Adatok biztonságos átalakítása leképezési adatfolyam használatával
A következőkre vonatkozik: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Ha még csak ismerkedik az Azure Data Factory használatával, olvassa el az Azure Data Factory használatának első lépéseit ismertető cikket.
Ebben az oktatóanyagban a Data Factory felhasználói felületével (UI) fog létrehozni egy folyamatot, amely adatokat másol és alakít át egy Azure Data Lake Storage Gen2-forrásból egy Data Lake Storage Gen2-fogadóba (mindkettő lehetővé teszi a hozzáférést csak a kiválasztott hálózatokhoz) a Data Factory által felügyelt virtuális hálózat adatfolyamának leképezésével. Ebben az oktatóanyagban kibonthatja a konfigurációs mintát, amikor az adatokat leképezési adatfolyam használatával alakítja át.
Az oktatóanyag során a következő lépéseket hajtja végre:
- Adat-előállító létrehozása
- Folyamat létrehozása adatfolyam-tevékenységgel.
- Leképezési adatfolyam létrehozása négy átalakítással.
- A folyamat próbafuttatása
- Adatfolyam-tevékenység figyelése.
Előfeltételek
- Azure-előfizetés. Ha nem rendelkezik Azure-előfizetéssel, mindössze néhány perc alatt létrehozhat egy ingyenes Azure-fiókot a virtuális gép létrehozásának megkezdése előtt.
- Egy Azure Storage-fiók. A Data Lake Storage-t forrás- és fogadóadattárként használja. Ha még nem rendelkezik tárfiókkal, tekintse meg az Azure Storage-fiók létrehozásának lépéseit ismertető cikket. Győződjön meg arról, hogy a tárfiók csak a kiválasztott hálózatokról engedélyezi a hozzáférést.
Az oktatóanyagban átalakítandó fájl a moviesDB.csv, amely ezen a GitHub-tartalomwebhelyen található. Ha le szeretné kérni a fájlt a GitHubról, másolja a tartalmat egy tetszőleges szövegszerkesztőbe, és mentse helyileg .csv fájlként. Ha fel szeretné tölteni a fájlt a tárfiókba, olvassa el a Blobok feltöltése az Azure Portallal című témakört. A példák egy mintaadatok nevű tárolóra fognak hivatkozni.
Adat-előállító létrehozása
Ebben a lépésben létrehoz egy adat-előállítót, és megnyitja a Data Factory felhasználói felületét egy folyamat létrehozásához az adat-előállítóban.
Nyissa meg a Microsoft Edge-et vagy a Google Chrome-ot. Jelenleg csak a Microsoft Edge és a Google Chrome böngészők támogatják a Data Factory felhasználói felületét.
A bal oldali menüben válassza a Resource>Analytics>Data Factory létrehozása lehetőséget.
Az Új adat-előállító lap Név mezőjében adja meg az ADFTutorialDataFactory értéket.
Az adat-előállító nevének globálisan egyedinek kell lennie. Ha hibaüzenetet kap a névértékről, adjon meg egy másik nevet az adat-előállítónak (például a saját neveADFTutorialDataFactory). A Data Factory-összetevők elnevezési szabályait a Data Factory elnevezési szabályait ismertető cikkben találja.
Válassza ki azt az Azure-előfizetést, amelyben az adat-előállítót létre szeretné hozni.
Erőforráscsoport: hajtsa végre a következő lépések egyikét:
- Kattintson a Meglévő használata elemre, majd a legördülő listából válasszon egy meglévő erőforráscsoportot.
- Kattintson az Új létrehozása elemre, és adja meg az erőforráscsoport nevét.
Az erőforráscsoportokkal kapcsolatos információkért tekintse meg az Erőforráscsoportok használata az Azure-erőforrások kezeléséhez ismertető cikket.
A Verzió résznél válassza a V2 értéket.
A Hely területen válassza ki az adat-előállító helyét. Csak a támogatott helyek jelennek meg a legördülő listában. Az adat-előállító által használt adattárak (például az Azure Storage és az Azure SQL Database) és a data factory által használt számítások (például az Azure HDInsight) más régiókban is lehetnek.
Select Create.
A létrehozás befejezése után megjelenik az értesítés az Értesítések központban. Válassza az Ugrás az erőforrásra lehetőséget a Data Factory lapra való ugráshoz.
Válassza az Azure Data Factory Studio megnyitása lehetőséget a Data Factory felhasználói felületének külön lapon való elindításához.
Azure IR létrehozása a Data Factory által felügyelt virtuális hálózatban
Ebben a lépésben létrehoz egy Azure IR-t, és engedélyezi a Data Factory által felügyelt virtuális hálózatot.
A Data Factory portálon lépjen a Kezelés elemre, és válassza az Új lehetőséget egy új Azure IR létrehozásához.
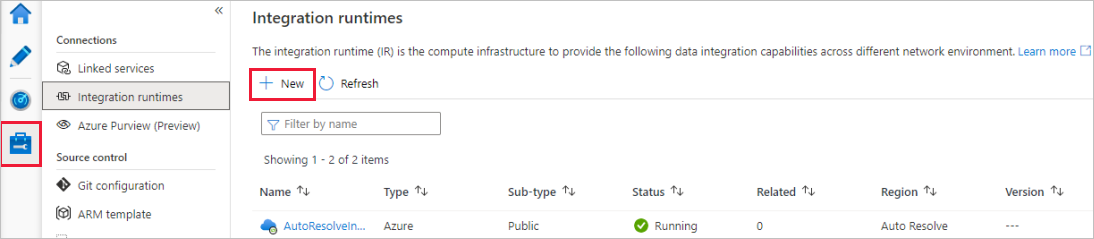
Az Integrációs modul beállítási lapján válassza ki, hogy milyen integrációs modult szeretne létrehozni a szükséges képességek alapján. Ebben az oktatóanyagban válassza a saját üzemeltetésű Azure-t, majd kattintson a Folytatás gombra.
Válassza az Azure-t, majd kattintson a Folytatás gombra egy Azure-integrációs modul létrehozásához.
