Tolleranza di errore dell'attività di copia nelle pipeline di Azure Data Factory e Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
Quando si copiano dati dall'archivio di origine all'archivio di destinazione, l'attività di copia fornisce un determinato livello di tolleranza di errore per impedire interruzioni da errori durante lo spostamento dei dati. Si consiglia, ad esempio, di copiare milioni di righe dall'archivio di origine a quello di destinazione, in cui sia stata creata una chiave primaria nel database di destinazione, ma senza che siano state definite chiavi primarie nel database di origine. Quando si copiano righe duplicate dall'origine alla destinazione, si verifica un errore di violazione della CP nel database di destinazione. Attualmente, l'attività di copia offre due modi per gestire tali errori:
- È possibile interrompere l'attività di copia quando viene rilevato un errore.
- È possibile continuare a copiare la parte restante abilitando la tolleranza di errore per ignorare i dati incompatibili. Ad esempio, in questo caso è possibile ignorare la riga duplicata. È anche possibile registrare i dati ignorati abilitando il log sessione all'interno dell'attività di copia. Per altri dettagli, fare riferimento al log della sessione nell'attività di copia.
Copia di file binari
Il servizio supporta gli scenari di tolleranza di errore seguenti durante la copia di file binari. È possibile scegliere di interrompere l'attività di copia o continuare a copiare il resto negli scenari seguenti:
- I file da copiare dal servizio vengono eliminati contemporaneamente da altre applicazioni.
- Alcune cartelle o file particolari non consentono l'accesso al servizio perché gli ACL di tali file o cartelle richiedono un livello di autorizzazione superiore rispetto alle informazioni di connessione configurate.
- Uno o più file non vengono verificati in modo che siano coerenti tra l'archivio di origine e quello di destinazione se si abilita l'impostazione di verifica della coerenza dei dati.
Abilitare la tolleranza di errore con l'interfaccia utente
Per configurare la tolleranza di errore in un attività Copy in una pipeline con l'interfaccia utente, seguire questa procedura:
Se non è già stata creata una attività Copy per la pipeline, cercare Copia nel riquadro Attività pipeline e trascinare un'attività Copia dati nell'area di disegno della pipeline.
Selezionare la nuova attività Copia dati nell'area di disegno se non è già selezionata e la relativa scheda Impostazioni per configurare la tolleranza di errore.
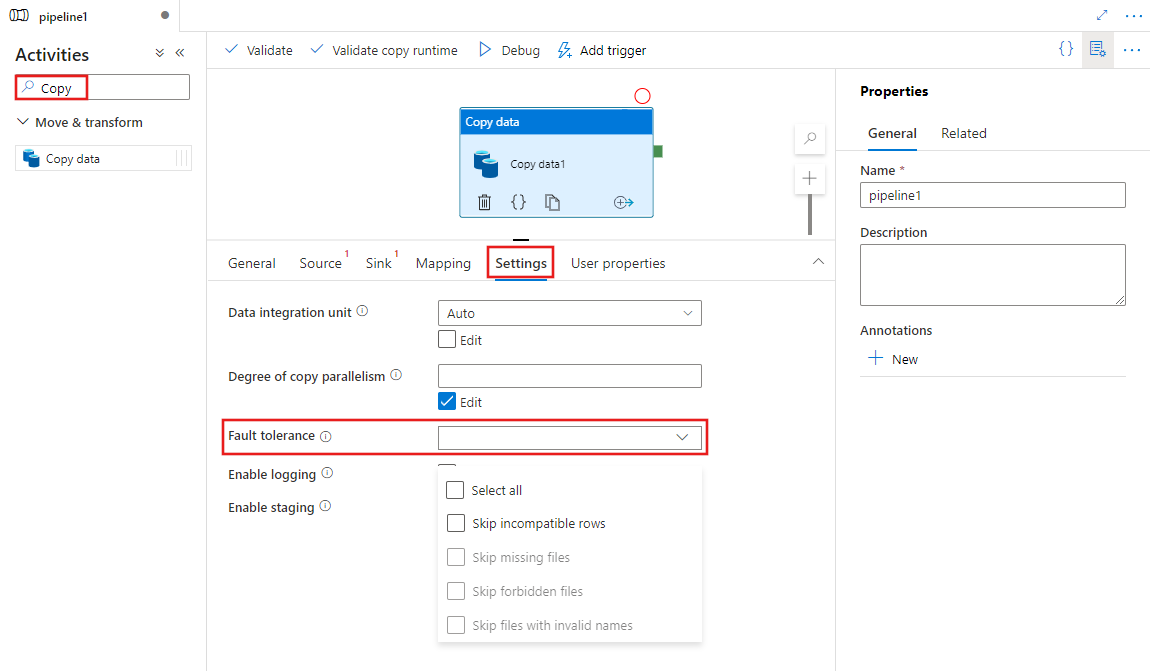
Configurazione
Quando si copiano file binari tra gli archivi, è possibile abilitare la tolleranza di errore come segue:
{
"name": "CopyActivityFaultTolerance",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BinarySource",
"storeSettings": {
"type": "AzureDataLakeStoreReadSettings",
"recursive": true
}
},
"sink": {
"type": "BinarySink",
"storeSettings": {
"type": "AzureDataLakeStoreWriteSettings"
}
},
"skipErrorFile": {
"fileMissing": true,
"fileForbidden": true,
"dataInconsistency": true,
"invalidFileName": true
},
"validateDataConsistency": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
}
}
| Proprietà | Descrizione | Valori consentiti | Richiesto |
|---|---|---|---|
| skipErrorFile | Gruppo di proprietà per specificare i tipi di errori da ignorare durante lo spostamento dati. | No | |
