Usare Browser processi e Vista processi per i processi di Azure Data Lake Analytics
Importante
Azure Data Lake Analytics ritirato il 29 febbraio 2024. Per altre informazioni , vedere questo annuncio.
Per l'analisi dei dati, l'organizzazione può usare Azure Synapse Analytics o Microsoft Fabric.
Il servizio Azure Data Lake Analytics archivia i processi inviati in un archivio query. Questo articolo contiene informazioni su come usare Job Browser e Job View (Visualizzazione processo) in Azure Data Lake Tools per Visual Studio per trovare informazioni sulla cronologia di processi.
Per impostazione predefinita, il servizio Data Lake Analytics archivia i processi per 30 giorni. È possibile configurare il periodo di scadenza nel portale di Azure configurando un criterio di scadenza personalizzato. Non sarà possibile accedere alle informazioni sul processo dopo la scadenza.
Prerequisiti
Vedere Prerequisiti di Data Lake Tools per Visual Studio.
Aprire Job Browser
Accedere al Browser processi tramite Esplora server>azure> Data Lake Analytics> Jobs in Visual Studio. Usando Browser processi è possibile accedere all'archivio query di un account Data Lake Analytics. In Browser processi a sinistra viene visualizzato Query Store, che mostra le informazioni di base sul processo, e a destra Vista processi, che mostra le informazioni dettagliate sul processo.
Job View (Visualizzazione processo)
Contiene informazioni dettagliate su un processo. Per aprire un processo, è possibile fare doppio clic su di esso in Job Browser o aprirlo dal menu Data Lake facendo clic su Job View (Visualizzazione processo). Verrà visualizzata una finestra di dialogo in cui è inserito l'URL del processo.
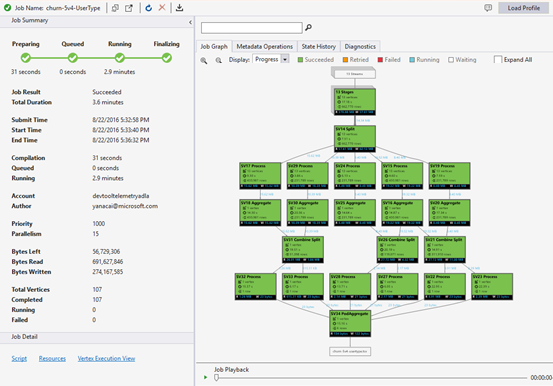
La finestra di dialogo Job View (Visualizzazione processo) contiene:
Riepilogo dei processi
Aggiornare la visualizzazione processo per visualizzare le informazioni più recenti sull'esecuzione dei processi.
Stato del processo (grafico):
Descrive le fasi del processo:
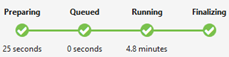
Preparing (Preparazione): caricare lo script nel cloud, compilandolo e ottimizzandolo tramite il servizio di compilazione.
Accodato: i processi vengono accodati quando sono in attesa di risorse sufficienti o i processi superano il numero massimo di processi simultanei per ogni limitazione dell'account. L'impostazione di priorità determina la sequenza di processi in coda: più basso è il numero, maggiore è la priorità.
Running (In esecuzione): il processo è in esecuzione nell'account Data Lake Analytics.
Finalizing (Finalizzazione): il processo è in fase di completamento, ad esempio, nella fase di finalizzazione del file.
Il processo può avere esito negativo in ogni fase. Ad esempio, possono verificarsi errori di compilazione nella fase di preparazione, errori di timeout nella fase di inserimento in coda, errori di esecuzione nella fase di esecuzione e così via.
Basic Information
Le informazioni di base sui processi vengono visualizzate nella parte inferiore del pannello di riepilogo del processo.
