Partizionare Reliable Services di Service Fabric
Questo articolo offre un'introduzione ai concetti di base del partizionamento di Reliable Services di Azure Service Fabric. Il partizionamento abilita l'archiviazione dei dati nei computer locali in modo che i dati e le risorse di calcolo possano essere ridimensionati insieme.
Suggerimento
Un esempio completo del codice in questo articolo è disponibile in GitHub.
Partizionamento
Il partizionamento non è una procedura specifica di Service Fabric, bensì si tratta di un modello di base per la creazione di servizi scalabili. Più in generale, si può pensare al partizionamento come alla divisione dello stato (dati) e del calcolo in unità accessibili più piccole per migliorare la scalabilità e le prestazioni. Una forma molto conosciuta di partizionamento è il partizionamento dei dati, noto anche come partizionamento orizzontale.
Partizionamento dei servizi senza stato di Service Fabric
Per i servizi senza stato un partizionamento può essere considerato un'unità logica contenente una o più istanze di un servizio. La figura 1 illustra un servizio senza stato con cinque istanze distribuite in un cluster usando una partizione.
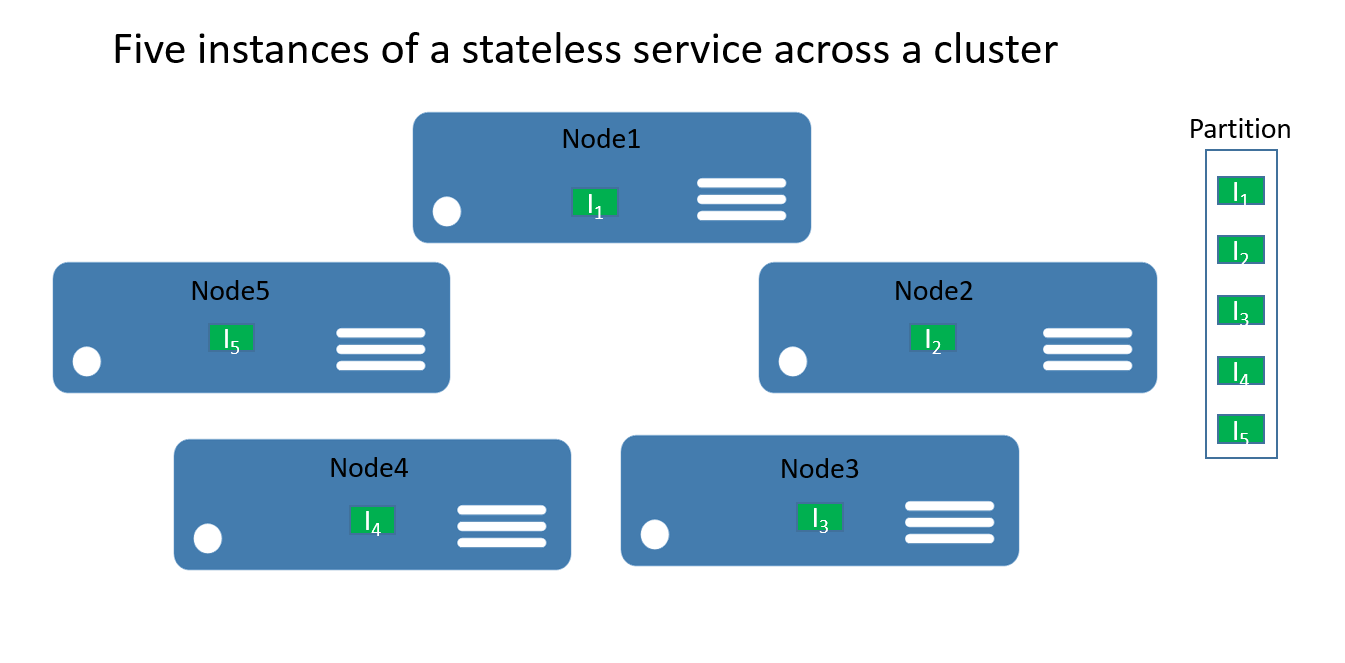
Sono disponibili due tipi di soluzioni di servizio senza stato. Il primo è un servizio che ne mantiene lo stato esternamente, ad esempio in un database in Azure SQL Database ,ad esempio un sito Web che archivia le informazioni e i dati della sessione. e la seconda include servizi solo di calcolo (ad esempio, una calcolatrice o l'anteprima di un'immagine) che non gestiscono alcuno stato persistente.
