Aggregazione e raccolta di eventi con Diagnostica di Microsoft Azure
Quando si esegue un cluster Azure Service Fabric, è consigliabile raccogliere i log da tutti i nodi in una posizione centrale. Il salvataggio dei log in una posizione centrale semplifica l'analisi e la risoluzione di eventuali problemi nel cluster o nelle applicazioni e nei servizi in esecuzione nel cluster.
Un modo per caricare e raccogliere i log consiste nell'usare l'estensione Diagnostica di Microsoft Azure, che carica i log in Archiviazione di Azure e offre anche la possibilità di inviarli ad Azure Application Insights o Hub eventi. È anche possibile usare un processo esterno per leggere gli eventi dall'archiviazione e inserirli in un prodotto della piattaforma di analisi, ad esempio i log di Monitoraggio di Azure o un'altra soluzione di analisi dei log.
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Prerequisiti
In questo articolo vengono usati gli strumenti seguenti:
Eventi della piattaforma Service Fabric
Service Fabric offre alcuni canali di registrazione predefiniti. Tra questi, i canali seguenti vengono preconfigurati con l'estensione per inviare i dati di monitoraggio e diagnostica a una tabella di archiviazione o un'altra posizione:
- Eventi operativi: operazioni generali eseguite dalla piattaforma Service Fabric. Gli esempi includono la creazione di applicazioni e servizi, le modifiche allo stato dei nodi e informazioni sull'aggiornamento. Questi eventi vengono generati come log di Event Tracing for Windows (ETW)
- Eventi del modello di programmazione Reliable Actors
- Eventi relativi al modello di programmazione Reliable Services
Distribuire l'estensione Diagnostica tramite il portale
Il primo passaggio per la raccolta dei log consiste nel distribuire l'estensione Diagnostica nei nodi del set di scalabilità di macchine virtuali nel cluster Service Fabric. Questa estensione raccoglie i log in ogni VM e li carica nell'account di archiviazione specificato. La procedura seguente illustra come eseguire questa operazione per i cluster nuovi ed esistenti tramite il portale di Azure e i modelli di Azure Resource Manager.
Distribuire l'estensione Diagnostica nell'ambito della creazione del cluster tramite il portale di Azure
Quando si crea il cluster, nel passaggio di configurazione del cluster espandere le impostazioni facoltative e verificare che Diagnostica sia impostata su Attivato (impostazione predefinita).
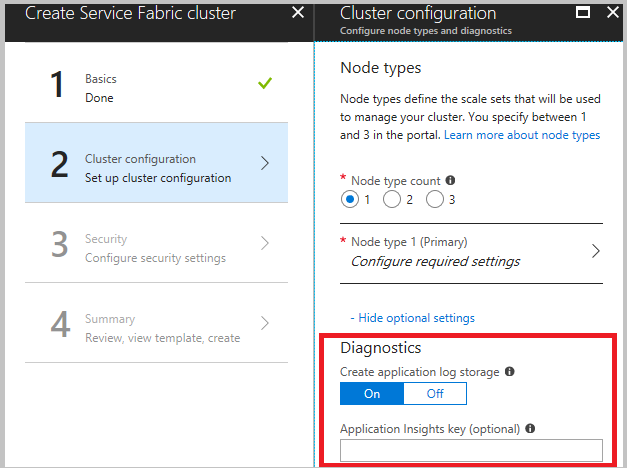
Si consiglia di scaricare il modello prima di fare clic su Crea nel passaggio finale. Per informazioni dettagliate, vedere Configurare un cluster di Service Fabric usando un modello di Azure Resource Manager. Il modello è necessario per apportare modifiche ai canali (elencati in precedenza) da cui raccogliere i dati.
