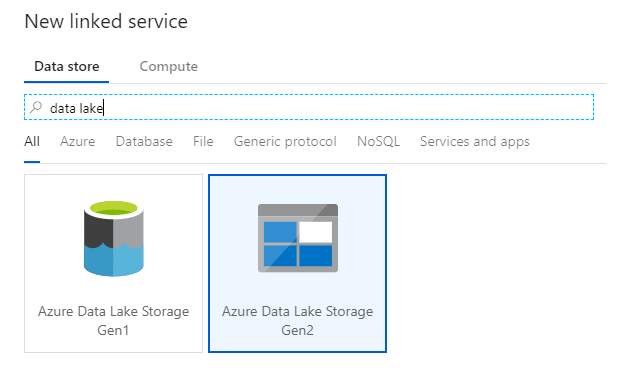
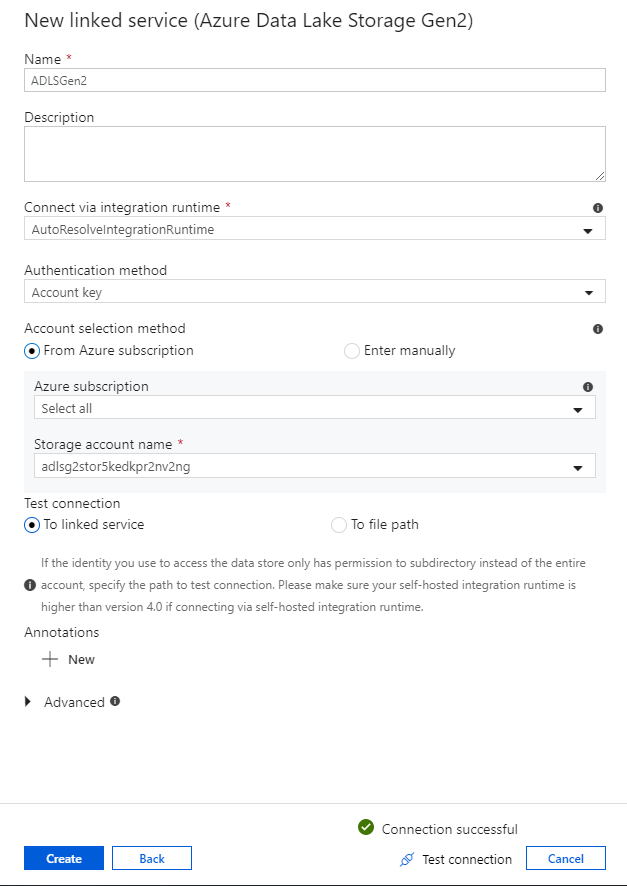
A társított szolgáltatás konfigurációs paneljén adja meg az "ADLSGen2" nevet a társított szolgáltatás neveként. Ha fiókkulcs-hitelesítést használ, válassza ki az ADLS Gen2-tárfiókot a Tárfiók neve legördülő listából. A Kapcsolat tesztelése lehetőség kiválasztásával ellenőrizheti, hogy a kapcsolat adatai helyesek-e. Miután végzett, válassza a Létrehozás lehetőséget.
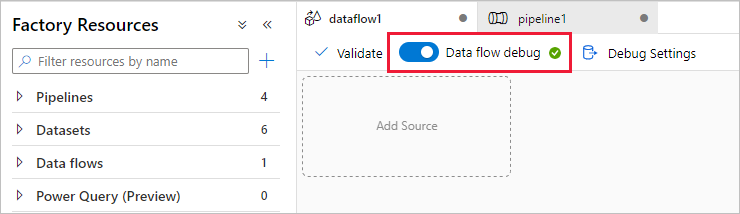
Adatfolyam-hibakeresési mód bekapcsolása
Az Adatok átalakítása leképezési adatfolyamokkal című szakaszban leképezési adatfolyamokat készít. A leképezési adatfolyamok létrehozása előtt ajánlott bekapcsolni a hibakeresési módot, amely lehetővé teszi, hogy másodpercek alatt tesztelje az átalakítási logikát egy aktív spark-fürtön.
A hibakeresés bekapcsolásához válassza az adatfolyam-vászon vagy a folyamatvászon felső sávjának adatfolyam-hibakeresési csúszkát, amikor adatfolyam-tevékenységeket végez. Válassza az OK gombot, amikor megjelenik a megerősítést kérő párbeszédpanel. A fürt körülbelül 5–7 perc múlva indul el. Folytassa az adatok Azure SQL Database-ből az ADLS Gen2-be való betöltését a másolási tevékenység használatával az inicializálás során.

Adatok betöltése a másolási tevékenység használatával
Ebben a szakaszban egy másolási tevékenységgel rendelkező folyamatot hoz létre, amely egy táblát egy Azure SQL Database-ből egy ADLS Gen2-tárfiókba betölt. Megtudhatja, hogyan vehet fel egy folyamatot, konfigurálhat egy adathalmazt, és hogyan végezhet hibakeresést egy folyamatban az ADF UX-en keresztül. Az ebben a szakaszban használt konfigurációs minta alkalmazható a relációs adattárból egy fájlalapú adattárba történő másolásra.
Az Azure Data Factoryben a folyamat olyan tevékenységek logikai csoportosítása, amelyek együttesen hajtanak végre egy feladatot. Egy tevékenység meghatározza az adatokon végrehajtandó műveletet. Az adatkészletek a társított szolgáltatásban használni kívánt adatokra mutatnak.
Folyamat létrehozása másolási tevékenységgel
A gyári erőforrások panelen a plusz ikonra kattintva nyissa meg az új erőforrásmenüt. Válassza a Folyamat lehetőséget.
A folyamatvászon Általános lapján nevezze el a folyamatot leírónak, például az "IngestAndTransformTaxiData" nevet.

A folyamatvászon tevékenységpaneljén nyissa meg az Áthelyezés és átalakítás harmonikát, és húzza az Adatmásolási tevékenységet a vászonra. Adjon egy leíró nevet a másolási tevékenységnek, például az "IngestIntoADLS"-nek.