In entrambi i casi, il partizionamento di un servizio senza stato è uno scenario molto raro e la scalabilità e la disponibilità in genere si ottengono aggiungendo altre istanze. I soli casi in cui è opportuno considerare più partizioni per le istanze di un servizio senza stato sono quelli in cui è necessario soddisfare speciali richieste di routing,
ad esempio, quando gli utenti con ID compresi in un determinato intervallo devono essere gestiti solo da una particolare istanza del servizio. Un altro esempio di quando è possibile partizionare un servizio senza stato è quando si dispone di un back-end realmente partizionato (ad esempio, un database partizionato in database SQL) e si vuole controllare quale istanza del servizio deve scrivere nel database shard-o eseguire altre operazioni di preparazione all'interno del servizio senza stato che richiede le stesse informazioni di partizionamento usate nel back-end. Tali tipi di scenario possono essere risolti anche in modo diverso e non richiedono necessariamente il partizionamento del servizio.
La parte restante di questa procedura dettagliata riguarda i servizi con stato.
Partizionamento dei servizi con stato di Service Fabric
L'infrastruttura di servizi facilita lo sviluppo di servizi con stato scalabili offrendo un modo straordinario per partizionare lo stato (dati). Concettualmente, si può pensare al partizionamento di un servizio con stato come a un'unità di scala estremamente affidabile nelle repliche distribuite e bilanciate nei nodi del cluster.
Il partizionamento, nell'ambito dei servizi con stato di Service Fabric, fa riferimento al processo che determina come una particolare partizione del servizio sia responsabile di una parte dello stato completo del servizio. Come accennato in precedenza, la partizione è un set di repliche. Un'importante caratteristica dell'infrastruttura di servizi è che inserisce le partizioni in nodi diversi, consentendo loro di crescere fino al limite di risorse di un nodo. Quando i dati richiedono uno spazio maggiore, le partizioni crescono e Service Fabric le ribilancia tra i nodi assicurando un uso continuo ed efficiente delle risorse hardware.
Si supponga, ad esempio, di iniziare con un cluster a 5 nodi e un servizio configurato per includere 10 partizioni e una destinazione di tre repliche. In questo caso, Service Fabric bilancerebbe e distribuirebbe le repliche nel cluster e risulterebbero due repliche primarie per nodo. Se poi fosse necessario scalare orizzontalmente il cluster fino a 10 nodi, Service Fabric ribilancerebbe le repliche primarie tra tutti i 10 nodi. Analogamente, se si tornasse a 5 nodi, Service Fabric ribilancerebbe tutte le repliche tra i 5 nodi.
La figura 2 illustra la distribuzione di 10 partizioni prima e dopo il ridimensionamento del cluster.
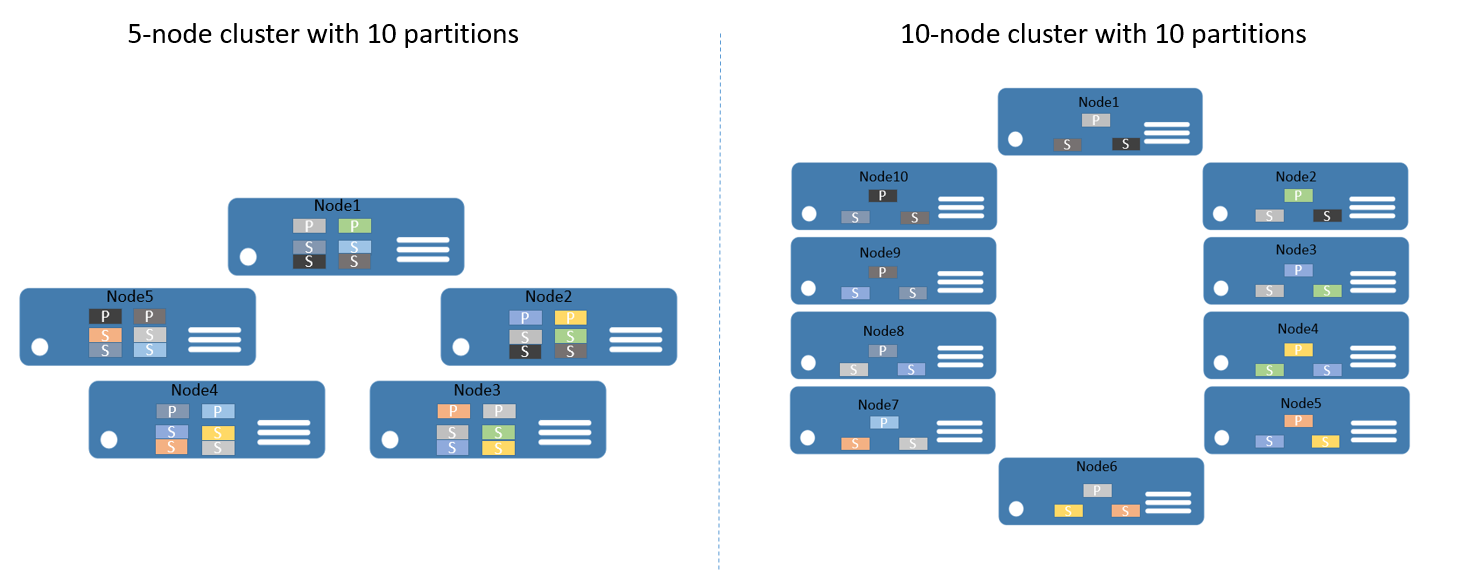
La scalabilità orizzontale è quindi garantita perché le richieste dei client vengono distribuite tra i computer, le prestazioni generali dell'applicazione vengono migliorate e la contesa in caso di accesso a blocchi di dati viene ridotta.
