"Gyakorlat – Azure Data Factory-leképezési adatfolyam létrehozása"
Adatok átalakítása a leképezési Adatfolyam
A leképezési Adatfolyam feladattal natív módon végezhet adatátalakításokat ingyenes Azure Data Factory-kóddal. A leképezési Adatfolyam teljes vizuális élményt nyújtanak kódolás nélkül. Az adatfolyamok a saját végrehajtási fürtön fognak futni a kibővített adatfeldolgozás érdekében. Az adatfolyam-tevékenységek a Data Factory meglévő ütemezési, vezérlési, folyamat- és monitorozási képességeivel kezelhetők.
Adatfolyamok létrehozásakor engedélyezheti a hibakeresési módot, amely bekapcsol egy kis interaktív Spark-fürtöt. Kapcsolja be a hibakeresési módot a szerkesztőmodul tetején található csúszka összevonásával. A hibakeresési fürtök bemelegedése néhány percet vesz igénybe, de az átalakítási logika kimenetének interaktív megtekintéséhez használható.

A leképezési Adatfolyam hozzáadásával és a Spark-fürt futtatásával ez lehetővé teszi az átalakítás végrehajtását, valamint az adatok futtatását és előnézetét. Nincs szükség kódolásra, mivel az Azure Data Factory kezeli az adatfolyam-feladatok összes kódfordítását, útvonaloptimalizálását és végrehajtását.
Forrásadatok hozzáadása a leképezési Adatfolyam
Nyissa meg a leképezési Adatfolyam vászont. Kattintson a forrás hozzáadása gombra a Adatfolyam vásznon. A forrásadatkészlet legördülő listájában válassza ki az adatforrást, ebben az esetben az ADLS Gen2 adatkészletet használja ebben a példában
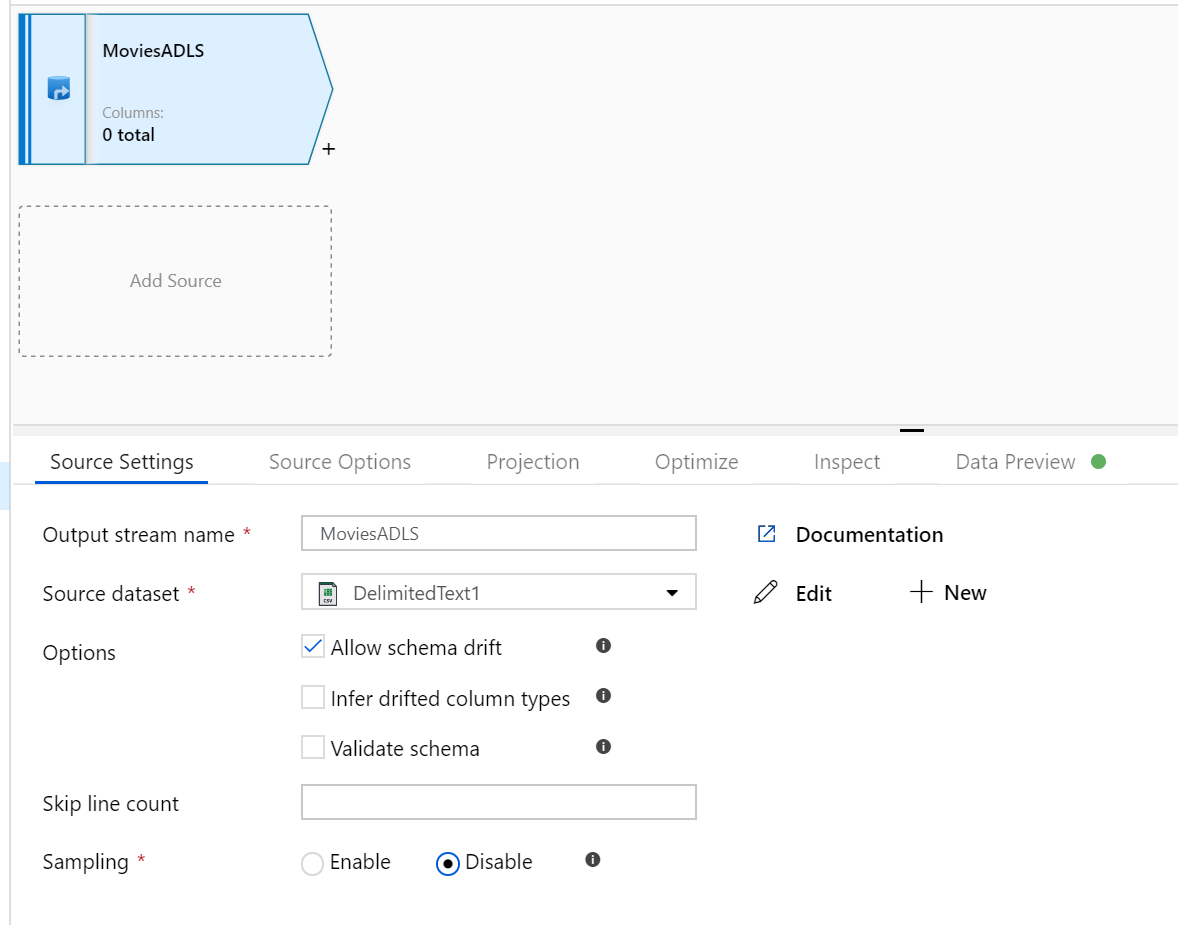
Néhány szempontot érdemes megjegyezni:
- Ha az adatkészlet egy más fájlokat tartalmazó mappára mutat, és csak egy fájlt szeretne használni, előfordulhat, hogy létre kell hoznia egy másik adatkészletet, vagy paraméterezést kell használnia, hogy csak egy adott fájl legyen olvasható
- Ha még nem importálta a sémát az ADLS-ben, de már betöltötte az adatokat, lépjen az adathalmaz Séma lapjára, és kattintson a Séma importálása gombra, hogy az adatfolyam megismerje a sémavetítést.
A leképezési Adatfolyam egy kinyerési, betöltési, átalakítási (ELT) megközelítést követ, és olyan átmeneti adatkészletekkel dolgozik, amelyek mindegyike az Azure-ban található. Jelenleg a következő adathalmazok használhatók forrásátalakításkor:
- Azure Blob Storage (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen1 (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen2 (JSON, Avro, Text, Parquet)
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Az Azure Data Factory több mint 80 natív összekötőhöz rendelkezik hozzáféréssel. Ha más forrásokból származó adatokat szeretne belefoglalni az adatfolyamba, a Másolási tevékenység használatával töltse be az adatokat az egyik támogatott átmeneti területre.
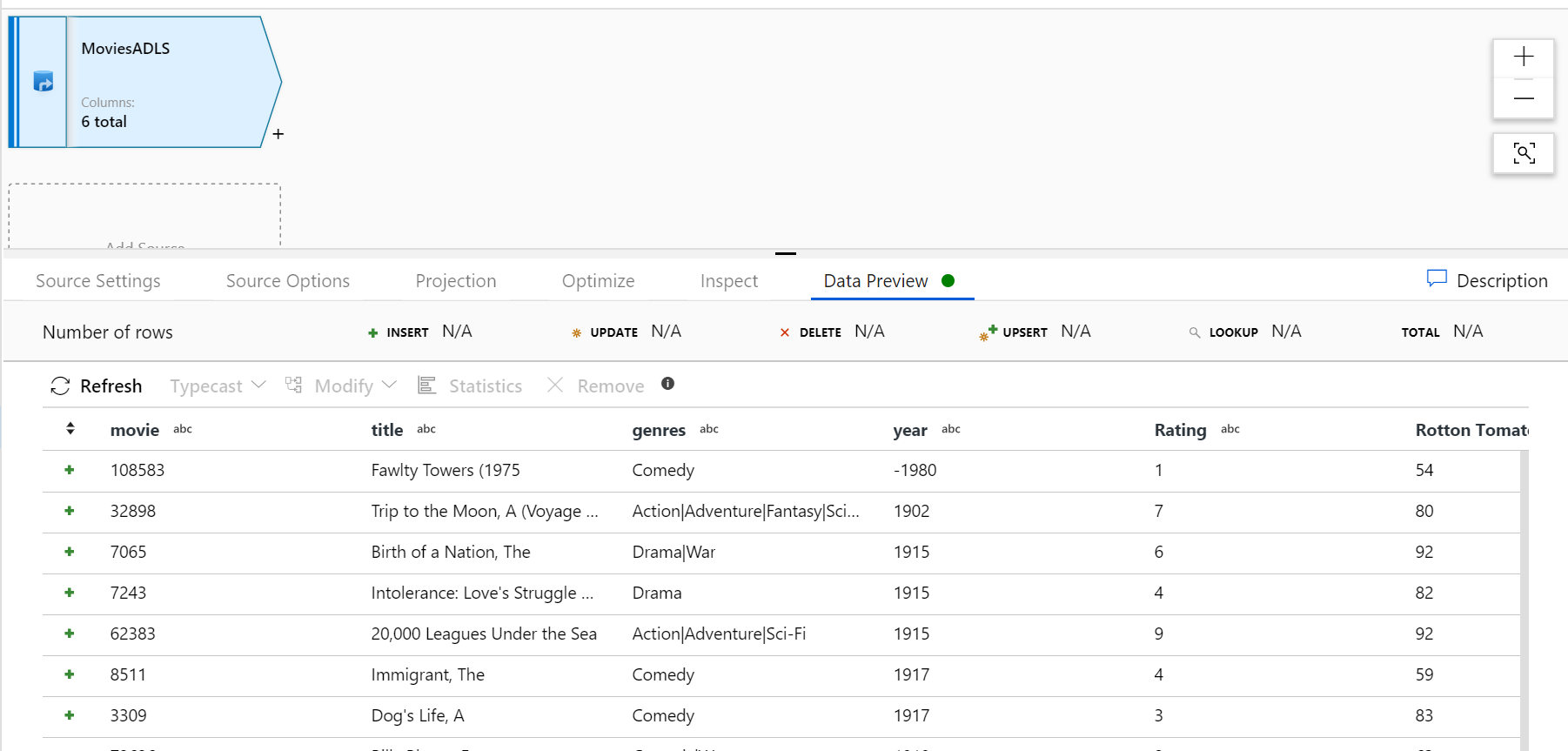
A hibakeresési fürt bemelegítését követően ellenőrizze, hogy az adatok megfelelően vannak-e betöltve az Adatok előnézete lapon. Miután a frissítés gombra kattint, a leképezési Adatfolyam egy pillanatképet jelenít meg arról, hogy az adatok hogyan néznek ki az egyes átalakítások során.
Átalakítások használata a leképezési Adatfolyam
Most, hogy áthelyezte az adatokat az Azure Data Lake Store Gen2-be, készen áll egy leképezési Adatfolyam létrehozására, amely nagy léptékben átalakítja az adatokat egy spark-fürtön keresztül, majd betölti őket egy adattárházba.
Ennek fő feladatai a következők:
A környezet előkészítése
Adatforrás hozzáadása
Leképezési Adatfolyam transzformáció használata
Írás adatgyűjtőbe
1. feladat: A környezet előkészítése
Kapcsolja be a Adatfolyam Hibakeresés funkciót Kapcsolja be a szerzői modul tetején található Adatfolyam Hibakeresés csúszkát.
Megjegyzés:
Adatfolyam fürtök bemelegedéséhez 5-7 perc kell.
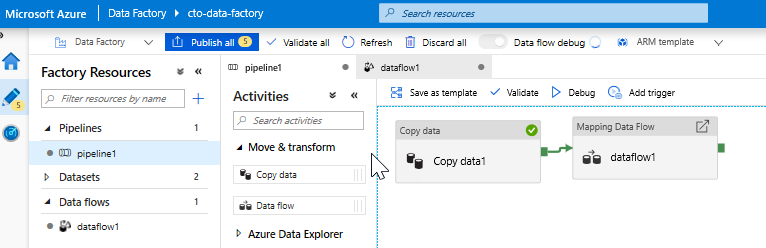
Adjon hozzá egy Adatfolyam tevékenységet. A Tevékenységek panelen nyissa meg az Áthelyezés és átalakítás harmonikát, és húzza a Adatfolyam tevékenységet a folyamatvászonra. Az előugró panelen kattintson az Új Adatfolyam létrehozása elemre, és válassza a Leképezési Adatfolyam lehetőséget, majd kattintson az OK gombra. Kattintson a folyamat1 fülre, és húzza a zöld mezőt a Copy tevékenység a Adatfolyam tevékenységre a sikeres állapot létrehozásához. A vásznon a következők láthatók:
2. feladat: Adatforrás hozzáadása
ADLS-forrás hozzáadása. Kattintson duplán a leképezési Adatfolyam objektumra a vásznon. Kattintson a forrás hozzáadása gombra a Adatfolyam vásznon. A Forrásadatkészlet legördülő listában válassza ki a Copy tevékenység
- Ha az adatkészlet más fájlokat tartalmazó mappára mutat, előfordulhat, hogy létre kell hoznia egy másik adatkészletet, vagy paraméterezést kell használnia, hogy csak a moviesDB.csv fájl legyen olvasható
- Ha még nem importálta a sémát az ADLS-ben, de már betöltötte az adatokat, lépjen az adathalmaz Séma lapjára, és kattintson a Séma importálása gombra, hogy az adatfolyam megismerje a sémavetítést.
A hibakeresési fürt bemelegítését követően ellenőrizze, hogy az adatok megfelelően vannak-e betöltve az Adatok előnézete lapon. Miután a frissítés gombra kattint, a leképezési Adatfolyam egy pillanatképet jelenít meg arról, hogy az adatok hogyan néznek ki az egyes átalakítások során.
3. feladat: Leképezési Adatfolyam átalakítás használata
Válasszon átalakítást az oszlopok átnevezéséhez és elvetéséhez. Az adatok előnézetében észrevehette, hogy a "Rotton Tomatoes" oszlop hibás. Ha helyesen szeretné elnevezni és elvetni a nem használt Minősítés oszlopot, hozzáadhat egy Kijelölés átalakítást az ADLS-forráscsomópont melletti + ikonra kattintva, majd válassza a Kiválasztás lehetőséget a Sémamódosító területen.
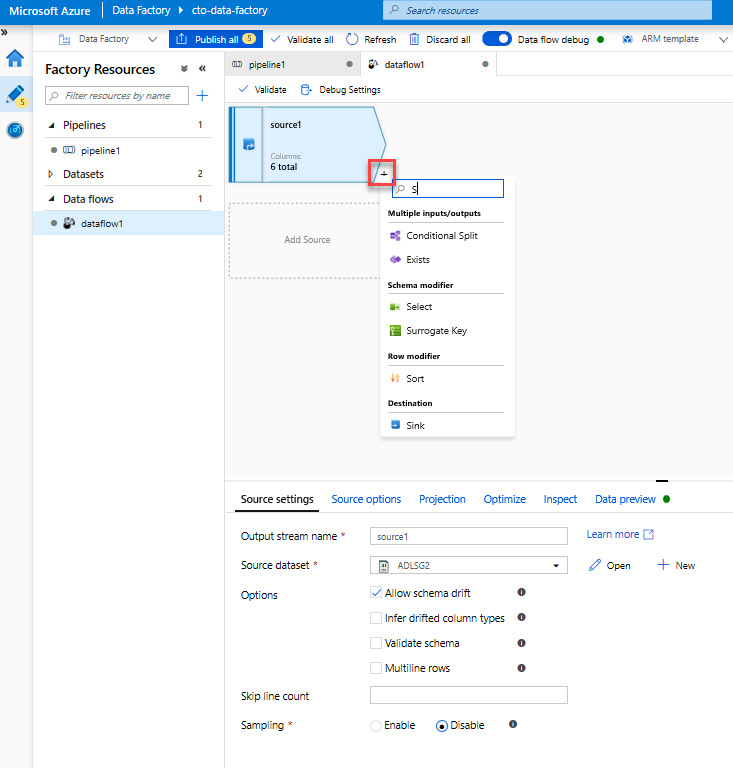
A Név mint mezőben módosítsa a "Rotton" értékét "Rotten" (Rotten) névre. Az Értékelés oszlop elvetéséhez mutasson rá, és kattintson a kuka ikonra.
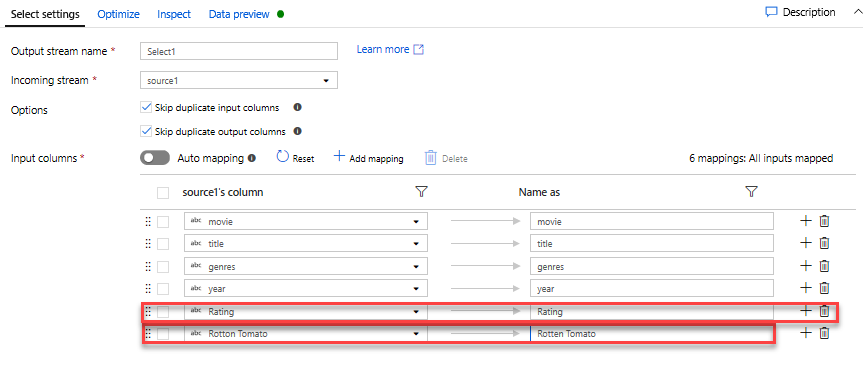
Szűrőátalakítás hozzáadása a nemkívánatos évek kiszűréséhez. Tegyük fel, hogy csak az 1951 után készült filmek érdeklik. Szűrőátalakítást úgy adhat hozzá, hogy szűrőfeltételt adjon meg. Ehhez kattintson az átalakítás kiválasztása melletti + ikonra, és válassza a Szűrő lehetőséget a Sormódosító alatt. A kifejezésmezőre kattintva nyissa meg a Kifejezésszerkesztőt, és adja meg a szűrőfeltételt. A leképezési Adatfolyam kifejezés nyelvének szintaxisával az 1950-es év > egész számra konvertálja a sztringév értékét egész számmá, és szűri a sorokat, ha ez az érték meghaladja az 1950-es értéket.

A kifejezésszerkesztő beágyazott adatok előnézeti paneljén ellenőrizheti, hogy a feltétel megfelelően működik-e
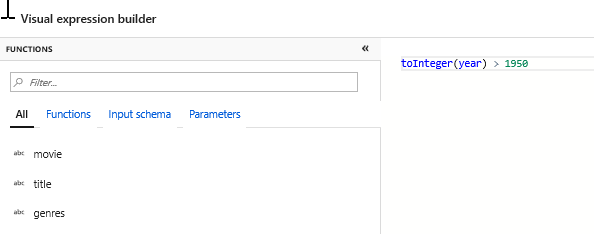
Adjon hozzá származtatott átalakítást az elsődleges műfaj kiszámításához. Mint bizonyára észrevette, a műfajok oszlopa egy |karakterrel tagolt sztring. Ha csak az egyes oszlopok első műfaja érdekli, a Származtatott oszlop átalakításon keresztül egy PrimaryGenre nevű új oszlopot is leküldhet a Szűrőátalakítás melletti + ikonra kattintva, majd a Sémamódosító alatt a Származtatott gombra kattintva. A szűrőátalakításhoz hasonlóan a származtatott oszlop a Leképezés Adatfolyam kifejezésszerkesztővel adja meg az új oszlop értékeit.

Ebben a forgatókönyvben az első műfajt próbálja kinyerni a műfajok oszlopból, amely "műfaj1|műfaj2|...|műfajN". A helykeresési függvénnyel lekérheti a(z) |első 1-alapú indexét a műfaji sztringben. Az iif függvény használatával, ha ez az index nagyobb, mint 1, az elsődleges műfaj a bal oldali függvényen keresztül számítható ki, amely egy sztring összes karakterét az index bal oldalán adja vissza. Ellenkező esetben a PrimaryGenre értéke megegyezik a műfajok mezővel. A kimenetet a kifejezésszerkesztő Adatelőnézet paneljén ellenőrizheti.
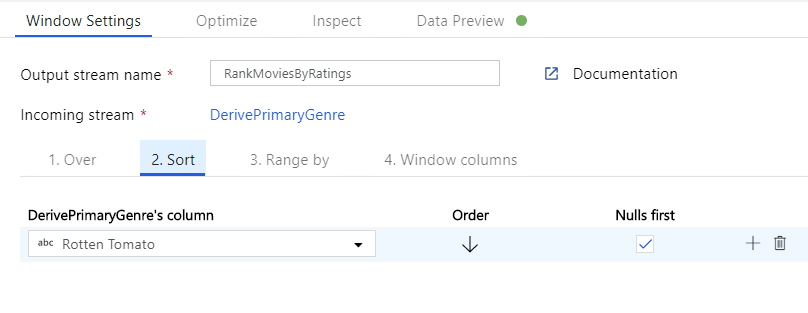
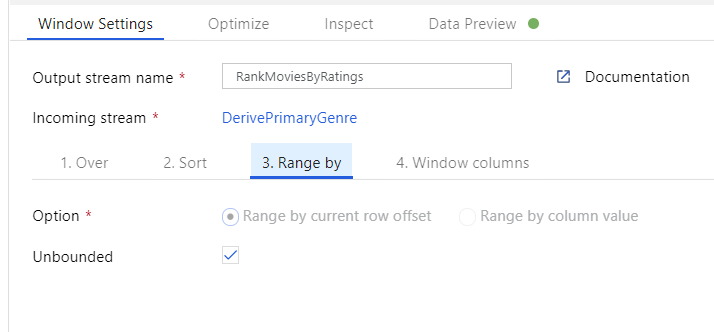
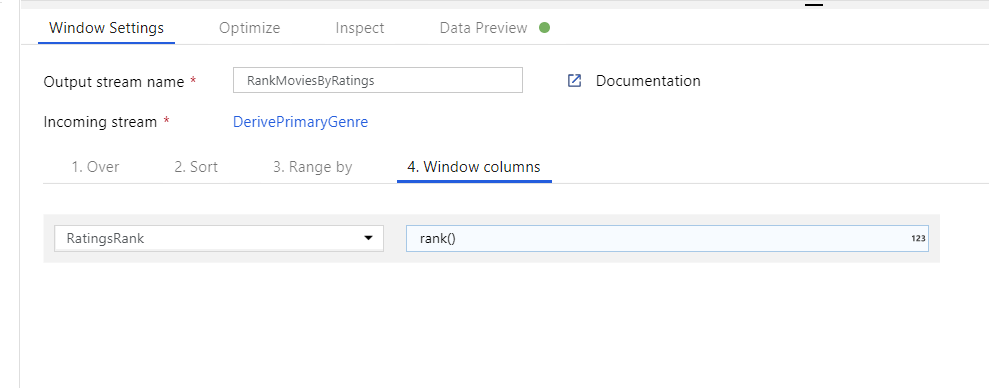
Filmek rangsorolása ablakátalakítással. Tegyük fel, hogy érdekli, hogy egy film hogyan rangsorolja az év során az adott műfaj. A Származtatott oszlop átalakítás melletti + ikonra kattintva és a Sémamódosító alatt az Ablak ikonra kattintva adhat hozzá ablakátalakítást az ablakalapú összesítések definiálásához. Ennek végrehajtásához adja meg, hogy mit válogat át, mi alapján rendez, mi a tartomány, és hogyan számítsa ki az új ablakoszlopokat. Ebben a példában a PrimaryGenre és az év határtalan tartományt használunk, a Rotten Paradicsom szerint csökkenő sorrendben rendezünk, és kiszámítunk egy új, RatingsRank nevű oszlopot, amely egyenlő azzal a rangtal, amelyet az egyes filmek a saját műfaji évén belül kapnak.
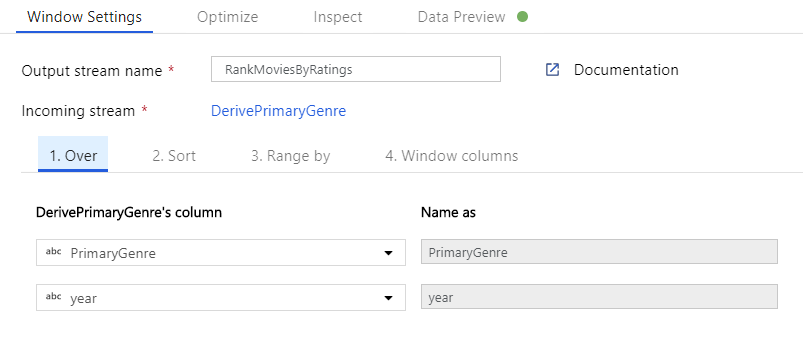
Összesítési átalakítással rendelkező minősítések összesítése. Most, hogy összegyűjtötte és levezette az összes szükséges adatot, hozzáadhat egy összesített átalakításta kívánt csoport alapján kiszámított metrikák kiszámításához. Ehhez kattintson az Ablak átalakítás melletti + ikonra, és kattintson az Összesítés gombra a Sémamódosító alatt. Ahogy az ablakátalakítás során tette, lehetővé teszi a filmek csoportosítását a PrimaryGenre és az év szerint
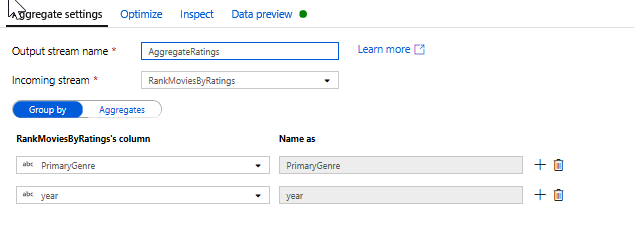
Az Összesítések lapon a megadott csoportban oszlopok szerint számított összesítéseket hozhat létre. Minden műfaj és év, lehetővé teszi, hogy az átlagos Rotten Tomatoes értékelés, a legmagasabb és legalacsonyabb besorolású film (kihasználva az ablakozás funkció) és a filmek száma, hogy az egyes csoportokban. Az összesítés jelentősen csökkenti az átalakítási adatfolyam sorainak számát, és csak az átalakításban megadott oszlopok alapján propagálja a csoportot, és összesíti az oszlopokat.
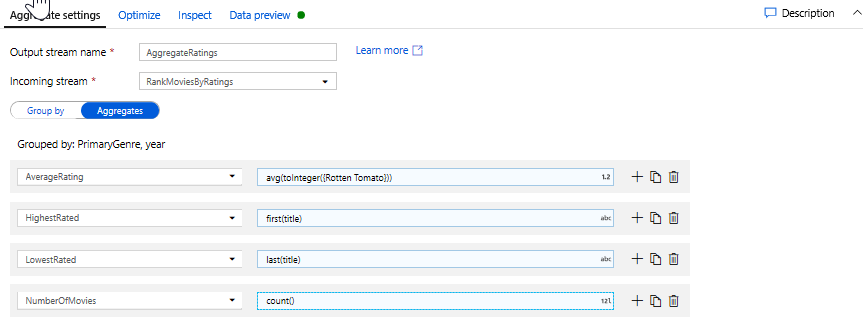
- Annak megtekintéséhez, hogy az összesítő átalakítás hogyan módosítja az adatokat, használja az Adatok előnézete lapot
Adja meg az Upsert feltételt az Alter Row Transformation használatával. Ha táblázatos fogadóba ír, a Sorok módosítása átalakítással megadhatja a sorok beszúrási, törlési, frissítési és frissítési szabályzatait. Ehhez kattintson az Összesítés átalakítás melletti + ikonra, majd a Sormódosító alatt a Sor módosítása elemre. Mivel mindig beszúr és frissít, megadhatja, hogy az összes sor mindig legyen frissítve.

4. feladat: Írás adatgyűjtőbe
- Írjon egy Azure Synapse Analytics-fogadóba. Most, hogy befejezte az összes átalakítási logikát, készen áll a fogadóba való írásra.
Vegyen fel egy fogadót az Upsert-átalakítás melletti + ikonra kattintva, majd a Fogadó elemre a Cél területen.
A Fogadó lapon hozzon létre egy új adattárház-adatkészletet az + Új gombbal.
Válassza az Azure Synapse Analytics lehetőséget a csempék listájából.
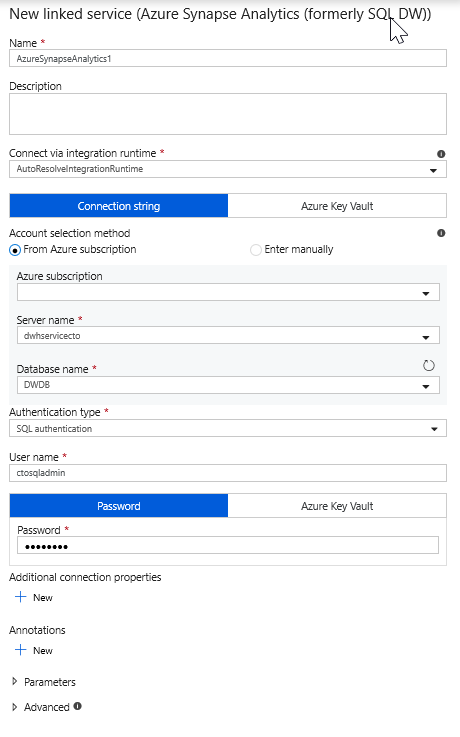
Válasszon ki egy új társított szolgáltatást, és konfigurálja az Azure Synapse Analytics-kapcsolatot a DWDB-adatbázishoz való csatlakozáshoz. Ha végzett, kattintson a Létrehozás gombra.
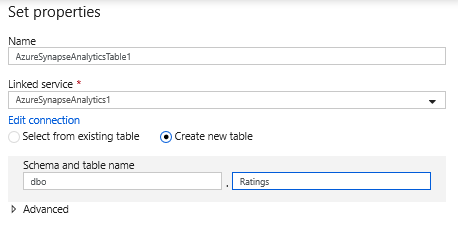
Az adathalmaz konfigurációjában válassza az Új tábla létrehozása lehetőséget, és adja meg a Dbo sémáját és a Minősítések táblanevét. Ha végzett, kattintson az OK gombra .
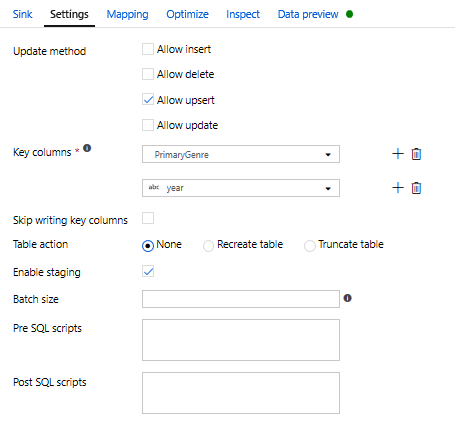
Mivel egy upsert feltételt adott meg, lépjen a Gépház lapra, és válassza az "Upsert engedélyezése" lehetőséget a PrimaryGenre és az év kulcsoszlopok alapján.
Ezen a ponton befejezte a 8 transzformációs leképezési Adatfolyam elkészítését. Itt az ideje, hogy futtassa a folyamatot, és tekintse meg az eredményeket!

5. feladat: A folyamat futtatása
Lépjen a folyamat1 lapra a vásznon. Mivel az Azure Synapse Analytics Adatfolyam PolyBase-t használ, meg kell adnia egy blob- vagy ADLS-előkészítési mappát. Az Adatfolyam tevékenység beállításai lapon nyissa meg a PolyBase harmonikát, válassza ki az ADLS-hez társított szolgáltatást, és adjon meg egy átmeneti mappa elérési útját.

A folyamat közzététele előtt futtasson egy másik hibakeresési futtatási műveletet annak ellenőrzéséhez, hogy a folyamat a várt módon működik-e. A Kimenet lapra tekintve mindkét tevékenység állapotát figyelheti, miközben futnak.
Ha mindkét tevékenység sikeres volt, a Adatfolyam tevékenység melletti szemüveg ikonra kattintva részletesebben is áttekintheti a Adatfolyam futtatásokat.
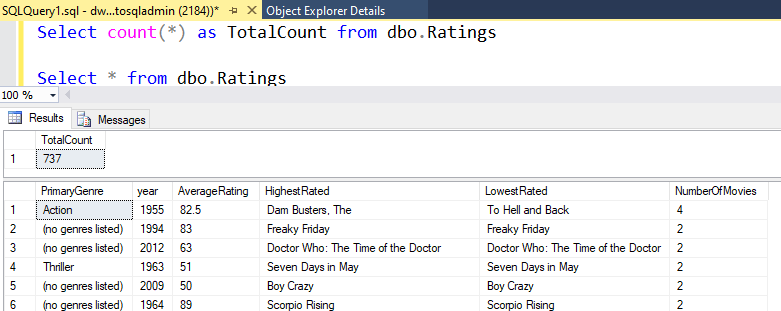
Ha a laborban ismertetett logikát használta, a Adatfolyam 737 sort ír az SQL DW-be. Az SQL Server Management Studióban ellenőrizheti, hogy a folyamat megfelelően működött-e, és hogy mit írtak.