Eseguire un cluster Cassandra su Linux in Azure con Node.js
Importante
Le VM classiche verranno ritirate il 1° marzo 2023.
Se si usano risorse IaaS di ASM, completare la migrazione entro il 1° marzo 2023. È consigliabile effettuare quanto prima questo passaggio per sfruttare i vantaggi delle numerose funzionalità avanzate di Azure Resource Manager.
Per altre informazioni, vedere Eseguire la migrazione delle risorse IaaS ad Azure Resource Manager entro il 1° marzo 2023.
Nota
Azure offre due modelli di distribuzione per creare e usare le risorse: Azure Resource Manager e distribuzione classica. Questo articolo usa il modello di distribuzione classica. Per le distribuzioni più recenti si consiglia di usare il modello di Resource Manager. Vedere i modelli di Resource Manager per cluster Datastax Enterprise e Spark e Cassandra in CentOS.
Panoramica
Microsoft Azure è una piattaforma cloud aperta che esegue software Microsoft e non Microsoft. Questo software include sistemi operativi, server applicazioni, middleware di messaggistica e database SQL e NoSQL da modelli commerciali e open source. La creazione di servizi resilienti in cloud pubblici come Azure richiede un'attenta pianificazione e un'architettura intenzionale per applicazioni, server e livelli di archiviazione.
L'architettura di archiviazione distribuita di Cassandra consente di creare sistemi a disponibilità elevata a tolleranza di errore per gli errori del cluster. Cassandra è un database NoSQL su scala cloud gestito da Apache Software Foundation. Cassandra è scritto in Java, quindi viene eseguito su piattaforme Windows e Linux.
Questo articolo illustra la distribuzione di Cassandra in Ubuntu come cluster singolo e multi-data center che usa Azure Macchine virtuali e reti virtuali di Azure. La distribuzione del cluster per carichi di lavoro ottimizzati per la produzione non rientra nell'ambito di questo articolo. Richiede la configurazione di più nodi su disco, la progettazione appropriata della topologia circolare e la modellazione dei dati per supportare i requisiti di replica, coerenza dei dati, velocità effettiva e disponibilità elevata necessari.
Questo articolo illustra cosa riguarda la creazione del cluster Cassandra, rispetto a Docker, Chef o Puppet. Questo approccio può semplificare notevolmente la distribuzione dell'infrastruttura.
Modelli di distribuzione
La rete di Microsoft Azure consente la distribuzione di cluster privati isolati. È possibile limitare l'accesso dei cluster per ottenere una sicurezza di rete dettagliata. Questo articolo illustra la distribuzione di Cassandra a un livello fondamentale. Non si concentra sul livello di coerenza e sulla progettazione ottimale dell'archiviazione per la velocità effettiva.
Ecco i requisiti di rete per il cluster ipotetico:
- I sistemi esterni non possono accedere al database Cassandra dall'interno o dall'esterno di Azure.
- Il cluster Cassandra deve essere protetto da un servizio di bilanciamento del carico per il traffico thrift.
- I nodi Cassandra vengono distribuiti in due gruppi in ogni data center per una disponibilità avanzata del cluster.
- Il cluster viene bloccato in modo che solo la server farm applicazioni abbia accesso diretto al database.
- Non esistono endpoint di rete pubblici, diversi da SSH.
- Ogni nodo Cassandra necessita di un indirizzo IP interno fisso.
Cassandra può essere distribuito in una singola area di Azure o in più aree. La distribuzione si basa sulla natura distribuita del carico di lavoro. Un modello di distribuzione in più aree può servire gli utenti più vicini a una determinata area geografica tramite la stessa infrastruttura Cassandra.
La replica dei nodi predefinita di Cassandra si occupa della sincronizzazione delle scritture multimaster originate da più data center. Offre una visualizzazione coerente dei dati alle applicazioni.
La distribuzione in più aree può essere utile anche per la mitigazione dei rischi di interruzioni dei servizi di Azure più ampie. La coerenza e la topologia di replica ottimizzabili di Cassandra consentono di soddisfare i diversi obiettivi del punto di ripristino (RPO) delle applicazioni.
Distribuzione in una singola area
Si inizierà con una distribuzione a singola area e si apprenderà come creare un modello a più aree. Viene usata una rete virtuale di Azure per creare subnet isolate che soddisfano i requisiti di sicurezza di rete.
Il processo descritto nella creazione della distribuzione a singola area usa Ubuntu 14.04 LTS e Cassandra 2.08. Ma il processo può essere facilmente adottato per le altre varianti linux. La distribuzione a singola area include le caratteristiche seguenti:
Disponibilità elevata: I nodi Cassandra illustrati nella figura 1 vengono distribuiti in due set di disponibilità. I nodi vengono distribuiti tra più domini di errore per la disponibilità elevata. Le macchine virtuali annotate con ogni set di disponibilità vengono mappate a due domini di errore.
Azure usa il concetto di domini di errore per gestire i tempi di inattività non pianificati, ad esempio errori hardware o software. Il concetto di domini di aggiornamento viene usato per gestire i tempi di inattività pianificati. Gli esempi sono l'applicazione di patch o aggiornamenti del sistema operativo guest o gli aggiornamenti dell'applicazione. Per altre informazioni sul ruolo dei domini di errore e di aggiornamento per raggiungere la disponibilità elevata, vedere Ripristino di emergenza e disponibilità elevata per le applicazioni Azure.
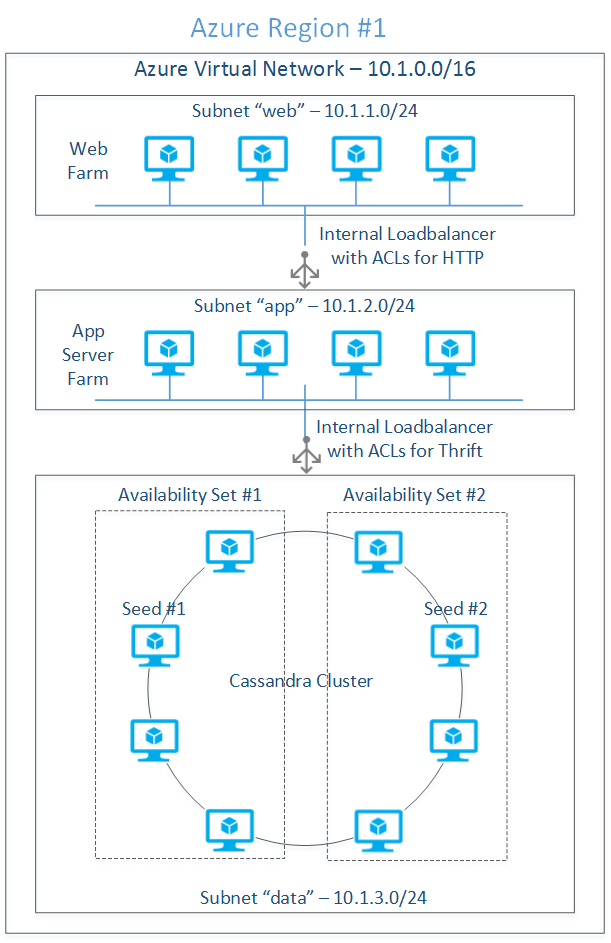
Figura 1: Distribuzione a singola area
Azure non consente il mapping esplicito di un gruppo di macchine virtuali a un dominio di errore specifico. Anche con il modello di distribuzione illustrato nella figura 1, è statisticamente probabile che tutte le macchine virtuali siano mappate a due domini di errore anziché a quattro.