Pianificazione del partizionamento
Prima di implementare un servizio, è sempre consigliabile prendere in considerazione la strategia di partizionamento necessaria per aumentare il numero di istanze. Esistono diversi modi, ma tutti si concentrano su ciò che l'applicazione deve raggiungere. Nell'ambito di questo articolo verranno illustrati alcuni degli aspetti più importanti.
Un valido approccio consiste nel considerare la struttura dello stato che deve essere partizionato come primo passaggio.
Un semplice esempio viene riportato di seguito. Se si desidera creare un servizio per un sondaggio a livello di contea, è possibile creare una partizione per ogni città della contea. e quindi archiviare i voti per ogni persona della città nella partizione corrispondente a tale città. La figura 3 illustra un gruppo di persone e la città in cui risiedono.
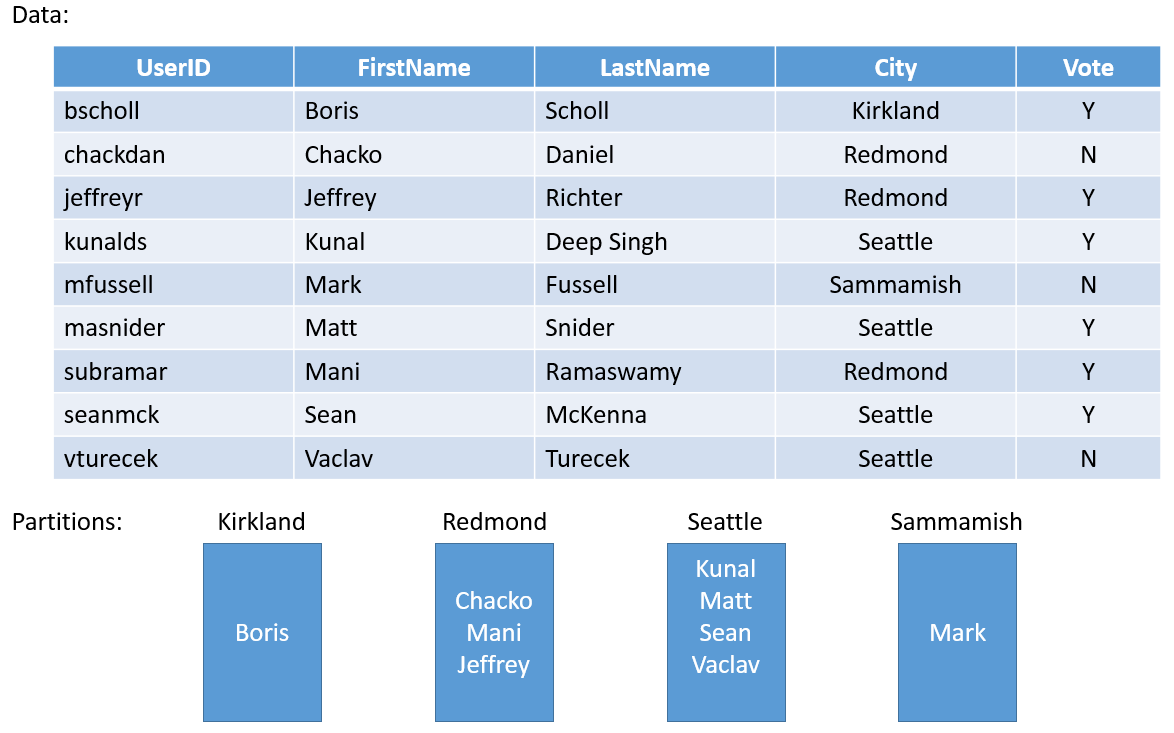
Poiché la popolazione delle città varia considerevolmente, si potrebbero avere alcune partizioni contenenti una grande quantità di dati (ad esempio, Seattle) e altre con dati in quantità molto piccole (ad esempio, Kirkland). Quale impatto hanno quindi partizioni con quantità di dati non uniformi?
