Fase di modellazione del ciclo di vita del processo di data science per i team
Questo argomento descrive gli obiettivi, le attività e i risultati finali associati alla fase di modellazione del processo TDSP. Questo processo offre un ciclo di vita consigliato che il team può usare per strutturare i progetti di data science. Il ciclo di vita descrive le fasi principali eseguite dal team, spesso iterativamente:
- Comprensione del business
- Acquisizione e comprensione dei dati
- Modellazione
- Distribuzione
- Accettazione del cliente
Ecco una rappresentazione visiva del ciclo di vita di TDSP:
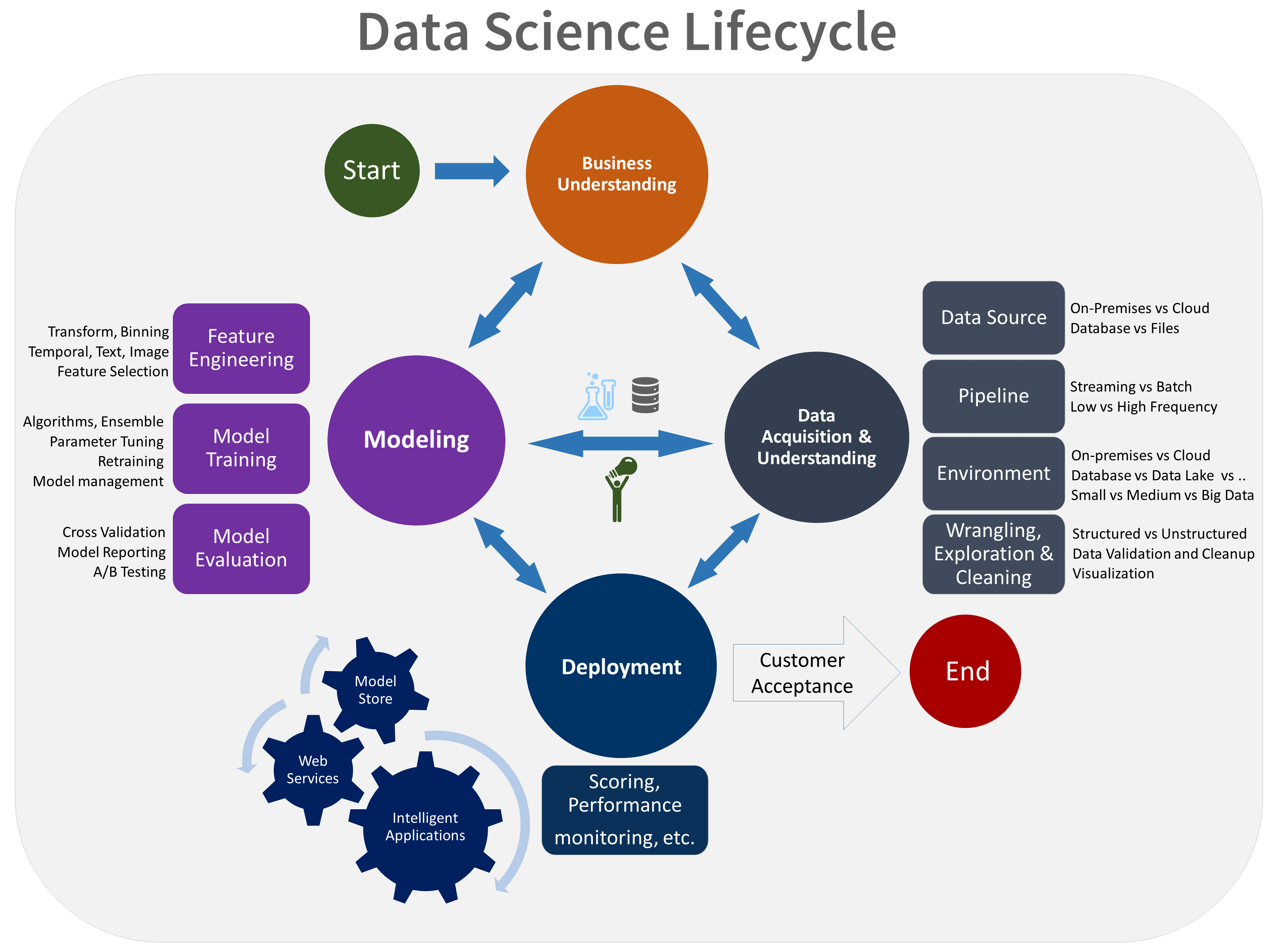
Obiettivi
Gli obiettivi della fase di modellazione sono:
Determinare le funzionalità dei dati ottimali per il modello di Machine Learning.
Creare un modello di Machine Learning informativo che stima la destinazione in modo più accurato.
Creare un modello di Machine Learning adatto per la produzione.
Come completare le attività
La fase di modellazione ha tre attività principali:
Progettazione delle funzioni: creare le funzionalità dei dati dai dati non elaborati per facilitare il training del modello.
Training del modello: trovare il modello che risponde più accuratamente alla domanda confrontando le metriche di successo dei modelli.
Valutazione del modello: determinare se il modello è adatto per la produzione.
Progettazione delle caratteristiche
La progettazione di funzionalità prevede l'aggiunta, l'aggregazione e la trasformazione delle variabili non elaborate per creare funzionalità usate nell'analisi. Per ottenere informazioni dettagliate sulla creazione di un modello, è necessario studiare le funzionalità sottostanti del modello.
