Az Azure Synapse Analytics kiszolgáló nélküli SQL-készleteinek hibaelhárítása
Ez a cikk az Azure Synapse Analytics kiszolgáló nélküli SQL-készletével kapcsolatos leggyakoribb problémák hibaelhárításával kapcsolatos információkat tartalmaz.
Ha többet szeretne megtudni az Azure Synapse Analyticsről, tekintse meg az Azure Synapse Analytics áttekintését és újdonságait.
Synapse Studio
A Synapse Studio egy könnyen használható eszköz, amellyel böngésző használatával férhet hozzá az adatokhoz anélkül, hogy adatbázis-hozzáférési eszközöket kellene telepítenie. A Synapse Studio nem alkalmas nagy mennyiségű adat beolvasására vagy SQL-objektumok teljes körű kezelésére.
A kiszolgáló nélküli SQL-készlet szürkítve jelenik meg a Synapse Studióban
Ha a Synapse Studio nem tud kapcsolatot létesíteni a kiszolgáló nélküli SQL-készletekkel, azt fogja tapasztalni, hogy a kiszolgáló nélküli SQL-készlet szürkítve jelenik meg, vagy offline állapotot jelenít meg.
Ez a probléma általában két okból jelentkezik:
- A hálózat megakadályozza az Azure Synapse Analytics háttérrendszerével való kommunikációt. A leggyakoribb eset az, hogy az 1443-at tartalmazó TCP-port le van tiltva. A kiszolgáló nélküli SQL-készlet működéséhez oldja fel a port letiltását. Más problémák megakadályozhatják a kiszolgáló nélküli SQL-készlet működését is. További információkért tekintse meg a hibaelhárítási útmutatót.
- Nincs engedélye a kiszolgáló nélküli SQL-készletbe való bejelentkezésre. A hozzáférés eléréséhez az Azure Synapse-munkaterület rendszergazdájának hozzá kell adnia Önt a munkaterület-rendszergazdai szerepkörhöz vagy az SQL-rendszergazdai szerepkörhöz. További információ: Azure Synapse hozzáférés-vezérlés.
A Websocket-kapcsolat váratlanul bezárult
Előfordulhat, hogy a lekérdezés meghiúsul a következő hibaüzenettel Websocket connection was closed unexpectedly. : Ez az üzenet azt jelenti, hogy a Synapse Studióval való böngészőkapcsolat megszakadt, például hálózati probléma miatt.
- A probléma megoldásához futtassa újra a lekérdezést.
- A további vizsgálathoz próbálja ki az Azure Data Studio vagy az SQL Server Management Studio ugyanazokat a lekérdezéseket a Synapse Studio helyett.
- Ha ez az üzenet gyakran fordul elő a környezetben, kérje a hálózati rendszergazda segítségét. A tűzfalbeállításokat és a hibaelhárítási útmutatót is ellenőrizheti.
- Ha a probléma továbbra is fennáll, hozzon létre egy támogatási jegyet az Azure Portalon.
A kiszolgáló nélküli adatbázisok nem jelennek meg a Synapse Studióban
Ha nem látja a kiszolgáló nélküli SQL-készletben létrehozott adatbázisokat, ellenőrizze, hogy elindult-e a kiszolgáló nélküli SQL-készlet. Ha a kiszolgáló nélküli SQL-készlet inaktiválva van, az adatbázisok nem jelennek meg. Hajtsa végre például SELECT 1a kiszolgáló nélküli SQL-készleten lévő lekérdezéseket az aktiválásához és az adatbázisok megjelenítéséhez.
A Synapse kiszolgáló nélküli SQL-készlet nem érhető el
Ennek a viselkedésnek gyakran a helytelen hálózati konfiguráció az oka. Győződjön meg arról, hogy a portok megfelelően vannak konfigurálva. Ha tűzfalat vagy privát végpontokat használ, ellenőrizze ezeket a beállításokat is.
Végül győződjön meg arról, hogy a megfelelő szerepkörök biztosítottak, és nem lettek visszavonva.
Nem lehet új adatbázist létrehozni, mert a kérés a régi/lejárt kulcsot fogja használni
Ezt a hibát a munkaterület titkosításhoz használt ügyfél által kezelt kulcsának módosítása okozza. Dönthet úgy, hogy újra titkosítja a munkaterület összes adatát az aktív kulcs legújabb verziójával. Az újratitkosításhoz módosítsa az Azure Portal kulcsát ideiglenes kulcsra, majd váltson vissza a titkosításhoz használni kívánt kulcsra. Itt megtudhatja, hogyan kezelheti a munkaterület kulcsait.
A Synapse kiszolgáló nélküli SQL-készlete nem érhető el, miután egy előfizetést egy másik Microsoft Entra-bérlőnek adott át
Ha egy előfizetést egy másik Microsoft Entra-bérlőre helyezett át, előfordulhat, hogy problémákat tapasztal a kiszolgáló nélküli SQL-készlettel kapcsolatban. Hozzon létre egy támogatási jegyet, és Azure-támogatás felveszi Önnel a kapcsolatot a probléma megoldásához.
Tárterület-hozzáférés
Ha hibaüzenetet kap, amikor megpróbál hozzáférni az Azure Storage-fájlokhoz, győződjön meg arról, hogy rendelkezik hozzáféréssel az adatokhoz. Nyilvánosan elérhető fájlokat kell tudnia elérni. Ha hitelesítő adatok nélkül próbál hozzáférni az adatokhoz, győződjön meg arról, hogy a Microsoft Entra-identitás közvetlenül hozzáfér a fájlokhoz.
Ha rendelkezik a fájlok elérésére használható közös hozzáférésű jogosultságkóddal, győződjön meg arról, hogy létrehozott egy kiszolgálószintű vagy adatbázis-hatókörű hitelesítő adatot, amely tartalmazza a hitelesítő adatokat. A hitelesítő adatokra akkor van szükség, ha a munkaterület által felügyelt identitással és egyéni szolgáltatásnévvel (SPN) kell hozzáférnie az adatokhoz.
Nem olvashatók, nem listázhatók és nem érhetők el fájlok az Azure Data Lake Storage-ban
Ha explicit hitelesítő adatok nélkül használ Microsoft Entra-bejelentkezést, győződjön meg arról, hogy a Microsoft Entra-identitás hozzáfér a tárban lévő fájlokhoz. A fájlok eléréséhez a Microsoft Entra-identitásnak blobadat-olvasó engedéllyel vagy hozzáférés-vezérlésilistákhoz (ACL) kell rendelkeznie az ADLS-ben. További információ: A lekérdezés meghiúsul, mert a fájl nem nyitható meg.
Ha hitelesítő adatokkal fér hozzá a tárterülethez, győződjön meg arról, hogy a felügyelt identitás vagy az egyszerű szolgáltatásnév rendelkezik adatolvasói vagy közreműködői szerepkörrel vagy adott ACL-engedélyekkel. Ha megosztott hozzáférésű jogosultságkód-jogkivonatot használt, győződjön meg arról, hogy rendelkezik rl engedéllyel, és hogy nem járt le.
Ha az SQL-bejelentkezést és a OPENROWSET függvényt adatforrás nélkül használja, győződjön meg arról, hogy rendelkezik a tároló URI-jának megfelelő kiszolgálószintű hitelesítő adatokkal, és rendelkezik engedéllyel a tárhoz való hozzáféréshez.
A lekérdezés meghiúsul, mert a fájl nem nyitható meg
Ha a lekérdezés meghiúsul a hibával File cannot be opened because it does not exist or it is used by another process , és biztos benne, hogy mindkét fájl létezik, és egy másik folyamat nem használja, a kiszolgáló nélküli SQL-készlet nem tudja elérni a fájlt. Ez a probléma általában azért fordul elő, mert a Microsoft Entra-identitás nem rendelkezik a fájlhoz való hozzáféréshez szükséges jogosultságokkal, vagy mert egy tűzfal blokkolja a fájlhoz való hozzáférést.
Alapértelmezés szerint a kiszolgáló nélküli SQL-készlet a Microsoft Entra-identitással próbálja elérni a fájlt. A probléma megoldásához megfelelő jogosultságokkal kell rendelkeznie a fájl eléréséhez. A legegyszerűbb módszer, ha tárblobadat-közreműködői szerepkört ad magának a lekérdezni kívánt tárfiókban.
További információkért lásd:
- A Microsoft Entra ID hozzáférés-vezérlése a tároláshoz
- Tárfiók-hozzáférés szabályozása kiszolgáló nélküli SQL-készlethez a Synapse Analyticsben
Alternatív megoldás a storage blobadatok közreműködői szerepkörére
Ahelyett, hogy tárblobadat-közreműködői szerepkört biztosítanának magának, részletesebb engedélyeket is adhat a fájlok egy részhalmazához.
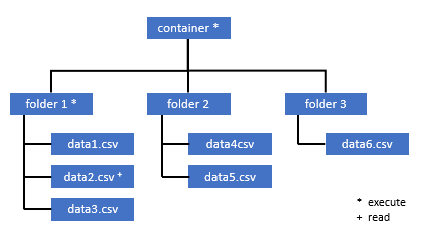
Minden olyan felhasználónak, akinek hozzá kell férnie a tároló egyes adataihoz, rendelkeznie kell AZ ÖSSZES szülőmappára vonatkozó VÉGREHAJTÁSI engedéllyel, egészen a gyökérig (a tárolóig).
További információ arról , hogyan állíthat be ACL-eket az Azure Data Lake Storage Gen2-ben.
Feljegyzés
A tároló szintjén a végrehajtási engedélyt az Azure Data Lake Storage Gen2-ben kell beállítani. A mappára vonatkozó engedélyek az Azure Synapse-ban állíthatók be.
Ha ebben a példában data2.csv szeretne lekérdezni, a következő engedélyekre van szükség:
- Engedély végrehajtása a tárolón
- Engedély végrehajtása a mappában1
- Olvasási engedély a data2.csv
Jelentkezzen be az Azure Synapse-be egy rendszergazdai felhasználóval, aki teljes engedélyekkel rendelkezik a elérni kívánt adatokhoz.
Az adatpanelen kattintson a jobb gombbal a fájlra, és válassza a Hozzáférés kezelése lehetőséget.
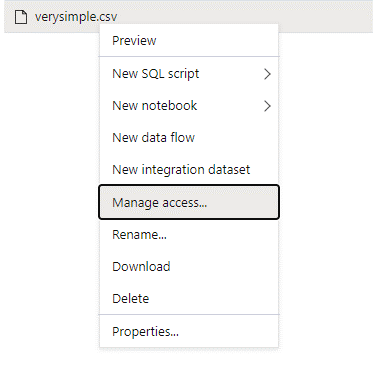
Válassza ki legalább az Olvasási engedélyt. Adja meg például a felhasználó UPN-jét vagy objektumazonosítóját
user@contoso.com. Válassza a Hozzáadás lehetőséget.Olvasási engedély megadása ehhez a felhasználóhoz.

Feljegyzés
A vendégfelhasználók számára ezt a lépést közvetlenül az Azure Data Lake-zel kell elvégezni, mert az nem végezhető el közvetlenül az Azure Synapse-on keresztül.
Az elérési út könyvtárának tartalma nem listázható
Ez a hiba azt jelzi, hogy az Azure Data Lake-t lekérdező felhasználó nem tudja listázni a tárban lévő fájlokat. A hiba több esetben is előfordulhat:
- A Microsoft Entra átmenő hitelesítést használó Microsoft Entra-felhasználó nem rendelkezik engedéllyel a Fájlok listázásához a Data Lake Storage-ban.
- Az a Microsoft Entra-azonosító vagy SQL-felhasználó, aki megosztott hozzáférésű jogosultságkód-kulcs vagy munkaterület által felügyelt identitás használatával olvas adatokat, és a kulcs vagy identitás nem rendelkezik engedéllyel a tárolóban lévő fájlok listázására.
- Az a felhasználó, aki hozzáfér a Dataverse-adatokhoz, és nem rendelkezik engedéllyel adatok lekérdezésére a Dataverse-ben. Ez a forgatókönyv sql-felhasználók használata esetén fordulhat elő.
- Előfordulhat, hogy a Delta Lake-hez hozzáférő felhasználó nem rendelkezik engedéllyel a Delta Lake tranzakciónaplójának olvasásához.
A probléma megoldásának legegyszerűbb módja, ha megadja magának a Storage Blob Data Contributor szerepkört a lekérdezni kívánt tárfiókban.
További információkért lásd:
- A Microsoft Entra ID hozzáférés-vezérlése a tároláshoz
- Tárfiók-hozzáférés szabályozása kiszolgáló nélküli SQL-készlethez a Synapse Analyticsben
A Dataverse-tábla tartalma nem listázható
Ha az Azure Synapse Link for Dataverse-t használja a csatolt DataVerse-táblák olvasásához, microsoft Entra-fiókkal kell hozzáférnie a csatolt adatokhoz a kiszolgáló nélküli SQL-készlet használatával. További információ: Azure Synapse Link for Dataverse with Azure Data Lake.
Ha SQL-bejelentkezéssel próbál beolvasni egy külső táblát, amely a DataVerse táblára hivatkozik, a következő hibaüzenet jelenik meg: External table '???' is not accessible because content of directory cannot be listed.
A dataverse külső táblák mindig a Microsoft Entra átengedési hitelesítését használják. Nem konfigurálhatja őket közös hozzáférésű jogosultságkódkulcs vagy munkaterület által felügyelt identitás használatára.
A Delta Lake tranzakciónapló tartalma nem listázható
A következő hibaüzenet jelenik meg, ha a kiszolgáló nélküli SQL-készlet nem tudja beolvasni a Delta Lake tranzakciónapló mappáját:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Győződjön meg arról, hogy a _delta_log mappa létezik. Lehet, hogy olyan egyszerű Parquet-fájlokat kérdez le, amelyek nem lesznek Delta Lake formátumúvá konvertálva. Ha a _delta_log mappa létezik, győződjön meg arról, hogy olvasási és listázási engedéllyel rendelkezik a mögöttes Delta Lake-mappákon. Próbálja meg közvetlenül a json-fájlokat olvasni a használatával FORMAT='csv'. Helyezze az URI-t a BULK paraméterbe:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Ha ez a lekérdezés sikertelen, a hívónak nincs engedélye a mögöttes tárfájlok olvasására.
Lekérdezés végrehajtása
A lekérdezés végrehajtása során a következő esetekben jelenhetnek meg hibák:
- A hívó nem tud hozzáférni bizonyos objektumokhoz.
- A lekérdezés nem fér hozzá külső adatokhoz.
- A lekérdezés olyan funkciókat tartalmaz, amelyek nem támogatottak a kiszolgáló nélküli SQL-készletekben.
A lekérdezés meghiúsul, mert az aktuális erőforrás-korlátozások miatt nem hajtható végre
Előfordulhat, hogy a lekérdezés meghiúsul a következő hibaüzenettel This query cannot be executed due to current resource constraints. : Ez az üzenet azt jelenti, hogy a kiszolgáló nélküli SQL-készlet jelenleg nem hajtható végre. Íme néhány hibaelhárítási lehetőség:
- Kérjük, győződjön meg arról, hogy megfelelő méretű adattípusokat használ.
- Ha a lekérdezés Parquet-fájlokra irányul, javasoljuk, hogy expliciten adja meg a sztringoszlopok típusát, mert alapértelmezés szerinti beállításuk VARCHAR(8000). Ellenőrizze a következtetett adattípusokat.
- Ha a lekérdezése CSV-fájlokat céloz meg, érdemes lehet statisztikákat létrehozni.
- A lekérdezés optimalizálásához tekintse meg a kiszolgáló nélküli SQL-készlet teljesítménnyel kapcsolatos ajánlott eljárásait.
A lekérdezés időkorlátja lejárt
A rendszer akkor adja vissza a hibát Query timeout expired , ha a lekérdezés több mint 30 percet hajtott végre kiszolgáló nélküli SQL-készleten. A kiszolgáló nélküli SQL-készlet korlátja nem módosítható.
- Próbálja optimalizálni a lekérdezést az ajánlott eljárások alkalmazásával.
- Próbálja meg materializálni a lekérdezések egy részét úgy, hogy külső táblát hoz létre a kiválasztás (CETAS) használatával.
- Ellenőrizze, hogy van-e egyidejű számítási feladat a kiszolgáló nélküli SQL-készleten, mert a többi lekérdezés igénybe veheti az erőforrásokat. Ebben az esetben a számítási feladatot több munkaterületre is feloszthatja.
Érvénytelen objektumnév
A hiba Invalid object name 'table name' azt jelzi, hogy olyan objektumot használ, például egy táblát vagy nézetet, amely nem létezik a kiszolgáló nélküli SQL-készlet adatbázisában. Próbálja ki az alábbi lehetőségeket:
Listázhatja a táblákat vagy nézeteket, és ellenőrizheti, hogy létezik-e az objektum. Használja az SQL Server Management Studiót vagy az Azure Data Studiót, mert előfordulhat, hogy a Synapse Studio olyan táblákat jelenít meg, amelyek nem érhetők el a kiszolgáló nélküli SQL-készletben.
Ha látja az objektumot, ellenőrizze, hogy kis- és nagybetűkre érzékeny/bináris adatbázis-rendezést használ-e. Lehet, hogy az objektumnév nem egyezik meg a lekérdezésben használt névvel. Bináris adatbázis-rendezéssel és
Employeeemployeekét különböző objektummal.Ha nem látja az objektumot, lehet, hogy egy táblát próbál lekérdezni egy tóból vagy Spark-adatbázisból. Előfordulhat, hogy a tábla nem érhető el a kiszolgáló nélküli SQL-készletben, mert:
- A táblázat néhány olyan oszloptípust tartalmaz, amelyek nem jeleníthetők meg kiszolgáló nélküli SQL-készletben.
- A tábla olyan formátummal rendelkezik, amely nem támogatott a kiszolgáló nélküli SQL-készletben. Ilyenek például az Avro vagy az ORC.
A sztring- vagy bináris adatok csonkoltak
Ez a hiba akkor fordul elő, ha a sztring vagy bináris oszloptípus hossza (például VARCHAR, VARBINARYvagy NVARCHAR) rövidebb, mint az éppen beolvasott adatok tényleges mérete. Ezt a hibát az oszloptípus hosszának növelésével háríthatja el:
- Ha a sztringoszlop típusként
VARCHAR(32)van definiálva, és a szöveg 60 karakter, használja a típust (vagy hosszabb) azVARCHAR(60)oszlopsémában. - Ha a séma következtetését használja (a séma nélkül), a
WITHrendszer minden sztringoszlopot automatikusan típuskéntVARCHAR(8000)definiál. Ha ezt a hibát kapja, explicit módon definiálja a sémát egyWITHnagyobbVARCHAR(MAX)oszloptípusú záradékban a hiba megoldásához. - Ha a tábla a Lake-adatbázisban található, próbálja meg növelni a sztringoszlop méretét a Spark-készletben.
- Próbálja meg engedélyezni a
SET ANSI_WARNINGS OFFkiszolgáló nélküli SQL-készlet számára a VARCHAR értékek automatikus csonkítását, ha ez nem befolyásolja a funkciókat.