Tornando all'esempio, si può osservare facilmente che la partizione con i voti per Seattle avrà più traffico di quella di Kirkland. Per impostazione predefinita, Service Fabric assicura che in ogni nodo sia presente all'incirca lo stesso numero di repliche primarie e secondarie, perciò si potrebbero avere nodi contenenti repliche che gestiscono più traffico e altre che gestiscono meno traffico. In un cluster è preferibile evitare le aree sensibili e non sensibili di questo genere.
Per evitarle, si consiglia di effettuare due azioni nell'ambito del partizionamento:
- Cercare di partizionare lo stato in modo che venga distribuito uniformemente tra tutte le partizioni.
- Segnalare il carico da ognuna delle repliche per il servizio. Per informazioni su come fare, vedere l'articolo relativo a metriche e carico. Service Fabric consente di segnalare il carico utilizzato dai servizi, ad esempio la quantità di memoria o il numero di record. In base alle metriche segnalate, Service Fabric rileva che alcune partizioni gestiscono carichi maggiori di altre e ribilancia il cluster spostando le repliche in nodi più adatti, per evitare il sovraccarico dei nodi in generale.
A volte non è possibile sapere quanti dati saranno presenti in una determinata partizione e quindi si consiglia di eseguire entrambe le operazioni, adottando prima una strategia di partizionamento che distribuisca i dati in modo uniforme nelle partizioni e poi creando un report del carico. Il primo metodo consente di evitare le situazioni descritte nell'esempio delle votazioni, il secondo invece di ridurre le differenze temporanee nell'accesso o nel carico nel corso del tempo.
Un altro aspetto della pianificazione delle partizioni è la scelta del numero corretto di partizioni con cui iniziare. Dal punto di vista di Service Fabric, nulla impedisce di iniziare con un numero di partizioni maggiore di quello anticipato per lo scenario. Infatti ipotizzare il numero massimo di partizioni è un valido approccio.
Raramente saranno necessarie più partizioni di quelle scelte inizialmente. Poiché non sarà più possibile modificare in seguito il conteggio delle partizioni, sarà necessario adottare alcuni approcci avanzati, ad esempio la creazione di una nuova istanza del servizio dello stesso tipo di servizio, e implementare una logica lato client che instradi le richieste all'istanza del servizio corretta in base alle conoscenze lato client che il codice client deve avere.
Un altro aspetto da considerare per la pianificazione del partizionamento sono le risorse del computer disponibili. Poiché lo stato deve essere accessibile e archiviato, è necessario rispettare i limiti seguenti:
- Larghezza di banda della rete
- Memoria di sistema
- Archiviazione su disco
Cosa accade quindi se si presentano vincoli relativi alle risorse in un cluster in esecuzione? Per soddisfare i nuovi requisiti, sarà sufficiente scalare orizzontalmente il cluster.
La guida alla pianificazione della capacità contiene indicazioni per determinare quanti nodi sono necessari al cluster.
Introduzione al partizionamento
Questa sezione descrive come iniziare a partizionare il servizio.
In primo luogo Service Fabric consente di scegliere tra tre schemi di partizione:
- Partizionamento con intervallo (noto anche come UniformInt64Partition).
- Partizionamento denominato. Le applicazioni che usano questo modello in genere hanno dati che possono essere inseriti in un bucket, in un set associato. Aree, codici postali, gruppi di clienti o altri limiti aziendali sono alcuni esempi comuni di campi dati usati come chiavi di partizione denominata.
- Partizionamento singleton. Le partizioni singleton in genere vengono usate quando il servizio non richiede alcun routing aggiuntivo. I servizi senza stato, ad esempio, usano questo schema di partizionamento per impostazione predefinita.
Gli schemi di partizionamento denominato e singleton sono forme particolari di partizioni con intervalli. Per impostazione predefinita, i modelli di Visual Studio per Service Fabric usano il partizionamento con intervallo perché è quello più comune e utile. La parte restante di questo articolo riguarda lo schema di partizionamento con intervallo.
Schema di partizionamento con intervallo
Viene usato per specificare un intervallo di numeri interi (identificato da una chiave minima e una chiave massima) e un numero di partizioni (n). Crea n partizioni, ognuna responsabile di un intervallo secondario non sovrapposto dell'intervallo di chiavi di partizione generale. Ad esempio, uno schema di partizionamento con intervallo con una chiave minima 0, una chiave massima 99 e un conteggio pari a 4 creerà quattro partizioni come mostrato di seguito.