| fileMissing | Una delle coppie chiave-valore all'interno del contenitore delle proprietà skipErrorFile per determinare se si desidera ignorare i file eliminati da altre applicazioni al momento in cui il servizio esegue l'operazione di copia. - True: consente di copiare la parte restante ignorando i file eliminati da altre applicazioni. - False: consente di interrompere l'attività di copia dopo che i file sono stati eliminati dall'archivio di origine durante lo spostamento dati. Notare che, per impostazione predefinita, questa proprietà è impostata su True. |
True(impostazione predefinita) False |
No |
| fileForbidden | Una delle coppie chiave-valore all'interno del contenitore delle proprietà skipErrorFile per determinare se si desidera ignorare i file specifici, quando gli elenchi di controllo di accesso di tali file o cartelle richiedono un livello di autorizzazione superiore rispetto alla connessione configurata. - True: permette di copiare il resto ignorando i file. - False: permette di interrompere l'attività di copia una volta rilevato il problema di autorizzazione per cartelle o file. |
Vero False (impostazione predefinita) |
No |
| dataInconsistency | Una delle coppie chiave-valore all'interno del contenitore delle proprietà skipErrorFile per determinare se ignorare i dati incoerenti tra l'archivio di origine e quello di destinazione. - True: permette di copiare il resto ignorando i dati incoerenti. - False: permette di interrompere l'attività di copia una volta trovati dati incoerenti. Tenere presente che questa proprietà è valida solo quando si imposta validateDataConsistency su True. |
Vero False (impostazione predefinita) |
No |
| invalidFileName | Una delle coppie chiave-valore all'interno del contenitore delle proprietà skipErrorFile per determinare se si desidera ignorare i file specifici, quando i nomi dei file non sono validi per l'archivio di destinazione. -True: si vuole copiare il resto ignorando i file con nomi di file non validi. - False: si vuole interrompere l'attività di copia dopo che tutti i file hanno nomi di file non validi. Tenere presente che questa proprietà funziona quando si copiano file binari da qualsiasi archivio di archiviazione ad ADLS Gen2 o si copiano file binari da AWS S3 solo in qualsiasi archivio di archiviazione. |
Vero False (impostazione predefinita) |
No |
| log Impostazioni | Un gruppo di proprietà che può essere specificato quando si vuole registrare i nomi degli oggetti ignorati. | No | |
| linkedServiceName | Servizio collegato di Archiviazione BLOB di Azure o Azure Data Lake Storage Gen2 per archiviare i file di log della sessione. | Nomi di un servizio collegato di tipo AzureBlobStorage o AzureBlobFS che fa riferimento all'istanza da usare per archiviare il file di log. |
No |
| path | Percorso dei file di log. | Specificare il percorso usato per archiviare i file di log. Se non si specifica un percorso, il servizio crea automaticamente un contenitore. | No |
Nota
Di seguito sono riportati i prerequisiti per abilitare la tolleranza di errore nell'attività di copia durante la copia di file binari. Per ignorare file specifici quando vengono eliminati dall'archivio di origine:
- Il set di dati di origine e il set di dati sink devono essere in formato binario e non è possibile specificare il tipo di compressione.