Nem szereplő idézőjel a karaktersztring után
Ritka esetekben, amikor a LIKE operátort karakterláncoszlopon vagy a sztringkonstansokkal való összehasonlítással használja, a következő hibaüzenet jelenhet meg:
Unclosed quotation mark after the character string
Ez a hiba akkor fordulhat elő, ha az Latin1_General_100_BIN2_UTF8 oszlop rendezést használja. A probléma megoldásához próbálja meg a rendezés helyett az Latin1_General_100_BIN2_UTF8 oszlop rendezését beállítaniLatin1_General_100_CI_AS_SC_UTF8. Ha a hiba továbbra is fennáll, küldjön támogatási kérést az Azure Portalon keresztül.
Nem sikerült lefoglalni a tempdb-területet, miközben adatokat továbbít az egyik disztribúcióból a másikba
A hiba Could not allocate tempdb space while transferring data from one distribution to another akkor jelenik meg, ha a lekérdezés-végrehajtási motor nem tudja feldolgozni az adatokat, és nem tudja továbbítani a lekérdezést végrehajtó csomópontok között. Az általános lekérdezés speciális esete, mert az aktuális erőforrás-korlátozások hibája miatt nem hajtható végre. Ez a hiba akkor jelenik meg, ha az adatbázishoz tempdb lefoglalt erőforrások nem elegendőek a lekérdezés futtatásához.
Ajánlott eljárások alkalmazása támogatási jegy küldése előtt.
A lekérdezés egy külső fájl kezelésével kapcsolatos hibával meghiúsul (a hibák maximális száma elérve)
Ha a lekérdezés a hibaüzenettel error handling external file: Max errors count reachedmeghiúsul, az azt jelenti, hogy a megadott oszloptípus és a betöltendő adatok nem egyeznek.
Ha további információt szeretne kapni a hibáról, valamint arról, hogy mely sorokat és oszlopokat szeretné megnézni, módosítsa az elemző verzióját a következőre 2.01.0: .
Példa
Ha ezzel a lekérdezéssel szeretné lekérdezni a fájlt names.csv , az Azure Synapse kiszolgáló nélküli SQL-készlet a következő hibával tér vissza: Error handling external file: 'Max error count reached'. File/External table name: [filepath]. Például:
A names.csv fájl a következőket tartalmazza:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
1. lekérdezés:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Ok
Amint az elemző verziója 2.0-ról 1.0-ra módosul, a hibaüzenetek segítenek azonosítani a problémát. Az új hibaüzenet most jelenik meg Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
A csonkolás azt jelzi, hogy az oszloptípus túl kicsi az adatokhoz való igazításhoz. A fájl leghosszabb keresztneve names.csv hét karakterből áll. A használni kívánt adattípusnak legalább VARCHAR(7) típusúnak kell lennie. A hibát a következő kódsor okozza:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
A lekérdezés ennek megfelelően történő módosítása megoldja a hibát. A hibakeresés után módosítsa ismét az elemző verzióját 2.0-ra a maximális teljesítmény eléréséhez.
További információ arról, hogy mikor érdemes használni az elemzőverziót: OpenROW Standard kiadás T használata kiszolgáló nélküli SQL-készlet használatával a Synapse Analyticsben.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Nem tölthető be tömegesen, mert a fájl nem nyitható meg
A hiba Cannot bulk load because the file could not be opened akkor jelenik meg, ha egy fájl módosul a lekérdezés végrehajtása során. Általában olyan hibaüzenet jelenhet meg, mint a Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
A kiszolgáló nélküli SQL-készletek nem tudják olvasni a lekérdezés futtatása közben módosított fájlokat. A lekérdezés nem tudja zárolni a fájlokat. Ha tudja, hogy a módosítási művelet hozzáfűzve van, próbálja meg beállítani a következő beállítást: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
További információ: csak hozzáfűző fájlok lekérdezése vagy táblák létrehozása csak hozzáfűző fájlokon.
A lekérdezés adatkonvertálási hibával meghiúsul
Előfordulhat, hogy a lekérdezés meghiúsul a következő hibaüzenettelBulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath].: Ez az üzenet azt jelenti, hogy az adattípusok nem egyeznek az n és az m oszlop tényleges adataival.
Ha például csak egész számokat vár az adatokban, de az n sorban van egy sztring, akkor ez a hibaüzenet jelenik meg.
A probléma megoldásához vizsgálja meg a fájlt és a választott adattípusokat. Azt is ellenőrizze, hogy a sorelválasztó és a mező terminátorbeállításai helyesek-e. Az alábbi példa bemutatja, hogyan végezhető el a vizsgálat a VARCHAR oszloptípussal.
A mezőkifejezésekről, a sorhatárolókról és a menekülő idéző karakterekről további információt a CSV-fájlok lekérdezése című témakörben talál.
Példa
Ha le szeretné kérdezni a fájlt names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
A következő lekérdezéssel:
1. lekérdezés:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Az Azure Synapse kiszolgáló nélküli SQL-készlete a hibát adja vissza Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Meg kell böngészni az adatokat, és megalapozott döntést kell hozni a probléma kezelése érdekében. A problémát okozó adatok megtekintéséhez először módosítani kell az adattípust. A rendszer aHELYETT, hogy a SMALLINT adattípussal kérdezi le az azonosító oszlopot, a VARCHAR(100) a probléma elemzésére szolgál.
Ezzel a kissé módosított 2. lekérdezéssel az adatok most már feldolgozhatók a nevek listájának visszaadásához.
2. lekérdezés:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Megfigyelheti, hogy az adatok az ötödik sorban nem várt azonosítóértékekkel rendelkeznek. Ilyen körülmények között fontos, hogy igazodjunk az adatok üzleti tulajdonosához annak érdekében, hogy a példához hasonló sérült adatok hogyan kerülhetők el. Ha az alkalmazás szintjén nem lehetséges a megelőzés, itt az ésszerű méretű VARCHAR lehet az egyetlen lehetőség.
Tipp.
Próbálja meg minél rövidebbre tenni a VARCHAR() elemet. Ha lehetséges, kerülje a VARCHAR(MAX) értéket, mert ez ronthatja a teljesítményt.
A lekérdezés eredménye nem a várt módon néz ki
Előfordulhat, hogy a lekérdezés nem hiúsul meg, de előfordulhat, hogy az eredményhalmaz nem a várt módon működik. Előfordulhat, hogy az eredményül kapott oszlopok üresek, vagy váratlan adatokat ad vissza. Ebben a forgatókönyvben valószínű, hogy helytelenül választotta ki a sorelválasztót vagy a mező terminátorát.
A probléma megoldásához tekintse meg az adatokat, és módosítsa ezeket a beállításokat. A lekérdezés hibakeresése egyszerű, ahogyan az alábbi példában is látható.
Példa
Ha a fájlt names.csv az 1. lekérdezésben szeretné lekérdezni, az Azure Synapse kiszolgáló nélküli SQL-készlete páratlan eredményt ad vissza:
A names.csv-ben:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Úgy tűnik, hogy nincs érték az oszlopban Firstname. Ehelyett az összes érték az ID oszlopban kötött ki. Ezeket az értékeket vessző választja el egymástól. A problémát ez a kódsor okozta, mert a pontosvessző helyett a vesszőt kell választani mezőkifejezésként:
FIELDTERMINATOR =';',
Az egyetlen karakter módosítása megoldja a problémát:
FIELDTERMINATOR =',',
A 2. lekérdezés által létrehozott eredményhalmaz a vártnak megfelelően néz ki:
2. lekérdezés:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Visszatér:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
A típusoszlop nem kompatibilis a külső adattípussal
Ha a lekérdezés a hibaüzenettel Column [column-name] of type [type-name] is not compatible with external data type […], meghiúsul, valószínű, hogy egy PARQUET-adattípus helytelen SQL-adattípusra van leképezve.
Ha például a Parquet-fájlnak van egy lebegőpontos számokat tartalmazó oszlopára (például 12,89), és megpróbálta leképezni az INT-be, akkor ez a hibaüzenet jelenik meg.
A probléma megoldásához vizsgálja meg a fájlt és a választott adattípusokat. Ez a leképezési táblázat segít a megfelelő SQL-adattípus kiválasztásában. Ajánlott eljárásként csak olyan oszlopok leképezését adja meg, amelyek egyébként feloldanák a VARCHAR adattípust. Ha lehetséges, a VARCHAR elkerülése jobb teljesítményt eredményez a lekérdezésekben.
Példa
Ha ezzel a lekérdezéssel szeretné lekérdezni a fájlt taxi-data.parquet , az Azure Synapse kiszolgáló nélküli SQL-készlet a következő hibát adja vissza:
A fájl taxi-data.parquet a következőket tartalmazza:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
1. lekérdezés:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Ez a hibaüzenet azt jelzi, hogy az adattípusok nem kompatibilisek, és az INT helyett a FLOAT használatát javasolja. A hibát a következő kódsor okozza:
SumTripDistance INT,
Ezzel a kissé módosított 2. lekérdezéssel az adatok most már feldolgozhatók, és mindhárom oszlopot megjelenítik:
2. lekérdezés:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
A lekérdezés olyan objektumra hivatkozik, amely nem támogatott elosztott feldolgozási módban
A hiba The query references an object that is not supported in distributed processing mode azt jelzi, hogy olyan objektumot vagy függvényt használt, amely nem használható az Azure Storage vagy az Azure Cosmos DB elemzési tárban lévő adatok lekérdezése során.
Egyes objektumok, például rendszernézetek és függvények nem használhatók az Azure Data Lake-ben vagy az Azure Cosmos DB elemzési tárában tárolt adatok lekérdezése során. Ne használja a külső adatokat rendszernézetekkel összekapcsoló lekérdezéseket, töltsön be külső adatokat egy ideiglenes táblába, vagy használjon biztonsági vagy metaadat-függvényeket a külső adatok szűréséhez.
Sikertelen WaitIOCompletion hívás
A hibaüzenet WaitIOCompletion call failed azt jelzi, hogy a lekérdezés sikertelen volt, miközben arra várt, hogy végrehajtsa az adatokat beolvasó I/O-műveletet az Azure Data Lake távoli tárolóból.
A hibaüzenet a következő mintával rendelkezik: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Győződjön meg arról, hogy a tároló ugyanabban a régióban van, mint a kiszolgáló nélküli SQL-készlet. Ellenőrizze a tárolási metrikákat, és ellenőrizze, hogy nincsenek-e más számítási feladatok a tárolási rétegen, például új fájlok feltöltése, amelyek betölthetik az I/O-kérelmeket.
A HRESULT mező tartalmazza az eredménykódot. A következő hibakódok a leggyakoribbak a lehetséges megoldásokkal együtt.
Ez a hibakód azt jelenti, hogy a forrásfájl nincs a tárolóban.
Ennek a hibakódnak több oka is lehet:
- A fájlt egy másik alkalmazás törölte.
- Ebben a gyakori forgatókönyvben a lekérdezés végrehajtása elindul, számba veszi a fájlokat, és a fájlok megtalálhatók. Később a lekérdezés végrehajtása során egy fájl törlődik. Törölheti például a Databricks, a Spark vagy az Azure Data Factory. A lekérdezés meghiúsul, mert a fájl nem található.
- Ez a hiba a Delta formátummal is előfordulhat. A lekérdezés újrapróbálkozása sikeres lehet, mert a tábla új verziója van, és a törölt fájl nem lesz újra lekérdezve.
- A rendszer érvénytelen végrehajtási tervet gyorsítótáraz.
- Ideiglenes megoldásként futtassa ezt a parancsot:
DBCC FREEPROCCACHE. Ha a probléma továbbra is fennáll, hozzon létre egy támogatási jegyet.
- Ideiglenes megoldásként futtassa ezt a parancsot:
Helytelen szintaxis a NOT közelében
A hiba Incorrect syntax near 'NOT' azt jelzi, hogy vannak olyan külső táblák, amelyek oszlopai a NOT NULL kényszert tartalmazzák az oszlopdefinícióban.
- Frissítse a táblát, hogy eltávolítsa a NOT NULL értéket az oszlopdefinícióból.
- Ez a hiba néha átmeneti módon is előfordulhat egy CETAS-utasításból létrehozott táblák esetén. Ha a probléma nem oldható meg, megpróbálhatja elvetni és újra létrehozni a külső táblát.
A partícióoszlop NULL értékeket ad vissza
Ha a lekérdezés null értékeket ad vissza particionálási oszlopok helyett, vagy nem találja a partícióoszlopokat, néhány lehetséges hibaelhárítási lépése van:
- Ha táblákkal kérdez le egy particionált adatkészletet, vegye figyelembe, hogy a táblák nem támogatják a particionálást. Cserélje le a táblát a particionált nézetekre.
- Ha a particionált nézeteket az OPENROW Standard kiadás T használatával használja, amely a FILEPATH() függvény használatával kéri le a particionált fájlokat, győződjön meg arról, hogy helyesen adta meg a helyettesítő karakterek mintáját a helyen, és a megfelelő indexet használta a helyettesítő karakterre való hivatkozáshoz.
- Ha közvetlenül a particionált mappában kérdezi le a fájlokat, vegye figyelembe, hogy a particionálási oszlopok nem a fájloszlopok részei. A particionálási értékek a mappa elérési útjaiba kerülnek, nem a fájlokba. Ezért a fájlok nem tartalmazzák a particionálási értékeket.
Az oszloptípushoz tartozó érték beszúrása kötegbe DATETIME2 nem sikerült
A hiba Inserting value to batch for column type DATETIME2 failed azt jelzi, hogy a kiszolgáló nélküli készlet nem tudja beolvasni a mögöttes fájlok dátumértékeit. A Parquet- vagy Delta Lake-fájlban tárolt dátum/idő érték nem jeleníthető meg oszlopként DATETIME2 .
Vizsgálja meg a fájl minimális értékét a Spark használatával, és ellenőrizze, hogy egyes dátumok kisebbek-e 0001-01-03-nál. Ha a fájlokat a Spark 2.4 (nem támogatott futtatókörnyezeti verzió) verziójával vagy az örökölt datetime storage formátumot használó magasabb Spark-verzióval tárolta, akkor a korábbi dátum/idő értékek a Kiszolgáló nélküli SQL-készletekben használt prolitikus Gergely-naptárhoz nem igazodó Julián naptárral vannak megírva.
Kétnapos különbség lehet a Parquetben (egyes Spark-verziókban) használt Julian-naptár és a kiszolgáló nélküli SQL-készletben használt prolitikus Gergely-naptár között. Ez a különbség negatív dátumértékké alakítást okozhat, amely érvénytelen.
Próbálja a Spark használatával frissíteni ezeket az értékeket, mert érvénytelen dátumértékekként vannak kezelve az SQL-ben. Az alábbi minta bemutatja, hogyan frissítheti az SQL-dátumtartományon kívüli értékeket NULL értékre a Delta Lake-ben:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Ez a módosítás eltávolítja a nem megjeleníthető értékeket. Előfordulhat, hogy a többi dátumérték megfelelően van betöltve, de helytelenül jelenik meg, mert még mindig van különbség a Julián és a gergely-naptárak között. A Spark 3.0-s vagy régebbi verzióinak használata esetén még a korábbi dátumok esetében 1900-01-01 is váratlan dátumeltolódások jelenhetnek meg.
Fontolja meg a Spark 3.1 vagy újabb verzióra való migrálást, és váltson a proleptikus Gergely-naptárra. A Legújabb Spark-verziók alapértelmezés szerint egy olyan gergely-naptárt használnak, amely a kiszolgáló nélküli SQL-készlet naptárához igazodik. Töltse újra az örökölt adatokat a Spark magasabb verziójával, és a következő beállítással javítsa ki a dátumokat:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
A lekérdezés topológiaváltozás vagy számítási tároló hibája miatt meghiúsult
Ez a hiba azt jelezheti, hogy belső folyamathiba történt a kiszolgáló nélküli SQL-készletben. Küldjön egy támogatási jegyet minden szükséges részlettel, amely segíthet a Azure-támogatás csapatnak a probléma kivizsgálásában.
Írja le a szokásos számítási feladathoz képest szokatlan eseményeket. Előfordulhat például, hogy a hiba bekövetkezése előtt nagy számú egyidejű kérés vagy speciális számítási feladat vagy lekérdezés kezdődött el.
A helyettesítő karakterek bővítése időtúllépést
A Lekérdezés mappák és több fájl szakaszban leírtak szerint a kiszolgáló nélküli SQL-készlet támogatja a több fájl/mappa helyettesítő karakterek használatával történő olvasását. Lekérdezésenként legfeljebb 10 helyettesítő karakter lehet. Tisztában kell lennie azzal, hogy ez a funkció költséges. Időbe telik, mire a kiszolgáló nélküli készlet felsorolja az összes olyan fájlt, amely megfelel a helyettesítő karakternek. Ez késést eredményez, és ez a késés akkor nőhet, ha a lekérdezéssel próbálkozó fájlok száma magas. Ebben az esetben a következő hibába ütközhet:
"Wildcard expansion timed out after X seconds."
Ennek elkerülése érdekében több megoldási lépést is elvégezhet:
- Ajánlott eljárások alkalmazása a kiszolgáló nélküli SQL-készlet ajánlott eljárásaiban leírtak szerint.
- Próbálja meg csökkenteni a lekérdezni kívánt fájlok számát úgy, hogy a fájlokat nagyobbakba tömöríti. Próbálja meg 100 MB felett tartani a fájlméreteket.
- Győződjön meg arról, hogy a particionálási oszlopokra vonatkozó szűrőket mindenhol használja a rendszer, ahol csak lehetséges.
- Ha delta fájlformátumot használ, használja a Spark írásoptimalizálási funkcióját. Ez javíthatja a lekérdezések teljesítményét azáltal, hogy csökkenti az olvasni és feldolgozni kívánt adatok mennyiségét. Az optimalizált írás használatának módját az Apache Spark írási optimalizálása című témakör ismerteti.
- Ha el szeretné kerülni a legfelső szintű helyettesítő karakterek némelyikét az implicit szűrők particionálási oszlopokon való hatékony keményítésével, használja a dinamikus SQL-t.
Hiányzó oszlop automatikus sémakövetkeztetés használatakor
Egyszerűen lekérdezhet fájlokat séma ismerete vagy megadása nélkül a WITH záradék kihagyásával. Ebben az esetben az oszlopnevek és adattípusok a fájlokból következtetnek. Ne feledje, hogy ha egyszerre több fájlt olvas be, a rendszer a sémát az első fájlszolgáltatásból származó tárolóból fogja kikövetkeztetni. Ez azt jelentheti, hogy a várt oszlopok némelyike hiányzik, mindezt azért, mert a szolgáltatás által a séma meghatározására használt fájl nem tartalmazza ezeket az oszlopokat. A séma explicit megadásához használja az OPENROW Standard kiadás T WITH záradékot. Ha sémát ad meg (külső tábla vagy OPENROW Standard kiadás T WITH záradék használatával), akkor a rendszer alapértelmezett hasábút-módot használ. Ez azt jelenti, hogy az egyes fájlokban nem létező oszlopok NULL-ként lesznek visszaadva (a fájlok sorai esetében). Az elérésiút-mód használatának megismeréséhez tekintse meg az alábbi dokumentációt és mintát.
Konfiguráció
A kiszolgáló nélküli SQL-készletek lehetővé teszik a T-SQL használatát az adatbázis-objektumok konfigurálásához. Vannak bizonyos korlátozások:
- Nem hozhat létre objektumokat
masteréslakehouseSpark-adatbázisokat. - A hitelesítő adatok létrehozásához főkulcs szükséges.
- Engedéllyel kell rendelkeznie az objektumokban használt adatokra való hivatkozáshoz.
Nem hozható létre adatbázis
Ha a hibaüzenet CREATE DATABASE failed. User database limit has been already reached.jelenik meg, létrehozta az egy munkaterületen támogatott adatbázisok maximális számát. További információ: Korlátozások.
- Ha el kell különítenie az objektumokat, használjon sémákat az adatbázisokban.
- Ha az Azure Data Lake Storage-ra kell hivatkoznia, hozzon létre olyan lakehouse-adatbázisokat vagy Spark-adatbázisokat, amelyek szinkronizálva lesznek a kiszolgáló nélküli SQL-készletben.
A tábla létrehozása vagy módosítása nem sikerült, mert a minimális sorméret meghaladja a maximálisan megengedett 8060 bájtos táblázatsorméretet
Bármely tábla legfeljebb 8KB méretű lehet soronként (a soron kívüli VARCHAR(MAX)/VARBINARY(MAX) adatokat nem beleértve). Ha olyan táblát hoz létre, amelyben a sor celláinak teljes mérete meghaladja a 8060 bájtot, a következő hibaüzenet jelenik meg:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Ez a hiba akkor is előfordulhat a Lake-adatbázisban, ha egy 8060 bájtnál nagyobb oszlopméretű Spark-táblát hoz létre, és a kiszolgáló nélküli SQL-készlet nem tud olyan táblát létrehozni, amely a Spark-tábla adataira hivatkozik.
Kockázatcsökkentésként kerülje a rögzített mérettípusok használatát, és CHAR(N) cserélje le őket változó mérettípusokra VARCHAR(N) , vagy csökkentse a méretet a következőben CHAR(N): . Lásd: 8KB-s sorok csoportkorlátozása az SQL Serverben.
A művelet végrehajtása előtt hozzon létre egy főkulcsot az adatbázisban, vagy nyissa meg a főkulcsot a munkamenetben
Ha a lekérdezés a hibaüzenettel Please create a master key in the database or open the master key in the session before performing this operation.meghiúsul, az azt jelenti, hogy a felhasználói adatbázis jelenleg nem fér hozzá a főkulcshoz.
Valószínűleg létrehozott egy új felhasználói adatbázist, és még nem hozott létre főkulcsot.
A probléma megoldásához hozzon létre egy főkulcsot a következő lekérdezéssel:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Feljegyzés
Cserélje le 'strongpasswordhere' itt egy másik titkos kódra.
A CREATE utasítás nem támogatott a főadatbázisban
Ha a lekérdezés a hibaüzenettel Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database.meghiúsul, az azt jelenti, hogy a master kiszolgáló nélküli SQL-készlet adatbázisa nem támogatja a következő létrehozását:
- Külső táblák.
- Külső adatforrások.
- Adatbázis-hatókörbe tartozó hitelesítő adatok.
- Külső fájlformátumok.
A megoldás a következő:
Felhasználói adatbázis létrehozása:
CREATE DATABASE <DATABASE_NAME>Hajtsa végre a CREATE utasítást a DATABA Standard kiadás_NAME> kontextusában<, amely korábban sikertelen volt az
masteradatbázis esetében.Íme egy példa egy külső fájlformátum létrehozására:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Nem hozható létre Microsoft Entra-bejelentkezés vagy felhasználó
Ha hibaüzenetet kap, amikor új Microsoft Entra-bejelentkezést vagy -felhasználót próbál létrehozni egy adatbázisban, ellenőrizze az adatbázishoz való csatlakozáshoz használt bejelentkezést. Az új Microsoft Entra-felhasználót létrehozó bejelentkezésnek engedéllyel kell rendelkeznie a Microsoft Entra tartomány eléréséhez, és ellenőriznie kell, hogy létezik-e a felhasználó. Vegye figyelembe, hogy:
- Az SQL-bejelentkezések nem rendelkeznek ezzel az engedéllyel, ezért ezt a hibát mindig megkapja, ha SQL-hitelesítést használ.
- Ha Microsoft Entra-bejelentkezéssel hoz létre új bejelentkezéseket, ellenőrizze, hogy rendelkezik-e engedéllyel a Microsoft Entra tartományhoz való hozzáféréshez.
Azure Cosmos DB
A kiszolgáló nélküli SQL-készletek lehetővé teszik az Azure Cosmos DB elemzési tárterületének lekérdezését a OPENROWSET függvény használatával. Győződjön meg arról, hogy az Azure Cosmos DB-tároló rendelkezik elemzési tárhellyel. Győződjön meg arról, hogy helyesen adta meg a fiók, az adatbázis és a tároló nevét. Győződjön meg arról is, hogy az Azure Cosmos DB-fiókkulcsa érvényes. További információkat az Előfeltételek között talál.
Nem lehet lekérdezni az Azure Cosmos DB-t az OPENROW Standard kiadás T függvény használatával
Ha nem tud csatlakozni az Azure Cosmos DB-fiókjához, tekintse meg az előfeltételeket. A lehetséges hibák és hibaelhárítási műveletek az alábbi táblázatban találhatók.
| Hiba | Gyökérok |
|---|---|
| Szintaxishibák: - Helytelen szintaxis a közelben OPENROWSET.- ... nem egy felismert BULK OPENROWSET szolgáltatói lehetőség.- Helytelen szintaxis a közelben .... |
Lehetséges kiváltó okok: - Nem az Azure Cosmos DB-t használja első paraméterként. – Sztringkonstans használata azonosító helyett a harmadik paraméterben. - Nem adja meg a harmadik paramétert (tároló neve). |
| Hiba történt az Azure Cosmos DB kapcsolati sztring. | - Nincs megadva a fiók, az adatbázis vagy a kulcs. - A kapcsolati sztring egyik lehetősége nem ismerhető fel. - A pontosvesszőt ( ;) egy kapcsolati sztring végén helyezik el. |
| Az Azure Cosmos DB elérési útjának feloldása "Helytelen fióknév" vagy "Helytelen adatbázisnév" hibával meghiúsult. | A megadott fióknév, adatbázisnév vagy tároló nem található, vagy az elemzési tár nincs engedélyezve a megadott gyűjteményben. |
| Az Azure Cosmos DB elérési útjának feloldása "Helytelen titkos kódérték" vagy "A titkos kód null értékű vagy üres" hibával meghiúsult. | A fiókkulcs érvénytelen vagy hiányzik. |
UTF-8 rendezési figyelmeztetés jelenik meg Azure Cosmos DB-sztringtípusok olvasásakor
A kiszolgáló nélküli SQL-készlet fordítási időt jelző figyelmeztetést ad vissza, ha az OPENROWSET oszlopeloszlás nem rendelkezik UTF-8 kódolással. A T-SQL utasítással egyszerűen módosíthatja az alapértelmezett rendezést az aktuális adatbázisban futó összes OPENROWSET függvény esetében:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
A Latin1_General_100_BIN2_UTF8 rendezés nyújtja a legjobb teljesítményt, amikor sztringpredikátumokkal szűri az adatokat.
Hiányzó sorok az Azure Cosmos DB elemzési tárában
Előfordulhat, hogy az Azure Cosmos DB egyes elemeit a OPENROWSET függvény nem adja vissza. Vegye figyelembe, hogy:
- Szinkronizálási késés van a tranzakciós és az elemzési tár között. Az Azure Cosmos DB tranzakciós tárolójában megadott dokumentum két-három perc után megjelenhet az elemzési tárban.
- A dokumentum megsérthet néhány sémakorlátozást.
A lekérdezés null értékeket ad vissza egyes Azure Cosmos DB-elemekben
Az Azure Synapse SQL a tranzakciós tárban látható értékek helyett NULL értéket ad vissza a következő esetekben:
- Szinkronizálási késés van a tranzakciós és az elemzési tár között. Az Azure Cosmos DB tranzakciós tárolóban megadott érték két-három perc után megjelenhet az elemzési tárban.
- Előfordulhat, hogy a WITH záradék nem megfelelő oszlopnevet vagy elérési utat tartalmaz. A WITH záradék oszlopnevének (vagy az oszloptípus utáni elérési út kifejezésének) meg kell egyeznie az Azure Cosmos DB-gyűjtemény tulajdonságneveivel. Az összehasonlítás megkülönbözteti a kis- és nagybetűk megkülönböztetettségét. Például,
productCodeésProductCodekülönböző tulajdonságok. Győződjön meg arról, hogy az oszlopnevek pontosan egyeznek az Azure Cosmos DB tulajdonságnevekkel. - Előfordulhat, hogy a tulajdonság nem helyezhető át az elemzési tárba, mert megsért bizonyos sémakorlátozásokat, például több mint 1000 tulajdonságot vagy több mint 127 beágyazási szintet.
- Ha jól definiált sémaábrázolást használ, előfordulhat, hogy a tranzakciós tárban lévő érték nem megfelelő típusú. A jól definiált séma a dokumentumok mintavételezésével zárolja az egyes tulajdonságok típusait. A tranzakciós tárolóban hozzáadott, a típusnak nem megfelelő érték helytelen értékként lesz kezelve, és nem migrálódik az elemzési tárolóba.
- Ha teljes körű sémaábrázolást használ, győződjön meg arról, hogy a típus utótagot a tulajdonság neve után adja hozzá, például
$.price.int64. Ha nem látja a hivatkozott elérési út értékét, lehet, hogy egy másik típusú elérési út tárolja, például$.price.float64. További információ: Azure Cosmos DB-gyűjtemények lekérdezése a teljes hűség sémában.
Az oszlop nem kompatibilis a külső adattípussal
A hiba Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. akkor jelenik meg, ha a WITH záradékban megadott oszloptípus nem egyezik az Azure Cosmos DB-tároló típusával. Próbálja meg módosítani az oszloptípust az Azure Cosmos DB szakaszban leírtak szerint SQL-típusleképezésekre , vagy használja a VARCHAR típust.
Megoldás: Az Azure Cosmos DB elérési útja hiba miatt meghiúsult
Ha a hibaellenőrzés Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. során kiderül, hogy privát végpontokat használt-e az Azure Cosmos DB-ben. Ahhoz, hogy a kiszolgáló nélküli SQL-készlet hozzáférjen egy privát végpontokkal rendelkező elemzési tárhoz, magánvégpontokat kell konfigurálnia az Azure Cosmos DB elemzési tárhoz.
Az Azure Cosmos DB teljesítményproblémái
Ha váratlan teljesítményproblémákat tapasztal, győződjön meg arról, hogy ajánlott eljárásokat alkalmazott, például:
- Győződjön meg arról, hogy az ügyfélalkalmazást, a kiszolgáló nélküli készletet és az Azure Cosmos DB elemzési tárat ugyanabban a régióban helyezte el.
- Győződjön meg arról, hogy a WITH záradékot optimális adattípusokkal használja.
- Ügyeljen arra, hogy Latin1_General_100_BIN2_UTF8 rendezést használjon, amikor sztring predikátumok használatával szűri az adatokat.
- Ha ismétlődő lekérdezések vannak gyorsítótárazva, próbálja meg a CETAS használatával tárolni a lekérdezési eredményeket az Azure Data Lake Storage-ban.
Delta Lake
A Delta Lake-támogatásban bizonyos korlátozások a kiszolgáló nélküli SQL-készletekben is megjelenhetnek:
- Győződjön meg arról, hogy az OPENROW Standard kiadás T függvényben vagy külső táblahelyen a Delta Lake gyökérmappára hivatkozik.
- A gyökérmappának rendelkeznie kell egy almappával.
_delta_logA lekérdezés meghiúsul, ha nincs_delta_logmappa. Ha nem látja ezt a mappát, egyszerű Parquet-fájlokra hivatkozik, amelyeket Apache Spark-készletek használatával delta lake-re kell konvertálni. - Ne adjon meg helyettesítő karaktereket a partícióséma leírásához. A Delta Lake-lekérdezés automatikusan azonosítja a Delta Lake-partíciókat.
- A gyökérmappának rendelkeznie kell egy almappával.
- Az Apache Spark-készletekben létrehozott Delta Lake-táblák automatikusan elérhetők a kiszolgáló nélküli SQL-készletben, de a séma nem frissül (nyilvános előzetes verzióra vonatkozó korlátozás). Ha Spark-készlet használatával ad hozzá oszlopokat a Delta táblához, a módosítások nem jelennek meg a kiszolgáló nélküli SQL-készlet adatbázisában.
- A külső táblák nem támogatják a particionálást. Használjon particionált nézeteket a Delta Lake mappában a partíció eltávolításának használatához. Az ismert problémákat és kerülő megoldásokat a cikk későbbi részében találja.
- A kiszolgáló nélküli SQL-készletek nem támogatják az időutazási lekérdezéseket. Apache Spark-készletek használata a Synapse Analyticsben az előzményadatok olvasásához.
- A kiszolgáló nélküli SQL-készletek nem támogatják a Delta Lake-fájlok frissítését. Kiszolgáló nélküli SQL-készlet használatával lekérdezheti a Delta Lake legújabb verzióját. Apache Spark-készletek használata a Synapse Analyticsben a Delta Lake frissítéséhez.
- A lekérdezési eredményeket nem tárolhatja Delta Lake formátumban a CETAS paranccsal. A CETAS-parancs csak a Parquet és a CSV formátumot támogatja kimeneti formátumként.
- A Synapse Analytics kiszolgáló nélküli SQL-készletei kompatibilisek az 1- es verziójú Delta-olvasóval. A kiszolgáló nélküli SQL-készletek nem támogatják azokat a Delta-funkciókat, amelyekhez a 2. vagy újabb verziójú Delta-olvasók szükségesek (például oszlopleképezés).
- A Synapse Analytics kiszolgáló nélküli SQL-készletei nem támogatják az adathalmazokat a BLOOM szűrővel. A kiszolgáló nélküli SQL-készlet figyelmen kívül hagyja a BLOOM-szűrőket.
- A Delta Lake-támogatás dedikált SQL-készletekben nem érhető el. Győződjön meg arról, hogy kiszolgáló nélküli SQL-készleteket használ a Delta Lake-fájlok lekérdezéséhez.
- A kiszolgáló nélküli SQL-készletekkel kapcsolatos ismert problémákról az Azure Synapse Analytics ismert problémáiról olvashat bővebben.
Az oszlop átnevezése a Delta táblában nem támogatott
A kiszolgáló nélküli SQL-készlet nem támogatja a Delta Lake-táblák átnevezett oszlopokkal való lekérdezését. A kiszolgáló nélküli SQL-készlet nem tud adatokat olvasni az átnevezett oszlopból.
A Delta tábla egyik oszlopának értéke NULL
Ha Olyan Delta-adatkészletet használ, amelyhez a Delta-olvasó 2-es vagy újabb verziója szükséges, és az 1. verzióban nem támogatott funkciókat használja (például : oszlopok átnevezése, oszlopok elvetése vagy oszlopleképezés), előfordulhat, hogy a hivatkozott oszlopok értékei nem jelennek meg.
A JSON-szöveg nincs megfelelően formázva
Ez a hiba azt jelzi, hogy a kiszolgáló nélküli SQL-készlet nem tudja beolvasni a Delta Lake tranzakciónaplóját. Valószínűleg a következő hibaüzenet jelenik meg:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Győződjön meg arról, hogy a Delta Lake-adatkészlet nem sérült. Ellenőrizze, hogy olvasható-e a Delta Lake mappa tartalma az Apache Spark-készlet használatával az Azure Synapse-ban. Így meggyőződhet arról, hogy a _delta_log fájl nem sérült.
Áthidaló megoldás
Próbáljon meg létrehozni egy ellenőrzőpontot a Delta Lake-adathalmazon az Apache Spark-készlet használatával, és futtassa újra a lekérdezést. Az ellenőrzőpont összesíti a tranzakciós JSON-naplófájlokat, és megoldhatja a problémát.
Ha az adathalmaz érvényes, hozzon létre egy támogatási jegyet, és adjon meg további információkat:
- Ne végezze el a módosításokat, például az oszlopok hozzáadását vagy eltávolítását vagy a tábla optimalizálását, mert ez a művelet megváltoztathatja a Delta Lake tranzakció naplófájljainak állapotát.
- Másolja a mappa tartalmát
_delta_logegy új üres mappába. Ne másolja a.parquet datafájlokat. - Próbálja meg elolvasni az új mappába másolt tartalmat, és ellenőrizze, hogy ugyanazt a hibát kapja-e.
- Küldje el a másolt
_delta_logfájl tartalmát a Azure-támogatás.
Most már használhatja a Delta Lake mappát a Spark-készlettel. A másolt adatokat a Microsoft ügyfélszolgálatának kell megadnia, ha megoszthatja ezeket az információkat. Az Azure csapata megvizsgálja a fájl tartalmát, és további információkat nyújt a delta_log lehetséges hibákról és kerülő megoldásokról.
Sikertelen deltanaplók feloldása
A következő hiba azt jelzi, hogy a kiszolgáló nélküli SQL-készlet nem tudja feloldani a Delta-naplókat: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. A leggyakoribb ok az, hogy last_checkpoint_file a mappában _delta_log 200 bájtnál nagyobb a Spark 3.3-ban hozzáadott mező miatt.checkpointSchema
A hiba megkerülésére két lehetőség áll rendelkezésre:
- Módosítsa a megfelelő konfigurációt a Spark-jegyzetfüzetben, és hozzon létre egy új ellenőrzőpontot, hogy
last_checkpoint_fileaz újra létrejönjön. Az Azure Databricks használata esetén a konfiguráció módosítása a következő:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Visszalépés a Spark 3.2.1-hez.
Mérnöki csapatunk jelenleg a Spark 3.3 teljes körű támogatásán dolgozik.
A Sparkban létrehozott Delta-tábla nem jelenik meg a kiszolgáló nélküli készletben
Feljegyzés
A Sparkban létrehozott Delta-táblák replikálása továbbra is nyilvános előzetes verzióban érhető el.
Ha deltatáblát hozott létre a Sparkban, és az nem jelenik meg a kiszolgáló nélküli SQL-készletben, ellenőrizze a következőket:
- Várjon egy kis időt (általában 30 másodpercet), mert a Spark-táblák késéssel vannak szinkronizálva.
- Ha a tábla egy idő után nem jelent meg a kiszolgáló nélküli SQL-készletben, ellenőrizze a Spark Delta-tábla sémáját. Az összetett vagy kiszolgáló nélküli típusok nem támogatott Spark-táblák nem érhetők el. Próbáljon meg létrehozni egy Spark Parquet-táblát ugyanazzal a sémával egy tóadatbázisban, és ellenőrizze, hogy a tábla megjelenik-e a kiszolgáló nélküli SQL-készletben.
- Ellenőrizze a tábla által hivatkozott Delta Lake-mappát a munkaterület felügyelt identitáshoz való hozzáférésében. A kiszolgáló nélküli SQL-készlet a munkaterület felügyelt identitásával szerzi be a tábla oszlopadatait a tárolóból a tábla létrehozásához.
Tóadatbázis
A Spark vagy a Synapse designer használatával létrehozott Lake-adatbázistáblák automatikusan elérhetők a kiszolgáló nélküli SQL-készletben a lekérdezéshez. Kiszolgáló nélküli SQL-készlet használatával lekérdezheti a Spark-készletben létrehozott Parquet-, CSV- és Delta Lake-táblákat, és további sémákat, nézeteket, eljárásokat, táblaértékfüggvényeket és Microsoft Entra-felhasználókat db_datareader adhat hozzá a Lake-adatbázishoz. A lehetséges problémákat ebben a szakaszban találja.
A Sparkban létrehozott tábla nem érhető el kiszolgáló nélküli készletben
Előfordulhat, hogy a létrehozott táblák nem lesznek azonnal elérhetők a kiszolgáló nélküli SQL-készletben.
- A táblák némi késéssel elérhetők lesznek a kiszolgáló nélküli készletekben. Előfordulhat, hogy 5–10 percet kell várnia a Tábla létrehozása után a Sparkban, hogy megjelenjen a kiszolgáló nélküli SQL-készletben.
- Kiszolgáló nélküli SQL-készletben csak a Parquet, CSV és Delta formátumra hivatkozó táblák érhetők el. Más táblázattípusok nem érhetők el.
- A kiszolgáló nélküli SQL-készletben nem lesz elérhető néhány nem támogatott oszloptípust tartalmazó tábla.
- A Delta Lake-táblák elérése a Lake-adatbázisokban nyilvános előzetes verzióban érhető el. Ellenőrizze az ebben a szakaszban vagy a Delta Lake szakaszban felsorolt egyéb problémákat.
A Sparkban létrehozott külső tábla váratlan eredményeket jelenít meg a kiszolgáló nélküli készletben
Előfordulhat, hogy a forrás Spark külső tábla és a kiszolgáló nélküli készlet replikált külső táblája nem egyezik. Ez akkor fordulhat elő, ha a Spark külső táblák létrehozásához használt fájlok bővítmények nélkül vannak. A megfelelő eredmények eléréséhez győződjön meg arról, hogy minden fájl olyan kiterjesztéssel van elemmel, mint a .parquet.
Replikált adatbázis esetén a művelet nem engedélyezett
Ez a hiba akkor jelenik meg, ha egy Lake-adatbázist próbál módosítani, külső táblákat, külső adatforrásokat, adatbázis-hatókörű hitelesítő adatokat vagy más objektumokat próbál létrehozni a Lake-adatbázisban. Ezek az objektumok csak SQL-adatbázisokon hozhatók létre.
A Lake-adatbázisok replikálva vannak az Apache Spark-készletből, és az Apache Spark felügyeli. Ezért T-SQL-nyelv használatával nem hozhat létre objektumokat, például az SQL Database-ben.
A Lake-adatbázisokban csak a következő műveletek engedélyezettek:
- Nézetek, eljárások és beágyazott táblaértékfüggvények (iTVF) létrehozása, elvetése vagy módosítása a sémákban
dbo. - Adatbázis-felhasználók létrehozása és elvetése a Microsoft Entra-azonosítóból.
- Adatbázis-felhasználók hozzáadása vagy eltávolítása a sémából
db_datareader.
Más műveletek nem engedélyezettek a Lake-adatbázisokban.
Feljegyzés
Ha sémában dbo hoz létre nézetet, eljárást vagy függvényt (vagy kihagyja a sémát, és az alapértelmezettet használja), a hibaüzenet jelenik dbomeg.
A Lake-adatbázisok deltatáblái nem érhetők el a kiszolgáló nélküli SQL-készletben
Győződjön meg arról, hogy a munkaterület felügyelt identitása olvasási hozzáféréssel rendelkezik a Delta mappát tartalmazó ADLS-tárolóban. A kiszolgáló nélküli SQL-készlet beolvassa a Delta Lake-tábla sémáját az ADLS-ben elhelyezett Delta-naplókból, és a munkaterület felügyelt identitásával éri el a Delta tranzakciónaplóit.
Próbáljon meg olyan adatforrást beállítani egy SQL Database-ben, amely az Azure Data Lake Storage-ra hivatkozik a Felügyelt identitás hitelesítő adataival, és próbáljon meg külső táblát létrehozni a felügyelt identitással rendelkező adatforrás tetején annak ellenőrzéséhez, hogy a felügyelt identitással rendelkező táblák hozzáférnek-e a tárolóhoz.
A Lake-adatbázisok deltatáblái nem rendelkeznek azonos sémával a Sparkban és a kiszolgáló nélküli készletekben
A kiszolgáló nélküli SQL-készletek lehetővé teszik a Lake-adatbázisban a Spark vagy a Synapse designer használatával létrehozott Parquet-, CSV- és Delta-táblák elérését. A Delta-táblák elérése továbbra is nyilvános előzetes verzióban érhető el, és jelenleg kiszolgáló nélküli verzióban szinkronizál egy Delta-táblát a Sparkkal a létrehozáskor, de nem frissíti a sémát, ha az oszlopokat később hozzáadja a ALTER TABLE Spark utasításával.
Ez egy nyilvános előzetes verziós korlátozás. A probléma megoldásához a táblák módosítása helyett helyezze el és hozza létre újra a Delta-táblát a Sparkban (ha lehetséges).
Teljesítmény
A kiszolgáló nélküli SQL-készlet az adathalmaz mérete és a lekérdezések összetettsége alapján rendeli hozzá az erőforrásokat a lekérdezésekhez. A lekérdezésekhez biztosított erőforrások nem módosíthatók és nem korlátozhatók. Vannak olyan esetek, amikor váratlan lekérdezési teljesítménycsökkenést tapasztalhat, és előfordulhat, hogy azonosítania kell a kiváltó okokat.
A lekérdezés időtartama nagyon hosszú
Ha 30 percnél hosszabb lekérdezési időtartamú lekérdezései vannak, a lekérdezés lassan visszaadja az eredményeket az ügyfélnek. A kiszolgáló nélküli SQL-készlet 30 perces végrehajtási korlátot biztosít. Az eredménystreamelés további időt tölt. Próbálkozzon a következő áthidaló megoldásokkal:
- Ha a Synapse Studiót használja, próbálja meg reprodukálni a problémákat más alkalmazásokkal, például az SQL Server Management Studióval vagy az Azure Data Studióval.
- Ha a lekérdezés lassú az SQL Server Management Studio, az Azure Data Studio, a Power BI vagy más alkalmazás használatával történő végrehajtáskor, ellenőrizze a hálózati problémákat és az ajánlott eljárásokat.
- Helyezze a lekérdezést a CETAS parancsba, és mérje meg a lekérdezés időtartamát. A CETAS-parancs tárolja az eredményeket az Azure Data Lake Storage-ban, és nem függ az ügyfélkapcsolattól. Ha a CETAS-parancs gyorsabban fejeződik be, mint az eredeti lekérdezés, ellenőrizze az ügyfél és a kiszolgáló nélküli SQL-készlet közötti hálózati sávszélességet.
A lekérdezés lassú, ha a Synapse Studióval hajtják végre
Ha a Synapse Studiót használja, próbáljon meg asztali ügyfelet használni, például az SQL Server Management Studiót vagy az Azure Data Studiót. A Synapse Studio egy webügyfél, amely a HTTP protokoll használatával csatlakozik a kiszolgáló nélküli SQL-készlethez, ami általában lassabb, mint az SQL Server Management Studióban vagy az Azure Data Studióban használt natív SQL-kapcsolatok.
A lekérdezés lassú, ha egy alkalmazás használatával hajtják végre
Ellenőrizze a következő problémákat, ha lassú lekérdezés-végrehajtást tapasztal:
- Győződjön meg arról, hogy az ügyfélalkalmazások a kiszolgáló nélküli SQL-készlet végpontjával vannak csoportosítva. A lekérdezés végrehajtása a régióban további késést és az eredményhalmaz lassú streamelését okozhatja.
- Győződjön meg arról, hogy nincsenek olyan hálózati problémák, amelyek okozhatják az eredményhalmaz lassú streamelását
- Győződjön meg arról, hogy az ügyfélalkalmazás rendelkezik elegendő erőforrással (például nem használ 100%-os processzorhasználatot).
- Győződjön meg arról, hogy a tárfiók vagy az Azure Cosmos DB elemzési tárterülete ugyanabban a régióban van, mint a kiszolgáló nélküli SQL-végpont.
Tekintse meg az erőforrások elosztásának ajánlott eljárásait.
Nagy eltérések a lekérdezések időtartamában
Ha ugyanazt a lekérdezést hajtja végre, és megfigyeli a lekérdezés időtartamának változásait, ennek több oka is lehet:
- Ellenőrizze, hogy ez-e a lekérdezés első végrehajtása. A lekérdezés első végrehajtása összegyűjti a terv létrehozásához szükséges statisztikákat. A statisztikákat a rendszer a mögöttes fájlok vizsgálatával gyűjti össze, és növelheti a lekérdezés időtartamát. A Synapse Studióban a lekérdezés előtt végrehajtott SQL-kérelmek listájában megjelennek a "globális statisztikák létrehozása" lekérdezések.
- A statisztikák egy idő után lejárhatnak. Időnként előfordulhat, hogy hatással van a teljesítményre, mert a kiszolgáló nélküli készletnek át kell vizsgálnia és újra kell építenie a statisztikákat. Előfordulhat, hogy a lekérdezés előtt végrehajtott SQL-kérelmek listájában egy másik "globális statisztika létrehozása" lekérdezés jelenik meg.