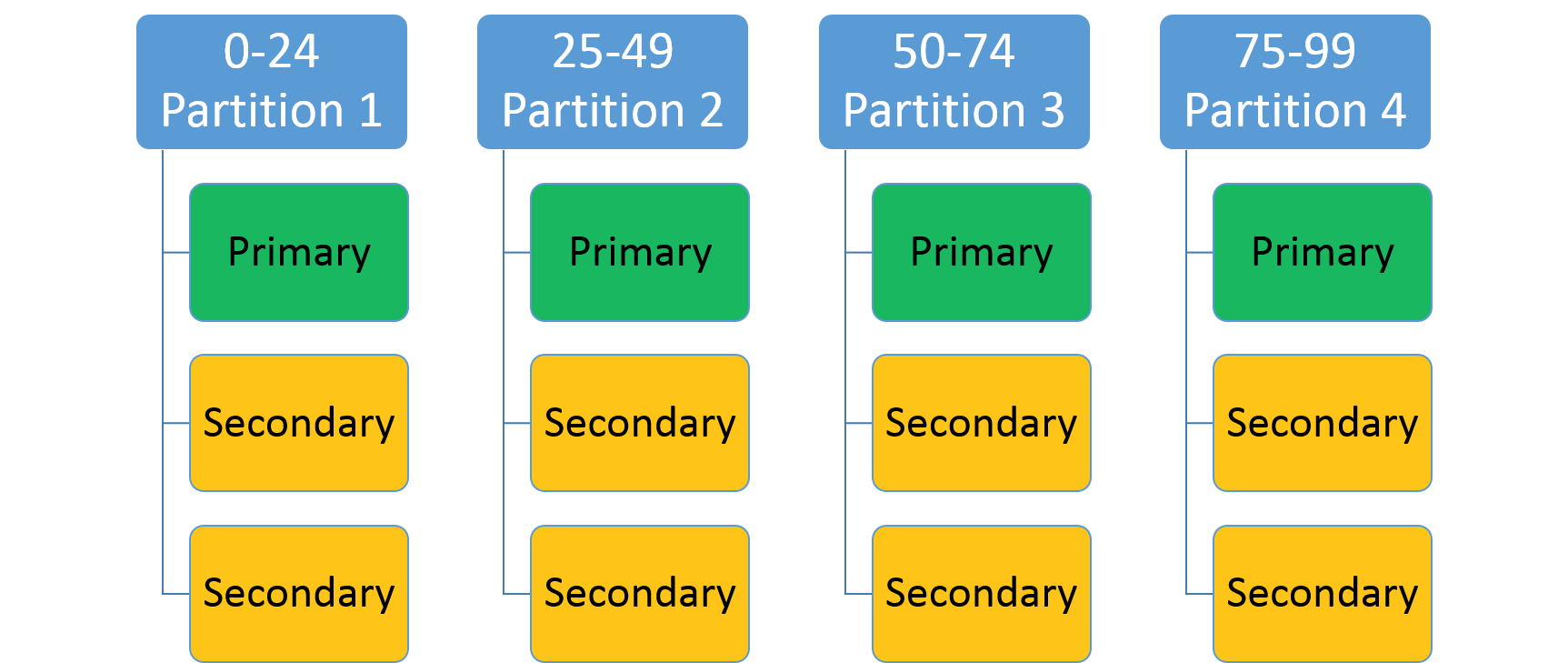
Un approccio comune consiste nel creare un hash basato su una chiave univoca nel set di dati. Sono esempi comuni di chiavi un Vehicle Identification Number (VIN), l'ID di un dipendente o una stringa univoca. Usando questa chiave univoca è possibile quindi generare un codice hash, modulo dell'intervallo di chiavi, da usare come chiave. È possibile specificare limiti massimi e minimi dell'intervallo di chiavi consentite.
Selezionare un algoritmo di hash
Una parte importante della generazione di un hash è rappresentata dalla selezione dell'algoritmo di hash. È necessario valutare se l'obiettivo sia raggruppare chiavi simili una accanto all'altra (hash sensibile alla località) o se l'attività debba essere distribuita su larga scala su tutte le partizioni (hash di distribuzione), che è l'obiettivo più comune.
Un valido algoritmo di hash di distribuzione si distingue perché è facile da elaborare, presenta pochi conflitti e distribuisce le chiavi in modo uniforme. FNV-1 è un valido esempio di algoritmo di hash efficiente.
Un'ottima risorsa per le scelte di algoritmi di codice di hash generali è rappresentata dalla pagina Wikipedia sulle funzioni hash.
Compilare un servizio con stato con più partizioni
Ora verrà creato il primo servizio con stato affidabile con più partizioni. In questo esempio si compilerà un'applicazione molto semplice in cui archiviare tutti i cognomi che iniziano con la stessa lettera nella stessa partizione.
Prima di scrivere il codice, considerare le partizioni e le chiavi di partizione. Sono necessarie 26 partizioni, una per ogni lettera dell'alfabeto, ma per quanto riguarda le chiavi minime e massime? Poiché è necessaria esattamente una partizione per ogni lettera, è possibile usare 0 come chiave minima e 25 come chiave massima, perché ogni lettera corrisponde alla propria chiave.