Traffico thrift di bilanciamento del carico: Le librerie client thrift all'interno del server Web si connettono al cluster tramite un servizio di bilanciamento del carico interno. Questo processo richiede l'aggiunta del servizio di bilanciamento del carico interno alla subnet "dati" nel contesto del servizio cloud che ospita il cluster Cassandra, come illustrato nella figura 1.
Dopo aver definito il servizio di bilanciamento del carico interno, ogni nodo richiede l'aggiunta dell'endpoint con carico bilanciato con le annotazioni di un set con bilanciamento del carico con il nome del servizio di bilanciamento del carico definito in precedenza. Per altre informazioni, vedere Bilanciamento del carico interno di Azure.
Inizializzazione del cluster: Selezionare i nodi a disponibilità elevata per i semi. I nuovi nodi comunicano con i nodi di inizializzazione per individuare la topologia del cluster. Per evitare un singolo punto di errore, creare un nodo da ogni set di disponibilità il nodo di inizializzazione.
Fattore di replica e livello di coerenza: La disponibilità elevata e la durabilità dei dati predefinite di Cassandra sono caratterizzate da:
- Fattore di replica (RF), ovvero il numero di copie di ogni riga archiviata nel cluster.
- Livello di coerenza, ovvero il numero di repliche da leggere o scrivere prima che il risultato venga restituito al chiamante.
Il fattore di replica viene specificato durante la creazione di un keyspace, simile a un database relazionale. Il livello di coerenza viene specificato mentre si esegue la query CRUD. Per informazioni dettagliate sulla coerenza e la formula per il calcolo del quorum, vedere la documentazione di Cassandra in Configurare per la coerenza.
Cassandra supporta due tipi di modelli di integrità dei dati: coerenza e coerenza finale. Al termine di un'operazione di scrittura, il fattore di replica e il livello di coerenza determinano insieme se i dati sono coerenti o eventualmente coerenti. Ad esempio, specificando QUORUM come livello di coerenza, si garantisce sempre la coerenza dei dati. Qualsiasi livello di coerenza al di sotto del numero di repliche da scrivere in base alle esigenze per ottenere quorum, ad esempio ONE, comporta la coerenza finale dei dati.
Il cluster a otto nodi illustrato nella figura 1 ha un fattore di replica pari a 3 e un quorum (due nodi vengono letti o scritti per coerenza) livello di coerenza di lettura/scrittura. Il cluster può sopravvivere alla perdita teorica di un nodo per ogni gruppo di replica prima che le applicazioni inizino a notare l'errore. Questo scenario presuppone che tutti gli spazi delle chiavi abbiano richieste di lettura/scrittura ben bilanciate.
Per il cluster distribuito vengono usati i parametri seguenti:
Cluster Cassandra a singola area
| Parametro del cluster | Valore | Osservazioni |
|---|---|---|
| Numero di nodi (N) | 8 | Numero totale di nodi nel cluster. |
| Fattore di replica (RF) | 3 | Numero di repliche di una determinata riga. |
| Livello di coerenza (scrittura) | QUORUM [(RF/2) +1) = 2] Il risultato della formula viene arrotondato per difetto. | Scrive al massimo due repliche prima che la risposta venga inviata al chiamante. Una terza replica viene scritta in modo coerente. |
| Livello di coerenza (lettura) | QUORUM [(RF/2) +1 = 2] Il risultato della formula viene arrotondato per difetto. | Legge due repliche prima che venga inviata una risposta al chiamante. |
| Strategia di replica | NetworkTopologyStrategy Per altre informazioni, vedere Replica dei dati nella documentazione di Cassandra. | Comprende la topologia di distribuzione e inserisce le repliche nei nodi in modo che tutte le repliche non finissono nello stesso rack. |
| Snitch | GossipingPropertyFileSnitch Per altre informazioni, vedere Snitches nella documentazione di Cassandra. | NetworkTopologyStrategy usa il concetto di snitch per comprendere la topologia. GossipingPropertyFileSnitch offre un controllo migliore nel mapping di ogni nodo al data center e al rack. Il cluster usa quindi il protocollo gossip per propagare queste informazioni. Questa configurazione è più semplice in un'impostazione IP dinamica rispetto a PropertyFileSnitch. |
Considerazioni di Azure per un cluster Cassandra: Microsoft Azure Macchine virtuali usa l'archiviazione BLOB di Azure per la persistenza del disco. Archiviazione di Azure salva tre repliche di ogni disco per una durabilità elevata. Questa ridondanza significa che ogni riga di dati inserita in una tabella Cassandra è già archiviata in tre repliche. Pertanto, la coerenza dei dati è già presa in considerazione anche se il fattore di replica è 1.
Il problema principale con il fattore di replica 1 è che l'applicazione riscontra tempi di inattività anche se un singolo nodo Cassandra ha esito negativo. Un nodo potrebbe essere inattivo per problemi quali errori hardware o software di sistema. Se il controller di Infrastruttura di Azure riconosce il problema, usa le stesse unità di archiviazione per effettuare il provisioning di un nuovo nodo al suo posto. Il provisioning di un nuovo nodo per sostituire quello precedente potrebbe richiedere alcuni minuti.
Il controller di Infrastruttura di Azure esegue anche gli aggiornamenti in sequenza dei nodi nel cluster per le attività di manutenzione pianificata. Queste attività includono modifiche del sistema operativo guest, aggiornamenti di Cassandra e modifiche dell'applicazione. Gli aggiornamenti in sequenza potrebbero arrestare alcuni nodi alla volta, pertanto il cluster potrebbe riscontrare brevi tempi di inattività per alcune partizioni. I dati non andranno persi a causa della ridondanza predefinita di Archiviazione di Azure.
Per i sistemi distribuiti in Azure che non richiedono disponibilità elevata, ad esempio circa 99,9, ovvero circa 8,76 ore all'anno, è possibile eseguire con RF=1 e livello di coerenza=ONE. Per altre informazioni, vedere Disponibilità elevata.
Per le applicazioni con requisiti di disponibilità elevata, RF=3 e livello di coerenza=QUORUM tollerano il tempo di inattività di uno dei nodi di una replica. Non è possibile usare RF=1 nelle distribuzioni tradizionali come in locale. La perdita di dati può causare problemi come gli errori del disco.
Distribuzione in più aree
Il modello di coerenza e replica compatibile con il data center di Cassandra consente la distribuzione in più aree senza la necessità di strumenti esterni. Questa configurazione è diversa dai database relazionali tradizionali in cui la configurazione per il mirroring del database per le scritture multimaster può essere complessa. L'uso di Cassandra in un'installazione in più aree può essere utile per gli scenari di utilizzo seguenti:
Distribuzione basata su prossimità: Le applicazioni multi-tenant, con un mapping chiaro degli utenti tenant all'area, traggono vantaggio dalle latenze basse del cluster in più aree. Ad esempio, un sistema di gestione dell'apprendimento per gli istituti di istruzione potrebbe distribuire un cluster distribuito nelle aree Stati Uniti orientali e Stati Uniti occidentali per servire i rispettivi campus per l'analisi transazionale. I dati possono essere coerenti in locale al momento delle operazioni di lettura e scrittura e possono essere infine coerenti in entrambe le aree. Ci sono altri esempi come la distribuzione multimediale e l'e-commerce. Qualsiasi elemento che serve una base utente con concentrazione geografica è un buon caso d'uso per questo modello di distribuzione.