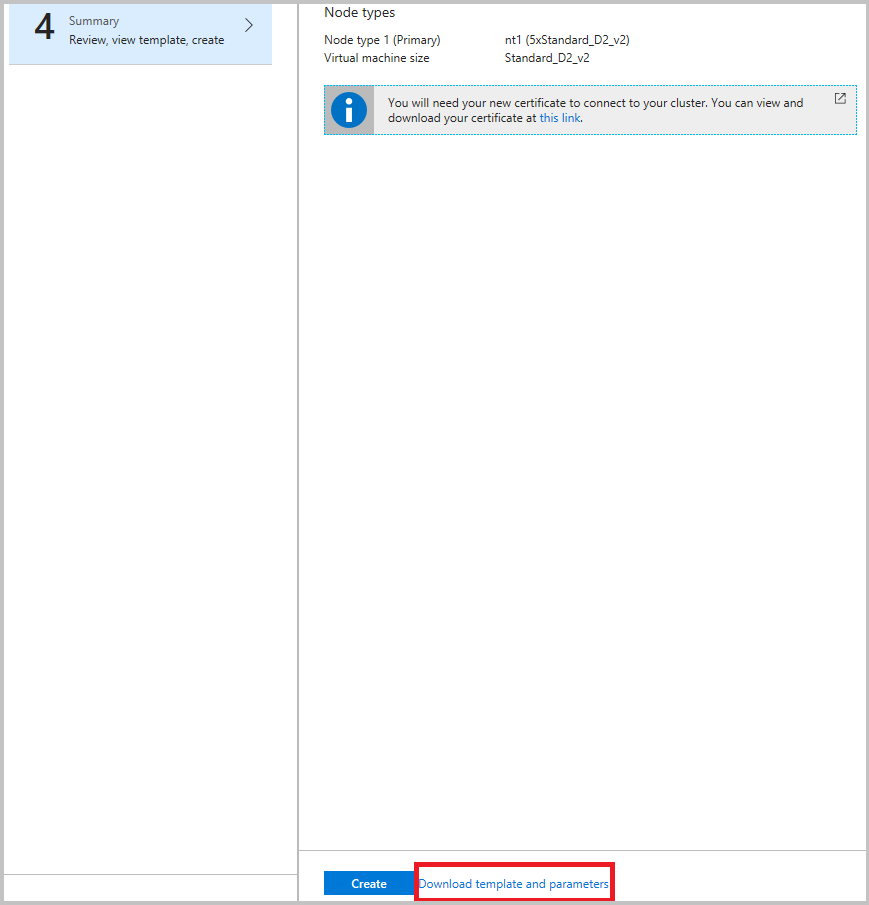
Dopo aver aggretato gli eventi in Archiviazione di Azure, configurare i log di Monitoraggio di Azure per ottenere informazioni dettagliate ed eseguirne query nel portale dei log di Monitoraggio di Azure
Nota
Attualmente non è possibile filtrare o eliminare gli eventi inviati alle tabelle. Se non si implementa un processo per rimuovere gli eventi dalla tabella, le dimensioni della tabella continueranno ad aumentare (il limite massimo è di 50 GB). Le istruzioni su come modificare questa impostazione sono disponibili più avanti in questo articolo. Inoltre, è disponibile un esempio di servizio di eliminazione dati in esecuzione nel watchdog di esempio. È consigliabile scriverne uno personalizzato, a meno che non esista un motivo valido per archiviare i log per un intervallo di tempo superiore a 30 o 90 giorni.
Distribuire l'estensione Diagnostica tramite Azure Resource Manager
Creare un cluster con l'estensione Diagnostica
Per creare un cluster tramite Resource Manager, è necessario aggiungere il file JSON di configurazione di Diagnostica al modello completo di Resource Manager. Gli esempi relativi ai modelli di Gestione risorse includono un modello di cluster con 5 VM con aggiunta della configurazione di Diagnostica, disponibile nella raccolta di esempi di Azure nella pagina relativa all'esempio di modello di Resource Manager di cluster con cinque nodi con Diagnostica.
Per visualizzare l'impostazione di Diagnostica nel modello di Resource Manager, aprire il file azuredeploy.json e cercare IaaSDiagnostics. Per creare un cluster con questo modello, è sufficiente selezionare il pulsante di distribuzione in Azure disponibile nel collegamento precedente.
In alternativa, è possibile scaricare l'esempio di Resource Manager, modificarlo e creare un cluster con il modello modificato mediante il comando New-AzResourceGroupDeployment in una finestra di Azure PowerShell. Per i parametri passati al comando, vedere il codice seguente. Per informazioni dettagliate sulla distribuzione di un gruppo di risorse con PowerShell, vedere l'articolo su come distribuire un gruppo di risorse con un modello di Azure Resource Manager.
Aggiungere l'estensione Diagnostica in un cluster esistente
Se in un cluster esistente non è stata distribuita l'estensione Diagnostica, è possibile aggiungerla o aggiornarla tramite il modello del cluster. Modificare il modello di Resource Manager usato per creare il cluster esistente o scaricare il modello dal portale come descritto in precedenza. Modificare il file template.json eseguendo le attività seguenti:
Aggiungere una nuova risorsa di archiviazione al modello nella sezione risorse.
{
"apiVersion": "2018-07-01",
"type": "Microsoft.Storage/storageAccounts",
"name": "[parameters('applicationDiagnosticsStorageAccountName')]",
"location": "[parameters('computeLocation')]",
"sku": {
"name": "[parameters('applicationDiagnosticsStorageAccountType')]"
"tier": "standard"
},
"tags": {
"resourceType": "Service Fabric",
"clusterName": "[parameters('clusterName')]"
}
},
Aggiungere quindi alla sezione parametri subito dopo le definizioni dell'account di archiviazione, tra supportLogStorageAccountName. Sostituire il testo segnaposto storage account name goes here con il nome dell'account di archiviazione preferito.
"applicationDiagnosticsStorageAccountType": {
"type": "string",
"allowedValues": [
"Standard_LRS",
"Standard_GRS"
],
"defaultValue": "Standard_LRS",
"metadata": {
"description": "Replication option for the application diagnostics storage account"
}
},
"applicationDiagnosticsStorageAccountName": {
"type": "string",
"defaultValue": "**STORAGE ACCOUNT NAME GOES HERE**",
"metadata": {
"description": "Name for the storage account that contains application diagnostics data from the cluster"
}
},
Aggiornare quindi la sezione VirtualMachineProfile del file template.json aggiungendo quanto segue all'interno della matrice delle estensioni. Assicurarsi di aggiungere una virgola all'inizio o alla fine, a seconda del punto di inserimento.
{
"name": "[concat(parameters('vmNodeType0Name'),'_Microsoft.Insights.VMDiagnosticsSettings')]",
"properties": {
"type": "IaaSDiagnostics",
"autoUpgradeMinorVersion": true,
"protectedSettings": {
"storageAccountName": "[parameters('applicationDiagnosticsStorageAccountName')]",
"storageAccountKey": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', parameters('applicationDiagnosticsStorageAccountName')),'2015-05-01-preview').key1]",
"storageAccountEndPoint": "https://core.windows.net/"
},
"publisher": "Microsoft.Azure.Diagnostics",
"settings": {
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
"StorageAccount": "[parameters('applicationDiagnosticsStorageAccountName')]"
},
"typeHandlerVersion": "1.5"
}
}
Dopo aver modificato il file template.json come descritto, pubblicare nuovamente il modello di Resource Manager. Se il modello è stato esportato, eseguire il file deploy.ps1 per pubblicarlo di nuovo. Dopo la distribuzione, assicurarsi che il valore di ProvisioningState sia Succeeded.
Suggerimento
Se si intende distribuire i contenitori nel cluster, abilitare WAD per raccogliere le statistiche docker aggiungendolo alla sezione WadCfg > DiagnosticMonitorConfiguration .
"DockerSources": {
"Stats": {
"enabled": true,
"sampleRate": "PT1M"
}
},
Aggiornare la quota di archiviazione
Dato che le tabelle popolate dall'estensione aumentano fino al raggiungimento della quota, è possibile valutare la possibilità di ridurre le dimensioni della quota. Il valore predefinito è 50 GB e può essere configurato nel modello nel campo overallQuotaInMB in DiagnosticMonitorConfiguration.
"overallQuotaInMB": "50000",
Configurazioni di raccolta log
Sono disponibili per la raccolta anche log da canali aggiuntivi; di seguito sono riportare alcune delle configurazioni più comuni che è possibile apportare nel modello per i cluster in esecuzione in Azure.
Canale operativo - Base: abilitato per impostazione predefinita, operazioni di alto livello eseguite da Service Fabric e dal cluster, inclusi gli eventi per un nodo in arrivo, una nuova applicazione distribuita o un rollback dell'aggiornamento e così via. Per un elenco di eventi, vedere Eventi del canale operativo.
"scheduledTransferKeywordFilter": "4611686018427387904"Canale operativo - Dettagliato: sono inclusi i rapporti sull'integrità e le decisioni sul bilanciamento del carico, oltre a tutti gli elementi del canale operativo di base. Questi eventi sono generati dal sistema o dal codice usando le API di creazione di report di integrità o caricamento, ad esempio ReportPartitionHealth o ReportLoad. Per visualizzare tali eventi nel visualizzatore eventi di diagnostica di Visual Studio, aggiungere "Microsoft-ServiceFabric:4:0x4000000000000008" all'elenco di provider ETW.
"scheduledTransferKeywordFilter": "4611686018427387912"Canale per la messaggistica e i dati - Base: registri ed eventi critici generati nella messaggistica (attualmente solo il ReverseProxy) e il percorso dei dati, oltre ai log dettagliati sul canale operativo. Questi eventi riguardano errori di elaborazione delle richieste e altri problemi critici nel ReverseProxy, oltre alle richieste elaborate. Questa è l'indicazione per la registrazione completa. Per visualizzare tali eventi nel visualizzatore eventi di diagnostica di Visual Studio, aggiungere "Microsoft-ServiceFabric:4:0x4000000000000010" all'elenco di provider ETW.
"scheduledTransferKeywordFilter": "4611686018427387928"Canale per la messaggistica e i dati - Dettagliato: canale dettagliato che contiene tutti i registri non critici di dati e messaggistica nel cluster, oltre ai log dettagliati sul canale operativo. Per informazioni dettagliate sulla risoluzione dei problemi relativi a tutti gli eventi del proxy inverso, vedere la guida alla diagnostica dei problemi relativi al proxy inverso. Per visualizzare tali eventi nel visualizzatore eventi di diagnostica di Visual Studio, aggiungere "Microsoft-ServiceFabric:4:0x4000000000000020" all'elenco di provider ETW.
"scheduledTransferKeywordFilter": "4611686018427387944"
Nota
Questo canale ha un volume molto elevato di eventi; permettendo la raccolta di eventi da questo canale dettagliato vengono generate numerose tracce e pertanto ciò può comportare un maggiore uso della capacità di archiviazione. Attivare questa funzionalità solo quando è strettamente necessario.
Per abilitare il canale operativo di base è consigliabile la registrazione completa con la minor quantità di rumore possibile. EtwManifestProviderConfiguration in WadCfg del modello avrà un aspetto simile al seguente:
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
Eseguire la raccolta dai nuovi canali EventSource
Per aggiornare Diagnostica in modo da raccogliere log da nuovi canali EventSource che rappresentano una nuova applicazione da distribuire, eseguire gli stessi passaggi descritti in precedenza per la configurazione di Diagnostica per un cluster esistente.
Aggiornare la sezione EtwEventSourceProviderConfiguration nel file template.json per aggiungere voci per i nuovi canali EventSource prima di applicare l'aggiornamento della configurazione tramite il comando New-AzResourceGroupDeployment di PowerShell. Il nome dell'origine evento è definito come parte del codice del file ServiceEventSource.cs generato da Visual Studio.
Ad esempio, se l'origine evento è denominato My Eventsource, aggiungere il codice seguente per inserire gli eventi da My Eventsource in una tabella denominata MyDestinationTableName.
{
"provider": "My-Eventsource",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "MyDestinationTableName"
}
}
Per raccogliere i contatori delle prestazioni o i log eventi, modificare il modello di Resource Manager tramite gli esempi forniti in Creare una macchina virtuale Windows con monitoraggio e diagnostica mediante i modelli di Azure Resource Manager. Pubblicare di nuovo il modello di Resource Manager.
Raccogliere i contatori delle prestazioni
Per raccogliere le metriche delle prestazioni dal cluster, aggiungere i contatori delle prestazioni al file "WadCfg > DiagnosticMonitorConfiguration" nel modello di Resource Manager per il cluster. Vedere Monitoraggio delle prestazioni con Diagnostica di Microsoft Azure per le istruzioni su come modificare WadCfg per raccogliere contatori delle prestazioni specifici. Per l'elenco dei contatori delle prestazioni che è consigliabile raccogliere, vedere l'articolo relativo ai contatori delle prestazioni in Service Fabric.
Se si usa un sink di Application Insights, come descritto nella sezione di seguito, e si vuole che queste metriche vengano visualizzate in Application Insights, aggiungere il nome del sink nella sezione "sinks" illustrata sopra. I contatori delle prestazioni configurati singolarmente verranno inviati automaticamente alla risorsa di Application Insights.
Inviare i log ad Application Insights
Configurazione di Application Insights con WAD
Nota
Al momento, si applica solo ai cluster Windows.
Esistono due modi principali per inviare dati da WAD a app Azure lication Insights, che viene ottenuto aggiungendo un sink di Application Insights alla configurazione wad, tramite il portale di Azure o tramite un modello di Azure Resource Manager.
Aggiungere una chiave di strumentazione di Application Insights durante la creazione di un cluster nel portale di Azure
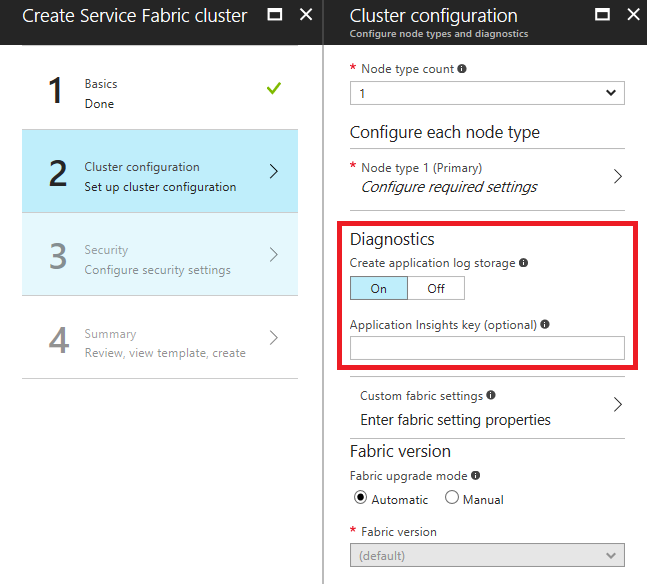
Quando si crea un cluster, se la diagnostica è attiva, si visualizzerà un campo facoltativo per immettere una chiave di strumentazione di Application Insights. Se si incolla la chiave di Application Insights qui, il sink di Application Insights viene configurato automaticamente nel modello di Resource Manager usato per distribuire il cluster.
Aggiungere il sink di Application Insights al modello di Resource Manager
Nel modello di Resource Manager, in "WadCfg" aggiungere un "Sink" apportando le due modifiche seguenti:
Aggiungere la configurazione del sink direttamente dopo il completamento della dichiarazione di
DiagnosticMonitorConfiguration:"SinksConfig": { "Sink": [ { "name": "applicationInsights", "ApplicationInsights": "***ADD INSTRUMENTATION KEY HERE***" } ] }Includere il sink in
DiagnosticMonitorConfigurationaggiungendo la riga seguente nell'elementoDiagnosticMonitorConfigurationdiWadCfg(subito prima della dichiarazione diEtwProviders):"sinks": "applicationInsights"
In entrambi i frammenti di codice precedenti il nome "applicationInsights" è stato usato per descrivere il sink. Questo non è un requisito e fino a quando il nome del sink è incluso in "sink", è possibile impostare il nome per qualsiasi stringa.
Attualmente, i log del cluster vengono mostrati come tracce nel visualizzatore di log di Application Insights. Poiché la maggior parte delle tracce provenienti dalla piattaforma è di livello "Informativo", è anche possibile modificare la configurazione del sink in modo da inviare solo i log di tipo "Avviso" o "Errore". Questa operazione può essere eseguita aggiungendo "Canali" al sink, come illustrato in questo articolo.
Nota
Se si usa una chiave di Application Insights errata nel portale o nel modello di Resource Manager è necessario modificare la chiave e aggiornare il cluster o ridistribuirlo manualmente.
Passaggi successivi
Dopo aver configurato correttamente Diagnostica di Azure, sarà possibile visualizzare i dati nelle tabelle di archiviazione dai log EventSource ed ETW. Se si sceglie di usare i log di Monitoraggio di Azure, Kibana o qualsiasi altra piattaforma di analisi e visualizzazione dei dati non configurata direttamente nel modello di Resource Manager, assicurarsi di configurare la piattaforma preferita per leggere i dati da queste tabelle di archiviazione. Questa operazione per i log di Monitoraggio di Azure è relativamente semplice ed è illustrata in Analisi degli eventi e dei log. Application Insights è un caso particolare sotto questo aspetto, perché può essere configurato nell'ambito della configurazione dell'estensione Diagnostica. Se si sceglie di usare Application Insights, vedere l'articolo appropriato.
Nota
Attualmente non è possibile filtrare o eliminare gli eventi inviati alla tabella. Se non si implementa un processo per rimuovere gli eventi dalla tabella, le dimensioni della tabella continueranno ad aumentare. È attualmente disponibile un esempio di servizio di eliminazione dati in esecuzione nel watchdog di esempio. È consigliabile scriverne uno personalizzato, a meno che non esista un motivo valido per archiviare i log per un intervallo di tempo superiore a 30 o 90 giorni.
- Informazioni su come raccogliere i contatori delle prestazioni o i log mediante l'estensione Diagnostica
- Event Analysis and Visualization with Application Insights (Analisi e visualizzazione degli eventi con Application Insights)
- Analisi e visualizzazione degli eventi con i log di Monitoraggio di Azure
- Event Analysis and Visualization with Application Insights (Analisi e visualizzazione degli eventi con Application Insights)
- Analisi e visualizzazione degli eventi con i log di Monitoraggio di Azure