Nota
Questo è uno scenario semplificato, perché nella realtà la distribuzione non sarebbe uniforme. I cognomi che iniziano con la lettera "S" o "M" sono più comuni di quelli che iniziano con "X" o "Y".
Aprirenuovoprogettofile>>di Visual Studio>.
Nella finestra di dialogo Nuovo progetto scegliere l'applicazione Service Fabric.
Assegnare al progetto il nome "AlphabetPartitions".
Nella finestra di dialogo Create a Service (Crea un servizio) scegliere il servizio con stato e assegnargli il nome "Alphabet.Processing".
Impostare il numero di partizioni. Aprire il file ApplicationManifest.xml che si trova nella cartella ApplicationPackageRoot del progetto AlphabetPartitions e aggiornare il parametro Processing_PartitionCount a 26, come illustrato di seguito.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />È anche necessario aggiornare le proprietà LowKey e HighKey dell'elemento StatefulService in ApplicationManifest.xml come illustrato di seguito.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>Per rendere accessibile il servizio, aprire un endpoint su una porta aggiungendo l'elemento endpoint di ServiceManifest.xml (nella cartella PackageRoot) per il servizio Alphabet.Processing, come mostrato sotto:
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />Il servizio ora è configurato per l'ascolto di un endpoint interno con 26 partizioni.
In seguito è necessario eseguire l'override del metodo
CreateServiceReplicaListeners()della classe Processing.Nota
Per questo esempio, si presume che venga usato un semplice oggetto HttpCommunicationListener. Per ulteriori informazioni sulla comunicazione Reliable Service, vedere Modello di comunicazione Reliable Service.
Un modello consigliato per l'URL su cui è in ascolto una replica è il formato seguente:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}, che consente di configurare il listener di comunicazione perché rimanga in ascolto degli endpoint corretti e con questo modello.Poiché è possibile che più repliche di questo servizio siano ospitate sullo stesso computer, questo indirizzo deve essere univoco per la replica Questo è il motivo per cui l'ID di partizione e l'ID replica si trovano nell'URL. HttpListener può ascoltare più indirizzi nella stessa porta purché il prefisso URL sia univoco.
Il GUID aggiuntivo è presente per un caso avanzato in cui anche le repliche secondarie sono in ascolto delle richieste di sola lettura. In questo caso, è opportuno assicurarsi che venga usato un nuovo indirizzo univoco quando si passa dalla replica primaria a quelle secondarie per obbligare i client a risolvere nuovamente l'indirizzo. '+' viene usato come indirizzo qui in modo che la replica sia in ascolto su tutti gli host disponibili (IP, FQDN, localhost e così via) Il codice seguente mostra un esempio.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }È anche importante notare che l'URL pubblicato è leggermente diverso dal prefisso dell'URL di ascolto. L'URL in ascolto viene assegnato a HttpListener. L'URL pubblicato è l'URL che viene pubblicato nel servizio Naming dell'infrastruttura di servizi, usato per l'individuazione dei servizi. I client richiederanno questo indirizzo con questo servizio di individuazione. Poiché l'indirizzo ottenuto dai client deve avere l'IP o il nome FQDN effettivo del nodo per connettersi, è necessario sostituire "+" con l'IP o il nome FQDN del nodo, come mostrato sotto.
L'ultimo passaggio consiste nell'aggiungere la logica di elaborazione al servizio, come mostrato sotto.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestlegge i valori del parametro della stringa di query usato per chiamare la partizione e chiamaAddUserAsyncper aggiungere il cognome al dizionario attendibiledictionary.Ora si aggiungerà un servizio senza stato al progetto per verificare se sia possibile chiamare una determinata partizione.
Questo servizio viene usato come semplice interfaccia Web che accetta il cognome come parametro della stringa di query, determina la chiave di partizione e la invia al servizio Alphabet.Processing per l'elaborazione.
Nella finestra di dialogo Create a Service (Crea un servizio) scegliere il servizio senza stato e assegnargli il nome "Alphabet.Web", come illustrato di seguito.