Disponibilità elevata: La ridondanza è un fattore chiave per ottenere una disponibilità elevata di software e hardware. Per altre informazioni, vedere Creare sistemi cloud affidabili in Microsoft Azure.
In Microsoft Azure, l'unico modo affidabile per ottenere la vera ridondanza consiste nel distribuire un cluster con più aree. È possibile distribuire le applicazioni in modalità attiva-attiva o attiva-passiva. Se un'area è inattiva, Gestione traffico di Azure reindirizza il traffico all'area attiva. Con la distribuzione a singola area, se la disponibilità è 99,9, una distribuzione a due aree può ottenere la disponibilità di 99,9999 calcolata dalla formula (1-(1-0,999) * (1-0,999)) * 100). Per altre informazioni, vedere il documento precedente.
Ripristino di emergenza: Un cluster Cassandra in più aree, se progettato correttamente, può resistere a interruzioni irreversibili del data center. Se un'area è inattiva, l'applicazione distribuita in altre aree può iniziare a servire gli utenti. Come qualsiasi altra implementazione di continuità aziendale, l'applicazione deve essere tollerante di una perdita di dati risultante dai dati nella pipeline asincrona. Cassandra rende il ripristino molto più veloce del tempo richiesto dai processi di ripristino del database tradizionali.
La figura 2 mostra un tipico modello di distribuzione in più aree con otto nodi in ogni area. Entrambe le aree sono immagini speculari tra loro per motivi di simmetria. Le progettazioni reali dipendono dal tipo di carico di lavoro (ad esempio, transazionale o analitico), RPO, obiettivo del tempo di ripristino (RTO), coerenza dei dati e requisiti di disponibilità.
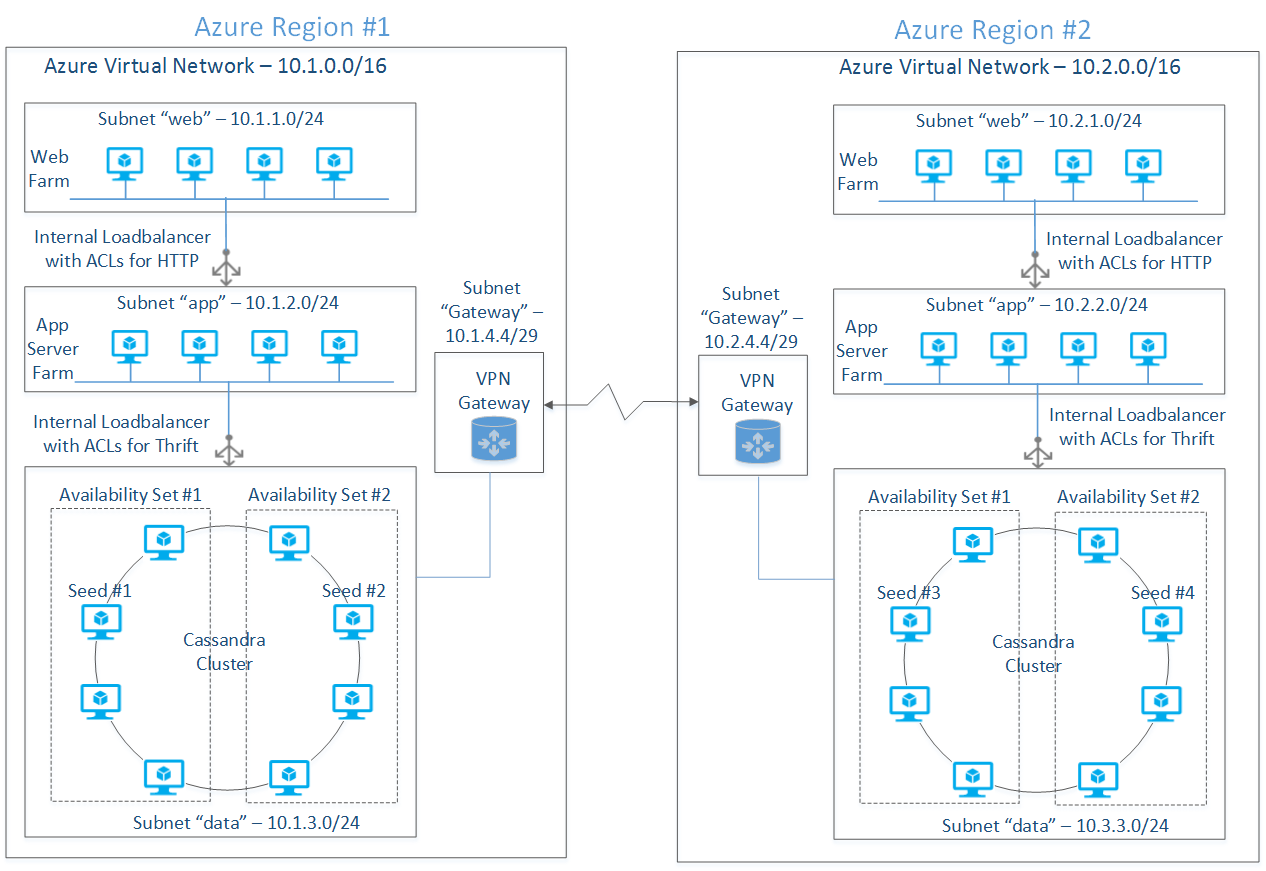
Figura 2: Distribuzione di Cassandra in più aree
Integrazione di rete
I set di macchine virtuali distribuite in reti private situate in due aree usano un tunnel VPN per comunicare tra loro. Il tunnel VPN connette due gateway software di cui viene effettuato il provisioning durante il processo di distribuzione in rete. Entrambe le aree hanno un'architettura di rete simile in termini di subnet "Web" e "dati".
La rete di Azure consente la creazione di tutte le subnet necessarie e applica gli ACL in base alle esigenze della sicurezza di rete. Prendere in considerazione la latenza di comunicazione tra data center e l'effetto economico del traffico di rete nella progettazione della topologia del cluster.
Coerenza dei dati per la distribuzione di più data center
Le distribuzioni distribuite devono essere consapevoli dell'impatto della topologia del cluster sulla velocità effettiva e sulla disponibilità elevata. Il livello di coerenza e RF deve essere selezionato in modo che il quorum non dipende dalla disponibilità di tutti i data center.
Per un sistema che necessita di coerenza elevata, LOCAL_QUORUM per il livello di coerenza (per letture e scritture) garantisce che le letture e le scritture locali siano soddisfatte dai nodi locali mentre i dati vengono replicati in modo asincrono nei data center remoti. La tabella seguente riepiloga i dettagli di configurazione per la distribuzione di cluster in più aree descritta in questo articolo.
Configurazione del cluster Cassandra in due aree
| Parametro del cluster | Valore | Osservazioni |
|---|---|---|
| Numero di nodi (N) | 8 + 8 | Numero totale di nodi nel cluster. |
| Fattore di replica (RF) | 3 | Numero di repliche di una determinata riga. |
| Livello di coerenza (scrittura) | LOCAL_QUORUM [(sum(RF)/2) +1) = 4] Il risultato della formula viene arrotondato per difetto. | Due nodi vengono scritti nel primo data center in modo sincrono. I due nodi aggiuntivi necessari per il quorum vengono scritti in modo asincrono nel secondo data center. |
| Livello di coerenza (lettura) | LOCAL_QUORUM ((RF/2) +1) = 2 Il risultato della formula viene arrotondato per difetto. | Le richieste di lettura vengono soddisfatte da una sola area. Due nodi vengono letti prima che la risposta venga inviata al client. |
| Strategia di replica | NetworkTopologyStrategy Per altre informazioni, vedere Replica dei dati nella documentazione di Cassandra. | Comprende la topologia di distribuzione e inserisce le repliche nei nodi in modo che tutte le repliche non finissono nello stesso rack. |
| Snitch | GossipingPropertyFileSnitch Per altre informazioni, vedere Snitches nella documentazione di Cassandra. | NetworkTopologyStrategy usa il concetto di snitch per comprendere la topologia. GossipingPropertyFileSnitch offre un controllo migliore nel mapping di ogni nodo al data center e al rack. Il cluster usa quindi il protocollo gossip per propagare queste informazioni. Questa configurazione è più semplice in un'impostazione IP dinamica rispetto a PropertyFileSnitch. |
Configurazione software
Durante la distribuzione vengono usate le versioni software seguenti:
| Software | Source (Sorgente) | Versione |
|---|---|---|
| JRE | JRE 8 | 8U5 |
| JNA | JNA | 3.2.7 |
| Cassandra | Apache Cassandra 2.0.8 | 2.0.8 |
| Ubuntu | Microsoft Azure | 14.04 LTS |
Per semplificare la distribuzione, scaricare sul desktop tutto il software necessario. Caricarlo quindi nell'immagine del modello Ubuntu per creare un precursore nella distribuzione del cluster.
Scaricare il software in una directory di download nota nel computer locale. Usare una directory come %TEMP%/download in Windows o ~/Downloads per la maggior parte delle distribuzioni Linux o Mac.
Creare una VM Ubuntu
Creare un'immagine Ubuntu con il software prerequisito. È possibile riutilizzare l'immagine per effettuare il provisioning di diversi nodi Cassandra.
Passaggio 1: Generare una coppia di chiavi SSH
In fase di provisioning Azure richiede una chiave pubblica X509 con codifica PEM o DER. Generare una coppia di chiavi pubblica/privata seguendo le istruzioni riportate in Usare SSH con Linux in Azure. Se si prevede di usare putty.exe come client SSH in Windows o Linux, convertire la chiave privata RSA con codifica PEM in formato di chiave pubblica/privata usando puttygen.exe. Per istruzioni su come eseguire questa conversione, vedere la pagina Web precedente.
Passaggio 2: Creare una macchina virtuale modello Ubuntu
Per creare la macchina virtuale modello, accedere alla portale di Azure. Selezionare >Nuova>macchina> virtualedi calcolodalla raccolta>Ubuntu Ubuntu>Server 14.04 LTS. Selezionare quindi la freccia destra. Per un'esercitazione che descrive come creare una macchina virtuale Linux, vedere Creare una macchina virtuale che esegue Linux.
Immettere le informazioni seguenti nella prima schermata di configurazione della macchina virtuale :
| Nome del campo | Valore campo | Osservazioni |
|---|---|---|
| DATA DI RILASCIO VERSIONE | Selezionare una data dall'elenco a discesa. | |
| NOME MACCHINA VIRTUALE | cass-template | Questo nome è il nome host della macchina virtuale. |
| LIVELLO | STANDARD | Lasciare il valore predefinito. |
| SIZE | A1 | Selezionare la macchina virtuale in base alle esigenze di I/O. A questo scopo, lasciare il valore predefinito. |
| NUOVO NOME UTENTE | localadmin | "Amministrazione" è un nome utente riservato in Ubuntu 12.xx e dopo. |
| AUTENTICAZIONE | Selezionare la casella di controllo. | Verificare se si vuole proteggere con una chiave SSH. |
| CERTIFICATE | Nome file del certificato di chiave pubblica. | Usare la chiave pubblica generata in precedenza. |
| Nuova password | Password complessa. | |
| Confirm Password | Password complessa. | |
Immettere le informazioni seguenti nella seconda schermata di configurazione della macchina virtuale :
| Nome del campo | Valore campo | Osservazioni |
|---|---|---|
| SERVIZIO CLOUD | Creare un nuovo servizio cloud | Il servizio cloud è una risorsa di calcolo del contenitore, ad esempio macchine virtuali. |
| NOME DNS DEL SERVIZIO CLOUD: | ubuntu-template.cloudapp.net | Assegnare un nome del servizio di bilanciamento del carico agnostico del computer. |
| AREA/GRUPPO DI AFFINITÀ/RETE VIRTUALE | Stati Uniti occidentali | Selezionare un'area da cui le applicazioni Web accedono al cluster Cassandra. |
| ACCOUNT DI ARCHIVIAZIONE | Usare quello predefinito. | Usare l'account di archiviazione predefinito o un account di archiviazione pre-creato in un'area specifica. |
| Set di disponibilità | No. | Lasciare vuoto. |
| ENDPOINT | Usare quello predefinito. | Usare la configurazione SSH predefinita. |
Selezionare la freccia destra e lasciare le impostazioni predefinite come illustrato nella terza schermata. Selezionare il pulsante Segno di spunta per completare il processo di provisioning della macchina virtuale. Dopo alcuni minuti, la macchina virtuale con il nome ubuntu-template viene visualizzata nello stato in esecuzione .
Installare il software necessario
Passaggio 1: Caricare tarball
Usando scp o pscp, copiare il software scaricato in precedenza nella directory ~/downloads usando il formato di comando seguente:
pscp server-jre-8u5-linux-x64.tar.gz localadmin@hk-cas-template.cloudapp.net:/home/localadmin/downloads/server-jre-8u5-linux-x64.tar.gz
Ripetere il comando precedente per JRE e per i bit Cassandra.
Passaggio 2: Preparare la struttura della directory ed estrarre gli archivi
Accedere alla macchina virtuale, creare la struttura di directory ed estrarre software come utente super usando lo script bash seguente:
#!/bin/bash
CASS_INSTALL_DIR="/opt/cassandra"
JRE_INSTALL_DIR="/opt/java"
CASS_DATA_DIR="/var/lib/cassandra"
CASS_LOG_DIR="/var/log/cassandra"
DOWNLOADS_DIR="~/downloads"
JRE_TARBALL="server-jre-8u5-linux-x64.tar.gz"
CASS_TARBALL="apache-cassandra-2.0.8-bin.tar.gz"
SVC_USER="localadmin"
RESET_ERROR=1
MKDIR_ERROR=2
reset_installation ()
{
rm -rf $CASS_INSTALL_DIR 2> /dev/null
rm -rf $JRE_INSTALL_DIR 2> /dev/null
rm -rf $CASS_DATA_DIR 2> /dev/null
rm -rf $CASS_LOG_DIR 2> /dev/null
}
make_dir ()
{
if [ -z "$1" ]
then
echo "make_dir: invalid directory name"
exit $MKDIR_ERROR
fi
if [ -d "$1" ]
then
echo "make_dir: directory already exists"
exit $MKDIR_ERROR
fi
mkdir $1 2>/dev/null
if [ $? != 0 ]
then
echo "directory creation failed"
exit $MKDIR_ERROR
fi
}
unzip()
{
if [ $# == 2 ]
then
tar xzf $1 -C $2
else
echo "archive error"
fi
}
if [ -n "$1" ]
then
SVC_USER=$1
fi
reset_installation
make_dir $CASS_INSTALL_DIR
make_dir $JRE_INSTALL_DIR
make_dir $CASS_DATA_DIR
make_dir $CASS_LOG_DIR
#Unzip JRE and Cassandra.
unzip $HOME/downloads/$JRE_TARBALL $JRE_INSTALL_DIR
unzip $HOME/downloads/$CASS_TARBALL $CASS_INSTALL_DIR
#Change the ownership to the service credentials.
chown -R $SVC_USER:$GROUP $CASS_DATA_DIR
chown -R $SVC_USER:$GROUP $CASS_LOG_DIR
echo "edit /etc/profile to add JRE to the PATH"
echo "installation is complete"
Se si incolla questo script nella finestra vim, rimuovere il ritorno a capo ('\r') usando il comando seguente:
tr -d '\r' <infile.sh >outfile.sh
Passaggio 3: Modificare etc/profile
Aggiungere lo script seguente alla fine:
JAVA_HOME=/opt/java/jdk1.8.0_05
CASS_HOME= /opt/cassandra/apache-cassandra-2.0.8
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$CASS_HOME/bin
export JAVA_HOME
export CASS_HOME
export PATH
Passaggio 4: Installare JNA per i sistemi di produzione
Usare questa sequenza di comandi. Il comando seguente installa jna-3.2.7.jar e jna-platform-3.2.7.jar nella directory /usr/share.java sudo apt-get install libjna-java.
Creare collegamenti simbolici nella directory $CASS_HOME/lib in modo che lo script di avvio cassandra possa trovare questi jar:
ln -s /usr/share/java/jna-3.2.7.jar $CASS_HOME/lib/jna.jar
ln -s /usr/share/java/jna-platform-3.2.7.jar $CASS_HOME/lib/jna-platform.jar
Passaggio 5: Configurare cassandra.yaml
Modificare cassandra.yaml in ogni macchina virtuale per visualizzare la configurazione necessaria per tutte le macchine virtuali. Questa configurazione viene modificata durante il provisioning effettivo.
| Nome del campo | Valore | Osservazioni |
|---|---|---|
| cluster_name | "CustomerService" | Usare il nome della distribuzione. |
| listen_address | [lasciare vuoto] | Eliminare "localhost". |
| rpc_address | [lasciare vuoto] | Eliminare "localhost". |
| seeds | "10.1.2.4, 10.1.2.6, 10.1.2.8" | Elenco di tutti gli indirizzi IP assegnati come semi. |
| endpoint_snitch | org.apache.cassandra.locator.GossipingPropertyFileSnitch | Questo valore viene usato da NetworkTopologyStrategy per dedurre il data center e il rack della macchina virtuale. |
Passaggio 6: Acquisire l'immagine della macchina virtuale
Accedere alla macchina virtuale usando il nome host (hk-cas-template.cloudapp.net) e la chiave privata SSH creata in precedenza. Per informazioni su come accedere usando SSH o putty.exe, vedere Usare SSH con Linux in Azure.
Per acquisire l'immagine, seguire questa procedura.
1. Deprovision
Usare il comando sudo waagent –deprovision+user per rimuovere informazioni specifiche dell'istanza di macchina virtuale. Per altre informazioni sul processo di acquisizione immagini, vedere Acquisire una macchina virtuale Linux.
2. Arrestare la macchina virtuale
Evidenziare la macchina virtuale e selezionare SHUTDOWN nella barra dei comandi inferiore.
3. Acquisire l'immagine
Evidenziare la macchina virtuale e selezionare CAPTURE sulla barra dei comandi inferiore. Nella schermata successiva assegnare un nome all'immagine, ad esempio hk-cas-2-08-ub-14-04-2014071. Immettere una descrizione dell'immagine. Selezionare il pulsante Segno di spunta per completare il processo di acquisizione.
Questo processo richiede alcuni secondi. L'immagine viene visualizzata nella sezione MY IMAGES della raccolta immagini. La macchina virtuale di origine verrà automaticamente eliminata una volta acquisita l'immagine.
Processo di distribuzione a area singola
Passaggio 1: Creare la rete virtuale
Accedere al portale di Azure. Usare il modello di distribuzione classica per creare una rete virtuale con gli attributi visualizzati in questa tabella. Per informazioni sui passaggi, vedere Creare una rete virtuale (classica) usando la portale di Azure.
| Nome attributo macchina virtuale | Valore | Osservazioni |
|---|---|---|
| NOME | vnet-cass-west-us | |
| Region | Stati Uniti occidentali | |
| Server DNS | nessuno | Ignorare questo attributo perché non si usa un server DNS di Azure. |
| Spazio degli indirizzi | 10.1.0.0/16 | |
| IP iniziale | 10.1.0.0 | |
| CIDR | /16 (65531) |
Aggiungere le subnet seguenti:
| NOME | IP iniziale | CIDR | Osservazioni |
|---|---|---|---|
| Web | 10.1.1.0 | /24 (251) | Subnet per la Web farm |
| data | 10.1.2.0 | /24 (251) | Subnet per i nodi del database |
I dati e le subnet Web possono essere protetti tramite gruppi di sicurezza di rete. Questo argomento non è compreso nell'ambito di questo articolo.
Passaggio 2: Effettuare il provisioning di macchine virtuali
Usando l'immagine creata in precedenza, creare le macchine virtuali seguenti nel server cloud hk-c-svc-west e associarle alle rispettive subnet, come illustrato di seguito:
| Nome computer | Subnet | Indirizzo IP | Set di disponibilità | DC/Rack | Valore di inizializzazione? |
|---|---|---|---|---|---|
| hk-c1-west-us | data | 10.1.2.4 | hk-c-aset-1 | dc =WESTUS rack =rack1 | Sì |
| hk-c2-west-us | data | 10.1.2.5 | hk-c-aset-1 | dc =WESTUS rack =rack1 | No |
| hk-c3-west-us | data | 10.1.2.6 | hk-c-aset-1 | dc =WESTUS rack =rack2 | Sì |
| hk-c4-west-us | data | 10.1.2.7 | hk-c-aset-1 | dc =WESTUS rack =rack2 | No |
| hk-c5-west-us | data | 10.1.2.8 | hk-c-aset-2 | dc =WESTUS rack =rack3 | Sì |
| hk-c6-west-us | data | 10.1.2.9 | hk-c-aset-2 | dc =WESTUS rack =rack3 | No |
| hk-c7-west-us | data | 10.1.2.10 | hk-c-aset-2 | dc =WESTUS rack =rack4 | Sì |
| hk-c8-west-us | data | 10.1.2.11 | hk-c-aset-2 | dc =WESTUS rack =rack4 | No |
| hk-w1-west-us | Web | 10.1.1.4 | hk-w-aset-1 | N/D | |
| hk-w2-west-us | Web | 10.1.1.5 | hk-w-aset-1 | N/D |
Per creare l'elenco delle macchine virtuali, seguire questa procedura.
- Creare un servizio cloud vuoto in una determinata area.
- Creare una macchina virtuale dall'immagine acquisita in precedenza. Collegarlo alla rete virtuale creata in precedenza. Ripetere questo passaggio per tutte le macchine virtuali.
- Aggiungere un servizio di bilanciamento del carico interno al servizio cloud. Collegarlo alla subnet "data".
- Per ogni macchina virtuale creata, aggiungere un endpoint con carico bilanciato per il traffico thrift. Il traffico viene eseguito attraverso un set con carico bilanciato connesso al servizio di bilanciamento del carico interno creato in precedenza.
È possibile usare il portale di Azure per eseguire questi passaggi. Usare un computer Windows o usare una macchina virtuale in Azure se non si ha accesso a un computer Windows. Usare lo script di PowerShell seguente per effettuare automaticamente il provisioning di tutte e otto le macchine virtuali.
Script di PowerShell usato per effettuare il provisioning di macchine virtuali
#Tested with Azure Powershell - November 2014
#This PowerShell script deploys a number of VMs from an existing image inside an Azure region.
#Import your Azure subscription into the current PowerShell session before proceeding.
#The process: 1. Create an Azure Storage account. 2. Create a virtual network. 3. Create the VM template. 4. Create a list of VMs from the template.
#Fundamental variables - Change these to reflect your subscription.
$country="us"; $region="west"; $vnetName = "your_vnet_name";$storageAccount="your_storage_account"
$numVMs=8;$prefix = "hk-cass";$ilbIP="your_ilb_ip"
$subscriptionName = "Azure_subscription_name";
$vmSize="ExtraSmall"; $imageName="your_linux_image_name"
$ilbName="ThriftInternalLB"; $thriftEndPoint="ThriftEndPoint"
#Generated variables
$serviceName = "$prefix-svc-$region-$country"; $azureRegion = "$region $country"
$vmNames = @()
for ($i=0; $i -lt $numVMs; $i++)
{
$vmNames+=("$prefix-vm"+($i+1) + "-$region-$country" );
}
#Select an Azure subscription already imported into the PowerShell session.
Select-AzureSubscription -SubscriptionName $subscriptionName -Current
Set-AzureSubscription -SubscriptionName $subscriptionName -CurrentStorageAccountName $storageAccount
#Create an empty cloud service.
New-AzureService -ServiceName $serviceName -Label "hkcass$region" -Location $azureRegion
Write-Host "Created $serviceName"
$VMList= @() # stores the list of azure vm configuration objects
#Create the list of VMs.
foreach($vmName in $vmNames)
{
$VMList += New-AzureVMConfig -Name $vmName -InstanceSize ExtraSmall -ImageName $imageName |
Add-AzureProvisioningConfig -Linux -LinuxUser "localadmin" -Password "Local123" |
Set-AzureSubnet "data"
}
New-AzureVM -ServiceName $serviceName -VNetName $vnetName -VMs $VMList
#Create an internal load balancer.
Add-AzureInternalLoadBalancer -ServiceName $serviceName -InternalLoadBalancerName $ilbName -SubnetName "data" -StaticVNetIPAddress "$ilbIP"
Write-Host "Created $ilbName"
#Add the thrift endpoint to the internal load balancer for all the VMs.
foreach($vmName in $vmNames)
{
Get-AzureVM -ServiceName $serviceName -Name $vmName |
Add-AzureEndpoint -Name $thriftEndPoint -LBSetName "ThriftLBSet" -Protocol tcp -LocalPort 9160 -PublicPort 9160 -ProbePort 9160 -ProbeProtocol tcp -ProbeIntervalInSeconds 10 -InternalLoadBalancerName $ilbName |
Update-AzureVM
Write-Host "created $vmName"
}
Passaggio 3: Configurare Cassandra in ogni macchina virtuale
Accedere alla macchina virtuale ed eseguire le operazioni seguenti:
Modificare $CASS_HOME/conf/cassandra-rackdc.properties per specificare le proprietà del data center e del rack.
dc =EASTUS, rack =rack1Modificare cassandra.yaml per configurare i nodi di inizializzazione.
Seeds: "10.1.2.4,10.1.2.6,10.1.2.8,10.1.2.10"
Passaggio 4: Avviare le macchine virtuali e testare il cluster
Accedere a uno dei nodi, ad esempio hk-c1-west-us. Per visualizzare lo stato del cluster, eseguire il comando seguente:
nodetool –h 10.1.2.4 –p 7199 status
Viene visualizzata una visualizzazione simile a questa per un cluster a otto nodi:
| Stato | Indirizzo | Caricamento | Tokens | Owns | Host ID | Rack |
|---|---|---|---|---|---|---|
| UN | 10.1.2.4 | 87,81 KB | 256 | 38,0% | Guid (removed) | rack1 |
| UN | 10.1.2.5 | 41,08 KB | 256 | 68,9% | Guid (removed) | rack1 |
| UN | 10.1.2.6 | 55,29 KB | 256 | 68,8% | Guid (removed) | rack2 |
| UN | 10.1.2.7 | 55,29 KB | 256 | 68,8% | Guid (removed) | rack2 |
| UN | 10.1.2.8 | 55,29 KB | 256 | 68,8% | Guid (removed) | rack3 |
| UN | 10.1.2.9 | 55,29 KB | 256 | 68,8% | Guid (removed) | rack3 |
| UN | 10.1.2.10 | 55,29 KB | 256 | 68,8% | Guid (removed) | rack4 |
| UN | 10.1.2.11 | 55,29 KB | 256 | 68,8% | Guid (removed) | rack4 |
Testare il cluster a area singola
Per testare il cluster, seguire questa procedura.
Usando il cmdlet Get-AzureInternalLoadbalancer di PowerShell , ottenere l'indirizzo IP del servizio di bilanciamento del carico interno, ad esempio 10.1.1.2.101. La sintassi del comando è Get-AzureLoadbalancer –ServiceName "hk-c-svc-west-us". I dettagli del servizio di bilanciamento del carico interno vengono visualizzati insieme al relativo indirizzo IP.
Accedere alla macchina virtuale della web farm, ad esempio hk-w1-west-us usando PuTTY o SSH.
Eseguire $CASS_HOME/bin/cqlsh 10.1.2.101 9160.
Per verificare se il cluster funziona, usare i comandi CQL seguenti:
CREATE KEYSPACE customers_ks WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 3 }; USE customers_ks; CREATE TABLE Customers(customer_id int PRIMARY KEY, firstname text, lastname text); INSERT INTO Customers(customer_id, firstname, lastname) VALUES(1, 'John', 'Doe'); INSERT INTO Customers(customer_id, firstname, lastname) VALUES (2, 'Jane', 'Doe'); SELECT * FROM Customers;
Vengono visualizzati risultati simili al seguente:
| customer_id | firstname | lastname |
|---|---|---|
| 1 | John | Doe |
| 2 | Jane | Doe |
Il keyspace creato nel passaggio 4 usa SimpleStrategy con un fattore di replica pari a 3. È consigliabile SimpleStrategy per le distribuzioni di data center singoli. Usare NetworkTopologyStrategy per le distribuzioni di più data center. Un fattore di replica pari a 3 fornisce la tolleranza per gli errori del nodo.
Processo di distribuzione a più aree
Usare il processo di distribuzione a area singola e ripetere il processo per installare la seconda area. La differenza chiave tra la distribuzione singola e più aree è la configurazione del tunnel VPN per la comunicazione tra aree. Si inizia con l'installazione di rete, effettuare il provisioning delle macchine virtuali e configurare Cassandra.
Passaggio 1: Creare la rete virtuale nella seconda area
Accedere alla portale di Azure e creare una rete virtuale con gli attributi visualizzati nella tabella. Per istruzioni, vedere Configurare una rete virtuale solo cloud nella portale di Azure.
| Nome attributo | Valore | Osservazioni |
|---|---|---|
| NOME | vnet-cass-east-us | |
| Region | Stati Uniti orientali | |
| Server DNS | Ignorare questo attributo perché non si usa un server DNS di Azure. | |
| Configura una VPN Point-to-Site | Ignorare questo attributo. | |
| Configura una VPN Site-to-Site | Ignorare questo attributo. | |
| Spazio degli indirizzi | 10.2.0.0/16 | |
| IP iniziale | 10.2.0.0 | |
| CIDR | /16 (65531) |
Aggiungere le subnet seguenti:
| NOME | IP iniziale | CIDR | Osservazioni |
|---|---|---|---|
| Web | 10.2.1.0 | /24 (251) | Subnet per la Web farm |
| data | 10.2.2.0 | /24 (251) | Subnet per i nodi del database |
Passaggio 2: Creare reti locali
Una rete locale nella rete virtuale di Azure è uno spazio di indirizzi proxy che esegue il mapping a un sito remoto che include un cloud privato o un'altra area di Azure. Questo spazio di indirizzi proxy è associato a un gateway remoto usato per instradare le reti alle destinazioni di rete corrette. Per informazioni su come stabilire una connessione da rete a rete, vedere Configurare una connessione da rete virtuale a rete virtuale.
Creare due reti locali in base alle informazioni seguenti:
| Nome della rete | Indirizzo del gateway VPN | Spazio degli indirizzi | Osservazioni |
|---|---|---|---|
| hk-lnet-map-to-east-us | 23.1.1.1 | 10.2.0.0/16 | Quando si crea la rete locale, usare un indirizzo del gateway segnaposto. L'indirizzo del gateway reale viene riempito dopo la creazione del gateway. Assicurarsi che lo spazio indirizzi corrisponda esattamente alla rispettiva rete virtuale remota. In questo caso, è la rete virtuale creata nell'area Stati Uniti orientali. |
| hk-lnet-map-to-west-us | 23.2.2.2 | 10.1.0.0/16 | Quando si crea la rete locale, usare un indirizzo del gateway segnaposto. L'indirizzo del gateway reale viene riempito dopo la creazione del gateway. Assicurarsi che lo spazio indirizzi corrisponda esattamente alla rispettiva rete virtuale remota. In questo caso, è la rete virtuale creata nell'area Stati Uniti occidentali. |
Passaggio 3: Eseguire il mapping di una rete locale alle rispettive reti virtuali
Nella portale di Azure selezionare ogni rete virtuale. Selezionare Configura>connessione alla rete locale. Selezionare le reti locali in base alle informazioni seguenti:
| Rete virtuale | Rete locale |
|---|---|
| hk-vnet-west-us | hk-lnet-map-to-east-us |
| hk-vnet-east-us | hk-lnet-map-to-west-us |
Passaggio 4: Creare gateway in entrambe le reti virtuali
Nei dashboard per entrambe le reti virtuali selezionare CREATE GATEWAY per avviare il processo di provisioning del gateway VPN. Dopo alcuni minuti, il dashboard di ogni rete virtuale visualizza l'indirizzo del gateway effettivo.
Passaggio 5: Aggiornare le reti locali con i rispettivi indirizzi del gateway
Modificare entrambe le reti locali per sostituire l'indirizzo IP del gateway segnaposto con l'indirizzo IP reale dei gateway di cui è stato effettuato il provisioning. Usare il mapping seguente:
| Rete locale | Gateway di rete virtuale |
|---|---|
| hk-lnet-map-to-east-us | Gateway di hk-vnet-west-us |
| hk-lnet-map-to-west-us | Gateway di hk-vnet-east-us |
Passaggio 6: Aggiornare la chiave condivisa
Usare lo script di PowerShell seguente per aggiornare la chiave IPSec di ogni gateway VPN. Usare la stessa chiave per entrambi i gateway.
Set-AzureVNetGatewayKey -VNetName hk-vnet-east-us -LocalNetworkSiteName hk-lnet-map-to-west-us -SharedKey D9E76BKK
Set-AzureVNetGatewayKey -VNetName hk-vnet-west-us -LocalNetworkSiteName hk-lnet-map-to-east-us -SharedKey D9E76BKK
Passaggio 7: Stabilire la connessione da rete a rete
Nella portale di Azure usare il menu DASHBOARD di entrambe le reti virtuali per stabilire una connessione gateway-to-gateway. Usare le voci di menu CONNECT nella barra degli strumenti inferiore. Dopo alcuni minuti, il dashboard visualizza le informazioni di connessione.
Passaggio 8: Creare le macchine virtuali nell'area n. 2
Creare l'immagine Ubuntu come descritto nella distribuzione dell'area #1 seguendo la stessa procedura. Oppure copiare il file VHD immagine nell'account di archiviazione di Azure situato nell'area #2 e creare l'immagine. Usare questa immagine per creare l'elenco seguente di macchine virtuali in un nuovo servizio cloud hk-c-svc-east-us:
| Nome computer | Subnet | Indirizzo IP | Set di disponibilità | DC/Rack | Valore di inizializzazione? |
|---|---|---|---|---|---|
| hk-c1-east-us | data | 10.2.2.4 | hk-c-aset-1 | dc =EASTUS rack =rack1 | Sì |
| hk-c2-east-us | data | 10.2.2.5 | hk-c-aset-1 | dc =EASTUS rack =rack1 | No |
| hk-c3-east-us | data | 10.2.2.6 | hk-c-aset-1 | dc =EASTUS rack =rack2 | Sì |
| hk-c5-east-us | data | 10.2.2.8 | hk-c-aset-2 | dc =EASTUS rack =rack3 | Sì |
| hk-c6-east-us | data | 10.2.2.9 | hk-c-aset-2 | dc =EASTUS rack =rack3 | No |
| hk-c7-east-us | data | 10.2.2.10 | hk-c-aset-2 | dc =EASTUS rack =rack4 | Sì |
| hk-c8-east-us | data | 10.2.2.11 | hk-c-aset-2 | dc =EASTUS rack =rack4 | No |
| hk-w1-east-us | Web | 10.2.1.4 | hk-w-aset-1 | N/D | N/D |
| hk-w2-east-us | Web | 10.2.1.5 | hk-w-aset-1 | N/D | N/D |
Seguire le stesse istruzioni dell'area #1, ma usare lo spazio indirizzi 10.2.xxx.xxx.