- I tipi di archivio dati supportati sono Archiviazione BLOB di Azure, Azure Data Lake Archiviazione Gen1, Azure Data Lake Archiviazione Gen2, File di Azure, File System, FTP, SFTP, Amazon S3, Google Cloud Archiviazione e HDFS.
- Solo se si specificano più file nel set di dati di origine, che può essere una cartella, un carattere jolly o un elenco di file, l'attività di copia può ignorare i file di errore specifici. Se un singolo file viene specificato nel set di dati di origine da copiare nella destinazione, l'attività di copia avrà esito negativo se si è verificato un errore.
Per ignorare determinati file quando l'accesso non è consentito dall'archivio di origine:
- Il set di dati di origine e il set di dati sink devono essere in formato binario e non è possibile specificare il tipo di compressione.
- I tipi di archivio dati supportati sono Archiviazione BLOB di Azure, Azure Data Lake Archiviazione Gen1, Azure Data Lake Archiviazione Gen2, File di Azure, SFTP, Amazon S3 e HDFS.
- Solo se si specificano più file nel set di dati di origine, che può essere una cartella, un carattere jolly o un elenco di file, l'attività di copia può ignorare i file di errore specifici. Se un singolo file viene specificato nel set di dati di origine da copiare nella destinazione, l'attività di copia avrà esito negativo se si è verificato un errore.
Per ignorare determinati file quando vengono verificati che siano incoerenti tra l'archivio di origine e quello di destinazione:
- È possibile ottenere altri dettagli dalla documentazione sulla coerenza dei dati qui.
Monitoraggio
Output dell'attività di copia
È possibile ottenere il numero di file letti, scritti e ignorati tramite l'output di ogni esecuzione dell'attività di copia.
"output": {
"dataRead": 695,
"dataWritten": 186,
"filesRead": 3,
"filesWritten": 1,
"filesSkipped": 2,
"throughput": 297,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"dataConsistencyVerification":
{
"VerificationResult": "Verified",
"InconsistentData": "Skipped"
}
}
Log di sessione dell'attività di copia
Se si configura la registrazione dei nomi file ignorati, vedere il file di log al percorso seguente: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
I file di log possono essere solo file CSV. Lo schema del file di log è il seguente:
| Colonna | Descrizione |
|---|---|
| Timestamp: | Timestamp quando il file è stato ignorato. |
| Livello | Livello log dell'elemento. Si troverà nel livello "Avviso" per l'elemento che mostra il file ignorato. |
| OperationName | attività Copy comportamento operativo in ogni file. Sarà "FileSkip" per specificare il file da ignorare. |
| OperationItem | Nomi file da ignorare. |
| Message | Altre informazioni per illustrare il motivo per cui il file viene ignorato. |
Di seguito è riportato un esempio di file di log:
Timestamp,Level,OperationName,OperationItem,Message
2020-03-24 05:35:41.0209942,Warning,FileSkip,"bigfile.csv","File is skipped after read 322961408 bytes: ErrorCode=UserErrorSourceBlobNotExist,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=The required Blob is missing. ContainerName: https://transferserviceonebox.blob.core.windows.net/skipfaultyfile, path: bigfile.csv.,Source=Microsoft.DataTransfer.ClientLibrary,'."
2020-03-24 05:38:41.2595989,Warning,FileSkip,"3_nopermission.txt","File is skipped after read 0 bytes: ErrorCode=AdlsGen2OperationFailed,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ADLS Gen2 operation failed for: Operation returned an invalid status code 'Forbidden'. Account: 'adlsgen2perfsource'. FileSystem: 'skipfaultyfilesforbidden'. Path: '3_nopermission.txt'. ErrorCode: 'AuthorizationPermissionMismatch'. Message: 'This request is not authorized to perform this operation using this permission.'. RequestId: '35089f5d-101f-008c-489e-01cce4000000'..,Source=Microsoft.DataTransfer.ClientLibrary,''Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Operation returned an invalid status code 'Forbidden',Source=,''Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message='Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message=Operation returned an invalid status code 'Forbidden',Source=Microsoft.DataTransfer.ClientLibrary,',Source=Microsoft.DataTransfer.ClientLibrary,'."
Dal log precedente è possibile visualizzare che bigfile.csv è stato ignorato a causa dell'eliminazione di questo file da parte di un'altra applicazione durante la copia del servizio. E 3_nopermission.txt è stato ignorato perché il servizio non è autorizzato ad accedervi a causa di un problema di autorizzazione.
Copia di dati tabulari
Scenari supportati
L'attività di copia supporta tre scenari per rilevare, ignorare e registrare i dati tabulari incompatibili:
Incompatibilità tra il tipo di dati di origine e il tipo nativo sink.
Esempio: si vogliono copiare dati da un file CSV nell'archiviazione BLOB a un database SQL con una definizione di schema che contiene tre colonne di tipo INT. Le righe del file CSV contenenti dati numerici, ad esempio 123, 456, 789, vengono copiate nell'archivio sink. Tuttavia, le righe che contengono valori non numerici, ad esempio 123, 456, abc, vengono rilevate come incompatibili e vengono ignorate.
Mancata corrispondenza nel numero di colonne tra l'origine e il sink.
Esempio: si vogliono copiare dati da un file CSV nell'archivio BLOB a un database SQL con una definizione di schema che contiene sei colonne. Le righe del file CSV che contengono sei colonne vengono copiate nell'archivio sink. Le righe del file CSV che contengono più di sei colonne vengono rilevate come incompatibili e vengono ignorate.
Violazione della chiave primaria per la scrittura in SQL Server/database SQL di Azure/Azure Cosmos DB.
Esempio: si vogliono copiare dati da un'istanza di SQL Server a un database SQL. Il database SQL del sink contiene la definizione di una chiave primaria, che invece manca nell'istanza di SQL Server di origine. Non è possibile copiare nel sink le righe duplicate presenti nell'origine. L'attività di copia copierà nel sink solo la prima riga dei dati di origine. Le righe di origine successive che contengono il valore della chiave primaria duplicato vengono rilevate come incompatibili e vengono ignorate.
Nota
- Per caricare i dati in Azure Synapse Analytics usando PolyBase, configurare le impostazioni di tolleranza di errore native di PolyBase specificando i criteri di rifiuto tramite "polyBase Impostazioni" nell'attività di copia. È comunque possibile abilitare il reindirizzamento delle righe incompatibili di PolyBase a BLOB o ADLS come di consueto, come illustrato di seguito.
- Questa funzionalità non è applicabile quando è configurata l'attività di copia per richiamare lo strumento Unload di Amazon Redshift.
- Questa funzionalità non si applica quando l'attività di copia è configurata per richiamare una stored procedure da un sink SQL o usare Upsert per scrivere dati in un sink SQL.
Configurazione
L'esempio seguente offre la definizione JSON per specificare di ignorare le righe incompatibili nell'attività di copia:
"typeProperties": {
"source": {
"type": "AzureSqlSource"
},
"sink": {
"type": "AzureSqlSink"
},
"enableSkipIncompatibleRow": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
},
| Proprietà | Descrizione | Valori consentiti | Richiesto |
|---|---|---|---|
| enableSkipIncompatibleRow | Specifica se ignorare o meno le righe incompatibili durante la copia. | True False (impostazione predefinita) |
No |
| log Impostazioni | Un gruppo di proprietà che può essere specificato quando si vuole registrare le righe incompatibili. | No | |
| linkedServiceName | Servizio collegato di Archiviazione BLOB di Azure o Azure Data Lake Storage Gen2 con cui archiviare il log che contiene le righe ignorate. | Nomi di un servizio collegato di tipo AzureBlobStorage o AzureBlobFS che fa riferimento all'istanza da usare per archiviare il file di log. |
No |
| path | Percorso del file di log che contiene le righe ignorate. | Specificare il percorso da usare per registrare i dati incompatibili. Se non si specifica un percorso, il servizio crea automaticamente un contenitore. | No |
Monitorare le righe ignorate
Al termine dell'esecuzione dell'attività di copia, è possibile visualizzare il numero di righe ignorate nell'output dell'attività di copia:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
Se si configura la registrazione delle righe incompatibili, vedere il file di log al percorso seguente: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
I file di log sono file CSV. Lo schema del file di log è il seguente:
| Colonna | Descrizione |
|---|---|
| Timestamp: | Timestamp quando le righe incompatibili sono state ignorate |
| Livello | Livello log dell'elemento. Il livello sarà "Avviso" se questo elemento mostra le righe ignorate |
| OperationName | attività Copy comportamento operativo in ogni riga. Sarà "TabularRowSkip" per specificare che la riga incompatibile specifica è stata ignorata |
| OperationItem | Righe ignorate dall'archivio dati di origine. |
| Message | Altre informazioni per illustrare il motivo dell'incompatibilità di questa riga specifica. |
Di seguito è riportato un esempio del contenuto del file di log:
Timestamp, Level, OperationName, OperationItem, Message
2020-02-26 06:22:32.2586581, Warning, TabularRowSkip, """data1"", ""data2"", ""data3""," "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
2020-02-26 06:22:33.2586351, Warning, TabularRowSkip, """data4"", ""data5"", ""data6"",", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
Nel file di log di esempio riportato sopra, è possibile vedere che una riga "data1, data2, data3" è stata ignorata a causa di un problema di conversione tipo dall'archivio di origine a quello di destinazione. Un'altra riga "data4, data5, data6" è stata ignorata a causa di un problema di violazione della CP dall'archivio di origine a quello di destinazione.
Copia di dati tabulari (legacy):
L'approccio seguente è il modo legacy per abilitare la tolleranza di errore solo per la copia di dati tabulari. Se si sta creando una nuova pipeline o attività, è consigliabile iniziare invece da qui.
Configurazione
L'esempio seguente offre la definizione JSON per specificare di ignorare le righe incompatibili nell'attività di copia:
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
},
"enableSkipIncompatibleRow": true,
"redirectIncompatibleRowSettings": {
"linkedServiceName": {
"referenceName": "<Azure Storage or Data Lake Store linked service>",
"type": "LinkedServiceReference"
},
"path": "redirectcontainer/erroroutput"
}
}
| Proprietà | Descrizione | Valori consentiti | Richiesto |
|---|---|---|---|
| enableSkipIncompatibleRow | Specifica se ignorare o meno le righe incompatibili durante la copia. | True False (impostazione predefinita) |
No |
| redirectIncompatibleRowSettings | Un gruppo di proprietà che può essere specificato quando si vuole registrare le righe incompatibili. | No | |
| linkedServiceName | Servizio collegato di Archiviazione di Azure o Azure Data Lake Store con cui archiviare il log che contiene le righe ignorate. | Nomi di un servizio collegato di tipo AzureStorage o AzureDataLakeStore che fa riferimento all'istanza da usare per archiviare il file di log. |
No |
| path | Percorso del file di log che contiene le righe ignorate. | Specificare il percorso da usare per registrare i dati incompatibili. Se non si specifica un percorso, il servizio crea automaticamente un contenitore. | No |
Monitorare le righe ignorate
Al termine dell'esecuzione dell'attività di copia, è possibile visualizzare il numero di righe ignorate nell'output dell'attività di copia:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"redirectRowPath": "https://myblobstorage.blob.core.windows.net//myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
Se si configura la registrazione delle righe incompatibili, vedere il file di log al percorso seguente: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/[copy-activity-run-id]/[auto-generated-GUID].csv.
I file di log possono essere solo i file CSV. Se necessario, i dati originali ignorati verranno registrati con la virgola come delimitatore di colonna. Altre due colonne "ErrorCode" e "ErrorMessage" vengono aggiunte ai dati di origine originali nel file di log, in cui è possibile visualizzare la causa radice dell'incompatibilità. ErrorCode ed ErrorMessage verranno racchiusi tra virgolette doppie.
Di seguito è riportato un esempio del contenuto del file di log:
data1, data2, data3, "UserErrorInvalidDataValue", "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
data4, data5, data6, "2627", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
Contenuto correlato
Vedere gli altri articoli relativi all'attività di copia: