Scenari comuni di diagnosi con Service Fabric
Questo articolo illustra gli scenari comuni affrontati dagli utenti nell'ambito del monitoraggio e della diagnostica con Service Fabric. Gli scenari presentati illustrano tutti i 3 livelli di Service Fabric: applicazione, cluster e infrastruttura. Ogni soluzione usa gli strumenti di monitoraggio di Azure, ovvero i log di Application Insights e Monitoraggio di Azure, per completare ogni scenario. I passaggi in ogni soluzione offrono agli utenti un'introduzione su come usare i log di Application Insights e Monitoraggio di Azure nel contesto di Service Fabric.
Nota
Questo articolo è stato aggiornato di recente in modo da usare il termine log di Monitoraggio di Azure anziché Log Analytics. I dati di log vengono comunque archiviati in un'area di lavoro Log Analytics e vengano ancora raccolti e analizzati dallo stesso servizio Log Analytics. Si sta procedendo a un aggiornamento della terminologia per riflettere meglio il ruolo dei log in Monitoraggio di Azure. Per informazioni dettagliate, vedere Modifiche della terminologia di Monitoraggio di Azure.
Prerequisiti e indicazioni
Le soluzioni in questo articolo useranno gli strumenti seguenti. È consigliabile installarli e configurarli:
- Application Insights con Service Fabric
- Abilitare Diagnostica di Azure nel cluster
- Configurare un'area di lavoro Log Analytics
- Agente di Log Analytics per tenere traccia dei contatori delle prestazioni
Come visualizzare le eccezioni non gestite nell'applicazione
Passare alla risorsa di Application Insights con cui l'applicazione è configurata.
Fare clic su Cerca in alto a sinistra, quindi fare clic sul filtro nel pannello successivo.
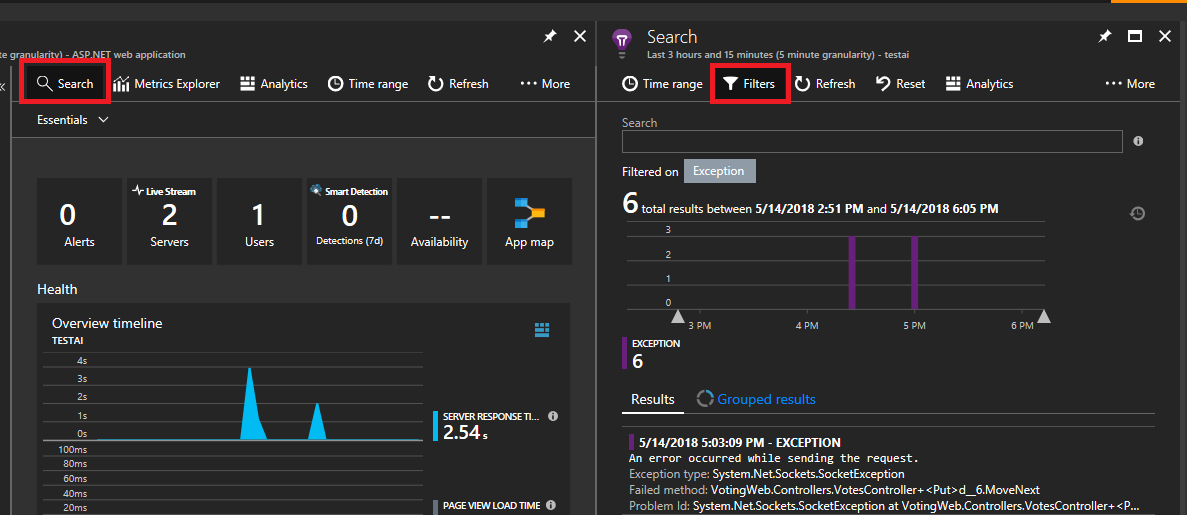
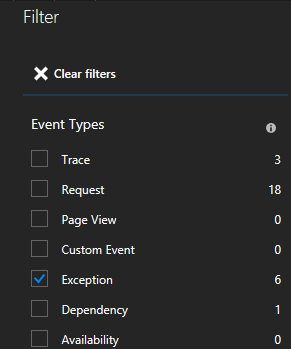
Verranno visualizzati molti tipi di eventi (tracce, richieste, eventi personalizzati). Scegliere "Eccezione" come filtro.
