Fase di acquisizione e comprensione dei dati del ciclo di vita del processo di data science per i team
Questo articolo descrive gli obiettivi, le attività e i risultati finali associati alla fase di acquisizione e comprensione dei dati nel processo di data science per i team (TDSP). Questo processo offre un ciclo di vita consigliato che il team può usare per strutturare i progetti di data science. Il ciclo di vita descrive le fasi principali eseguite dal team, spesso iterativamente:
- Comprensione del business
- Acquisizione e comprensione dei dati
- Modellazione
- Distribuzione
- Accettazione del cliente
Ecco una rappresentazione visiva del ciclo di vita di TDSP:
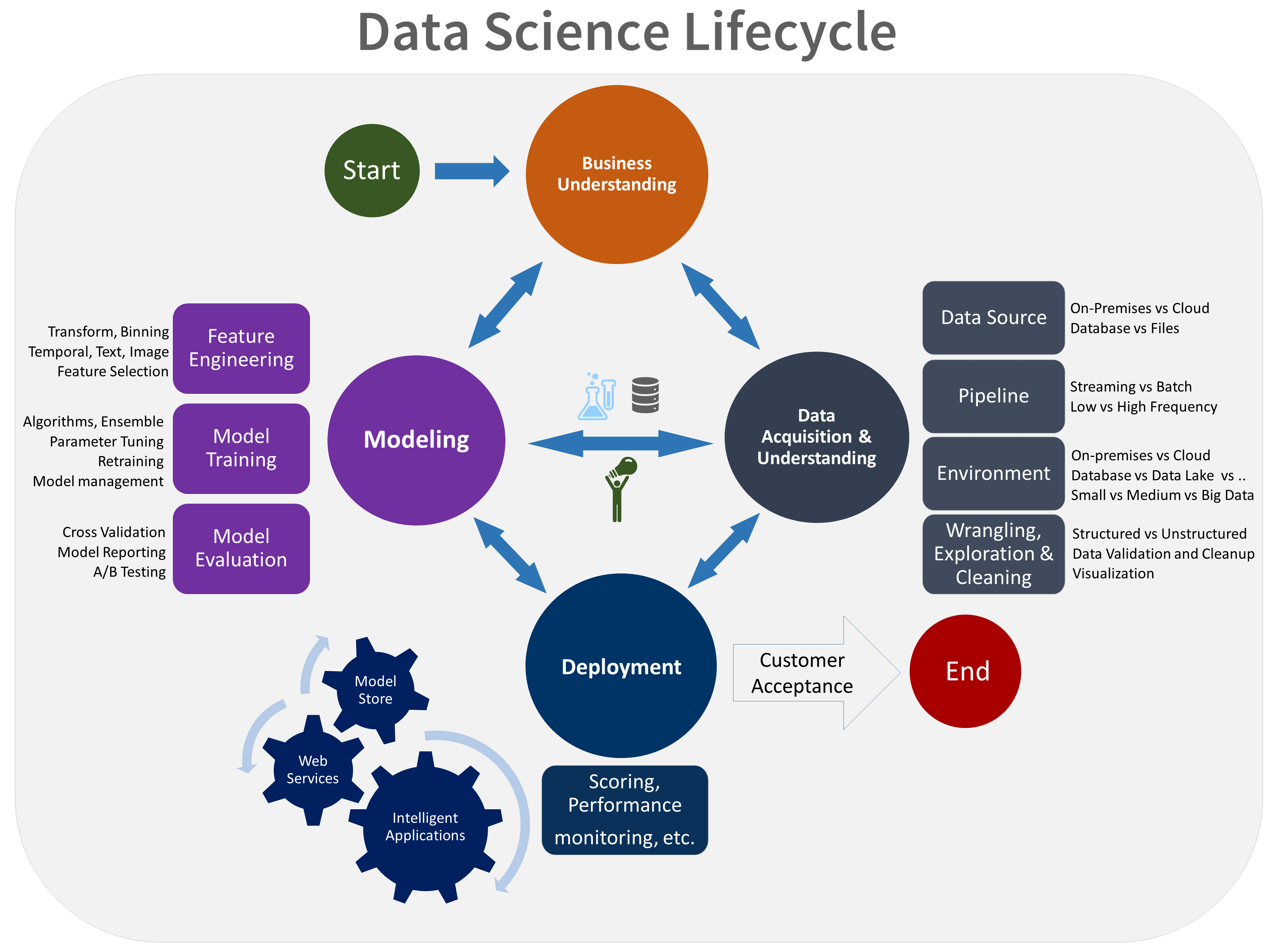
Obiettivi
Gli obiettivi della fase di acquisizione e comprensione dei dati sono:
Produrre un set di dati pulito e di alta qualità che sia chiaramente correlato alle variabili di destinazione. Individuare il set di dati nell'ambiente di analisi appropriato in modo che il team sia pronto per la fase di modellazione.
Sviluppare un'architettura della soluzione della pipeline di dati per aggiornare e valutare regolarmente i dati.
Come completare le attività
La fase di acquisizione e comprensione dei dati ha tre attività principali:
Inserire dati nell'ambiente analitico di destinazione.
Esplorare i dati per determinare se i dati possono rispondere alla domanda.
Configurare una pipeline di dati per calcolare dati nuovi o regolarmente aggiornati.
Inserire i dati
Configurare un processo per spostare i dati dalle posizioni di origine alle posizioni di destinazione in cui si eseguono operazioni di analisi, ad esempio training e stime.
Esplorare i dati
Prima di eseguire il training dei modelli, è necessario sviluppare una buona comprensione dei dati. I set di dati reali sono spesso rumorosi, mancano valori o presentano altre discrepanze. È possibile usare il riepilogo e la visualizzazione dei dati per controllare la qualità dei dati e raccogliere informazioni per l'elaborazione dei dati prima che sia pronta per la modellazione. Spesso, questo processo è iterativo. Per istruzioni sulla pilizia dei dati, vedere Attività per preparare i dati per operazioni avanzate con Machine Learning.
Dopo aver soddisfatto la qualità dei dati puliti, il passaggio successivo consiste nel comprendere meglio i modelli nei dati. L'analisi dei dati agevola la scelta e lo sviluppo di un modello predittivo appropriato per il proprio obiettivo. Determinare la quantità di dati corrispondente alla destinazione. Decidere quindi se il team dispone di dati sufficienti per procedere con i passaggi di modellazione successivi. Anche questo processo è iterativo. Potrebbe essere necessario trovare nuove origini dati con dati più accurati o più pertinenti per regolare il set di dati inizialmente identificato nella fase precedente.
Impostare una pipeline di dati
Oltre all'inserimento e alla pulizia dei dati, in genere è necessario configurare un processo per assegnare punteggi ai nuovi dati o aggiornare regolarmente i dati come parte di un processo di apprendimento continuo. È possibile usare una pipeline di dati o un flusso di lavoro per assegnare un punteggio ai dati. È consigliabile una pipeline che usa Azure Data Factory.
In questa fase si sviluppa un'architettura della soluzione della pipeline di dati. La pipeline viene creata in parallelo con la fase successiva del progetto di data science. A seconda delle esigenze aziendali e dei vincoli dei sistemi esistenti in cui questa soluzione è in fase di integrazione, la pipeline può essere:
- Basata su batch
- In streaming o in tempo reale
- Ibrido
Integrazione con MLflow
Durante la fase di comprensione dei dati, è possibile usare il rilevamento dell'esperimento di MLflow per tenere traccia e documentare varie strategie di pre-elaborazione dei dati e analisi esplorativa dei dati.
Artifacts
In questa fase il team offre:
Report data quality che include riepiloghi dei dati, relazioni tra ogni attributo e destinazione, classificazione delle variabili e altro ancora.
Un'architettura della soluzione, ad esempio un diagramma o una descrizione della pipeline di dati usata dal team per eseguire stime sui nuovi dati. Questo diagramma contiene anche la pipeline per ripetere il training del modello in base ai nuovi dati. Quando si usa il modello di struttura di directory TDSP, archiviare il documento nella directory del progetto.
Decisione del checkpoint. Prima di iniziare la progettazione completa delle funzionalità e la compilazione di modelli, è possibile rivalutare il progetto per determinare se il valore previsto è sufficiente per continuare a eseguirlo. È possibile, ad esempio, essere pronti per continuare, raccogliere più dati o abbandonare il progetto se non è possibile trovare dati che rispondono alle domande.
Letteratura con revisione peer
I ricercatori pubblicano studi sul TDSP nella letteratura con revisione peer. Le citazioni offrono l'opportunità di analizzare altre applicazioni o idee simili al TDSP, tra cui la fase relativa all'acquisizione e alla comprensione del ciclo di vita dei dati.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Mark Tabladillo | Senior Cloud Solution Architect
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Risorse correlate
Questi articoli descrivono le altre fasi del ciclo di vita di TDSP:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per