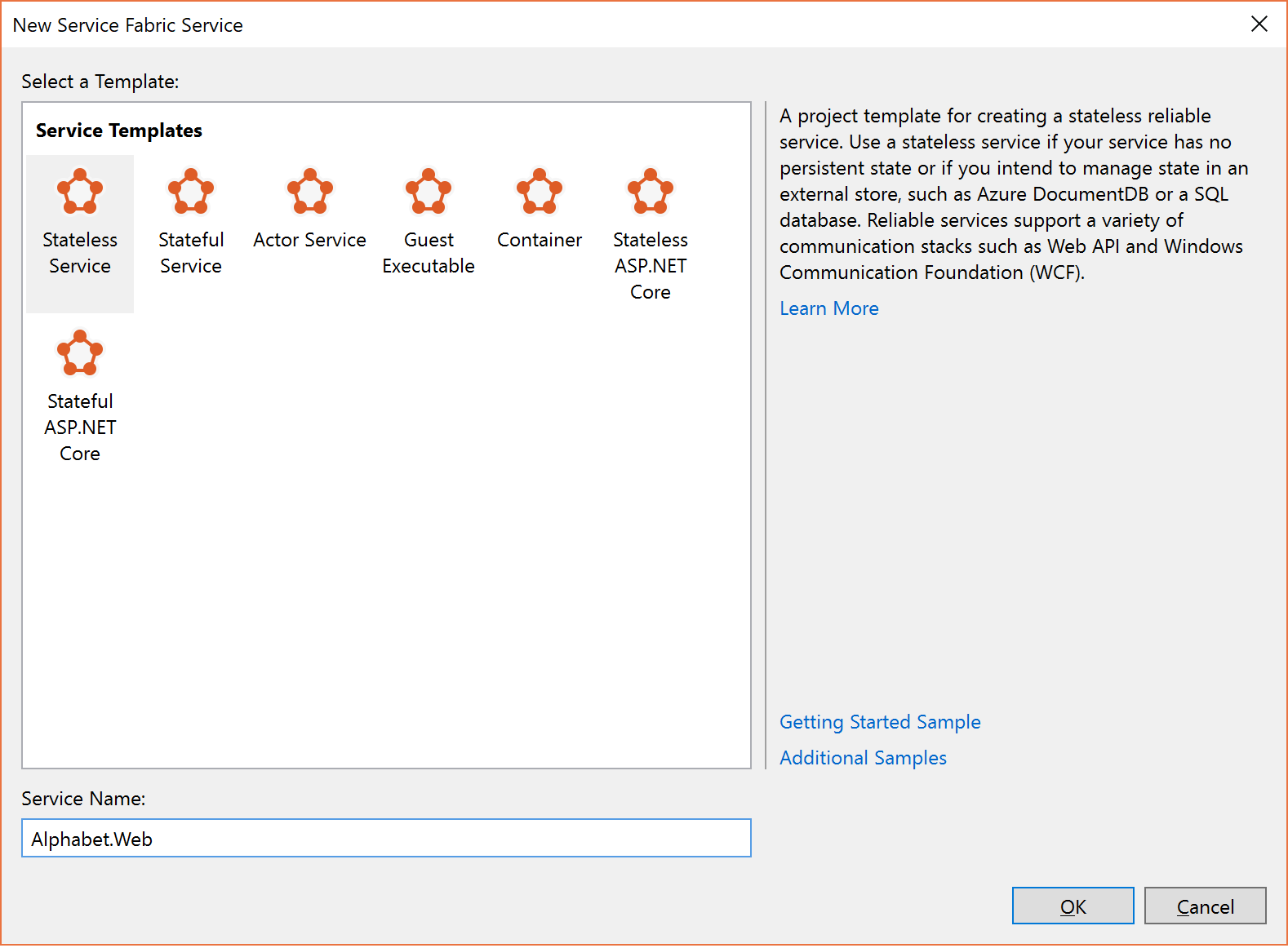 .
.Aggiornare le informazioni sull'endpoint nel file ServiceManifest.xml del servizio Alphabet.WebApi per aprire una porta, come mostrato sotto.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>È necessario restituire una raccolta di ServiceInstanceListener nella classe Web. Anche in questo caso è possibile scegliere di implementare un semplice HttpCommunicationListener.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Ora è necessario implementare la logica di elaborazione. HttpCommunicationListener chiama
ProcessInputRequestquando arriva una richiesta. Ora aggiungere il codice seguente.private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Analisi dettagliata: il codice legge la prima lettera del parametro della stringa di query
lastnamein un char. Quindi determina la chiave di partizione di questa lettera sottraendo il valore esadecimale diAdal valore esadecimale della prima lettera dei cognomi.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');Si ricordi che in questo esempio si usano 26 partizioni con una chiave per ogni partizione. A questo punto è necessario ottenere la partizione del servizio
partitionper la chiave usando il metodoResolveAsyncnell'oggettoservicePartitionResolver.servicePartitionResolverviene definito come mostrato di seguito.private readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();Il metodo
ResolveAsyncaccetta l'URI del servizio, la chiave di partizione e un token di annullamento come parametri. L'URI del servizio di elaborazione èfabric:/AlphabetPartitions/Processing. A questo punto è necessario ottenere l'endpoint della partizione.ResolvedServiceEndpoint ep = partition.GetEndpoint()Infine si compilano l'URL dell'endpoint e la stringa di query e si chiama il servizio di elaborazione.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);Una volta completata l'elaborazione, si scrive l'output.
L'ultimo passaggio consiste nel testare il servizio. Visual Studio usa i parametri dell'applicazione per la distribuzione locale e cloud. Per testare il servizio in locale con 26 partizioni, è necessario aggiornare il file
Local.xmlnella cartella ApplicationParameters del progetto AlphabetPartitions, come mostrato di seguito:<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>Al termine del processo di distribuzione, è possibile controllare il servizio e tutte le partizioni in Service Fabric Explorer.

Per testare la logica di partizionamento, immettere
http://localhost:8081/?lastname=somenamein un browser. Ogni cognome che inizia con la stessa lettera risulta archiviato nella stessa partizione.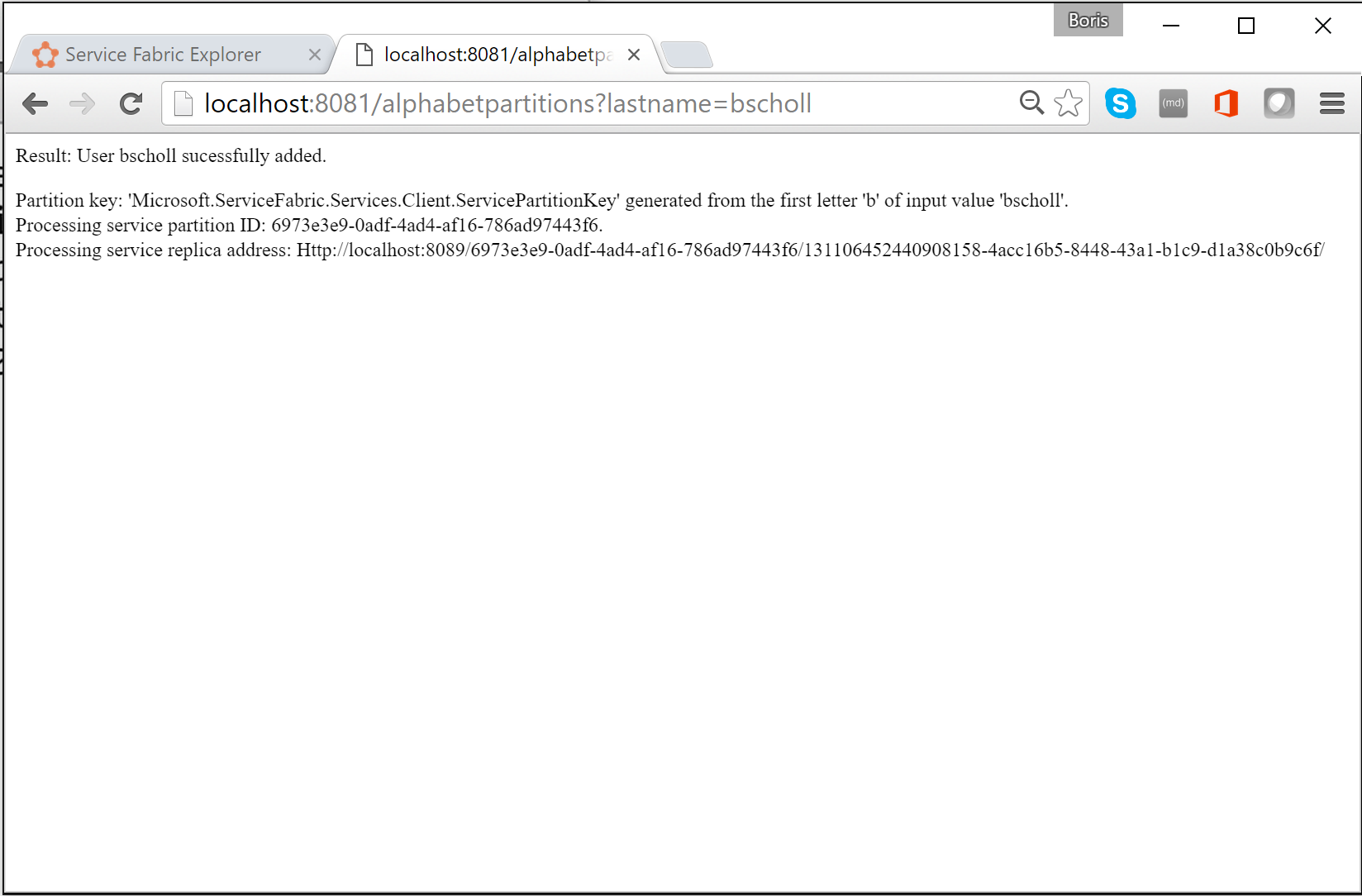
La soluzione completa del codice usato in questo articolo è disponibile qui: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Passaggi successivi
Altre informazioni sui servizi di Service Fabric: