Archiviazione vettoriale in Ricerca di intelligenza artificiale di Azure
Ricerca di intelligenza artificiale di Azure offre archiviazione vettoriale e configurazioni per la ricerca vettoriale e la ricerca ibrida. Il supporto viene implementato a livello di campo, il che significa che è possibile combinare i campi vettoriali e non di filtro nello stesso corpus di ricerca.
I vettori vengono archiviati in un indice di ricerca. Usare l'API REST Create Index o un metodo azure SDK equivalente per creare l'archivio vettoriale.
Le considerazioni per l'archiviazione vettoriale includono i punti seguenti:
- Progettare uno schema per adattarsi al caso d'uso in base al modello di recupero vettoriale previsto.
- Stimare le dimensioni dell'indice e controllare la capacità del servizio di ricerca.
- Gestire un archivio vettoriale
- Proteggere un archivio vettoriale
Modelli di recupero vettoriale
In Ricerca di intelligenza artificiale di Azure sono disponibili due modelli per l'uso dei risultati della ricerca.
Ricerca generativa. I modelli linguistici formulano una risposta alla query dell'utente usando i dati di Ricerca di intelligenza artificiale di Azure. Questo modello include un livello di orchestrazione per coordinare le richieste e mantenere il contesto. In questo modello, i risultati della ricerca vengono inseriti nei flussi di richiesta, ricevuti da modelli di chat come GPT e Text-Davinci. Questo approccio si basa sull'architettura rag (Retrieval Augmented Generation), in cui l'indice di ricerca fornisce i dati di base.
Ricerca classica con una barra di ricerca, una stringa di input di query e risultati visualizzati. Il motore di ricerca accetta ed esegue la query vettoriale, formula una risposta ed esegue il rendering di tali risultati in un'app client. In Ricerca di intelligenza artificiale di Azure i risultati vengono restituiti in un set di righe bidimensionale ed è possibile scegliere i campi da includere nei risultati della ricerca. Poiché non esiste un modello di chat, è previsto che si popola l'archivio vettoriale (indice di ricerca) con contenuto non visibile nella risposta. Anche se il motore di ricerca corrisponde ai vettori, è consigliabile usare valori non di filtro per popolare i risultati della ricerca. Le query vettoriali e le query ibride coprono i tipi di richieste di query che è possibile formulare per scenari di ricerca classici.
Lo schema dell'indice deve riflettere il caso d'uso principale. La sezione seguente evidenzia le differenze nella composizione dei campi per le soluzioni create per l'intelligenza artificiale generativa o la ricerca classica.
Schema di un archivio vettoriale
Uno schema di indice per un archivio vettoriale richiede un nome, un campo chiave (stringa), uno o più campi vettoriali e una configurazione vettoriale. I campi non di filtro sono consigliati per le query ibride o per la restituzione di contenuto leggibile verbatim che non deve passare attraverso un modello linguistico. Per istruzioni sulla configurazione del vettore, vedere Creare un archivio vettoriale.
Configurazione dei campi vettoriali di base
I campi vettoriali sono distinti in base al tipo di dati e alle proprietà specifiche del vettore. Ecco l'aspetto di un campo vettoriale in una raccolta di campi:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
I campi vettoriali sono di tipo Collection(Edm.Single).
I campi vettoriali devono essere ricercabili e recuperabili, ma non possono essere filtrati, visualizzabili o ordinabili oppure avere analizzatori, normalizzatori o assegnazioni di mappe sinonimiche.
I campi vettoriali devono essere dimensions impostati sul numero di incorporamenti generati dal modello di incorporamento. Ad esempio, text-embedding-ada-002 genera 1.536 incorporamenti per ogni blocco di testo.
I campi vettoriali vengono indicizzati usando algoritmi indicati da un profilo di ricerca vettoriale, definito altrove nell'indice e quindi non visualizzato nell'esempio. Per altre informazioni, vedere Configurazione della ricerca vettoriale.
Raccolta di campi per carichi di lavoro vettoriali di base
Gli archivi vettoriali richiedono più campi oltre ai campi vettoriali. Ad esempio, un campo chiave ("id" in questo esempio) è un requisito di indice.
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Altri campi, ad esempio il "content" campo, forniscono l'equivalente leggibile del "content_vector" campo. Se si usano modelli linguistici esclusivamente per la formulazione della risposta, è possibile omettere i campi di contenuto non di filtro, ma le soluzioni che inserisce i risultati della ricerca direttamente nelle app client devono avere contenuto non di filtro.
I campi dei metadati sono utili per i filtri, soprattutto se i metadati includono informazioni sull'origine del documento di origine. Non è possibile filtrare direttamente un campo vettoriale, ma è possibile impostare le modalità prefiltro o postfiltro per filtrare prima o dopo l'esecuzione della query vettoriale.
Schema generato dalla procedura guidata Importa e vettorizza dati
È consigliabile importare e vettorizzare i dati per i test di valutazione e modello di verifica. La procedura guidata genera lo schema di esempio in questa sezione.
La distorsione di questo schema è che i documenti di ricerca vengono creati intorno ai blocchi di dati. Se un modello linguistico formula la risposta, come in genere per le app RAG, si vuole uno schema progettato per i blocchi di dati.
La suddivisione in blocchi dei dati è necessaria per rimanere entro i limiti di input dei modelli linguistici, ma migliora anche la precisione nella ricerca di somiglianza quando le query possono essere confrontate con blocchi di contenuto più piccoli estratti da più documenti padre. Infine, se si usa la classificazione semantica, il ranker semantico ha anche limiti di token, che sono più facilmente soddisfatti se la suddivisione in blocchi di dati fa parte dell'approccio.
Nell'esempio seguente, per ogni documento di ricerca, è presente un id blocco, un blocco, un titolo e un campo vettore. Il chunkID e l'ID padre vengono popolati dalla procedura guidata, usando la codifica base 64 dei metadati BLOB (percorso). I blocchi e il titolo derivano dal contenuto BLOB e dal nome del BLOB. Solo il campo vettoriale viene generato completamente. È la versione vettorializzata del campo del blocco. Gli incorporamenti vengono generati chiamando un modello di incorporamento OpenAI di Azure fornito.
"name": "example-index-from-import-wizard",
"fields": [
{"name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Schema per le app di tipo RAG e chat
Se si progetta l'archiviazione per la ricerca generativa, è possibile creare indici separati per il contenuto statico indicizzato e vettorializzato e un secondo indice per le conversazioni che possono essere usate nei flussi di richiesta. Gli indici seguenti vengono creati dall'acceleratore chat-with-your-data-solution-accelerator .
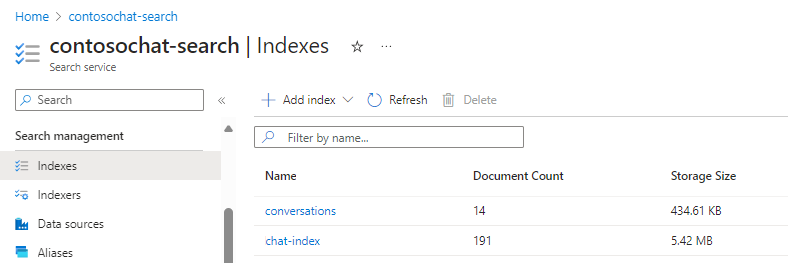
Campi dell'indice di chat che supportano l'esperienza di ricerca generativa:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Campi dell'indice delle conversazioni che supportano l'orchestrazione e la cronologia delle chat:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
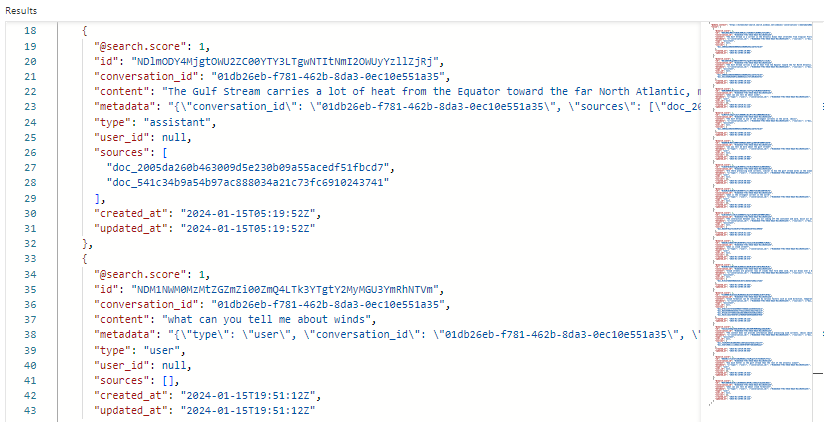
Ecco uno screenshot che mostra i risultati della ricerca in Esplora ricerche per l'indice delle conversazioni. Il punteggio di ricerca è 1,00 perché la ricerca non è stata qualificata. Si notino i campi esistenti per supportare l'orchestrazione e i flussi di richiesta. Un ID conversazione identifica una chat specifica. "type" indica se il contenuto proviene dall'utente o dall'assistente. Le date vengono usate per escludere le chat dalla cronologia.
Struttura fisica e dimensioni
In Ricerca di intelligenza artificiale di Azure la struttura fisica di un indice è in gran parte un'implementazione interna. È possibile accedere al relativo schema, caricare ed eseguire query sul relativo contenuto, monitorarne le dimensioni e gestire la capacità, ma i cluster stessi (indici invertiti e vettoriali) vengono gestiti internamente da Microsoft.
Le dimensioni e la sostanza di un indice sono determinate da:
- Quantità e composizione dei documenti
- Attributi nei singoli campi. Ad esempio, per i campi filtrabili è necessaria una maggiore archiviazione.
- Configurazione dell'indice, inclusa la configurazione vettoriale che specifica come vengono create le strutture di navigazione interne in base al fatto che si scelga HNSW o KNN completo per la ricerca di somiglianza.
Ricerca di intelligenza artificiale di Azure impone limiti all'archiviazione vettoriale, che consente di mantenere un sistema bilanciato e stabile per tutti i carichi di lavoro. Per rimanere al di sotto dei limiti, l'utilizzo del vettore viene monitorato e segnalato separatamente nella portale di Azure e a livello di codice tramite le statistiche di servizio e indice.
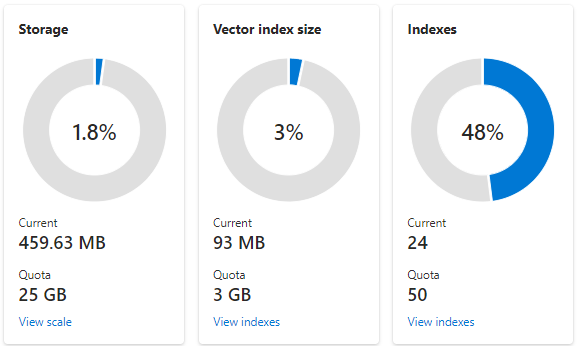
Lo screenshot seguente mostra un servizio S1 configurato con una partizione e una replica. Questo particolare servizio ha 24 indici di piccole dimensioni, con un campo vettore in media, ogni campo costituito da 1536 incorporamenti. Il secondo riquadro mostra la quota e l'utilizzo per gli indici vettoriali. Un indice vettoriale è una struttura di dati interna creata per ogni campo vettoriale. Di conseguenza, l'archiviazione per gli indici vettoriali è sempre una frazione dello spazio di archiviazione usato dall'indice nel complesso. Altri campi non di vettori e strutture di dati utilizzano il resto.
I limiti e le stime degli indici vettoriali sono trattati in un altro articolo, ma due punti da sottolineare in primo piano è che la quantità massima di archiviazione varia in base al livello di servizio e anche al momento della creazione del servizio di ricerca. I servizi dello stesso livello più recenti hanno una capacità significativamente maggiore per gli indici vettoriali. Per questi motivi, eseguire le azioni seguenti:
Controllare la data di distribuzione del servizio di ricerca. Se è stato creato prima del 3 aprile 2024, prendere in considerazione la creazione di un nuovo servizio di ricerca per una maggiore capacità.
Scegliere un livello scalabile se si prevedono fluttuazioni nei requisiti di archiviazione vettoriali. Il livello Basic è fisso in una partizione nei servizi di ricerca meno recenti. Si consideri Standard 1 (S1) e versioni successive per una maggiore flessibilità e prestazioni più veloci oppure creare un nuovo servizio di ricerca che usa limiti più elevati e più partizioni a ogni livello nillable.
Operazioni di base e interazione
Questa sezione presenta le operazioni di runtime del vettore, inclusa la connessione e la protezione di un singolo indice.
Nota
Quando si gestisce un indice, tenere presente che non è disponibile alcun portale o supporto API per lo spostamento o la copia di un indice. I clienti in genere puntano la soluzione di distribuzione dell'applicazione in un servizio di ricerca diverso (se si usa lo stesso nome di indice) o modificano il nome per creare una copia nel servizio di ricerca corrente e quindi compilarla.
Disponibilità continua
Un indice è immediatamente disponibile per le query non appena viene indicizzato il primo documento, ma non sarà completamente operativo fino a quando non vengono indicizzati tutti i documenti. Internamente, un indice viene distribuito tra le partizioni ed eseguito nelle repliche. L'indice fisico viene gestito internamente. L'indice logico viene gestito dall'utente.
Un indice è disponibile continuamente, senza possibilità di sospendere o portare offline. Poiché è progettato per l'operazione continua, gli aggiornamenti al relativo contenuto o aggiunte all'indice stesso vengono eseguiti in tempo reale. Di conseguenza, le query potrebbero restituire temporaneamente risultati incompleti se una richiesta coincide con un aggiornamento del documento.
Si noti che la continuità delle query esiste per le operazioni sui documenti (aggiornamento o eliminazione) e per le modifiche che non influiscono sulla struttura e sull'integrità esistenti dell'indice corrente, ad esempio l'aggiunta di nuovi campi. Se è necessario apportare aggiornamenti strutturali (modificando i campi esistenti), questi vengono in genere gestiti usando un flusso di lavoro drop-and-rebuild in un ambiente di sviluppo o creando una nuova versione dell'indice nel servizio di produzione.
Per evitare una ricompilazione dell'indice, alcuni clienti che apportano piccole modifiche scelgono di "versione" un campo creandone uno nuovo che coesiste insieme a una versione precedente. Nel corso del tempo, questo comporta contenuti orfani sotto forma di campi obsoleti o definizioni di analizzatori personalizzati obsoleti, in particolare in un indice di produzione costoso da replicare. È possibile risolvere questi problemi sugli aggiornamenti pianificati dell'indice come parte della gestione del ciclo di vita dell'indice.
Connessione dell'endpoint
Tutti gli indici vettoriali e le richieste di query hanno come destinazione un indice. Gli endpoint sono in genere uno dei seguenti:
| Endpoint | Connessione e controllo di accesso |
|---|---|
<your-service>.search.windows.net/indexes |
È destinata all'insieme degli indici. Utilizzato durante la creazione, l'elenco o l'eliminazione di un indice. Amministrazione diritti sono necessari per queste operazioni, disponibili tramite l'amministratore Chiavi API o ruolo Collaboratore ricerca. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
È destinata all'insieme documents di un singolo indice. Utilizzato durante l'esecuzione di query su un indice o un aggiornamento dati. Per le query, i diritti di lettura sono sufficienti e disponibili tramite chiavi API di query o un ruolo lettore dati. Per l'aggiornamento dei dati, sono necessari i diritti di amministratore. |
Come connettersi a Ricerca intelligenza artificiale di Azure
Assicurarsi di disporre delle autorizzazioni o di una chiave di accesso api. A meno che non si esegua una query su un indice esistente, sono necessari diritti di amministratore o un'assegnazione di ruolo collaboratore per gestire e visualizzare il contenuto in un servizio di ricerca.
Iniziare con il portale di Azure. La persona che ha creato il servizio di ricerca può visualizzare e gestire il servizio di ricerca, inclusa la concessione dell'accesso ad altri utenti tramite la pagina Controllo di accesso (IAM).
Passare ad altri client per l'accesso a livello di codice. Per i primi passaggi, è consigliabile seguire le guide introduttive e gli esempi:
Proteggere l'accesso ai dati vettoriali
Ricerca di intelligenza artificiale di Azure implementa la crittografia dei dati, le connessioni private per scenari senza Internet e le assegnazioni di ruolo per l'accesso sicuro tramite Microsoft Entra ID. La gamma completa di funzionalità di sicurezza aziendali è descritta in Sicurezza in Ricerca di intelligenza artificiale di Azure.
Gestire gli archivi vettoriali
Azure offre una piattaforma di monitoraggio che include la registrazione diagnostica e gli avvisi. È consigliabile seguire le procedure consigliate seguenti:
- Abilita registrazione diagnostica
- Impostare gli avvisi in Application Insights
- Analizzare le prestazioni delle query e degli indici