- Ellenőrizze, hogy van-e olyan számítási feladat, amely ugyanazon a végponton fut a lekérdezés hosszabb időtartamú végrehajtásakor. A kiszolgáló nélküli SQL-végpont egyenlően lefoglalja az erőforrásokat a párhuzamosan végrehajtott összes lekérdezéshez, és a lekérdezés késhet.
Kapcsolatok
A kiszolgáló nélküli SQL-készlet lehetővé teszi a csatlakozást a TDS protokoll és a T-SQL nyelv használatával az adatok lekérdezéséhez. Az SQL Serverhez vagy az Azure SQL Database-hez csatlakozni képes eszközök többsége kiszolgáló nélküli SQL-készlethez is csatlakozhat.
Az SQL-készlet bemelegedik
Hosszabb inaktivitás után a kiszolgáló nélküli SQL-készlet inaktiválódik. Az aktiválás automatikusan megtörténik az első következő tevékenységen, például az első kapcsolati kísérleten. Az aktiválási folyamat tovább is tarthat, mint a csatlakozási kísérletek időköze, ami a hibaüzenet megjelenítését okozhatja. A kapcsolati kísérlet újrapróbálkozásának elegendőnek kell lennie.
Ajánlott eljárásként az azt támogató ügyfelek számára használja a Csatlakozás ionRetryCount és Csatlakozás RetryInterval kapcsolati sztring kulcsszavakat az újracsatlakozás viselkedésének szabályozásához.
Ha a hibaüzenet továbbra is fennáll, küldjön támogatási jegyet az Azure Portalon.
Nem lehet csatlakozni a Synapse Studióból
Lásd a Synapse Studio szakaszt.
Nem lehet csatlakozni az Azure Synapse-készlethez egy eszközről
Előfordulhat, hogy egyes eszközök nem rendelkeznek explicit beállítással, amellyel csatlakozhat az Azure Synapse kiszolgáló nélküli SQL-készletéhez. Az SQL Serverhez vagy az SQL Database-hez való csatlakozáshoz használjon egy lehetőséget. A kapcsolati párbeszédpanelt nem kell "Synapse" néven használni, mert a kiszolgáló nélküli SQL-készlet ugyanazt a protokollt használja, mint az SQL Server vagy az SQL Database.
Még akkor is, ha egy eszköz lehetővé teszi, hogy csak egy logikai kiszolgálónevet adjon meg, és előre definiálja a database.windows.net tartományt, tegye az Azure Synapse-munkaterület nevét, majd az -ondemand utótagot és a tartományt database.windows.net .
Biztonság
Győződjön meg arról, hogy a felhasználó rendelkezik az adatbázisok elérésére, a parancsok végrehajtására és az Azure Data Lake vagy az Azure Cosmos DB Storage elérésére vonatkozó engedélyekkel.
Nem érhető el az Azure Cosmos DB-fiók
Az elemzési tár eléréséhez írásvédett Azure Cosmos DB-kulcsot kell használnia, ezért győződjön meg arról, hogy az nem járt le, vagy nem jött létre újra.
Ha a következő hibaüzenet jelenik meg: "Az Azure Cosmos DB elérési útjának feloldása hiba miatt meghiúsult", győződjön meg arról, hogy tűzfalat konfigurált.
Nem érhető el a Lakehouse vagy a Spark-adatbázis
Ha egy felhasználó nem fér hozzá egy lakehouse- vagy Spark-adatbázishoz, előfordulhat, hogy a felhasználónak nincs engedélye az adatbázis elérésére és olvasására. A CONTROL Standard kiadás RVER engedéllyel rendelkező felhasználóknak teljes hozzáféréssel kell rendelkezniük az összes adatbázishoz. Korlátozott engedélyként megpróbálhatja használni a CONNECT ANY DATABA Standard kiadás és Standard kiadás LECT ALL U Standard kiadás R Standard kiadás CURABLES parancsot.
Az SQL-felhasználó nem fér hozzá a Dataverse-táblákhoz
A dataverse-táblák a hívó Microsoft Entra-identitásával férnek hozzá a tárolóhoz. A magas engedélyekkel rendelkező SQL-felhasználók megpróbálhatnak adatokat kiválasztani egy táblából, de a tábla nem férne hozzá a Dataverse-adatokhoz. Ez a forgatókönyv nem támogatott.
A Microsoft Entra szolgáltatásnév bejelentkezési hibái, amikor a SPI létrehoz egy szerepkör-hozzárendelést
Ha egy szolgáltatásnév-azonosítóhoz (SPI) vagy Microsoft Entra-alkalmazáshoz szeretne szerepkör-hozzárendelést létrehozni egy másik SPI használatával, vagy már létrehozott egyet, és nem tud bejelentkezni, valószínűleg a következő hibaüzenet jelenik meg: Login error: Login failed for user '<token-identified principal>'.
Alkalmazáspéldányok esetében a bejelentkezést biztonsági azonosítóként (SID), nem pedig objektumazonosítóként használt alkalmazásazonosítóval kell létrehozni. Az alkalmazáspéldányok egyik ismert korlátozása miatt az Azure Synapse nem tudja lekérni az alkalmazásazonosítót Microsoft Graphból, amikor az SPI egy másik SPI vagy alkalmazás számára hoz létre szerepkör-hozzárendelést.
1\. megoldás
Nyissa meg az Azure Portal>Synapse Studio>>Hozzáférés-vezérlését, és adja hozzá manuálisan a Synapse Rendszergazda istratort vagy a Synapse SQL Rendszergazda istratort a kívánt szolgáltatásnévhez.
2\. megoldás
Manuálisan kell létrehoznia egy megfelelő bejelentkezést AZ SQL-kóddal:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
3. megoldás
A PowerShell használatával szolgáltatásnév azure synapse-rendszergazdát is beállíthat. Telepítve kell lennie az Az.Synapse modulnak .
A megoldás a parancsmag New-AzSynapseRoleAssignment használata a következővel -ObjectId "parameter": . Ebben a paramétermezőben adja meg az alkalmazásazonosítót az objektumazonosító helyett a munkaterület-rendszergazda Azure-szolgáltatásnév hitelesítő adataival.
PowerShell-szkript:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Érvényesítés
Csatlakozás a kiszolgáló nélküli SQL-végpontra, és ellenőrizze, hogy létrejön-e a külső bejelentkezés a SID-vel (app_id_to_add_as_adminaz előző mintában):
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Vagy próbáljon meg bejelentkezni a kiszolgáló nélküli SQL-végpontra a beállított rendszergazdai alkalmazással.
Megszorítások
Néhány általános rendszerkorlátozás hatással lehet a számítási feladatra:
| Tulajdonság | Korlátozás |
|---|---|
| Az Azure Synapse-munkaterületek maximális száma előfizetésenként | Lásd a korlátokat. |
| Az adatbázisok maximális száma kiszolgáló nélküli készletenként | 100 (nem tartalmazza az Apache Spark-készletből szinkronizált adatbázisokat). |
| Az Apache Spark-készletből szinkronizált adatbázisok maximális száma | Nincs korlátozva. |
| Adatbázis-objektumok maximális száma adatbázisonként | Az adatbázis összes objektumának összege nem haladhatja meg a 2 147 483 647-et. Lásd az SQL Server adatbázismotor korlátait. |
| Az azonosító maximális hossza karakterekben | 128. Lásd az SQL Server adatbázismotor korlátait. |
| A lekérdezés maximális időtartama | 30 perc. |
| Az eredményhalmaz maximális mérete | Akár 400 GB is megosztható az egyidejű lekérdezések között. |
| Maximális egyidejűség | Nem korlátozott, és a lekérdezés összetettségétől és a beolvasott adatok mennyiségétől függ. Egy kiszolgáló nélküli SQL-készlet egyszerre 1000 aktív munkamenetet képes kezelni, amelyek egyszerű lekérdezéseket hajtanak végre. A számok csökkennek, ha a lekérdezések összetettebbek, vagy nagyobb mennyiségű adatot vizsgálnak, ezért ebben az esetben fontolja meg az egyidejűség csökkentését, és ha lehetséges, hosszabb ideig futtassa a lekérdezéseket. |
| Külső tábla nevének maximális mérete | 100 karakter. |
Nem hozható létre adatbázis kiszolgáló nélküli SQL-készletben
A kiszolgáló nélküli SQL-készletek korlátozásokkal rendelkeznek, és munkaterületenként nem hozhat létre több mint 100 adatbázist. Ha el kell különítenie az objektumokat, és el kell különítenie őket, használjon sémákat.
Ha azt a hibát CREATE DATABASE failed. User database limit has been already reached kapja, hogy létrehozta az egy munkaterületen támogatott adatbázisok maximális számát.
Nem kell külön adatbázisokat használnia a különböző bérlők adatainak elkülönítéséhez. A rendszer minden adatot külsőleg tárol egy data lake-en és az Azure Cosmos DB-n. A metaadatok, például a táblák, nézetek és függvénydefiníciók sémák használatával sikeresen elkülöníthetők. A sémaalapú elkülönítést a Sparkban is használják, ahol az adatbázisok és sémák ugyanazok a fogalmak.
Következő lépések
- Az Azure Synapse Analytics kiszolgáló nélküli SQL-készleteihez ajánlott eljárások
- Az Azure Synapse Analytics gyakori kérdések
- Lekérdezési eredmények tárolása tárolóba kiszolgáló nélküli SQL-készlet használatával az Azure Synapse Analyticsben
- A Synapse Studio hibaelhárítása
- Lassú lekérdezés hibaelhárítása dedikált SQL-készleten