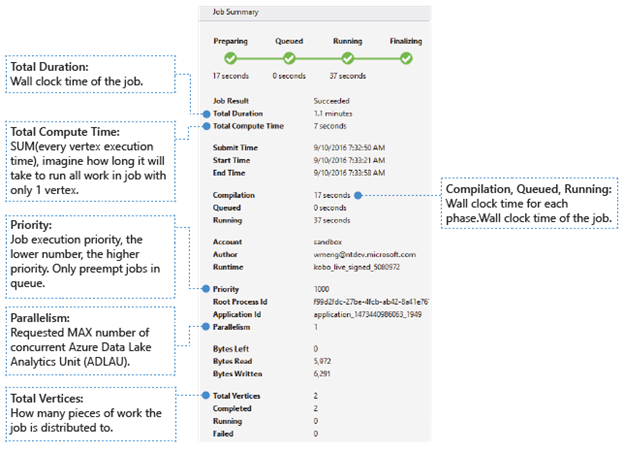
- Job Result (Risultato processo): indica l'esito positivo o negativo. Il processo potrebbe non riuscire in ogni fase.
- Total Duration (Durata totale): il tempo reale tra l'ora di invio e l'ora di fine.
- Total Compute Time (Tempo di calcolo totale): la somma del tempo di esecuzione di ogni vertice; questo valore può essere considerato come il tempo di esecuzione del processo in un solo vertice. Per altre informazioni sul vertice, fare riferimento all'opzione Total Vertices (Totale vertici).
- Submit Time/Start Time/End Time: (Ora di invio/Ora di inizio/Ora di fine): ora in cui il servizio Data Lake Analytics riceve l'invio di un processo/avvia l'esecuzione del processo/termina il processo con esito positivo o negativo.
- Compilation/Queued/Running (Compilazione/In coda/In esecuzione): il tempo reale trascorso durante la fase di preparazione/inserimento in coda/esecuzione.
- Account: l'account Data Lake Analytics usato per l'esecuzione del processo.
- Author (Autore): l'utente che ha inviato il processo; può essere l'account di una persona reale o un account di sistema.
- Priority (Priorità): la priorità del processo. Più è basso il numero, maggiore sarà la priorità. Interessa solo la sequenza di processi in coda. L'impostazione di una priorità più alta non comporta l'interruzione dell'esecuzione dei processi.
- Parallelismo: numero massimo richiesto di unità di Data Lake Analytics di Azure simultanee, note anche come vertici. Attualmente, un vertice è uguale a una macchina virtuale con due core virtuali e 6 GB di RAM, anche se questo potrebbe essere aggiornato in futuro Data Lake Analytics aggiornamenti.
- Bytes Left (Byte restanti): byte da elaborare fino al completamento del processo.
- Bytes read/written (Byte letti/scritti): byte che sono stati letti/scritti dopo l'avvio del processo.
- Total vertices (Totale vertici): il processo è suddiviso in elementi di lavoro e ogni elemento è chiamato vertice. Questo valore descrive il numero di elementi di lavoro che costituiscono il processo. È possibile considerare un vertice come un'unità di processo di base, nota anche come unità di Data Lake Analytics di Azure (ADLAU) e i vertici possono essere eseguiti in parallelo.
- Completed/Running/Failed (Completati/In esecuzione/Non riusciti): indica il numero di vertici completati, in esecuzione o non riusciti. I vertici possono avere esito negativo a causa di errori di sistema o del codice utente, ma il sistema tenta automaticamente di eseguire i vertici più volte. Se l'esito è negativo dopo questi tentativi, tutto il processo avrà esito negativo.
Grafico del processo
Uno script SQL U rappresenta la logica di trasformazione dei dati di input in dati di output. Lo script viene compilato e ottimizzato in un piano di esecuzione fisico in fase di preparazione. Il grafico del processo mostra il piano di esecuzione fisico. Il diagramma seguente illustra il processo:
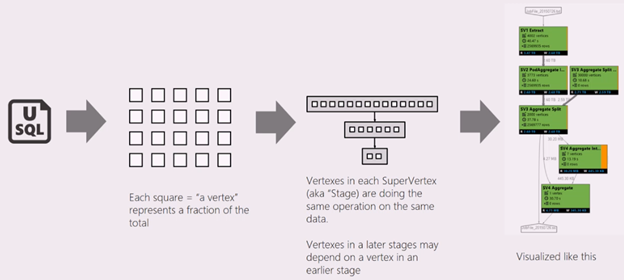
Un processo è suddiviso in più elementi di lavoro. Ogni elemento di lavoro è chiamato vertice. I vertici sono raggruppati come Super Vertex (noto anche come fase) e visualizzati come grafo del processo. Le etichette di colore verde nel grafico del processo indicano le fasi.
Ogni vertice raggruppato in una fase esegue lo stesso tipo di lavoro con blocchi diversi degli stessi dati. Ad esempio, se si dispone di un file con dati one-TB e sono presenti centinaia di vertici che leggono, ognuna delle quali legge un blocco. Questi vertici vengono raggruppati nella stessa fase e svolgono lo stesso lavoro su parti diverse dello stesso file di input.
-
In una specifica fase, l'etichetta riporta alcuni numeri.
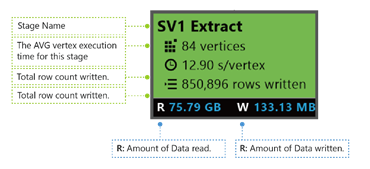
SV1 Extract (Estrazione SV1): il nome di una fase, indicato da un numero e dal metodo dell'operazione.
84 vertices (84 vertici): il conteggio totale di vertici in questa fase. La figura indica il numero di pezzi di lavoro divisi in questa fase.
12.90 s/vertex (12,90 s/vertice): il tempo medio di esecuzione di vertici per questa fase. Questo valore viene calcolato da SUM (tempo di esecuzione di ogni vertice)/(conteggio totale vertici). Se si assegnassero tutti i vertici eseguiti in parallelismo, l'intera fase verrebbe completata in 12,90 s. Se quindi tutto il lavoro in questa fase fosse eseguito in serie, il valore sarebbe numero vertici * tempo AVG.
850,895 rows written (850,895 righe scritte): il conteggio totale delle righe scritte in questa fase.
R/W (L/S): la quantità di dati letti/scritti in questa fase, espressa in byte.
I colori usati nella fase indicano lo stato dei vertici.
- Il verde indica che il vertice è riuscito.
- L'arancione indica che sono stati eseguiti nuovi tentativi per il vertice. Il vertice non ha avuto esito positivo, ma il sistema ha eseguito automaticamente un nuovo tentativo riuscito e la fase è stata completata correttamente. Se i nuovi tentativi non riescono, il colore diventa rosso e l'intero processo risulta non riuscito.
- Il rosso indica l'esito negativo, ovvero il sistema ha eseguito più tentativi non riusciti per un determinato vertice. Questo scenario causa l'esito negativo dell'intero processo.
- Il blu indica che un determinato vertice è in esecuzione.
- Il bianco indica che il vertice è in attesa. Il vertice potrebbe essere in attesa di essere pianificato una volta che un ADLAU diventa disponibile o potrebbe essere in attesa di input perché i dati di input potrebbero non essere pronti.
Posizionare il cursore del mouse vicino a uno stato per ottenere altri dettagli sulla fase:
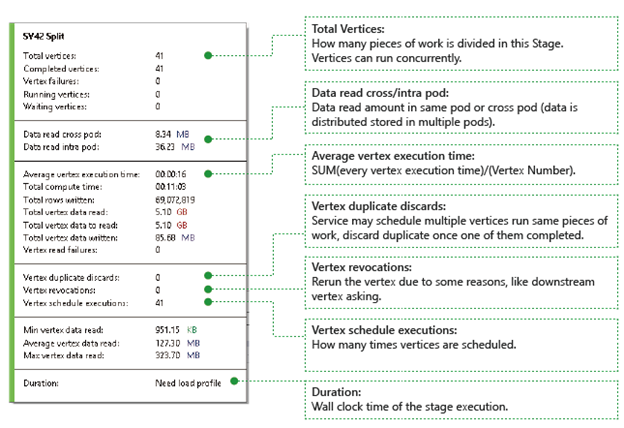
Vertices (Vertici): descrive i dettagli relativi ai vertici, ad esempio il numero totale di vertici, il numero di vertici completati, non riusciti, ancora in esecuzione o in attesa e così via.
Data read cross/intra pod (Lettura dati tra pod/nel pod): i file e i dati vengono archiviati in più pod nel file system distribuito. Il valore qui descrive la quantità di dati letti nello stesso pod o tra più pod.
Total Compute Time (Tempo di calcolo totale): la somma del tempo di esecuzione di ogni vertice nella fase; questo valore può essere considerato come il tempo di esecuzione se tutto il lavoro nella fase fosse eseguito in un solo vertice.