Az Azure SQL DB forrásadatkészletének konfigurálása
Válassza ki a másolási tevékenység Forrás lapján. Új adatkészlet létrehozásához válassza az Új lehetőséget. A forrás a korábban konfigurált SQLDB társított szolgáltatásban található tábla
dbo.TripDatalesz.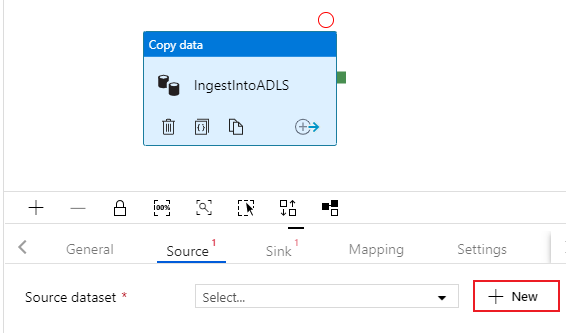
Keresse meg az Azure SQL Database-t , és válassza a Folytatás lehetőséget.
Hívja meg a "TripData" adatkészletet. Válassza az "SQLDB" elemet társított szolgáltatásként. Válassza ki a tábla nevét
dbo.TripDataa táblanév legördülő listából. Importálja a sémát a kapcsolatból/tárolóból. Ha végzett , válassza az OK gombra.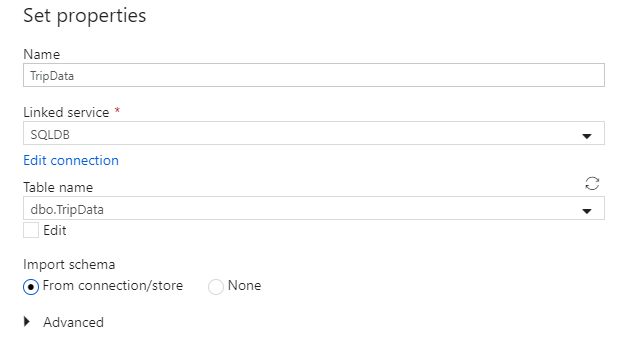
Sikeresen létrehozta a forrásadatkészletet. Győződjön meg arról, hogy a forrásbeállításokban a Tábla alapértelmezett érték van kiválasztva a Lekérdezés használata mezőben.
Az ADLS Gen2 fogadó adatkészletének konfigurálása
Válassza ki a másolási tevékenység Fogadó lapján. Új adatkészlet létrehozásához válassza az Új lehetőséget.
Keresse meg az Azure Data Lake Storage Gen2-t , és válassza a Folytatás lehetőséget.
A Formátum kiválasztása panelen válassza a DelimitedText elemet, amikor csv-fájlba ír. Válassza a Folytatás lehetőséget.

Nevezze el a "TripDataCSV" fogadóadatkészletet. Válassza az "ADLSGen2" elemet csatolt szolgáltatásként. Adja meg, hogy hová szeretné írni a csv-fájlt. Megírhatja például az adatokat a tárolóban
staging-containerlévő fájlbatrip-data.csv. Állítsa az Első sort fejlécként igaz értékre, ha azt szeretné, hogy a kimeneti adatok fejlécekkel rendelkezzenek. Mivel még nincs fájl a célhelyen, állítsa az Importálási sémát Nincs értékre. Ha végzett , válassza az OK gombra.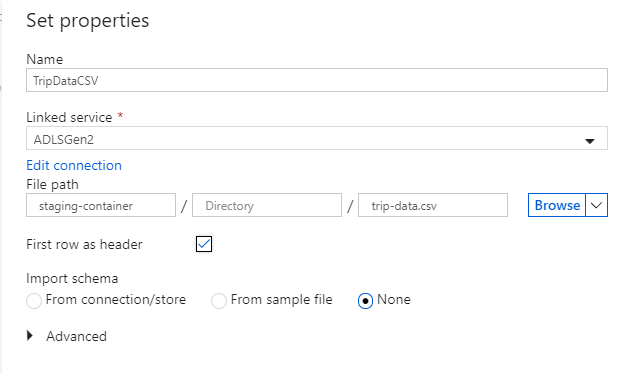
A másolási tevékenység tesztelése folyamatkeresési futtatással
Ha ellenőrizni szeretné, hogy a másolási tevékenység megfelelően működik-e, válassza a hibakeresési futtatás végrehajtásához a folyamatvászon tetején található Hibakeresés lehetőséget. A hibakeresési futtatás lehetővé teszi a folyamat teljes körű vagy töréspontig történő tesztelését, mielőtt közzétennénk a data factory szolgáltatásban.

A hibakeresési futtatás figyeléséhez nyissa meg a folyamatvászon Kimenet lapját. A monitorozási képernyő 20 másodpercenként automatikusan visszavált, vagy ha manuálisan választja ki a frissítés gombot. A másolási tevékenység speciális monitorozási nézetet biztosít, amely a Műveletek oszlop szemüveg ikonjának kiválasztásával érhető el.
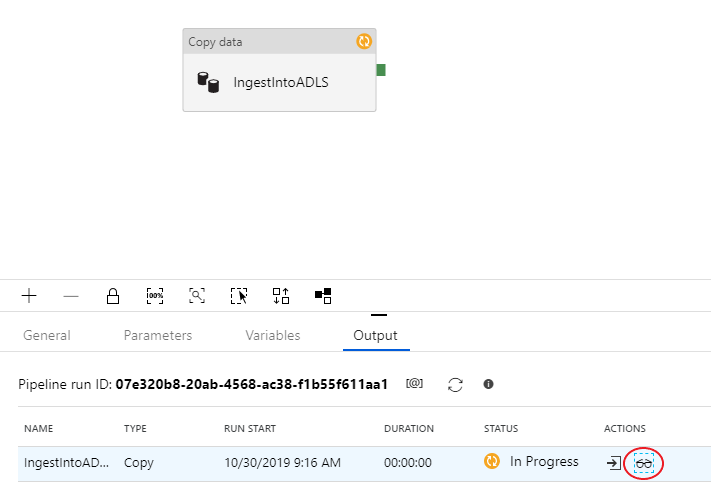
A másolásfigyelési nézet megadja a tevékenység végrehajtási adatait és teljesítményjellemzőit. Megtekintheti az olyan információkat, mint az adatok olvasása/írása, a sorok olvasása/írása, az olvasási/írási fájlok és az átviteli sebesség. Ha mindent megfelelően konfigurált, 49 999 sort kell látnia egy fájlba az ADLS-fogadóban.

Mielőtt továbblépne a következő szakaszra, javasoljuk, hogy tegye közzé a módosításokat a data factory szolgáltatásban a Publish all in the factory top bar (Az összes közzététele) lehetőség választásával. Bár ez a labor nem foglalkozik ezzel a tesztkörnyezettel, az Azure Data Factory támogatja a teljes git-integrációt. A Git-integráció lehetővé teszi a verziókövetést, az adattárakban való iteratív mentést és az adat-előállítón végzett együttműködést. További információ: forráskövetés az Azure Data Factoryben.


Adatok átalakítása adatfolyam-leképezéssel
Most, hogy sikeresen átmásolta az adatokat az Azure Data Lake Storage-ba, ideje összekapcsolni és összesíteni az adatokat egy adattárházba. A leképezési adatfolyamot, az Azure Data Factory vizuálisan megtervezett átalakítási szolgáltatását használjuk. A leképezési adatfolyamok lehetővé teszik a felhasználók számára az átalakítási logika kód nélküli fejlesztését és végrehajtását az ADF szolgáltatás által felügyelt Spark-fürtökön.
Az ebben a lépésben létrehozott adatfolyam összekapcsolja az előző szakaszban létrehozott TripDataCSV adatkészletet egy négy kulcsoszlopon alapuló "SQLDB"-ben tárolt táblával dbo.TripFares . Ezután az adatok oszlop payment_type alapján lesznek összesítve, hogy kiszámítsák bizonyos mezők átlagát, és egy Azure Synapse Analytics-táblába írjanak.
Adatfolyam-tevékenység hozzáadása a folyamathoz
A folyamatvászon tevékenységpaneljén nyissa meg az Áthelyezés és átalakítás harmonikát, és húzza az adatfolyam-tevékenységet a vászonra.
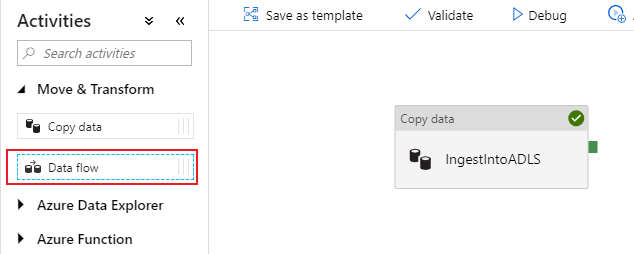
A megnyíló oldalpanelen válassza az Új adatfolyam létrehozása és az Adatfolyam leképezése lehetőséget. Kattintson az OK gombra.

A rendszer arra az adatfolyam-vászonra irányítja, ahol az átalakítási logikát fogja létrehozni. Az általános lapon adja meg az adatfolyam "JoinAndAggregateData" nevét.



Az utazási adatok CSV-forrásának konfigurálása
Első lépésként konfigurálja a két forrásátalakítást. Az első forrás a "TripDataCSV" DelimitedText adatkészletre mutat. Forrásátalakítás hozzáadásához válassza a vászon Forrás hozzáadása mezőjét.
Nevezze el a forrás "TripDataCSV" nevét, és válassza ki a "TripDataCSV" adatkészletet a forrás legördülő listából. Ha emlékszik, kezdetben nem importált sémát az adatkészlet létrehozásakor, mivel ott nem voltak adatok. Mivel
trip-data.csvmár létezik, válassza a Szerkesztés lehetőséget az adathalmaz beállításai lap megnyitásához.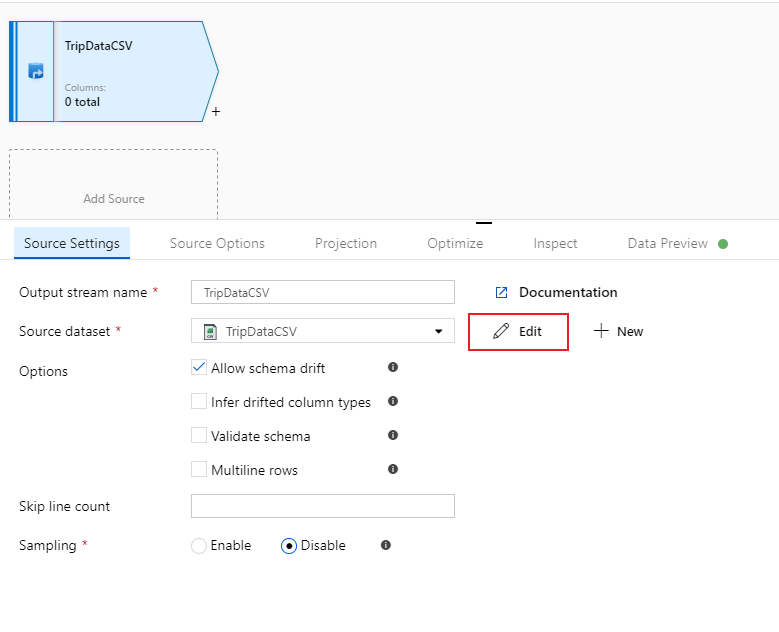
Lépjen a Lapséma lapra, és válassza a Séma importálása lehetőséget. Válassza a Kapcsolat/tár lehetőséget, ha közvetlenül a fájltárolóból szeretne importálni. 14 típusú sztringoszlopnak kell megjelennie.

Térjen vissza a "JoinAndAggregateData" adatfolyamhoz. Ha a hibakeresési fürt elindult (a hibakeresési csúszka melletti zöld kör jelzi), az Adatok előnézete lapon pillanatképet kaphat az adatokról. Az adatok előnézetének lekéréséhez válassza a Frissítés lehetőséget.



Megjegyzés:
Az adatelőnézet nem ír adatokat.
Utazás viteldíjainak konfigurálása SQL Database-forrás
A második forrás, amely pontokat ad hozzá az SQL Database táblához
dbo.TripFares. A "TripDataCSV" forrás alatt van egy másik Forrás hozzáadása mező. Új forrásátalakítás hozzáadásához jelölje ki.
Nevezze el ennek a forrásnak a "TripFaresSQL" nevet. Új SQL Database-adatkészlet létrehozásához válassza az Új lehetőséget a forrásadatkészlet mező mellett.
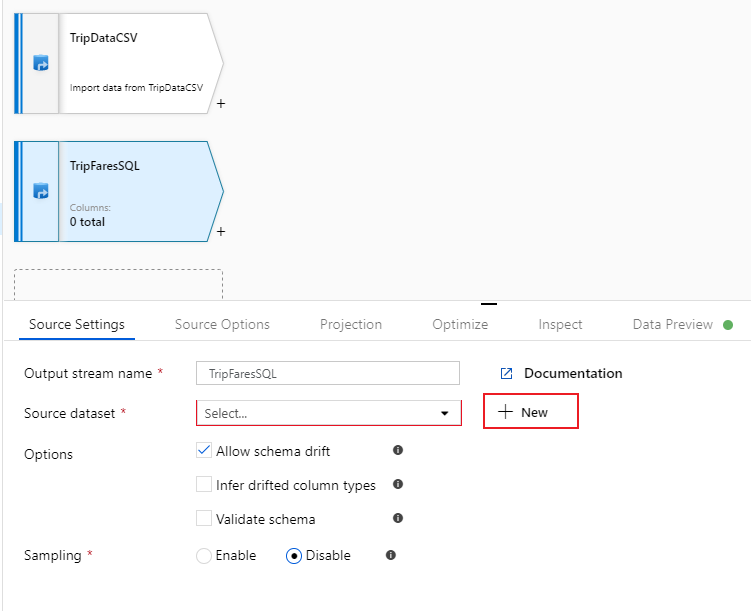
Válassza az Azure SQL Database csempét, és válassza a Folytatás lehetőséget. Észreveheti, hogy a data factory számos összekötője nem támogatott az adatfolyamok leképezésében. Ha ezen források egyikéből szeretne adatokat átalakítani, a másolási tevékenység használatával betöltse azt egy támogatott forrásba.

Hívja meg a TripFares adatkészletet. Válassza az "SQLDB" elemet társított szolgáltatásként. Válassza ki a tábla nevét
dbo.TripFaresa táblanév legördülő listából. Importálja a sémát a kapcsolatból/tárolóból. Ha végzett , válassza az OK gombra.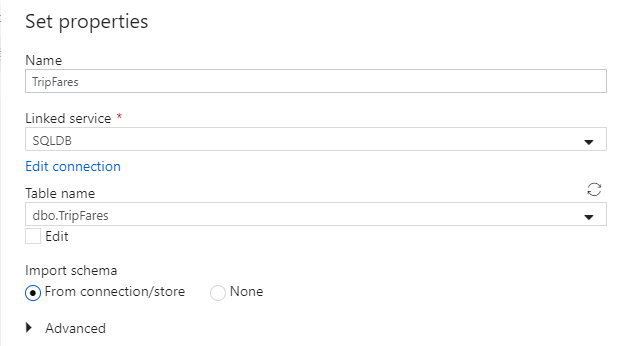
Az adatok ellenőrzéséhez kérje le az adatok előnézetét az Adatelőnézet lapon.


Belső csatlakozás TripDataCSV és TripFaresSQL
Új átalakítás hozzáadásához válassza a plusz ikont a TripDataCSV jobb alsó sarkában. A Több bemenet/kimenet csoportban válassza a Csatlakozás lehetőséget.
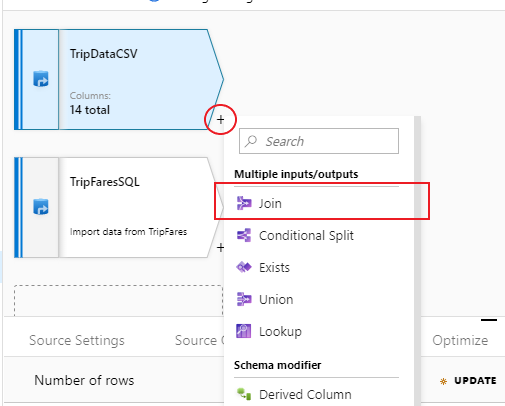
Nevezze el az "InnerJoinWithTripFares" illesztési átalakítást. Válassza a "TripFaresSQL" lehetőséget a jobb oldali stream legördülő listából. Az illesztés típusaként válassza az Inner (Belső ) lehetőséget. Ha többet szeretne megtudni a leképezési adatfolyam különböző illesztési típusairól, tekintse meg az illesztési típusokat.
Válassza ki az egyes streamek oszlopait az Illesztési feltételek legördülő listából. További csatlakozási feltétel hozzáadásához válassza a meglévő feltétel melletti plusz ikont. Alapértelmezés szerint az összes illesztés feltétel és egy AND operátor együttese, ami azt jelenti, hogy az egyezéshez minden feltételnek teljesülnie kell. Ebben a laborban egyezni szeretnénk a következő oszlopokon
medallion:hack_licensevendor_idpickup_datetime
Ellenőrizze, hogy sikeresen csatlakozott-e 25 oszlophoz egy adatelőnézettel együtt.



Összesítés payment_type szerint
Az illesztési átalakítás befejezése után adjon hozzá egy összesített átalakítást az InnerJoinWithTripFares melletti plusz ikonra kattintva. Válassza az Összesítés lehetőséget a Sémamódosító területen.
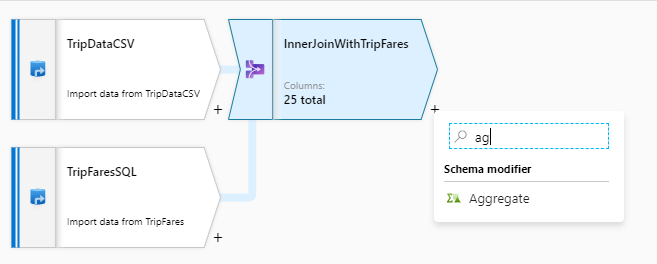
Adja az összesítő átalakításnak az "AggregateByPaymentType" nevet. Válassza ki
payment_typea csoportot oszlop szerint.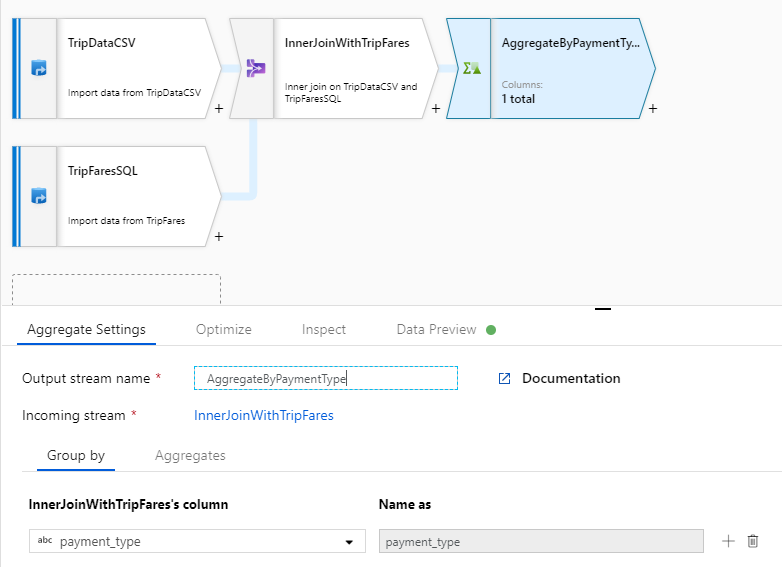
Lépjen az Összesítések lapra. Adjon meg két összesítést:
- Az átlagos viteldíj fizetési típus szerint csoportosítva
- Az utazás teljes távolsága fizetési típus szerint csoportosítva
Először az átlagos viteldíj-kifejezést fogja létrehozni. Az Oszlop hozzáadása vagy kijelölése feliratú szövegmezőbe írja be a "average_fare" kifejezést.

Aggregációs kifejezés megadásához jelölje ki az Enter kifejezés kék mezőjét, amely megnyitja az adatfolyam-kifejezésszerkesztőt, amely egy olyan eszköz, amellyel vizuálisan hozhat létre adatfolyam-kifejezéseket bemeneti sémával, beépített függvényekkel és műveletekkel, valamint felhasználó által definiált paraméterekkel. A kifejezésszerkesztő képességeivel kapcsolatos további információkért tekintse meg a kifejezésszerkesztő dokumentációját.
Az átlagos viteldíj lekéréséhez az
avg()aggregációs függvénnyel összesítheti aztotal_amountoszlopot egy egész számmaltoInteger(). Az adatfolyam-kifejezés nyelvében ez a következőképpen van definiálvaavg(toInteger(total_amount)): . Ha elkészült, válassza a Mentés és befejezés lehetőséget.
További összesítési kifejezés hozzáadásához válassza a mellette lévő plusz ikont
average_fare. Válassza az Oszlop hozzáadása lehetőséget.
Az Oszlop hozzáadása vagy kijelölése feliratú szövegmezőbe írja be a következőt: "total_trip_distance". Az utolsó lépéshez hasonlóan nyissa meg a kifejezésszerkesztőt a kifejezésbe való belépéshez.
A teljes utazási távolság lekéréséhez az
sum()aggregációs függvénnyel összesítheti aztrip_distanceoszlopot egy egész számra a következőveltoInteger(): . Az adatfolyam-kifejezés nyelvében ez a következőképpen van definiálvasum(toInteger(trip_distance)): . Ha elkészült, válassza a Mentés és befejezés lehetőséget.
Tesztelje az átalakítási logikát az Adatok előnézete lapon. Mint látható, a korábbiakhoz képest lényegesen kevesebb sor és oszlop van. Csak az átalakítás során definiált három csoport és aggregációs oszlop folytatódik lefelé. Mivel a mintában csak öt fizetésitípus-csoport szerepel, csak öt sor jelenik meg.






Az Azure Synapse Analytics-fogadó konfigurálása
Most, hogy befejeztük az átalakítási logikát, készen állunk arra, hogy az adatokat egy Azure Synapse Analytics-táblába süllyesztsük. Vegyen fel egy fogadóátalakítást a Cél szakaszban.

Nevezze el az "SQLDWSink" fogadót. Új Azure Synapse Analytics-adatkészlet létrehozásához válassza az Új lehetőséget a fogadó adathalmaz mező mellett.
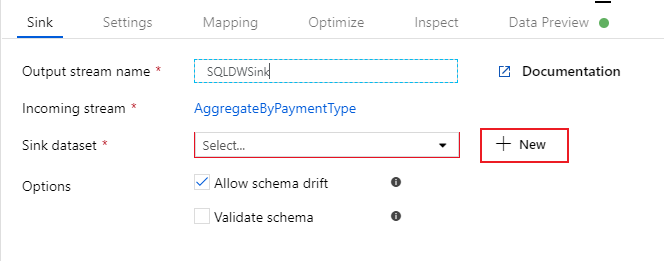
Válassza ki az Azure Synapse Analytics csempét, és válassza a Folytatás lehetőséget.

Hívja meg az "AggregatedTaxiData" adatkészletet. Válassza az "SQLDW" elemet társított szolgáltatásként. Válassza az Új tábla létrehozása lehetőséget, és nevezze el az új táblát
dbo.AggregateTaxiData. Ha végzett , válassza az OK gombra.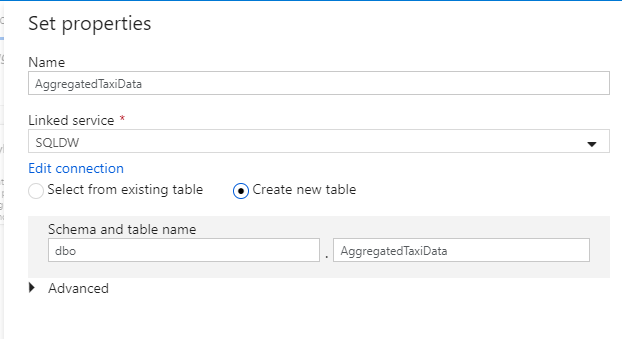
Lépjen a fogadó Gépház lapjára. Mivel új táblát hozunk létre, a táblaművelet alatt ki kell választanunk a Tábla újbóli létrehozása lehetőséget. Törölje az Előkészítés engedélyezése jelölőnégyzet jelölését, amely azt váltja ki, hogy sorról sorra vagy kötegbe szúrunk-e be.



Sikeresen létrehozta az adatfolyamot. Most itt az ideje, hogy egy folyamattevékenységben futtassa.
A folyamat végpontok közötti hibakeresése
Lépjen vissza az IngestAndTransformData folyamat lapjára. Figyelje meg az "IngestIntoADLS" másolási tevékenység zöld mezőjét. Húzza át a "JoinAndAggregateData" adatfolyam-tevékenységhez. Ez létrehoz egy "sikeres" értéket, amely miatt az adatfolyam-tevékenység csak akkor fut, ha a másolat sikeres.
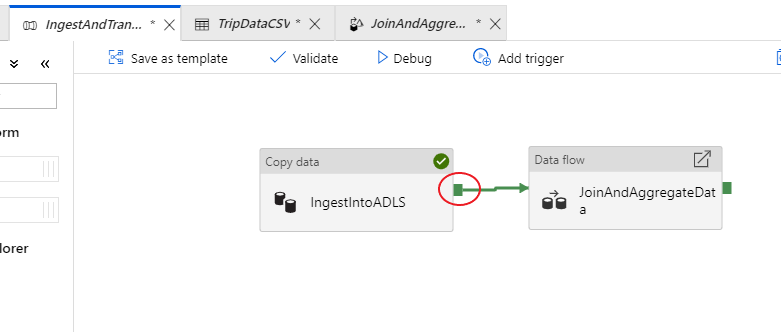
Ahogyan a másolási tevékenységnél is, válassza a Hibakeresés lehetőséget a hibakeresési futtatás végrehajtásához. Hibakeresési futtatások esetén az adatfolyam-tevékenység az aktív hibakeresési fürtöt használja új fürt pörgetése helyett. A folyamat végrehajtása egy kicsit több mint egy percet vesz igénybe.

A másolási tevékenységhez hasonlóan az adatfolyamnak is van egy speciális monitorozási nézete, amelyet a szemüveg ikon ér el a tevékenység befejezésekor.

A monitorozási nézetben egy egyszerűsített adatfolyam-gráf látható, valamint az egyes végrehajtási szakaszok végrehajtási ideje és sorai. Ha helyesen végzett, 49 999 sort kellett volna összesítenie öt sorba ebben a tevékenységben.

Az átalakítások kiválasztásával további részleteket kaphat a végrehajtásról, például particionálási információkat és új/frissített/elvetett oszlopokat.





Ezzel befejezte a labor adat-előállító részét. Ha eseményindítókkal szeretné üzembe helyezni az erőforrásokat, tegye közzé azokat. Sikeresen futtatott egy folyamatot, amely adatokat fogyott az Azure SQL Database-ből az Azure Data Lake Storage-ba a másolási tevékenységgel, majd összesítve az adatokat egy Azure Synapse Analyticsbe. Az adatok sikeres megírásának ellenőrzéséhez tekintse meg magát az SQL Servert.
Adatmegosztás az Azure Data Share szolgáltatás használatával
Ebben a szakaszban megtudhatja, hogyan állíthat be új adatmegosztást az Azure Portal használatával. Ez magában foglalja egy új adatmegosztás létrehozását, amely az Azure Data Lake Storage Gen2 és az Azure Synapse Analytics adatkészleteit tartalmazza. Ezután konfigurál egy pillanatkép-ütemezést, amely lehetővé teszi az adatfelhasználók számára a velük megosztott adatok automatikus frissítését. Ezután meghívja a címzetteket az adatmegosztásba.
Miután létrehozott egy adatmegosztást, átválthat a kalapokra, és adatfelhasználóvá válik. Adatfelhasználóként végigvezeti az adatmegosztási meghívás elfogadásának folyamatán, konfigurálja az adatok fogadásának helyét, és leképezi az adathalmazokat különböző tárolási helyekre. Ezután elindít egy pillanatképet, amely a megadott célhelyre másolja az Önnel megosztott adatokat.
Adatok megosztása (adatszolgáltatói folyamat)
Nyissa meg az Azure Portalt a Microsoft Edge-ben vagy a Google Chrome-ban.
A lap tetején található keresősáv használatával keressen adatmegosztásokat
Válassza ki a névben a "Provider" (Szolgáltató) nevű adatmegosztási fiókot. Például: DataProvider0102.
Válassza az adatok megosztásának megkezdése lehetőséget

Válassza a +Létrehozás lehetőséget az új adatmegosztás konfigurálásának megkezdéséhez.
A Megosztás név alatt adjon meg egy tetszőleges nevet. Ezt a megosztásnevet fogja látni az adatfelhasználó, ezért mindenképpen adjon neki egy leíró nevet, például TaxiData-t.
A Leírás területen adjon meg egy mondatot, amely az adatmegosztás tartalmát írja le. Az adatmegosztás a taxiút-adatok széles skáláját tartalmazza, amelyek számos üzletben vannak tárolva, például az Azure Synapse Analyticsben és az Azure Data Lake Storage-ban.
A Használati feltételek területen adja meg azokat a feltételeket, amelyeket az adatfelhasználónak be kell tartania. Ilyenek például a "Ne ossza el ezeket az adatokat a szervezeten kívül" vagy a "Hivatkozás jogi megállapodásra".

Válassza a Folytatás lehetőséget.
Válassza az Adathalmazok hozzáadása lehetőséget

Az Azure Synapse Analytics kiválasztásával válasszon ki egy táblát az Azure Synapse Analyticsből, amelyben az ADF-átalakítások landoltak.
A folytatás előtt egy szkriptet kap, amelyet futtatnia kell. A megadott szkript létrehoz egy felhasználót az SQL-adatbázisban, hogy lehetővé tegye az Azure Data Share MSI számára a hitelesítést a nevében.
Fontos
A szkript futtatása előtt be kell állítania magát Active Directory Rendszergazda az Azure SQL Database logikai SQL-kiszolgálójához.
Nyisson meg egy új lapot, és lépjen az Azure Portalra. Másolja ki a megadott szkriptet, hogy létrehozzon egy felhasználót abban az adatbázisban, amelyből adatokat szeretne megosztani. Ehhez jelentkezzen be az EDW-adatbázisba az Azure Portal Lekérdezésszerkesztőjével a Microsoft Entra-hitelesítés használatával. A felhasználót a következő példaszkriptben kell módosítania:
CREATE USER [dataprovider-xxxx@contoso.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER [wiassaf@microsoft.com];Váltson vissza az Azure Data Share-be, ahol adathalmazokat adott hozzá az adatmegosztáshoz.
Válassza az EDW elemet, majd válassza az AggregatedTaxiData lehetőséget a táblához.
Válassza az Adathalmaz hozzáadása lehetőséget
Most már rendelkezünk egy SQL-táblával, amely az adathalmaz részét képezi. Ezután további adatkészleteket adunk hozzá az Azure Data Lake Storage-ból.
Válassza az Adathalmaz hozzáadása lehetőséget, és válassza az Azure Data Lake Storage Gen2 lehetőséget

Válassza a Tovább lehetőséget
Bontsa ki a wwtaxidata elemet. Bontsa ki a Boston Taxi adatait. Megoszthatja a fájlszintet.
Válassza ki a Boston Taxi Data mappát, ha a teljes mappát hozzá szeretné adni az adatmegosztáshoz.
Válassza az Adathalmazok hozzáadása lehetőséget
Tekintse át a hozzáadott adathalmazokat. Hozzá kell adnia egy SQL-táblát és egy ADLS Gen2-mappát az adatmegosztáshoz.
Select Continue
Ezen a képernyőn címzetteket vehet fel az adatmegosztásba. A hozzáadott címzettek meghívókat kapnak az adatmegosztáshoz. A tesztkörnyezethez két e-mail-címet kell megadnia:
A benne lévő Azure-előfizetés e-mail-címe.

Adja hozzá a fiktív adatfelhasználó neve .janedoe@fabrikam.com
Ezen a képernyőn konfigurálhat egy pillanatkép-beállítást az adatfelhasználó számára. Ez lehetővé teszi számukra, hogy az Ön által meghatározott időközönként megkapják az adatok rendszeres frissítéseit.
Ellenőrizze a Pillanatkép ütemezését , és konfigurálja az adatok óránkénti frissítését az Ismétlődés legördülő listával.
Select Create.
Most már aktív adatmegosztása van. Lehetővé teszi, hogy áttekintse, mit láthat adatszolgáltatóként adatmegosztás létrehozásakor.
Válassza ki a létrehozott adatmegosztást DataProvider néven. Ehhez az Elküldött megosztások az Adatmegosztásban lehetőség kiválasztásával navigálhat.
Válassza ki a Pillanatkép ütemezése lehetőséget. Ha úgy dönt, letilthatja a pillanatkép-ütemezést.
Ezután válassza az Adathalmazok lapot. A létrehozás után további adatkészleteket is hozzáadhat ehhez az adatmegosztáshoz.
Válassza az Előfizetések megosztása lapot. Még nem léteznek megosztási előfizetések, mert az adatfelhasználó még nem fogadta el a meghívást.
Lépjen a Meghívók lapra. Itt megjelenik a függőben lévő meghívás(ok) listája.

Válassza ki a meghívót janedoe@fabrikam.com. Select Delete. Ha a címzett még nem fogadta el a meghívást, azt a továbbiakban nem fogja tudni megtenni.
Válassza az Előzmények lapot. Egyelőre semmi sem jelenik meg, mert az adatfelhasználó még nem fogadta el a meghívást, és pillanatképet aktivált.






Adatok fogadása (Adatfelhasználói folyamat)
Most, hogy áttekintettük az adatmegosztást, készen állunk arra, hogy kontextust váltsunk, és viseljük az adatfelhasználói kalapunkat.
Most már rendelkeznie kell egy Azure Data Share-meghívóval a Beérkezett üzenetek mappában a Microsoft Azure-ból. Indítsa el az Outlook Web Accesst (outlook.com), és jelentkezzen be az Azure-előfizetéshez megadott hitelesítő adatokkal.
A kapott e-mailben válassza a "Meghívó >megtekintése" lehetőséget. Ezen a ponton szimulálni fogja az adatfelhasználói élményt, amikor egy adatszolgáltató meghívást fogad az adatmegosztásra.

Előfordulhat, hogy a rendszer arra kéri, hogy válasszon ki egy előfizetést. Győződjön meg arról, hogy kiválasztja azt az előfizetést, amelyben ebben a laborban dolgozott.
Válassza ki a DataProvider meghívást.
Ebben a Meghívó képernyőn figyelje meg a korábban adatszolgáltatóként konfigurált adatmegosztás különböző részleteit. Tekintse át a részleteket, és fogadja el a használati feltételeket, ha meg van adva.
Válassza ki a tesztkörnyezethez már létező előfizetést és erőforráscsoportot.
Adatmegosztási fiók esetén válassza a DataConsumer lehetőséget. Új adatmegosztási fiókot is létrehozhat.
A Fogadott megosztás neve mellett figyelje meg, hogy az alapértelmezett megosztás neve az adatszolgáltató által megadott név. Adjon a megosztásnak egy rövid nevet, amely leírja a kapni kívánt adatokat, például a TaxiDataShare-t.