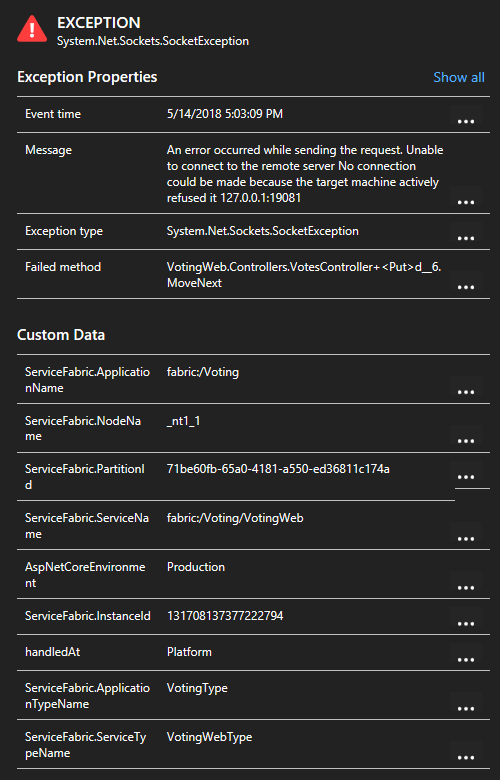
Facendo clic su un'eccezione nell'elenco, è possibile vedere altri dettagli, incluso il contesto del servizio se si usa Service Fabric Application Insights SDK.
Come visualizzare le chiamate HTTP usate nei servizi
Nella stessa risorsa di Application Insights è possibile filtrare in base alle "richieste" invece che alle eccezioni e visualizzare tutte le richieste effettuate
Se si usa Service Fabric Application Insights SDK, è possibile visualizzare una rappresentazione visiva della connessione tra i servizi e il numero di richieste con esito positivo e negativo. A sinistra fare clic su "Mappa delle applicazioni"
 delle
delle 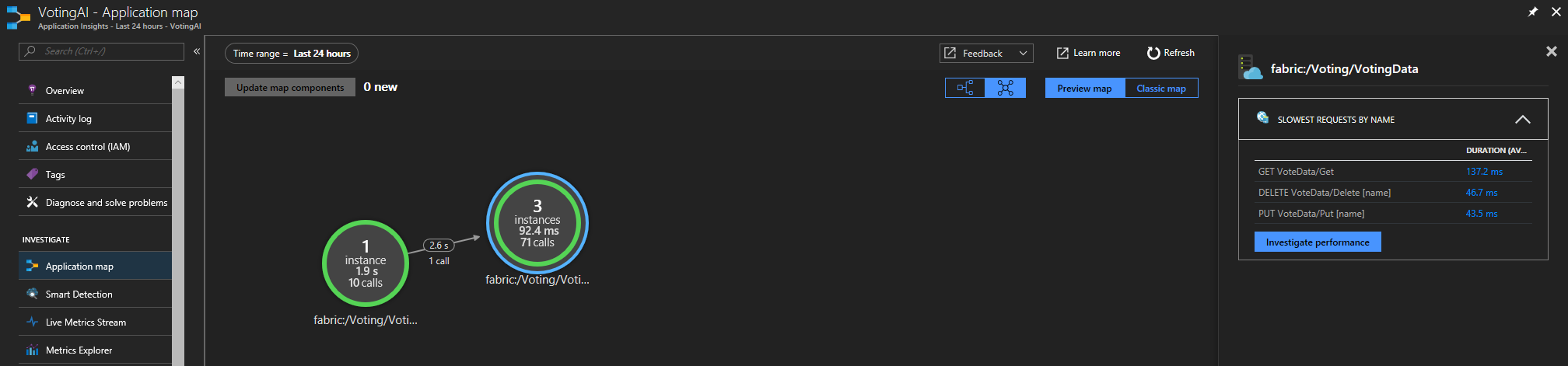
Per altre informazioni sulla mappa delle app, vedere la documentazione sulla mappa delle applicazioni
Come creare un avviso quando un nodo diventa inattivo
Il cluster di Service Fabric tiene traccia degli eventi dei nodi. Passare alla risorsa della soluzione Analisi Service Fabric denominata ServiceFabric(NameofResourceGroup)
Fare clic sul grafico nella parte inferiore del pannello intitolato "Riepilogo"
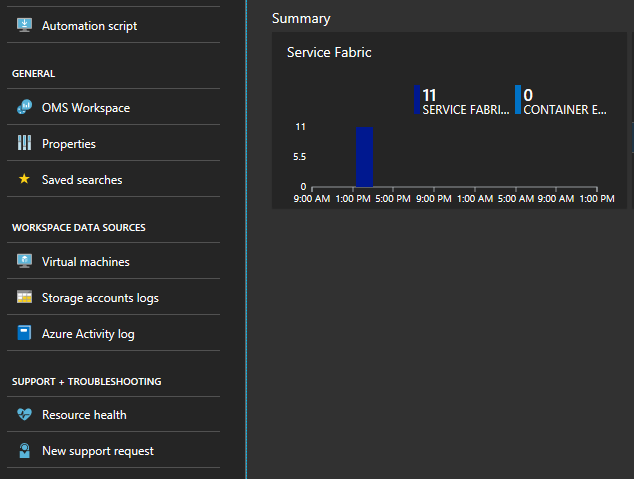
Sono disponibili molti grafici e riquadri con diverse metriche. Fare clic su uno dei grafici per passare alla ricerca log, dove è possibile cercare gli eventi del cluster o i contatori delle prestazioni.
Immettere la query seguente. Questi ID evento sono inclusi nella documentazione di riferimento sugli eventi dei nodi
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Fare clic su "Nuova regola di avviso" nella parte superiore. Da questo momento, ogni volta che arriva un evento basato su questa query, si riceverà un avviso con il metodo di comunicazione scelto.

Come essere avvisati dei ripristini dello stato precedente dell'aggiornamento dell'applicazione?
Nella stessa finestra di ricerca log di prima immettere la query seguente per i ripristini dello stato precedente dell'aggiornamento. Questi ID evento sono inclusi nella documentazione di riferimento sugli eventi dell'applicazione
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Fare clic su "Nuova regola di avviso" nella parte superiore. Da questo momento, ogni volta che arriva un evento basato su questa query, si riceverà un avviso.
Come visualizzare le metriche dei contenitori
Nella stessa visualizzazione con tutti i grafici si noteranno alcuni riquadri per le prestazioni dei contenitori. Sono necessari l'agente di Log Analytics e la soluzione Monitoraggio contenitori per popolare questi riquadri.
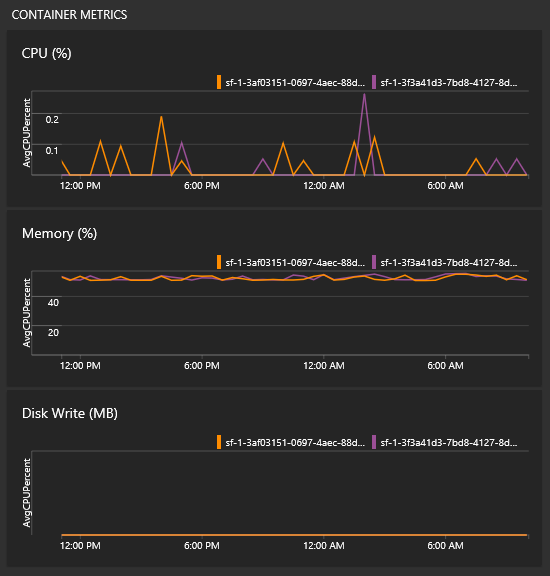
Nota
Per instrumentare i dati di telemetria dall'interno del contenitore, sarà necessario aggiungere il pacchetto nuget di Application Insights per i contenitori.
Come monitorare i contatori delle prestazioni
Dopo aver aggiunto l'agente di Log Analytics al cluster, è necessario aggiungere i contatori delle prestazioni specifici di cui si vuole tenere traccia. Passare alla pagina dell'area di lavoro Log Analytics nel portale. Nella pagina della soluzione la scheda dell'area di lavoro è nel menu a sinistra.
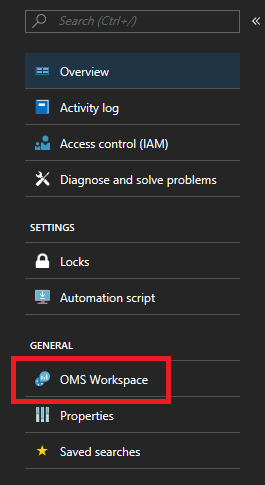
Nella pagina dell'area di lavoro fare clic su "Impostazioni avanzate" nello stesso menu a sinistra.
Fare clic su Contatori delle prestazioni di Windows dati > (contatori delle prestazioni di Data > Linux per i computer Linux) per iniziare a raccogliere contatori specifici dai nodi tramite l'agente di Log Analytics. Ecco alcuni esempi del formato dei contatori da aggiungere
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeNella guida introduttiva vengono usati i nomi di processo VotingData e VotingWeb, quindi il codice per tenere traccia di questi contatori sarà simile ai seguenti
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes
In questo modo sarà possibile visualizzare come l'infrastruttura gestisce i carichi di lavoro e impostare avvisi pertinenti in base all'utilizzo delle risorse. È ad esempio possibile impostare un avviso se l'utilizzo totale del processore è superiore al 90% o inferiore al 5%. Il nome del contatore usato in questo caso sarà "% Processor Time". A questo scopo, è possibile creare una regola di avviso per la query seguente:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Come tenere traccia delle prestazioni di Reliable Services e Actors
Per tenere traccia delle prestazioni di Reliable Services o Actors nelle applicazioni, è consigliabile raccogliere anche i contatori Actor di Service Fabric, Metodo Actor, Service e Metodo Service. Di seguito sono riportati alcuni esempi di contatori delle prestazioni di Reliable Service e Actor per la raccolta
Nota
Attualmente i contatori delle prestazioni in Service Fabric non possono essere raccolti dall'agente di Log Analytics, ma possono essere raccolti da altre soluzioni di diagnostica
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Fare clic su questi collegamenti per l'elenco completo dei contatori delle prestazioni per Reliable Services e Actors
Passaggi successivi
- Cercare errori comuni di attivazione del pacchetto di codice
- Configurare gli avvisi in AI per ricevere una notifica sulle modifiche apportate alle prestazioni o all'uso
- Rilevamento intelligente in Application Insights esegue un'analisi proattiva dei dati di telemetria che vengono inviati ad AI per avvisare l'utente in caso di potenziali problemi di prestazioni
- Altre informazioni sugli avvisi dei log di Monitoraggio di Azure per agevolare il rilevamento e la diagnostica.
- Per i cluster locali, i log di Monitoraggio di Azure offrono un Gateway, ovvero un proxy di inoltro HTTP, che può essere usato per inviare i dati ai log di Monitoraggio di Azure. Per altre informazioni, vedere Connettere computer senza accesso a Internet ai log di Monitoraggio di Azure usando il gateway Log Analytics
- Acquisire familiarità con le funzionalità di ricerca log ed esecuzione di query incluse nei log di Monitoraggio di Azure
- Per avere una panoramica più dettagliata dei log di Monitoraggio di Azure e dei vantaggi offerti, vedere la pagina che spiega che cosa sono i log di Monitoraggio di Azure