Data and rows written/read (Dati e righe scritti/letti): la quantità di dati o righe letti/scritti o che devono essere letti.
Vertex read failures (Errori di lettura vertici): descrive il numero di vertici con esito negativo durante la lettura dei dati.
Elimina i duplicati dei vertici: se un vertice viene eseguito troppo lentamente, il sistema potrebbe pianificare più vertici per eseguire lo stesso lavoro. I vertici ridondanti verranno eliminati al termine di uno dei vertici. Registra il numero di vertici eliminati come duplicati nella fase.
Vertex revocations (Revoche vertici): il vertice è stato completato, ma verrà eseguito di nuovo in un secondo momento per qualche motivo. Ad esempio, se il vertice di downstream perde i dati di input intermedi, verrà chiesto di eseguire di nuovo il vertice di upstream.
Vertex schedule executions (Esecuzioni pianificazione vertici): il tempo totale per cui i vertici sono stati pianificati.
Min/Average/Max Vertex data read (Dati vertici min/medi/max letti): la quantità minima/media/massima di dati letti di ogni vertice.
Duration (Durata): il tempo reale di una fase; è necessario caricare il profilo per visualizzare questo valore.
Riproduzione del processo
Data Lake Analytics esegue processi e archivia i vertici che eseguono informazioni sui processi, ad esempio quando i vertici vengono avviati, arrestati, non riusciti e come vengono ritentati e così via. Tutte le informazioni vengono registrate automaticamente nell'archivio query e archiviate nel relativo profilo di processo. È possibile scaricare il profilo del processo tramite Carica profilo nella visualizzazione processo; è possibile esaminare la riproduzione del processo dopo avere scaricato il profilo del processo.
Il processo di riproduzione è una visualizzazione di sintesi delle operazioni eseguite nel cluster. Consente di controllare lo stato di avanzamento del processo e rilevare visivamente eventuali colli di bottiglia o anomalie delle prestazioni in un periodo molto breve, in genere inferiore a 30 secondi.
Visualizzazione della mappa termica del processo
È possibile selezionare la mappa termica del processo tramite l'elenco a discesa di visualizzazione nel grafico del processo.
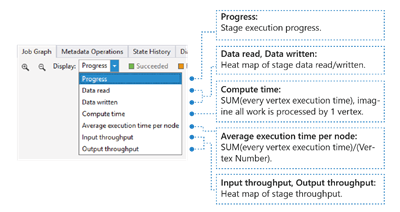
Mostra la mappa termica di I/O, del tempo e della velocità effettiva di un processo, consentendo di individuare il punto in cui il processo impiega la maggior parte del tempo o se si tratta di un processo associato a operazioni di I/O e così via.
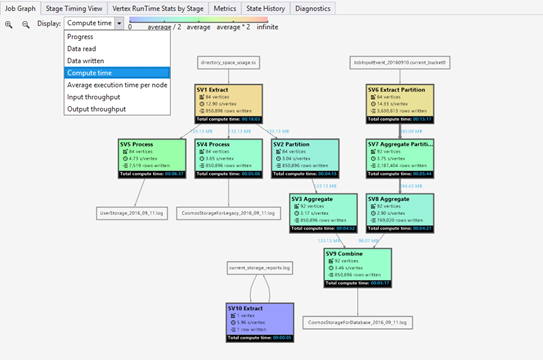
- Progress (Stato): lo stato di esecuzione del processo: vedere i dettagli in informazioni sulla fase.
- Data read/written (Dati letti/scritti): la mappa termica dei dati totali letti/scritti in ogni fase.
- Tempo di calcolo: mappa termica di SUM (ogni tempo di esecuzione dei vertici), è possibile considerare quanto tempo sarebbe necessario se tutto il lavoro nella fase venga eseguito con un solo vertice.
- Average execution time per node (Tempo medio di esecuzione per ogni nodo): la mappa termica di SUM (tempo di esecuzione di ogni vertice)/(numero di vertici). Se quindi si assegnassero tutti i vertici eseguiti in parallelismo, l'intera fase verrebbe completata in questo intervallo di tempo.
- Input/Output throughput (Velocità effettiva di input/output): la mappa termica della velocità effettiva di input/output di ogni fase; consente di verificare se il processo è associato a operazioni di I/O.
-
Operazioni sui metadati
È possibile eseguire alcune operazioni sui metadati nello script U-SQL, ad esempio creare un database, eliminare una tabella e così via. Queste operazioni vengono visualizzate in Operazione metadati dopo la compilazione. È possibile trovare asserzioni, creare entità, eliminare le entità qui.

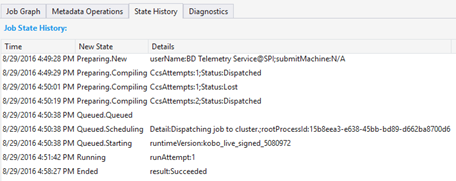
Cronologia dello stato
Nel riepilogo del processo viene visualizzata la cronologia dello stato, ma qui sono disponibili maggiori dettagli. È possibile trovare informazioni dettagliate, ad esempio quando il processo è stato preparato, inserito in coda, avviato in esecuzione e terminato. È anche possibile trovare il numero di volte per cui il processo è stato compilato (CcsAttempts: 1), quando il processo è stato inviato effettivamente al cluster (Detail: Dispatching job to cluster - Dettaglio: Invio del processo al cluster) e così via.
Diagnostica
Lo strumento diagnostica automaticamente l'esecuzione del processo Si riceveranno avvisi quando si verificano alcuni errori o problemi di prestazioni nei processi. Si noti che è necessario scaricare il profilo per ottenere informazioni complete qui.
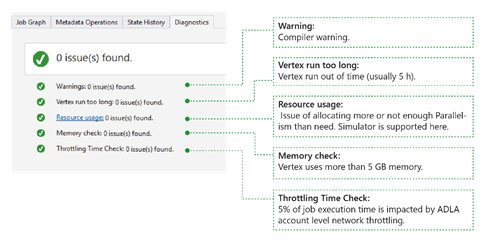
- Warnings (Avvisi): viene visualizzato un avviso del compilatore. È possibile selezionare il collegamento "x issue(s)" per avere altri dettagli una volta visualizzato l'avviso.
- Vertex viene eseguito troppo a lungo: se un vertice esaurisce il tempo (ad esempio 5 ore), i problemi verranno trovati qui.
- Resource usage (Uso risorse): se il parallelismo assegnato è maggiore o minore rispetto al valore necessario, i problemi vengono indicati qui. È anche possibile selezionare Utilizzo risorse per visualizzare altri dettagli ed eseguire scenari di simulazione per trovare un'allocazione migliore delle risorse (per altri dettagli, vedere questa guida).
- Memory check (Controllo memoria): se uno dei vertici usa più di 5 GB di memoria, i problemi vengono visualizzati qui. L'esecuzione del processo potrebbe essere terminata dal sistema se usa più memoria rispetto alla limitazione del sistema.
Dettagli processo
Mostra informazioni dettagliate sul processo, inclusi gli script, le risorse e la visualizzazione esecuzione vertici.
Script
Lo script SQL U del processo viene archiviato nell'archivio query. È possibile visualizzare lo script U-SQL originale e inviarlo di nuovo, se necessario.
Risorse
Consente di trovare gli output di compilazione del processo archiviati nell'archivio query. Ad esempio, è possibile trovare "algebra.xml" che viene usato per mostrare il grafico del processo, l'assembly registrato e così via.
Vertex execution view (Visualizzazione esecuzioni vertici)
Mostra i dettagli di esecuzione dei vertici. Il profilo processo archivia ogni log di esecuzione dei vertici, ad esempio dati totali letti/scritti, runtime, stato e così via. Tramite questa visualizzazione è possibile ottenere altri dettagli sulla modalità di esecuzione di un processo. Per altre informazioni vedere Usare la visualizzazione esecuzioni di vertici in Azure Data Lake Tools per Visual Studio.
Passaggi successivi
- Per registrare informazioni di diagnostica, vedere Accesso ai log di diagnostica per Azure Data Lake Analytics
- Per visualizzare una query più complessa, vedere Analizzare i log del sito Web mediante Azure Data Lake Analytics.
- Per usare la visualizzazione esecuzioni vertici, vedere Usare la visualizzazione esecuzioni vertici in Azure Data Lake Tools per Visual Studio