Dönthet úgy, hogy elfogadja és konfigurálja most , vagy fogadja el és konfigurálja később. Ha most úgy dönt, hogy elfogadja és konfigurálja, adjon meg egy tárfiókot, ahol az összes adatot át kell másolni. Ha később elfogadja és konfigurálja, a megosztásban lévő adathalmazok le lesznek képezve, és manuálisan kell őket leképeznie. Ezt később fogjuk választani.
Válassza az Elfogadás lehetőséget, majd konfigurálja később.
A beállítás konfigurálásakor létrejön egy megosztási előfizetés, de az adatok nem érnek el, mivel nincs célhely megfeleltetve.
Ezután konfigurálja az adathalmaz-leképezéseket az adatmegosztáshoz.
Válassza ki a fogadott megosztást (az 5. lépésben megadott nevet).
Az eseményindító pillanatképe szürkítve van, de a megosztás aktív.
Válassza az Adathalmazok lapot. Minden adatkészlet nincs megfeleltetve, ami azt jelenti, hogy nincs célhely az adatok másolásához.
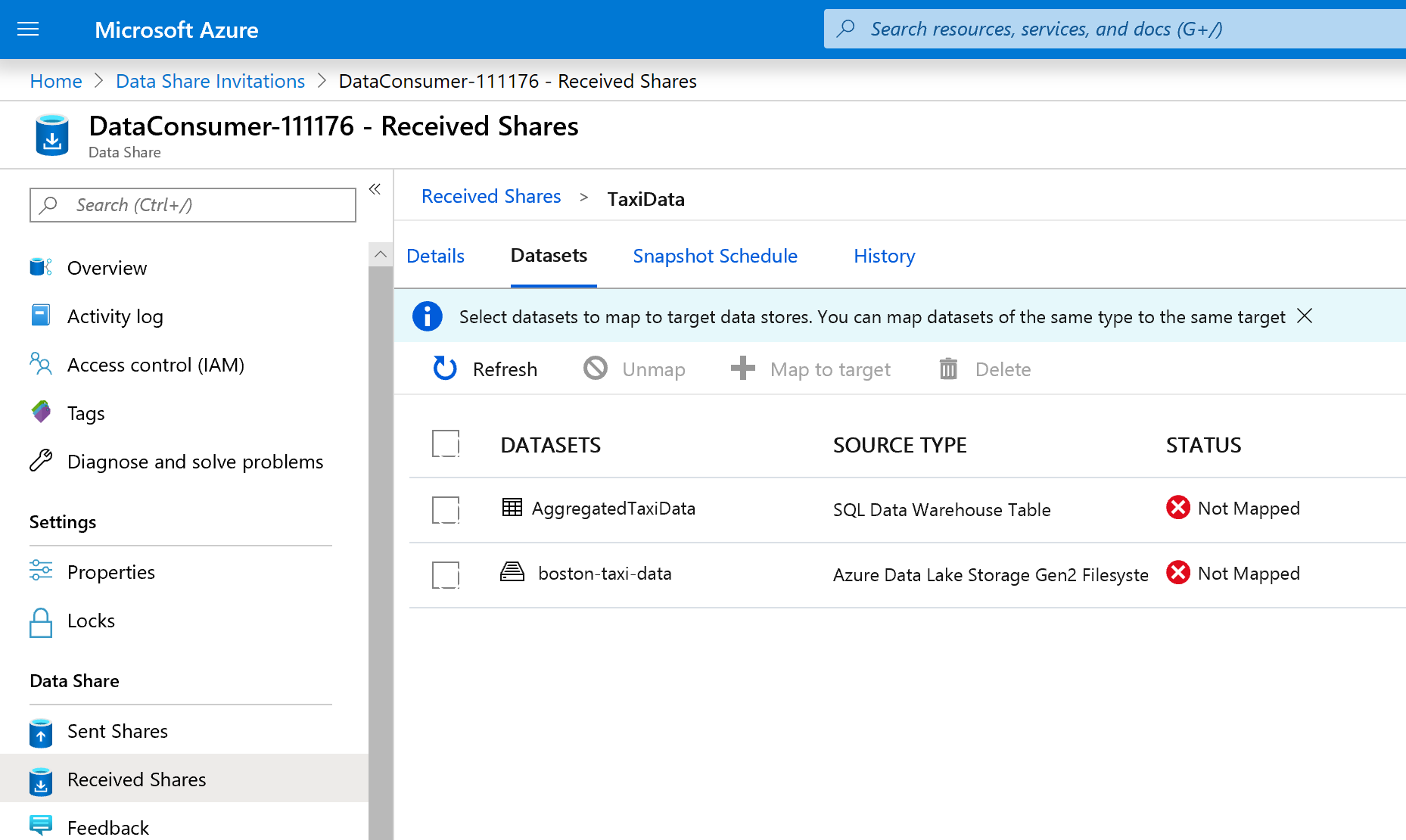
Válassza ki az Azure Synapse Analytics-táblát, majd válassza a + Leképezés célhoz lehetőséget.
A képernyő jobb oldalán válassza a Céladattípus legördülő listát.
Az SQL-adatokat számos adattárhoz rendelheti. Ebben az esetben egy Azure SQL Database-hez leszünk megfeleltetve.

(Nem kötelező) Válassza ki az Azure Data Lake Storage Gen2-t céladattípusként.
(Nem kötelező) Válassza ki azt az előfizetést, erőforráscsoportot és tárfiókot, amelyben dolgozott.
(Nem kötelező) Dönthet úgy, hogy csv vagy parquet formátumban fogadja az adatokat a data lake-be.
A Cél adattípus mellett válassza az Azure SQL Database lehetőséget.
Válassza ki azt az előfizetést, erőforráscsoportot és tárfiókot, amelyben dolgozott.

A folytatáshoz létre kell hoznia egy új felhasználót az SQL Serveren a megadott szkript futtatásával. Először másolja a vágólapra a megadott szkriptet.
Nyisson meg egy új Azure Portal lapot. Ne zárja be a meglévő lapot, mert egy pillanat alatt vissza kell térnie hozzá.
A megnyitott új lapon keresse meg az SQL-adatbázisokat.
Válassza ki az SQL-adatbázist (az előfizetésben csak egynek kell lennie). Ügyeljen arra, hogy ne válassza ki az adattárházat.
Lekérdezésszerkesztő kiválasztása (előzetes verzió)
A Microsoft Entra-hitelesítés használatával jelentkezzen be a Lekérdezésszerkesztőbe.
Futtassa az adatmegosztásban megadott lekérdezést (a 14. lépésben vágólapra másolva).
Ez a parancs lehetővé teszi, hogy az Azure Data Share szolgáltatás felügyelt identitásokat használjon az Azure Serviceshez az SQL Serveren való hitelesítéshez, hogy adatokat másolhasson bele.
Térjen vissza az eredeti lapra, és válassza a Célhoz rendelendő térkép lehetőséget.
Ezután válassza ki az adathalmaz részét képező Azure Data Lake Storage Gen2 mappát, és képezheti le egy Azure Blob Storage-fiókra.

Az összes adathalmaz megfeleltetése után készen áll arra, hogy megkezdje az adatok fogadását az adatszolgáltatótól.

Válassza a Részletek lehetőséget.
Az eseményindító pillanatképe már nem szürkítve van, mivel az adatmegosztásban már vannak másolni kívánt célhelyek.
Válassza az Eseményindító pillanatkép –>Teljes másolat lehetőséget.

Ezzel megkezdi az adatok másolását az új adatmegosztási fiókba. Valós forgatókönyv esetén ezek az adatok egy harmadik féltől származnak.
Az adatok körülbelül 3–5 percet vesznek igénybe. A folyamat előrehaladását az Előzmények lap kiválasztásával figyelheti.
Várakozás közben lépjen az eredeti adatmegosztásra (DataProvider), és tekintse meg az Előfizetések és előzmények megosztása lap állapotát. Most már aktív előfizetés van, és adatszolgáltatóként azt is figyelheti, hogy az adatfelhasználó mikor kezdte fogadni a velük megosztott adatokat.
Lépjen vissza az adatfelhasználó adatmegosztásához. Ha az eseményindító állapota sikeres, keresse meg a cél SQL-adatbázist és a Data Lake-t, és ellenőrizze, hogy az adatok a megfelelő tárolókban landolt-e.







Gratulálunk, befejezte a labort!