Fase di comprensione delle strategie aziendali nel ciclo di vita del processo di data science per i team
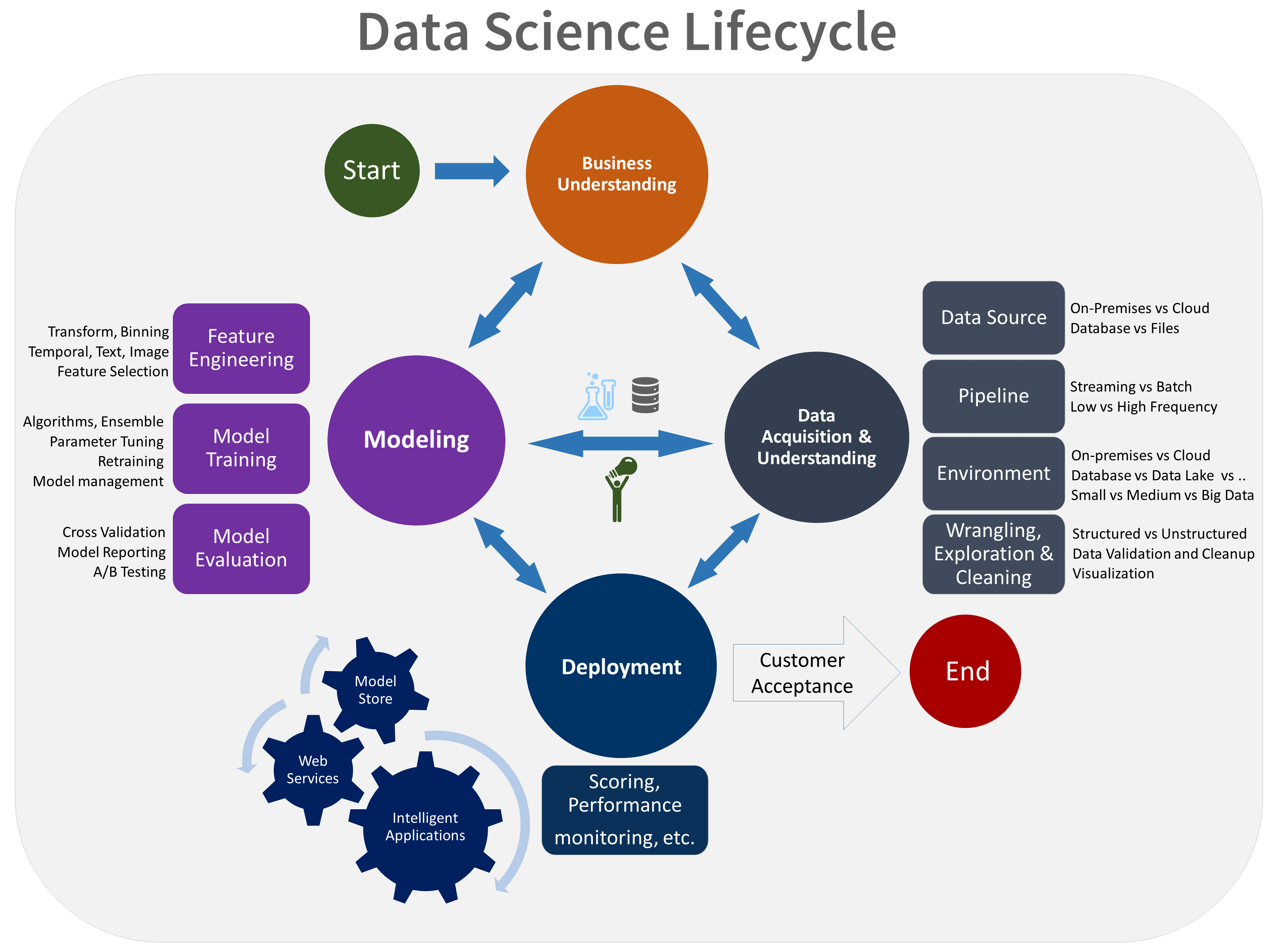
Questo argomento descrive gli obiettivi, le attività e i risultati finali associati alla fase di comprensione del business del processo di data science per i team. Questo processo offre un ciclo di vita consigliato che il team può usare per strutturare i progetti di data science. Il ciclo di vita descrive le fasi principali eseguite dal team, spesso iterativamente:
- Comprensione del business
- Acquisizione e comprensione dei dati
- Modellazione
- Distribuzione
- Accettazione del cliente
Ecco una rappresentazione visiva del ciclo di vita di TDSP:
Obiettivi
Gli obiettivi della fase di comprensione aziendale sono:
Specificare le variabili chiave che fungono da destinazioni del modello. Specificare le metriche delle destinazioni, che determinano l'esito positivo del progetto.
Identificare le origini dati pertinenti a cui l'azienda ha accesso o per le quali deve ottenere l'accesso.
Come completare le attività
La fase di comprensione aziendale ha due attività principali:
Definizione degli obiettivi: interagire con il cliente e altre parti interessate per comprendere e identificare i problemi aziendali. Formulare domande che definiscano i target aziendali e a cui si possano applicare le tecniche di data science.
Identificare le origini dati: trovare i dati rilevanti che consentono di rispondere alle domande di definizione degli obiettivi del progetto.
Definire gli obiettivi
Un obiettivo centrale di questa fase consiste nell'identificare le variabili aziendali chiave che l'analisi deve prevedere. Queste variabili sono denominate destinazioni del modello e le metriche associate vengono usate per determinare l'esito positivo del progetto. Ad esempio, una destinazione può essere una previsione di vendita o la probabilità che un ordine sia fraudolento.
Per definire gli obiettivi del progetto, porre e perfezionare domande precise pertinenti, specifiche e non ambigue. Il data science è un processo che usa nomi e numeri per rispondere a tali domande. In genere si usa il data science o Machine Learning per rispondere a cinque tipi di domande:
- In che quantità o in che numero? (regressione)
- Quale categoria? (classificazione)
- Quale gruppo? (clustering)
- È insolito? (rilevamento anomalie)
- Quale opzione scegliere? (suggerimento)
Determinare quale di queste domande porre e come rispondere può aiutare a raggiungere gli obiettivi aziendali.
Per definire il team del progetto, specificare i ruoli e le responsabilità dei membri. Sviluppare un piano con attività cardine di alto livello da ripetere man mano che la quantità di informazioni acquisite aumenta.
È necessario definire le metriche di successo. Ad esempio, potrebbe essere necessario soddisfare una stima della varianza dei clienti con un tasso di accuratezza pari a x % entro la fine di un progetto di tre mesi. Con questi dati è possibile offrire ai clienti promozioni per ridurre il tasso di abbandono. Le metriche devono essere SMART:
- Specifico
- Measurable: misurabili
- Achievable: conseguibili
- Relevant: rilevanti
- Time-bound: con associazione temporale
Identificare le origini dati
Identificare le origini dati che contengono esempi noti di risposte alle domande. Cercare i dati seguenti:
- Dati pertinenti alla domanda. Sono presenti misure del target e funzionalità correlate al target?
- Dati che rappresentano una misurazione accurata del target di modello e delle funzionalità di interesse.
Ad esempio, un sistema esistente potrebbe non avere i dati necessari per risolvere un problema e raggiungere un obiettivo del progetto. In questo caso, potrebbe essere necessario trovare origini dati esterne o aggiornare i sistemi per raccogliere nuovi dati.
Integrazione con MLflow
Per la fase di comprensione aziendale, il team non usa gli strumenti MLflow, ma può trarre vantaggio indirettamente dalla documentazione e dalle funzionalità di rilevamento degli esperimenti di MLflow. Queste funzionalità possono fornire informazioni dettagliate e contesto cronologico per allineare il progetto agli obiettivi aziendali.
Artifacts
In questa fase il team offre:
Documento charter. Il documento di dichiarazione di intenti è sempre in evoluzione. Aggiornare il documento in tutto il progetto man mano che si apportano nuove individuazioni e man mano che cambiano i requisiti aziendali. La chiave consiste nell'scorrere il documento. Aggiungere altri dettagli durante il processo di individuazione. Informare il cliente e altri stakeholder delle modifiche e dei motivi per loro.
Origini dati. È possibile usare Azure Machine Learning per gestire la gestione delle origini dati. È consigliabile usare questo servizio di Azure per progetti attivi e particolarmente di grandi dimensioni perché si integra con MLflow.
Dizionari dati. Questo documento fornisce descrizioni dei dati forniti dal client. Queste descrizioni includono informazioni sullo schema (tipi di dati e informazioni sulle regole di convalida, se presenti) e diagrammi sulle relazioni di entità, se disponibili. Il team deve documentare alcune o tutte queste informazioni.
Letteratura con revisione peer
I ricercatori pubblicano studi sul TDSP nella letteratura con revisione peer. Le citazioni offrono l'opportunità di analizzare altre applicazioni o idee simili al TDSP, inclusa la fase del ciclo di vita di comprensione aziendale.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Mark Tabladillo | Senior Cloud Solution Architect
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Risorse correlate
Questi articoli descrivono le altre fasi del ciclo di vita di TDSP:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per