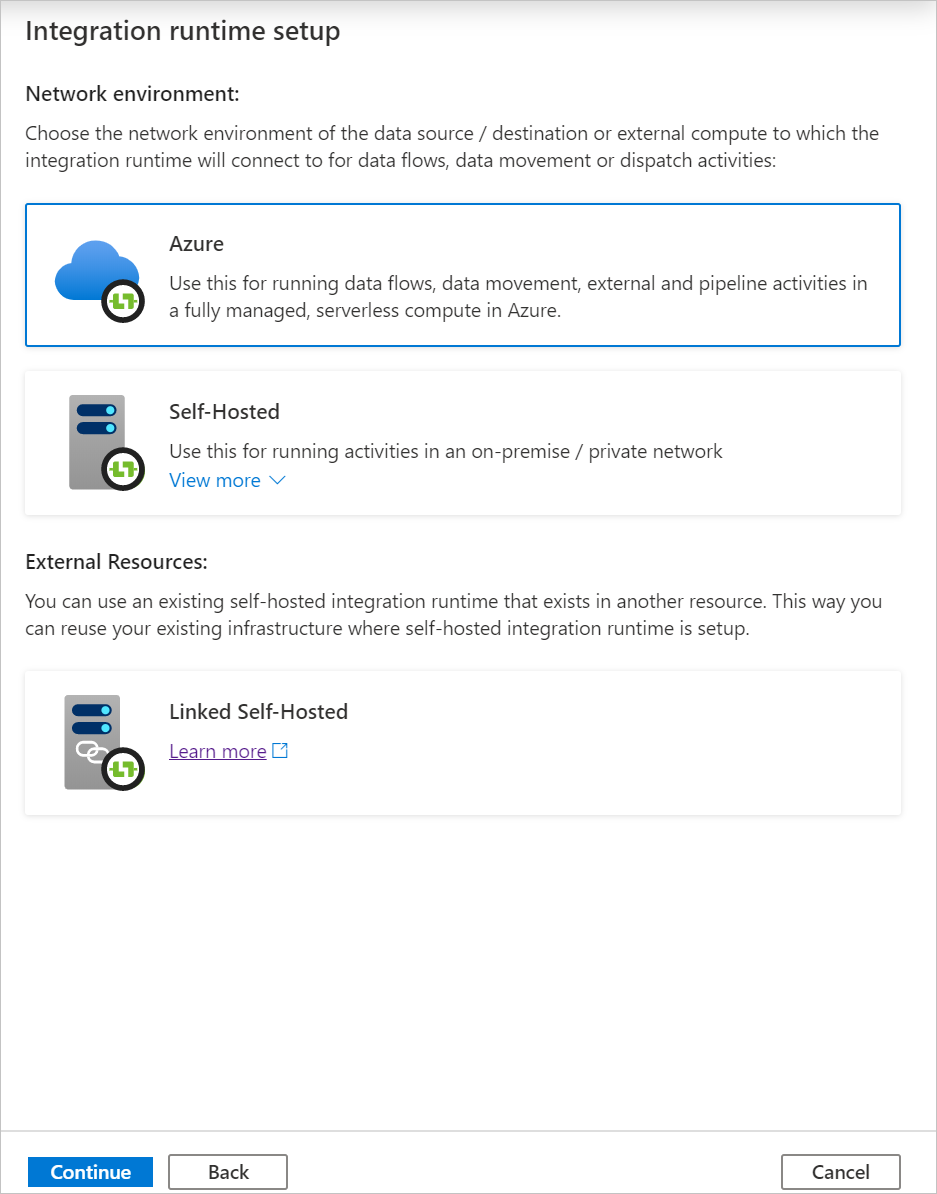
A Virtuális hálózat konfigurációja (előzetes verzió) területen válassza az Engedélyezés lehetőséget.
Select Create.
Folyamat létrehozása adatfolyam-tevékenységgel
Ebben a lépésben egy adatfolyam-tevékenységet tartalmazó folyamatot fog létrehozni.
Az Azure Data Factory kezdőlapján válassza az Orchestrate lehetőséget.
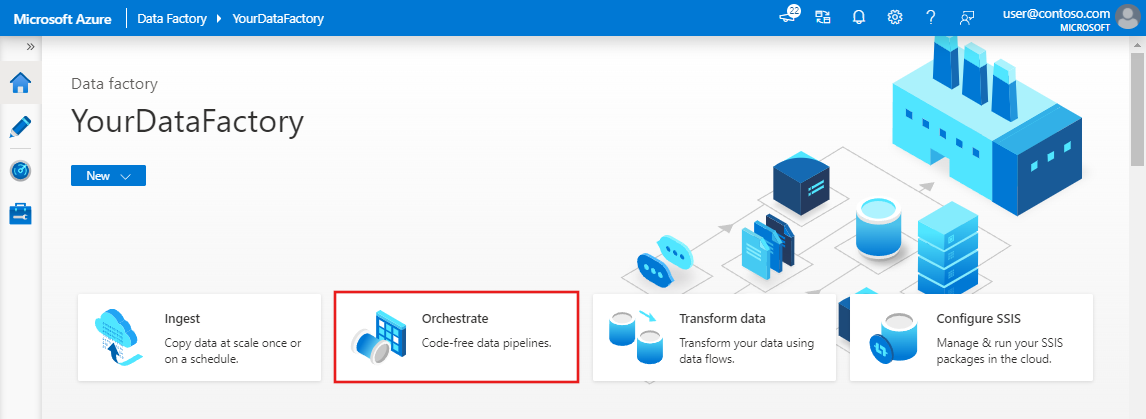
A folyamat tulajdonságok paneljén adja meg a Folyamat nevének TransformMovies elemét.
A Tevékenységek panelen bontsa ki az Áthelyezés és átalakítás elemet. Húzza a Adatfolyam tevékenységet a panelről a folyamatvászonra.
Az Adatfolyam hozzáadása előugró ablakban válassza az Új adatfolyam létrehozása, majd a Leképezési Adatfolyam lehetőséget. Ha végzett, válassza az OK gombot.
Nevezze el az adatfolyamot a TransformMovies névvel a tulajdonságok panelen.
A folyamatvászon felső sávján húzza a Adatfolyam hibakeresési csúszkát. A hibakeresési mód lehetővé teszi az átalakítási logika interaktív tesztelését egy élő Spark-fürtön. Adatfolyam fürtök bemelegedése 5-7 percet vesz igénybe, és a felhasználóknak ajánlott először bekapcsolniuk a hibakeresést, ha Adatfolyam fejlesztést terveznek. További információ: Hibakeresési mód.

Átalakítási logika létrehozása az adatfolyam-vásznon
Az adatfolyam létrehozása után a rendszer automatikusan elküldi az adatfolyam-vásznon. Ebben a lépésben létrehoz egy adatfolyamot, amely a Data Lake Storage-ban a moviesDB.csv fájlt veszi fel, és összesíti a vígjátékok átlagos minősítését 1910 és 2000 között. Ezután visszaírja ezt a fájlt a Data Lake Storage-ba.
A forrásátalakítás hozzáadása
Ebben a lépésben a Data Lake Storage Gen2-t állítja be forrásként.
Az adatfolyam-vásznon adjon hozzá egy forrást a Forrás hozzáadása mező kiválasztásával.
Nevezze el a forrás MoviesDB-t. Új forrásadatkészlet létrehozásához válassza az Új lehetőséget.
Válassza az Azure Data Lake Storage Gen2 lehetőséget, majd a Folytatás lehetőséget.
Válassza a DelimitedText, majd a Continue (Folytatás) lehetőséget.
Nevezze el az adathalmazt a MoviesDB-nek. A társított szolgáltatás legördülő menüjében válassza az Új lehetőséget.
A társított szolgáltatás létrehozása képernyőn adja meg a Data Lake Storage Gen2 társított szolgáltatásának ADLSGen2 nevet, és adja meg a hitelesítési módszert. Ezután adja meg a kapcsolat hitelesítő adatait. Ebben az oktatóanyagban fiókkulcsot használunk a tárfiókhoz való csatlakozáshoz.
Győződjön meg arról, hogy engedélyezi az interaktív szerkesztést. Az engedélyezés eltarthat egy percig.
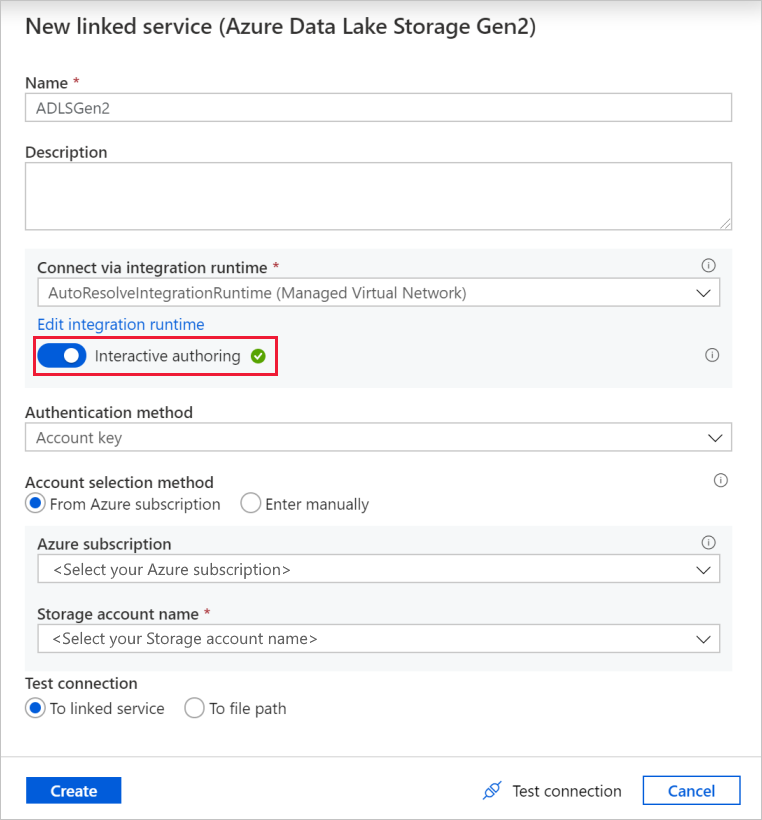
Select Test connection. Sikertelennek kell lennie, mert a tárfiók nem engedélyezi a hozzáférést a privát végpont létrehozása és jóváhagyása nélkül. A hibaüzenetben egy olyan hivatkozást kell látnia, amely egy felügyelt privát végpont létrehozásához követhető privát végpontot hoz létre. Másik lehetőségként lépjen közvetlenül a Kezelés lapra, és kövesse az ebben a szakaszban található utasításokat egy felügyelt privát végpont létrehozásához.
Tartsa nyitva a párbeszédpanelt, majd nyissa meg a tárfiókot.
Kövesse az ebben a szakaszban található utasításokat a privát hivatkozás jóváhagyásához.
Lépjen vissza a párbeszédpanelre. Válassza ismét a Kapcsolat tesztelése lehetőséget, és válassza a Létrehozás lehetőséget a társított szolgáltatás üzembe helyezéséhez.
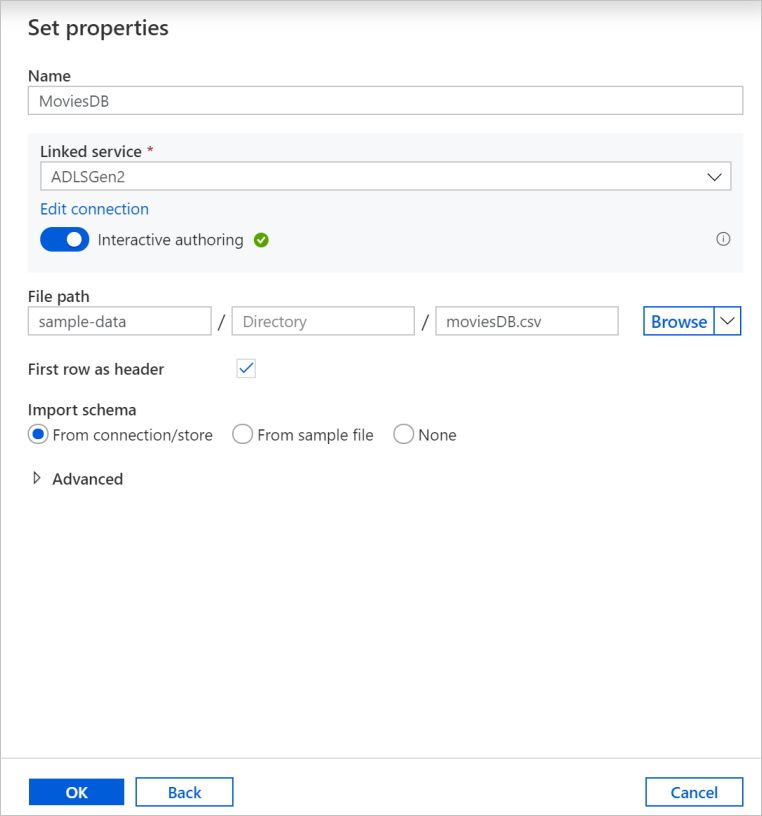
Az adathalmaz létrehozása képernyőn adja meg, hogy hol található a fájl a Fájl elérési útja mező alatt. Ebben az oktatóanyagban a moviesDB.csv fájl a tároló mintaadatai között található. Mivel a fájl fejlécekkel rendelkezik, jelölje be az Első sort fejlécként jelölőnégyzetet. Válassza a Kapcsolat/tár lehetőséget a fejlécséma közvetlen importálásához a tárban lévő fájlból. Ha végzett, válassza az OK gombot.
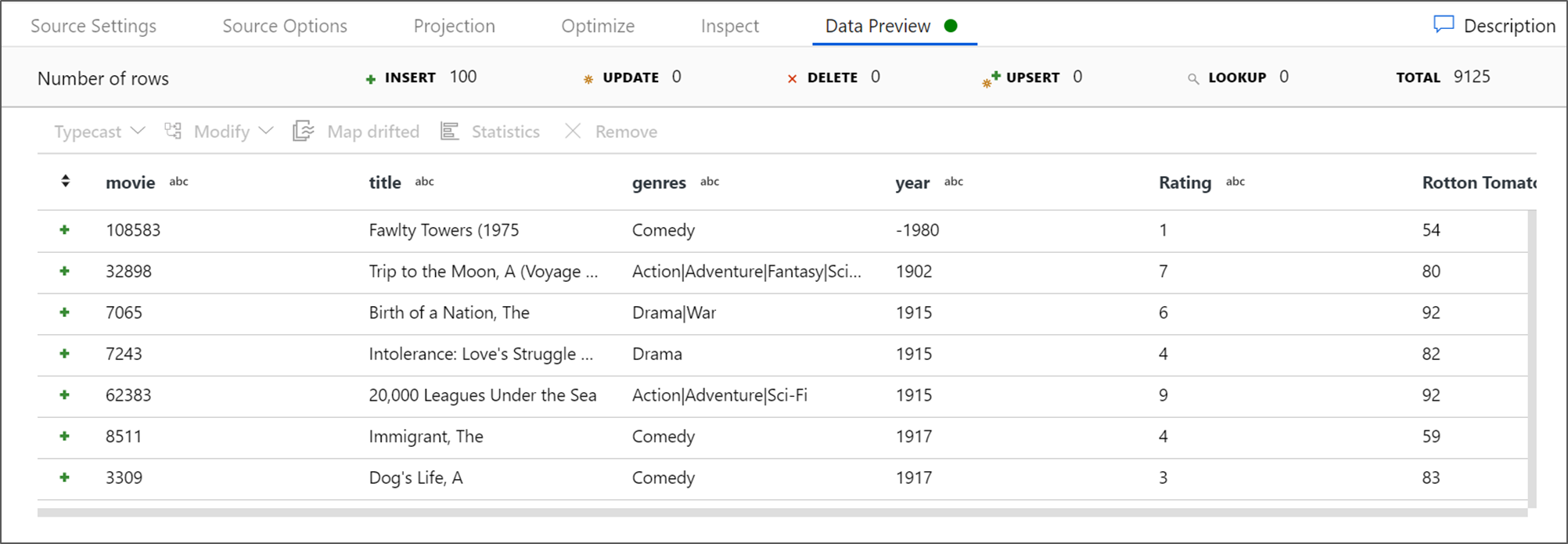
Ha a hibakeresési fürt elindult, lépjen a forrásátalakítás Adatelőnézet lapjára, és válassza a Frissítés lehetőséget az adatok pillanatképének lekéréséhez. Az adatelőnézet használatával ellenőrizheti, hogy az átalakítás megfelelően van-e konfigurálva.
Felügyelt privát végpont létrehozása
Ha az előző kapcsolat tesztelése során nem használta a hivatkozást, kövesse az elérési utat. Most létre kell hoznia egy felügyelt privát végpontot, amelyhez csatlakozni fog a létrehozott társított szolgáltatáshoz.
Lépjen a Kezelés lapra.
Megjegyzés:
Előfordulhat, hogy a Kezelés lap nem érhető el az összes Data Factory-példányhoz. Ha nem látja, a privát végpontok eléréséhez válassza a Szerző> Csatlakozás ions>privát végpont lehetőséget.
Lépjen a Felügyelt privát végpontok szakaszra .
Válassza az + Új lehetőséget a felügyelt privát végpontok alatt.
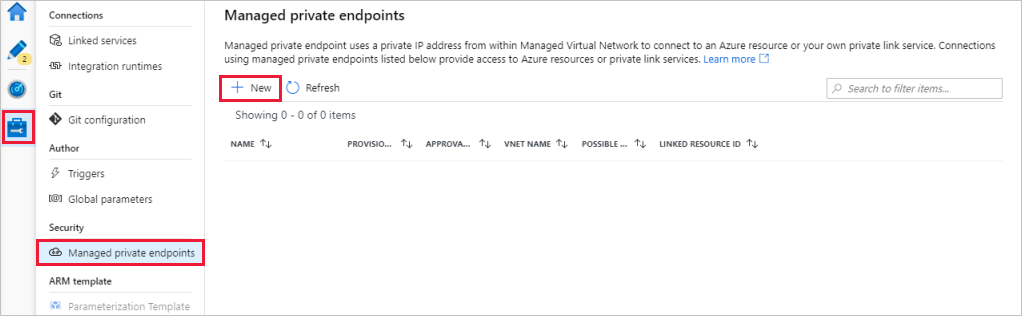
Válassza ki az Azure Data Lake Storage Gen2 csempét a listából, és válassza a Folytatás lehetőséget.
Adja meg a létrehozott tárfiók nevét.
Select Create.
Néhány másodperc elteltével látnia kell, hogy a létrehozott privát hivatkozásnak jóváhagyásra van szüksége.
Válassza ki a létrehozott privát végpontot. Megjelenik egy hivatkozás, amely arra készteti, hogy a tárfiók szintjén jóváhagyja a privát végpontot.
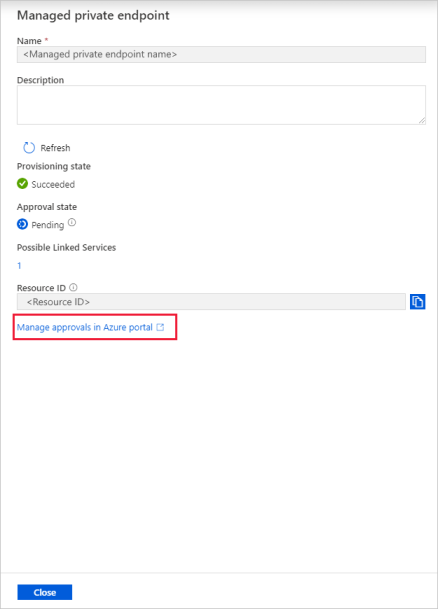
Privát kapcsolat jóváhagyása tárfiókban
A tárfiókban lépjen a privát végpontkapcsolatokra a Gépház szakaszban.
Jelölje be a létrehozott privát végpont melletti jelölőnégyzetet, és válassza a Jóváhagyás lehetőséget.
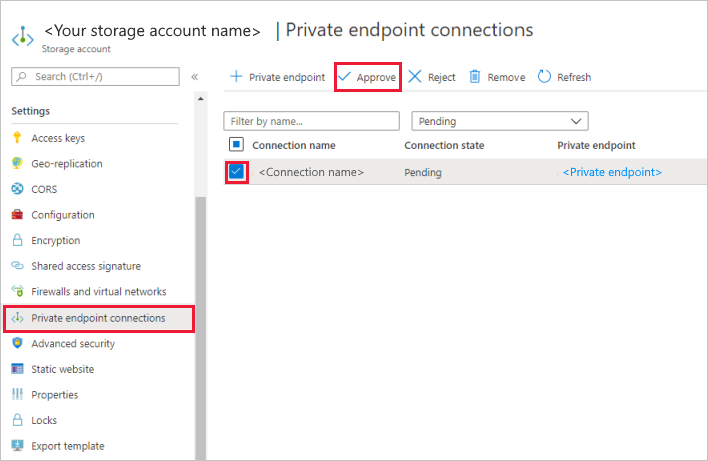
Adjon meg egy leírást, és válassza az igen lehetőséget.
Térjen vissza a Data Factory Kezelés lapjának Felügyelt privát végpontok szakaszához.
Körülbelül egy perc múlva látnia kell, hogy a jóváhagyás megjelenik a privát végponthoz.
A szűrőátalakítás hozzáadása
Az adatfolyam-vásznon a forráscsomópont mellett válassza a plusz ikont egy új átalakítás hozzáadásához. Az első hozzáadni kívánt átalakítás egy szűrő.
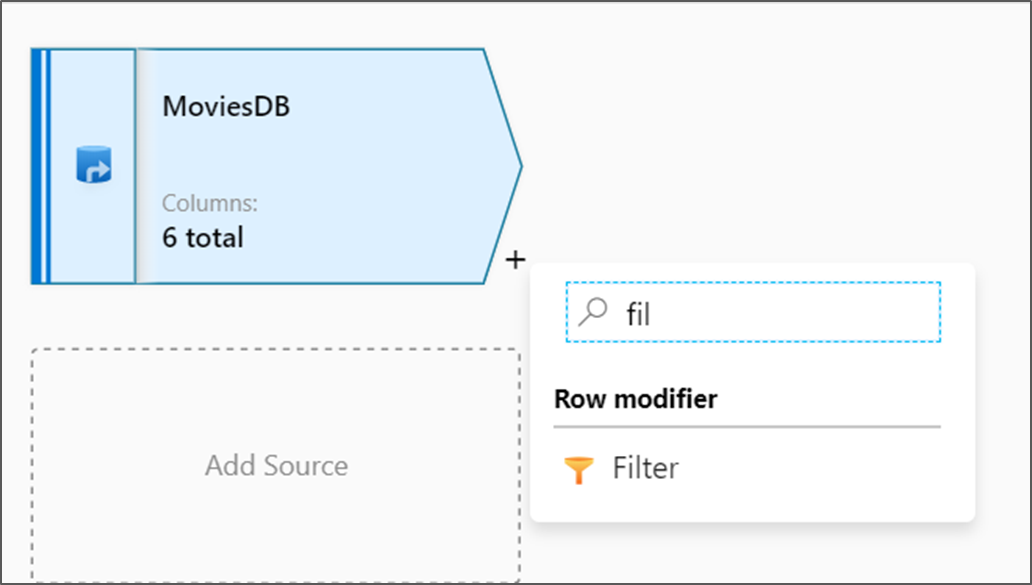
Nevezze el a szűrőátalakítás Szűrőévek nevet. A kifejezésszerkesztő megnyitásához válassza a Szűrő bekapcsolva gomb melletti kifejezésmezőt. Itt adhatja meg a szűrési feltételt.
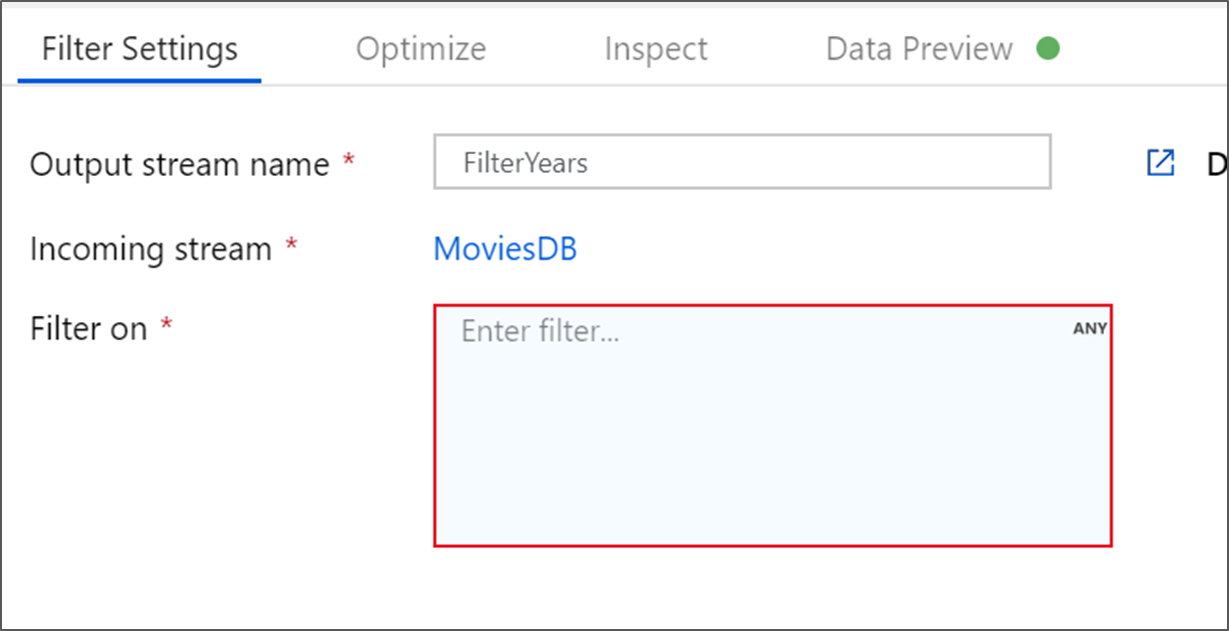
Az adatfolyam-kifejezésszerkesztővel interaktívan hozhat létre különböző átalakításokban használható kifejezéseket. A kifejezések tartalmazhatnak beépített függvényeket, a bemeneti sémából származó oszlopokat és felhasználó által definiált paramétereket. A kifejezések készítéséről további információt az Adatfolyam-kifejezésszerkesztőben talál.
Ebben az oktatóanyagban az 1910 és 2000 között megjelent vígjáték műfajú filmeket szeretné szűrni. Mivel az év jelenleg sztring, a függvény használatával egész számmá kell alakítania
toInteger(). Az 1910-es és a 2000-es literális évértékek összehasonlításához használja a (=) vagy annál kisebb (><=) operátorokat. Egyesítve ezeket a kifejezéseket a (> és a(z) operátorral együtt. A kifejezés a következőképpen jelenik meg:toInteger(year) >= 1910 && toInteger(year) <= 2000Ha meg szeretné találni, hogy mely filmek vígjátékok, a
rlike()függvény segítségével megtalálhatja a "Comedy" mintát az oszlop műfajaiban. Egyesíteni kell arlikekifejezést az év összehasonlításával a következőhöz:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Ha aktív hibakeresési fürttel rendelkezik, a Logika ellenőrzéséhez válassza a Frissítés lehetőséget a kifejezés kimenetének megtekintéséhez a használt bemenetekhez képest. Több helyes válasz is van arra, hogyan valósíthatja meg ezt a logikát az adatfolyam-kifejezés nyelvének használatával.

A kifejezés befejezése után válassza a Mentés és befejezés lehetőséget.
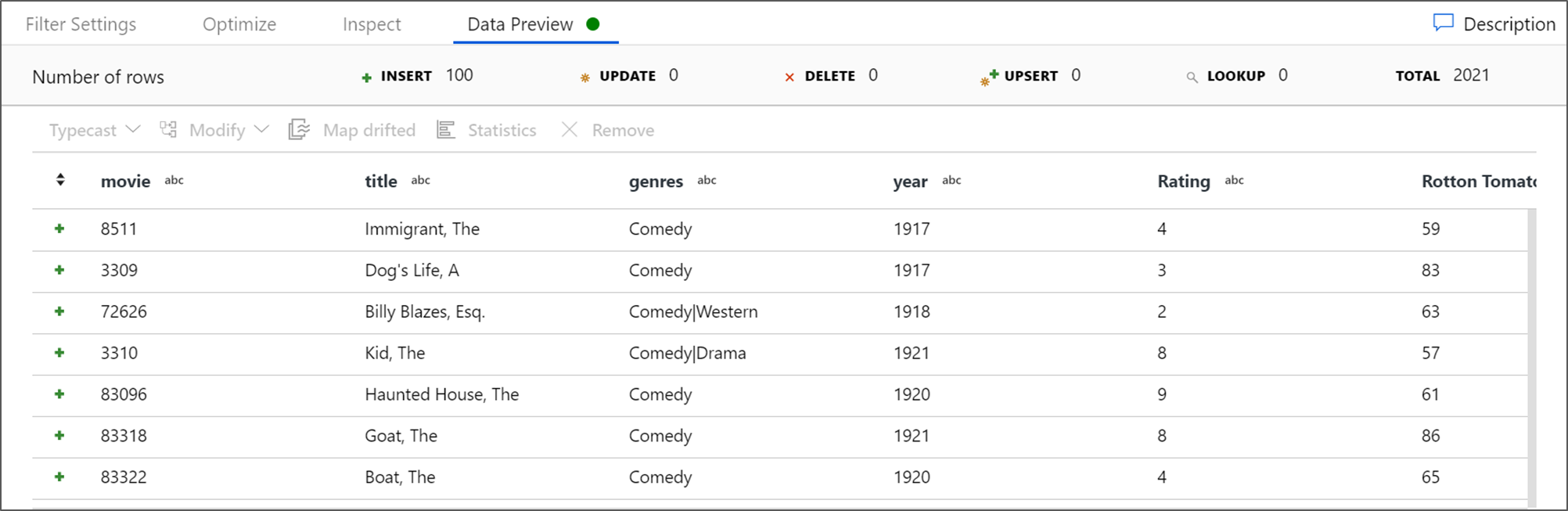
Adatelőnézet beolvasásával ellenőrizze, hogy a szűrő megfelelően működik-e.
Az összesítő átalakítás hozzáadása
A következő átalakítási művelet a Sémamódosító alatt lévő Összesítés átalakítás.
Nevezze el összesített átalakítását AggregateComedyRating néven. A Csoportosítás lapon válassza ki az évet a legördülő listából, és csoportosítsa az összesítéseket a film kiadásának évéhez.
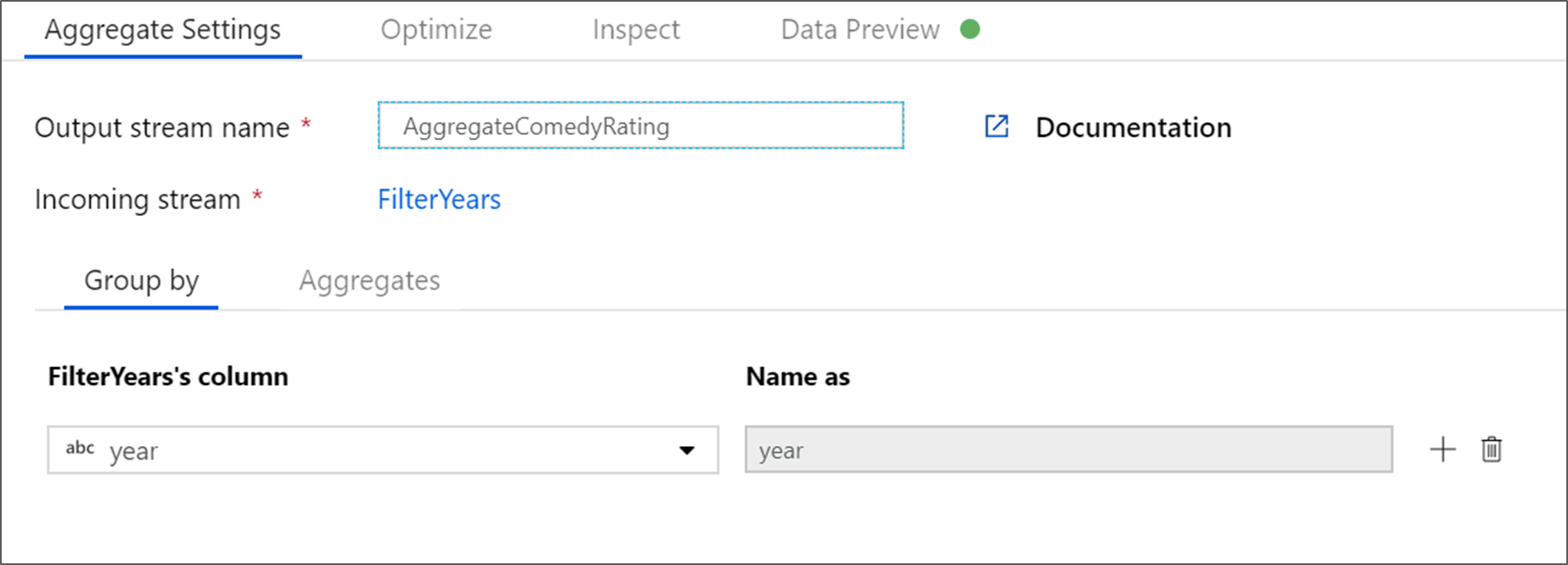
Lépjen az Összesítések lapra. A bal oldali szövegmezőben nevezze el az AverageComedyRating összesítő oszlopot. A megfelelő kifejezésmezőt választva adja meg az összesítő kifejezést a kifejezésszerkesztőn keresztül.
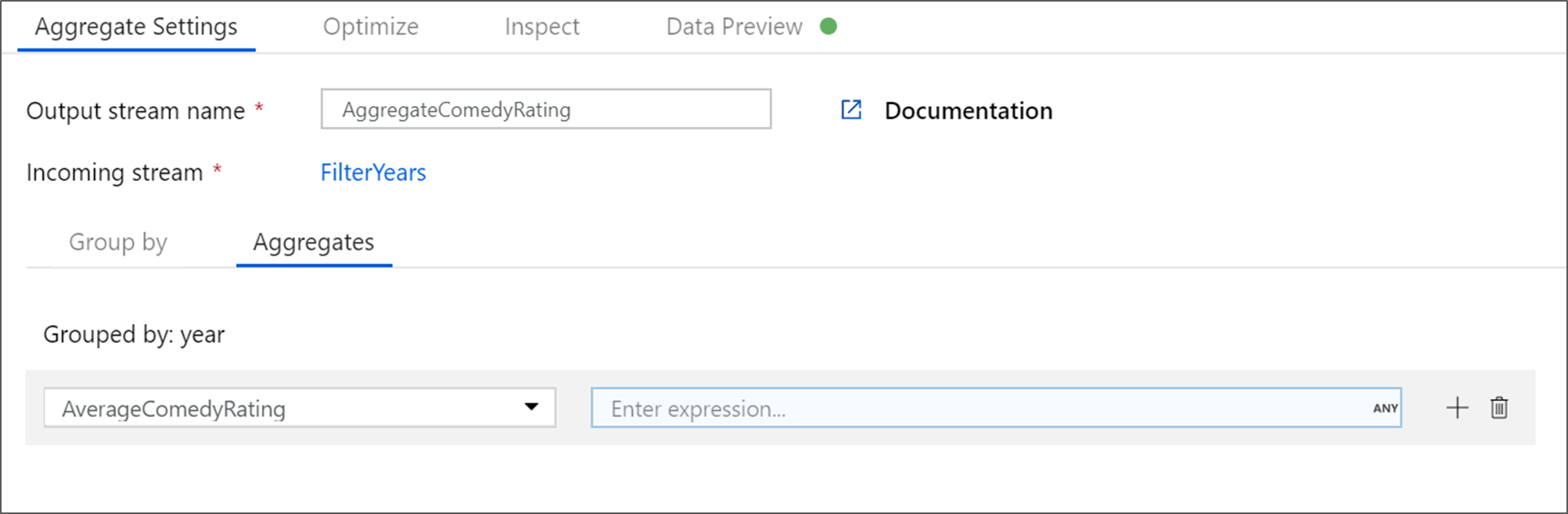
Az oszlopminősítés átlagának lekéréséhez használja az összesítő függvényt
avg(). Mivel az Értékelés egy sztring, ésavg()numerikus bemenetet vesz fel, az értéket számmá kell konvertálnunk atoInteger()függvényen keresztül. Ez a kifejezés a következőképpen néz ki:avg(toInteger(Rating))Ha végzett, válassza a Mentés és befejezés lehetőséget.

Az átalakítási kimenet megtekintéséhez lépjen az Adatelőnézet lapra. Figyelje meg, hogy csak két oszlop van, év és AverageComedyRating.
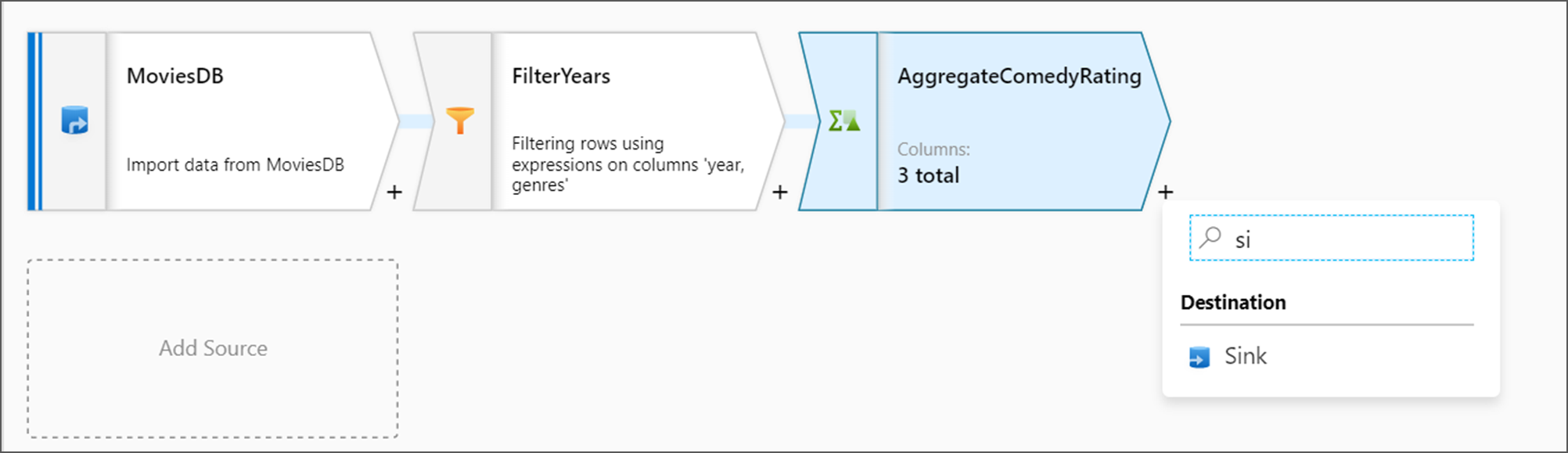
A fogadó átalakításának hozzáadása
A következő lépésben egy Fogadó átalakítást szeretne hozzáadni a Cél területen.
Nevezze el a fogadó fogadóját. Válassza az Új lehetőséget a fogadóadatkészlet létrehozásához.
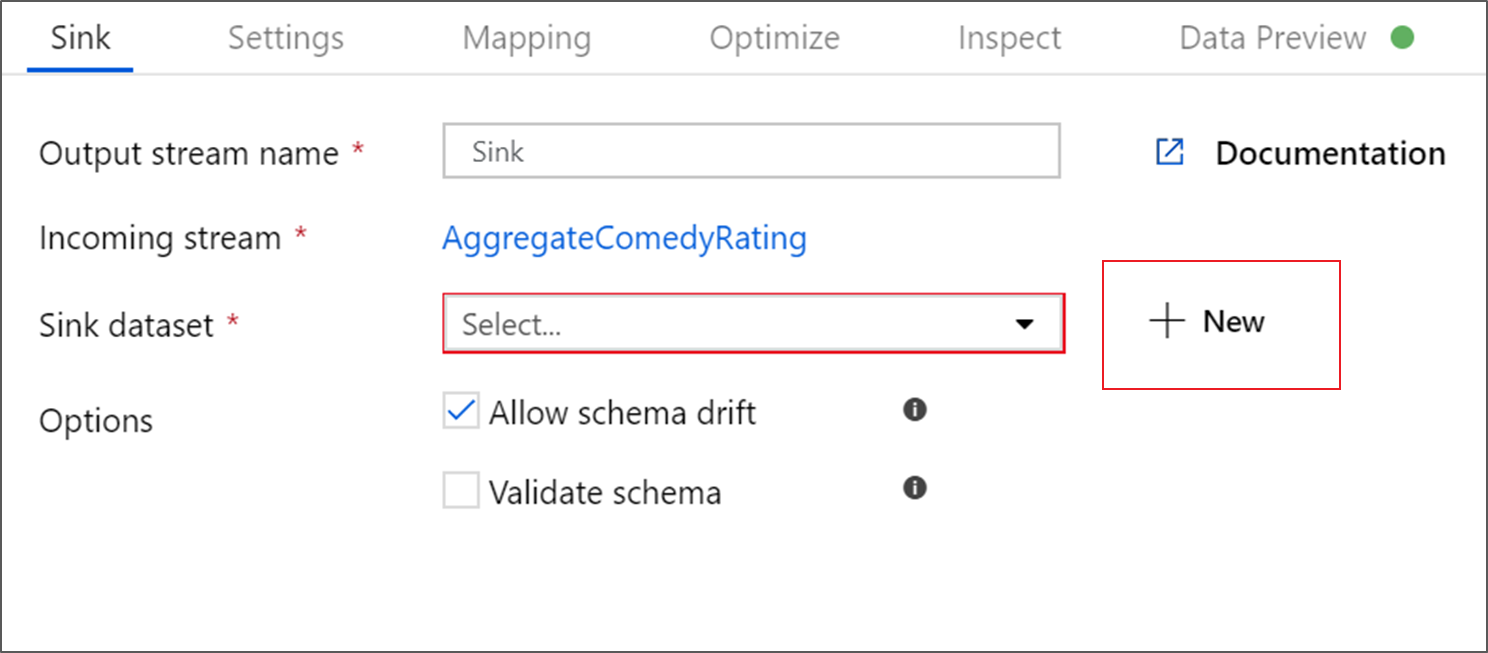
Az Új adathalmaz lapon válassza az Azure Data Lake Storage Gen2 lehetőséget, majd a Folytatás lehetőséget.
A Formátum kiválasztása lapon válassza a DelimitedText, majd a Continue (Folytatás) lehetőséget.
Nevezze el a Fogadó adatkészletet a MoviesSink névvel. Csatolt szolgáltatás esetén válassza ki ugyanazt az ADLSGen2 társított szolgáltatást, amelyet a forrásátalakításhoz hozott létre. Adjon meg egy kimeneti mappát az adatok írásához. Ebben az oktatóanyagban a tárolóminta-adatok mappájának kimenetére írunk. A mappának nem kell előzetesen léteznie, és dinamikusan létrehozható. Jelölje be az Első sort fejlécként jelölőnégyzetet, és válassza a Nincs az importálási sémához jelölőnégyzetet. Kattintson az OK gombra.
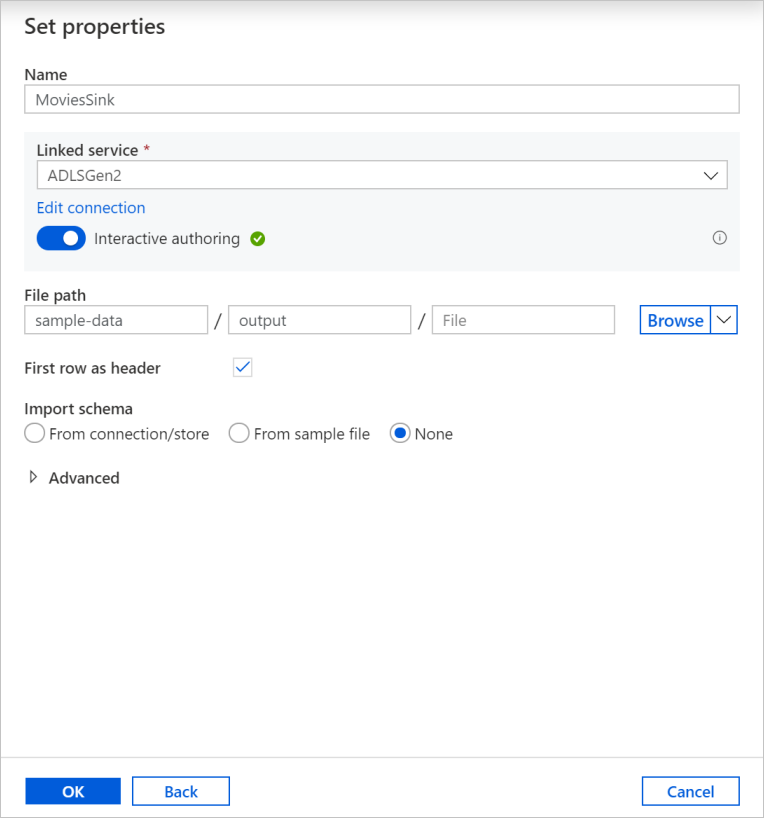
Most befejezte az adatfolyam összeállítását. Készen áll a folyamat futtatására.
Az adatfolyam futtatása és monitorozása
A közzététel előtt hibakeresést végezhet egy folyamaton. Ebben a lépésben elindítja az adatfolyam-folyamat hibakeresési futtatását. Bár az adatelőnézet nem ír adatokat, a hibakeresési futtatás adatokat ír a fogadó célhelyére.
Lépjen a folyamatvászonra. Hibakeresési futtatás indításához válassza a Hibakeresés lehetőséget.
Az adatfolyam-tevékenységek folyamatkeresése az aktív hibakeresési fürtöt használja, de az inicializálás legalább egy percet vesz igénybe. Az előrehaladást a Kimenet lapon követheti nyomon. A futtatás sikeres befejezése után válassza a szemüveg ikont a futtatás részleteinek megadásához.
A részletek oldalon láthatja a sorok számát és az egyes átalakítási lépésekre fordított időt.
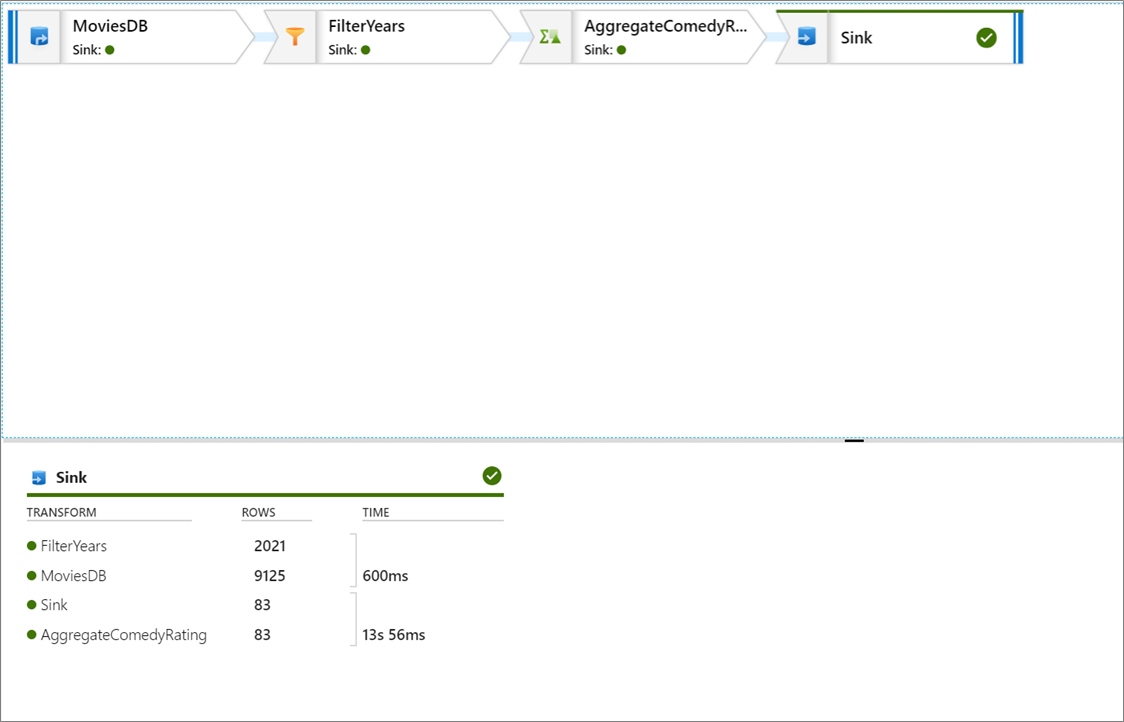
Az átalakítás kiválasztásával részletes információkat kaphat az oszlopokról és az adatok particionálásáról.
Ha helyesen követte ezt az oktatóanyagot, 83 sort és 2 oszlopot kellett volna írnia a fogadó mappába. A blobtároló ellenőrzésével ellenőrizheti, hogy az adatok helyesek-e.
Összesítés
Ebben az oktatóanyagban a Data Factory felhasználói felületével létrehozott egy folyamatot, amely adatokat másol és alakít át egy Data Lake Storage Gen2-forrásból egy Data Lake Storage Gen2-fogadóba (mindkettő csak a kiválasztott hálózatokhoz való hozzáférést teszi lehetővé) a Data Factory által felügyelt virtuális hálózatban lévő adatfolyam leképezésével.