Questo passaggio richiede una combinazione creativa di competenze a livello di dominio e di informazioni approfondite ottenute dal passaggio di esplorazione dei dati. La progettazione delle funzionalità è un atto di bilanciamento della ricerca e dell'inclusione di variabili informative, ma allo stesso tempo cercando di evitare troppe variabili non correlate. Le variabili informative migliorano il risultato. Le variabili non correlate introducono rumore non necessario nel modello. È anche necessario generare le seguenti funzionalità per i nuovi dati ottenuti durante la valutazione. La generazione di queste funzionalità, quindi, può dipendere esclusivamente dai dati disponibili al momento della valutazione.
Training del modello
Esistono molti algoritmi di modellazione che è possibile usare, a seconda del tipo di domanda a cui si sta provando a rispondere. Per indicazioni sulla scelta di un algoritmo predefinito, vedere Foglio informativo sugli algoritmi di Machine Learning per la finestra di progettazione di Azure Machine Learning. Altri algoritmi sono disponibili tramite pacchetti open source in R o Python. Anche se questo articolo è incentrato su Azure Machine Learning, le indicazioni fornite sono utili per molti progetti di Machine Learning.
Il processo di training del modello include i passaggi seguenti:
Suddividere i dati di input in modo casuale per la modellazione in un set di dati di training e un set di dati di test.
Compilare i modelli usando il set di dati di training.
Valutare il set di dati di test e di training. Usare una serie di algoritmi di Machine Learning concorrenti. Usare vari parametri di ottimizzazione associati (noti come sweep di parametri) orientati alla risposta alla domanda di interesse con i dati correnti.
Determinare la soluzione migliore per rispondere alla domanda confrontando le metriche di successo tra metodi alternativi.
Per altre informazioni, vedere Eseguire il training di modelli con Machine Learning.
Nota
Evitare perdite: è possibile che si verifichino perdite di dati se si includono dati dall'esterno del set di dati di training che consente a un modello o a un algoritmo di Machine Learning di eseguire stime non realistiche. La perdita è il motivo comune che infastidisce gli esperti di dati quando ottengono risultati predittivi che appaiono troppo validi per essere reali. Queste dipendenze potrebbero essere difficili da rilevare. Evitare la perdita spesso richiede l'iterazione tra la creazione di un set di dati di analisi, la creazione di un modello e la valutazione dell'accuratezza dei risultati.
Valutazione del modello
Dopo aver eseguito il training del modello, un data scientist del team è incentrato sulla valutazione del modello.
Effettuare una determinazione: valutare se il modello esegue sufficientemente per la produzione. Alcune domande chiave da porsi:
Il modello risponde alla domanda con sufficiente certezza rispetto ai dati del test?
È consigliabile tentare approcci alternativi?
È consigliabile raccogliere più dati, eseguire altre attività di progettazione delle funzionalità o sperimentare altri algoritmi?
Interpretare il modello: usare Machine Learning Python SDK per eseguire le attività seguenti:
Spiegare l'intero comportamento del modello o le singole previsioni nel computer personale in locale.
Abilitare le tecniche di interpretabilità per le funzionalità progettate.
Spiegare il comportamento dell'intero modello e delle singole previsioni in Azure.
Caricare spiegazioni nella cronologia di esecuzione di Machine Learning.
Usare un dashboard di visualizzazione per interagire con le spiegazioni del modello, sia in un notebook jupyter che nell'area di lavoro di Machine Learning.
Distribuire un explainer dell'assegnazione di punteggi insieme al modello per osservare le spiegazioni durante l'inferenza.
Valutare l'equità: usare il pacchetto Python open source fairlearn con Machine Learning per eseguire le attività seguenti:
Valutazione della congruità delle previsioni del modello. Questo processo consente al team di ottenere altre informazioni sull'equità nell'apprendimento automatico.
Caricare, elencare e scaricare informazioni dettagliate sulla valutazione dell'equità da e verso Machine Learning Studio.
Per interagire con le informazioni dettagliate sull'equità dei modelli, vedere il dashboard di valutazione dell'equità in Machine Learning Studio.
Integrazione con MLflow
Machine Learning si integra con MLflow per supportare il ciclo di vita della modellazione. Usa il rilevamento di MLflow per esperimenti, distribuzione del progetto, gestione dei modelli e registro dei modelli. Questa integrazione garantisce un flusso di lavoro di Machine Learning facile ed efficiente. Le funzionalità seguenti di Machine Learning supportano questo elemento del ciclo di vita della modellazione:
Tenere traccia degli esperimenti: la funzionalità di base di MLflow viene ampiamente usata nella fase di modellazione per tenere traccia di vari esperimenti, parametri, metriche e artefatti.
Distribuire progetti: la creazione di pacchetti di codice con progetti MLflow garantisce esecuzioni coerenti e una facile condivisione tra i membri del team, essenziale durante lo sviluppo di modelli iterativi.
Gestire i modelli: la gestione e il controllo delle versioni dei modelli è fondamentale in questa fase perché vengono compilati, valutati e perfezionati modelli diversi.
Registrare i modelli: il registro dei modelli viene usato per il controllo delle versioni e la gestione dei modelli durante il ciclo di vita.
Letteratura con revisione peer
I ricercatori pubblicano studi sul TDSP nella letteratura con revisione peer. Le citazioni offrono l'opportunità di analizzare altre applicazioni o idee simili al TDSP, inclusa la fase del ciclo di vita della modellazione.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Mark Tabladillo | Senior Cloud Solution Architect
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Risorse correlate
Questi articoli descrivono le altre fasi del ciclo di vita di TDSP:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per