Passaggio 9: Configurare Cassandra in ogni VM
Accedere alla macchina virtuale ed eseguire le operazioni seguenti:
Modificare $CASS_HOME/conf/cassandra-rackdc.properties per specificare le proprietà del data center e del rack nel formato:
dc =EASTUS rack =rack1Modificare cassandra.yaml per configurare i nodi di inizializzazione:
Seeds: "10.1.2.4,10.1.2.6,10.1.2.8,10.1.2.10,10.2.2.4,10.2.2.6,10.2.2.8,10.2.2.10"
Passaggio 10: Avviare Cassandra
Accedere a ogni macchina virtuale e avviare Cassandra in background eseguendo il comando seguente:
$CASS_HOME/bin/cassandra
Testare il cluster a più aree
A questo momento, Cassandra viene distribuito in 16 nodi con 8 nodi in ogni area di Azure. Questi nodi si trovano nello stesso cluster a causa del nome del cluster comune e della configurazione del nodo di inizializzazione. Usare il processo seguente per testare il cluster.
Passaggio 1: Ottenere l'indirizzo IP del servizio di bilanciamento del carico interno per entrambe le aree usando PowerShell
Get-AzureInternalLoadbalancer -ServiceName "hk-c-svc-west-us"
Get-AzureInternalLoadbalancer -ServiceName "hk-c-svc-east-us"
Si notino gli indirizzi IP, ad esempio west - 10.1.2.101, east - 10.2.2.101, che vengono visualizzati.
Passaggio 2: Eseguire i comandi seguenti nell'area ovest dopo aver eseguito l'accesso a hk-w1-west-us
Eseguire $CASS_HOME/bin/cqlsh 10.1.2.101 9160.
Eseguire i comandi CQL seguenti:
CREATE KEYSPACE customers_ks WITH REPLICATION = { 'class' : 'NetworkToplogyStrategy', 'WESTUS' : 3, 'EASTUS' : 3}; USE customers_ks; CREATE TABLE Customers(customer_id int PRIMARY KEY, firstname text, lastname text); INSERT INTO Customers(customer_id, firstname, lastname) VALUES(1, 'John', 'Doe'); INSERT INTO Customers(customer_id, firstname, lastname) VALUES (2, 'Jane', 'Doe'); SELECT * FROM Customers;
Viene visualizzato un display simile al seguente:
| customer_id | firstname | Lastname |
|---|---|---|
| 1 | John | Doe |
| 2 | Jane | Doe |
Passaggio 3: Eseguire i comandi seguenti nell'area orientale dopo l'accesso a hk-w1-east-us
Eseguire $CASS_HOME/bin/cqlsh 10.2.2.101 9160.
Eseguire i comandi CQL seguenti:
USE customers_ks; CREATE TABLE Customers(customer_id int PRIMARY KEY, firstname text, lastname text); INSERT INTO Customers(customer_id, firstname, lastname) VALUES(1, 'John', 'Doe'); INSERT INTO Customers(customer_id, firstname, lastname) VALUES (2, 'Jane', 'Doe'); SELECT * FROM Customers;
Viene visualizzata la stessa visualizzazione visualizzata per l'area Occidentale:
| customer_id | firstname | Lastname |
|---|---|---|
| 1 | John | Doe |
| 2 | Jane | Doe |
Eseguire alcuni altri inserimenti e verificare che tali inserimenti vengano replicati nella parte west-us del cluster.
Testare il cluster Cassandra da Node.js
Usando una delle macchine virtuali Linux create in precedenza nel livello "Web", eseguire uno script Node.js per leggere i dati inseriti in precedenza.
Passaggio 1: Installare Node.js e il client Cassandra
Installare Node.js e npm.
Installare il pacchetto node cassandra-client usando npm.
Eseguire lo script seguente al prompt della shell che visualizza la stringa JSON dei dati recuperati:
var pooledCon = require('cassandra-client').PooledConnection; var ksName = "custsupport_ks"; var cfName = "customers_cf"; var hostList = ['internal_loadbalancer_ip:9160']; var ksConOptions = { hosts: hostList, keyspace: ksName, use_bigints: false }; function createKeyspace(callback) { var cql = 'CREATE KEYSPACE ' + ksName + ' WITH strategy_class=SimpleStrategy AND strategy_options:replication_factor=1'; var sysConOptions = { hosts: hostList, keyspace: 'system', use_bigints: false }; var con = new pooledCon(sysConOptions); con.execute(cql,[],function(err) { if (err) { console.log("Failed to create Keyspace: " + ksName); console.log(err); } else { console.log("Created Keyspace: " + ksName); callback(ksConOptions, populateCustomerData); } }); con.shutdown(); } function createColumnFamily(ksConOptions, callback) { var params = ['customers_cf','custid','varint','custname', 'text','custaddress','text']; var cql = 'CREATE COLUMNFAMILY ? (? ? PRIMARY KEY,? ?, ? ?)'; var con = new pooledCon(ksConOptions); con.execute(cql,params,function(err) { if (err) { console.log("Failed to create column family: " + params[0]); console.log(err); } else { console.log("Created column family: " + params[0]); callback(); } }); con.shutdown(); } //populate Data function populateCustomerData() { var params = ['John','Infinity Dr, TX', 1]; updateCustomer(ksConOptions,params); params = ['Tom','Fermat Ln, WA', 2]; updateCustomer(ksConOptions,params); } //update also inserts the record if none exists function updateCustomer(ksConOptions,params) { var cql = 'UPDATE customers_cf SET custname=?,custaddress=? where custid=?'; var con = new pooledCon(ksConOptions); con.execute(cql,params,function(err) { if (err) console.log(err); else console.log("Inserted customer : " + params[0]); }); con.shutdown(); } //read the two rows inserted above function readCustomer(ksConOptions) { var cql = 'SELECT * FROM customers_cf WHERE custid IN (1,2)'; var con = new pooledCon(ksConOptions); con.execute(cql,[],function(err,rows) { if (err) console.log(err); else for (var i=0; i<rows.length; i++) console.log(JSON.stringify(rows[i])); }); con.shutdown(); } //execute the code createKeyspace(createColumnFamily); readCustomer(ksConOptions)
Conclusione
Microsoft Azure è una piattaforma flessibile che esegue software Microsoft e open source, come illustrato in questo esercizio. È possibile distribuire cluster Cassandra a disponibilità elevata in un singolo data center distribuendo i nodi del cluster in più domini di errore. I cluster Cassandra possono anche essere distribuiti in più aree di Azure geograficamente distanti per sistemi di prova di emergenza. Usare Insieme Azure e Cassandra per creare servizi cloud altamente scalabili, a disponibilità elevata e ripristinabili in emergenza per i servizi su Internet.